.webp)
July 10, 2026
|
5 min read

Published: February 26, 2026

Blazingly fast way to build, track and deploy your models!
It’s tempting to believe that the biggest challenge with AI agents is intelligence. For a long time, that was true. Models struggled to reason, tools were brittle, and multi-step tasks fell apart easily. But that phase is largely behind us.
Modern agents can already do a lot. They can reason across multiple steps, call tools, invoke MCP servers, and even coordinate with other agents. With the right prompts and models, many teams can build impressive agent prototypes in a surprisingly short time. Demos look convincing. Early results feel magical.
And yet, when these same systems are pushed toward real usage, they start to fail in quiet, confusing ways.
This is the gap that defines the emerging agent-to-agent economy. Not a lack of intelligence, but a lack of infrastructure.
Most early agent implementations follow a deceptively simple pattern. A user sends an input, the agent reasons over it, optionally calls a tool, and returns a response. This linear flow is easy to understand and easy to debug. It also maps well to how developers are used to thinking about applications.
But this model hides an assumption that doesn’t survive contact with reality: that agent execution is short-lived, isolated, and self-contained.
As soon as agents start interacting with other agents, that assumption breaks. One agent delegates work to another. A follow-up action is triggered later. A tool invocation leads to a secondary decision. Execution paths branch, rejoin, and sometimes pause altogether.
At this point, the system stops behaving like an application feature and starts behaving like a distributed system made up of autonomous components.
This transition is subtle, but critical. Teams often don’t realize it has happened until things start going wrong.
When agent systems struggle in production, the failures are rarely dramatic. The system doesn’t crash outright. Instead, trust erodes slowly.
An action is triggered, but no one is sure why.
A downstream agent runs, but under unclear permissions.
Costs spike without an obvious cause.
A workflow stops halfway, and there’s no clear trace explaining where or why.
These aren’t reasoning failures. The agent may have made a perfectly reasonable decision given the information it had. The problem is that no one can reliably explain or govern what happened across the system.
This is the point where many teams instinctively try to “fix” the agent itself, by adjusting prompts, swapping models, or adding more logic. But those changes rarely address the root cause, because the issue doesn’t live inside the agent.
It lives between agents.
If intelligence were the real blocker, we would expect a simple pattern: better models would lead to stable production systems. That’s not what we see.
What we see instead is that as agents become more capable, the systems around them become harder to manage. More intelligence leads to more autonomy, more branching behavior, and more downstream effects. Without the right infrastructure, this extra capability actually increases risk.
The agent-to-agent economy amplifies this effect. As agents begin to call other agents and operate across shared tools and environments, the cost of missing infrastructure grows rapidly. Identity, coordination, policy enforcement, and observability stop being optional concerns and become foundational requirements.
This is where a shift in mindset becomes necessary. Agents cannot be treated as just another piece of application logic. In a real agent ecosystem, agents are long-lived actors that participate in workflows, delegate work, and operate under different authorities.
Platforms like TrueFoundry’s Agent Hub reflect this shift. Instead of assuming agents are private, embedded logic, Agent Hub treats them as registered, discoverable components with explicit interfaces and ownership. Agents are published, versioned, and invoked through a shared control surface rather than calling each other directly through ad-hoc code paths.
This reframing doesn’t make agents smarter. It makes the system around them operable.
The agent-to-agent economy isn’t waiting for a breakthrough in reasoning. It’s waiting for infrastructure that can support autonomy without losing control.
Understanding how agent systems change once they hit production, and why traditional approaches fail, is the first step. From there, the role of control planes, gateways, and explicit execution APIs becomes unavoidable. That’s where the real work begins.
By the time an agent system reaches production, most teams have already solved the obvious problems.
They know how to send requests to an LLM.
They know how to wire tools or MCP servers.
They know how to spin up an agent and get a response back.
These capabilities are no longer experimental. They’re stable, well-documented, and easy to reproduce. In fact, this is precisely why teams gain confidence so quickly. Early success creates the impression that the system is “mostly done.”
Production is where that illusion breaks.
What production really does is expose everything that prototypes conveniently hide.
In a demo, an agent usually runs in isolation. It handles a single request, performs a small number of actions, and exits. There’s one execution path and one outcome. Debugging is straightforward because the entire context fits in a developer’s head.
In production, agents don’t behave this way.
They run continuously.
They trigger follow-up actions.
They call other agents.
They operate across environments, teams, and permissions.
Execution stops being a single interaction and becomes a workflow, often one that unfolds over time.
This is where agent systems start to resemble distributed systems, not because they use microservices or queues, but because behavior is now spread across multiple autonomous actors.
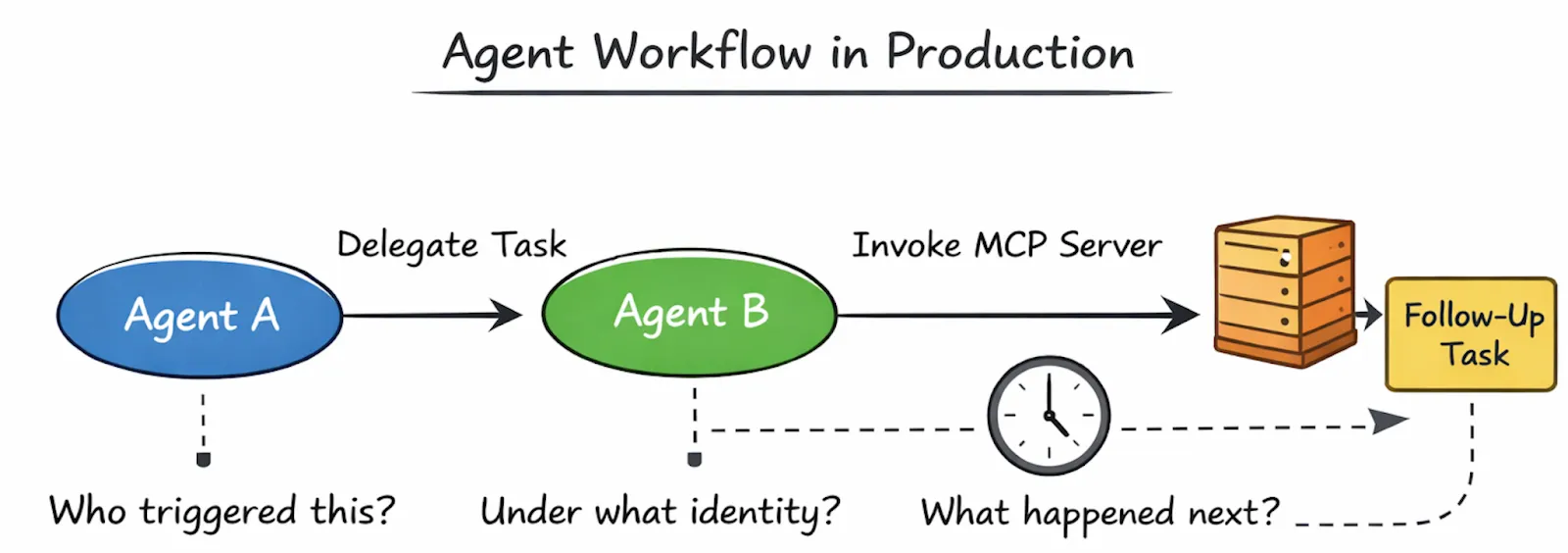
When something goes wrong in production, teams don’t ask whether the agent was “smart enough.” Instead, they ask questions that sound very familiar to anyone who has operated distributed systems:
What triggered this action?
Which agent made the decision?
Under what identity did it run?
Why did the execution branch here?
Why did it stop altogether?
These questions are deceptively simple, and they’re impossible to answer reliably without infrastructure support.
In most early agent setups, execution context lives inside the agent itself. Once an agent calls another agent, or invokes a tool, that context often disappears unless every developer carefully propagates it. Over time, logs fragment, tracing breaks, and the system becomes opaque.
The agent may still be producing outputs, but the system as a whole becomes hard to reason about.
The natural reaction at this stage is to patch the problem locally. One team adds logging around tool calls. Another wraps agents with authentication checks. Someone adds retries in a few places. None of these changes are wrong on their own.
But taken together, they create a fragile web of glue code where:
This is the point where teams start to feel slowed down, not because the agents can’t do more, but because changing anything has unintended consequences.
What’s emerging here, whether teams realize it or not, is a control plane. It just happens to be accidental and poorly defined.
This is where platforms like TrueFoundry draw a clear line between agent logic and system responsibility.
With the Agent Hub, agents are no longer invoked implicitly through local function calls or hidden dependencies. They are registered, discoverable, and executed through a shared interface. With the Agent API, agent execution becomes explicit, contextual, and observable.
Instead of an agent quietly calling another agent, execution is surfaced as a managed operation.
# Using TrueFoundry's Agent API with registered MCP servers
import httpx
response = httpx.post(
"https://{controlPlaneURL}/api/llm/agent/chat/completions",
headers={
"Authorization": "Bearer {TFY_API_TOKEN}",
"Content-Type": "application/json"
},
json={
"model": "openai/gpt-4o",
"messages": [{"role": "user", "content": "Evaluate risk for transaction txn_123"}],
"mcp_servers": [{"integration_fqn": "common-tools", "tools": [{"name": "web_search"}, {"name": "sequential_thinking"}]}],
"stream": True
}
)# Connecting to MCP server through TrueFoundry Gateway
from fastmcp import Client
from fastmcp.client.transports import StreamableHttpTransport
async def main():
url = "https://{controlPlaneURL}/api/llm/mcp/common-tools/server"
transport = StreamableHttpTransport(
url=url,
auth="<tfy-api-token>",
)
async with Client(transport=transport) as client:
tools = await client.list_tools()
result = await client.call_tool("web_search", {"query": "What is Python?"})
return result
Note: The Agent Hub API contract is currently under active development. For the latest syntax and capabilities, refer to the Agent API documentation.
This might look like a small change, but it has significant consequences. Identity travels with the request. Execution boundaries are clear. Downstream actions can be traced back to their origin. Policies can be evaluated before the agent runs, not after something goes wrong.
The agent still reasons and decides what to do. The platform handles how that decision is executed safely.
Once agents reach production, the hard problems are no longer about intelligence. They’re about coordination, identity, visibility, and control. These concerns don’t belong inside agent code, because they apply across agents, workflows, and teams.
This is why many teams reach for a shortcut next: putting a router in front of their agents and hoping that will be enough.
It rarely is.
Understanding why that approach fails is the next step in understanding what real agent infrastructure needs to look like.
Once teams realize their agent system is becoming hard to manage, the first instinct is usually pragmatic: add a router in front of the agents.
This approach feels familiar. API gateways and routers are well understood. They’ve worked for microservices, so why not reuse the same pattern for agents? Put a routing layer in front, decide which agent to call, and move on.
For a short while, this works. Then the system starts to bend in ways the router was never designed to handle.
Routers are built for a very specific world. They assume requests are short-lived, execution paths are mostly linear, and identity is either uniform or resolved once at the edge. They forward traffic efficiently, but they don’t understand intent.
Agent-to-agent systems violate these assumptions almost immediately.
Agents don’t just respond to requests. They initiate actions, delegate work to other agents, and trigger side effects that unfold over time. A single decision can fan out into multiple downstream executions, some immediate, some delayed. Identity is no longer a single header; it’s something that needs to be preserved and reasoned about across hops.
A router can forward a request. It can’t explain why that request exists.
As agent systems grow, teams begin pushing more responsibility into the router. Authentication rules get added. Model selection gets encoded into routes. Policy checks are hard-coded into routing logic. Context is stitched together using headers and conventions.
None of this feels wrong in isolation. But over time, the router becomes a dumping ground for concerns it wasn’t meant to handle. It turns into a brittle choke point where:
Ironically, the router that was meant to simplify the system becomes the thing that slows everyone down.
The deeper issue is that agent systems don’t just need traffic management. They need governance.
Security and compliance teams don’t ask which route was hit. They ask who accessed what, under what authority, and why. Product teams don’t just want to know where a request went; they want to understand how a decision propagated across agents and tools. Operators need to see how cost and behavior evolve across an entire workflow, not just at the edge.
These questions can’t be answered by routing alone, because they depend on intent, delegation, and derived actions. Those concepts don’t live naturally in a router.
This is where the distinction between a router and a control plane becomes clear.
With TrueFoundry’s Agent Hub, agents are not anonymous endpoints behind a routing table. They are named, registered entities with explicit interfaces and ownership. When one agent invokes another, it does so through a managed execution layer rather than an opaque network hop.
The Agent API reinforces this separation. Execution isn’t hidden behind a route; it’s an explicit operation with identity, metadata, and policy evaluation built in. The gateway enforces rules consistently, while preserving context across agent-to-agent interactions.
This doesn’t remove flexibility. It restores it. By keeping routing focused on traffic and moving governance into dedicated infrastructure, teams can evolve agent behavior without turning their routing layer into a fragile monolith.
“Just a router” fails not because it’s poorly implemented, but because it’s solving the wrong problem. Agent-to-agent systems are not request routers with smarter endpoints. They are distributed systems with autonomous behavior.
Once teams accept that, the next realization follows naturally: agent systems behave like distributed systems, but with higher stakes.
By the time teams realize that a router isn’t enough, another pattern usually starts to emerge on its own. Small pieces of coordination logic begin appearing everywhere. One agent adds permission checks before calling a tool. Another embeds retry logic when invoking a downstream agent. A third team adds custom logging to track what happened after an action was triggered.
None of these changes are wrong. In fact, they’re practical responses to real problems. But taken together, they point to something deeper: the system is missing a control plane.
A control plane isn’t about doing the work. It’s about deciding how work is allowed to happen.
In an agent-to-agent system, there are questions that simply don’t belong inside agent logic:
Who is allowed to invoke this agent?
Under what conditions?
Using which tools or MCP servers?
With what level of visibility and auditability?
When these decisions are embedded directly inside agents, they get duplicated and drift over time. Two agents that should behave the same way slowly diverge. Policies are enforced inconsistently. Debugging becomes guesswork because no single place reflects how the system is actually governed.
This is exactly the problem TrueFoundry’s Agent Hub is designed to solve.
Agent Hub treats agents not as private implementation details, but as registered, discoverable entities within a shared system. It provides capabilities including:
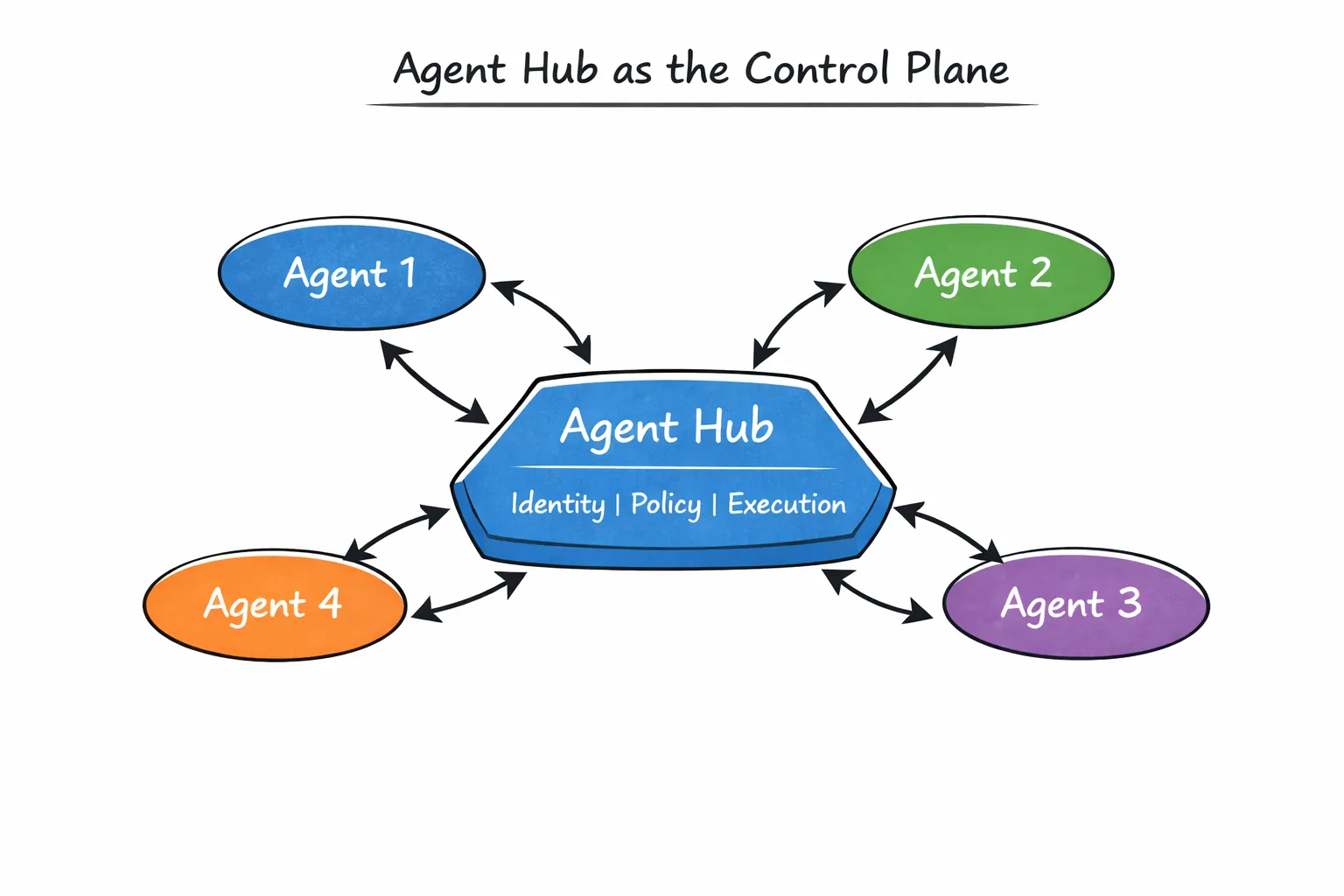
Each agent is published with a clear interface, ownership, and execution boundary. Other agents don’t “reach into” it through ad-hoc code paths. They invoke it explicitly.
This changes the nature of agent-to-agent interactions. Instead of hidden dependencies, relationships become visible. Instead of implicit trust, execution flows through a managed layer.
A useful way to visualize this is to place Agent Hub at the center of the system:
As systems grow, workflows rarely stay simple. One agent might specialize in retrieval, another in evaluation, another in decision-making. These agents don’t replace each other; they collaborate.
Agent Hub supports this explicitly through sub-agents and multi-agent workflows. Rather than hard-coding orchestration logic inside a single “mega-agent,” teams can compose workflows by chaining agents together in a controlled way.
This has two important effects. First, it keeps individual agents focused and understandable. Second, it centralizes coordination logic so that changes to how agents interact don’t require rewriting every agent involved.
The system becomes easier to evolve, not harder.
Another quiet benefit of a centralized control plane is visibility. In many organizations, agents proliferate faster than governance. Teams build what they need, copy credentials, and deploy agents wherever they can. Over time, no one is quite sure how many agents exist, what data they access, or who owns them.
Agent Hub provides a shared surface where agents are registered and discovered. This doesn’t slow teams down; it gives them a safe default. When the official path is easy and visible, there’s far less incentive to build agents in the shadows.
It’s important to be clear about what a control plane is not. It’s not a place where all logic lives, and it’s not a bottleneck that teams must negotiate for every change. Agent Hub doesn’t tell agents what to think. It defines how agents participate in the system.
Agents still reason independently. Teams still ship quickly. But the rules of engagement, identity, invocation, and coordination, are handled consistently across the ecosystem.
This separation is what makes agent systems sustainable as they grow.
Once a control plane exists, the final piece of the puzzle becomes obvious: execution needs to be enforced and observed at runtime. That’s where gateways and explicit agent APIs come in, and that’s what we’ll look at next.
Once a control plane exists, one question becomes unavoidable: where is that control actually enforced?
In agent systems, decisions about identity, policy, and routing don’t matter unless they are applied at runtime, right at the moment an agent tries to act. This is where gateways and explicit agent APIs become critical. Without them, a control plane is only advisory. With them, it becomes real.
One of the most common failure modes in agent systems is invisible execution. An agent calls another agent as a local function. That agent invokes a tool. A side effect occurs. Everything “works,” but no one can clearly see what happened or why.
The problem isn’t that the execution is wrong. It’s that it’s hidden.
TrueFoundry’s Agent API forces agent execution to be explicit. Instead of implicit calls buried in code, agent interactions become first-class operations. Each invocation carries identity, context, and intent with it, and flows through the same infrastructure every time.
# TrueFoundry Agent API - explicit, governed agent execution
import httpx
response = httpx.post(
"https://{controlPlaneURL}/api/llm/agent/chat/completions",
headers={
"Authorization": "Bearer {TFY_API_TOKEN}",
"Content-Type": "application/json"
},
json={
"model": "openai/gpt-4o",
"messages": [{"role": "user", "content": "Search for information about Python"}],
"mcp_servers": [
{"integration_fqn": "common-tools", "tools": [{"name": "web_search"}]}
]
}
)Note: The Agent Hub API contract is currently under active development. For the latest syntax and capabilities, refer to the Agent API documentation.
This call may look simple, but it represents a major architectural shift. The agent is no longer acting in isolation. Its execution is mediated, tracked, and governed.
In traditional systems, gateways are often treated as traffic routers. In agent systems, that framing is too narrow. Gateways aren’t just forwarding requests, they are enforcing intent.
TrueFoundry’s AI Gateway sits between agents, models, and MCP servers. Every agent execution passes through it. This allows the system to evaluate policies before anything happens: whether an agent is allowed to run, which tools it can access, which model it should use, and what must be logged or restricted.
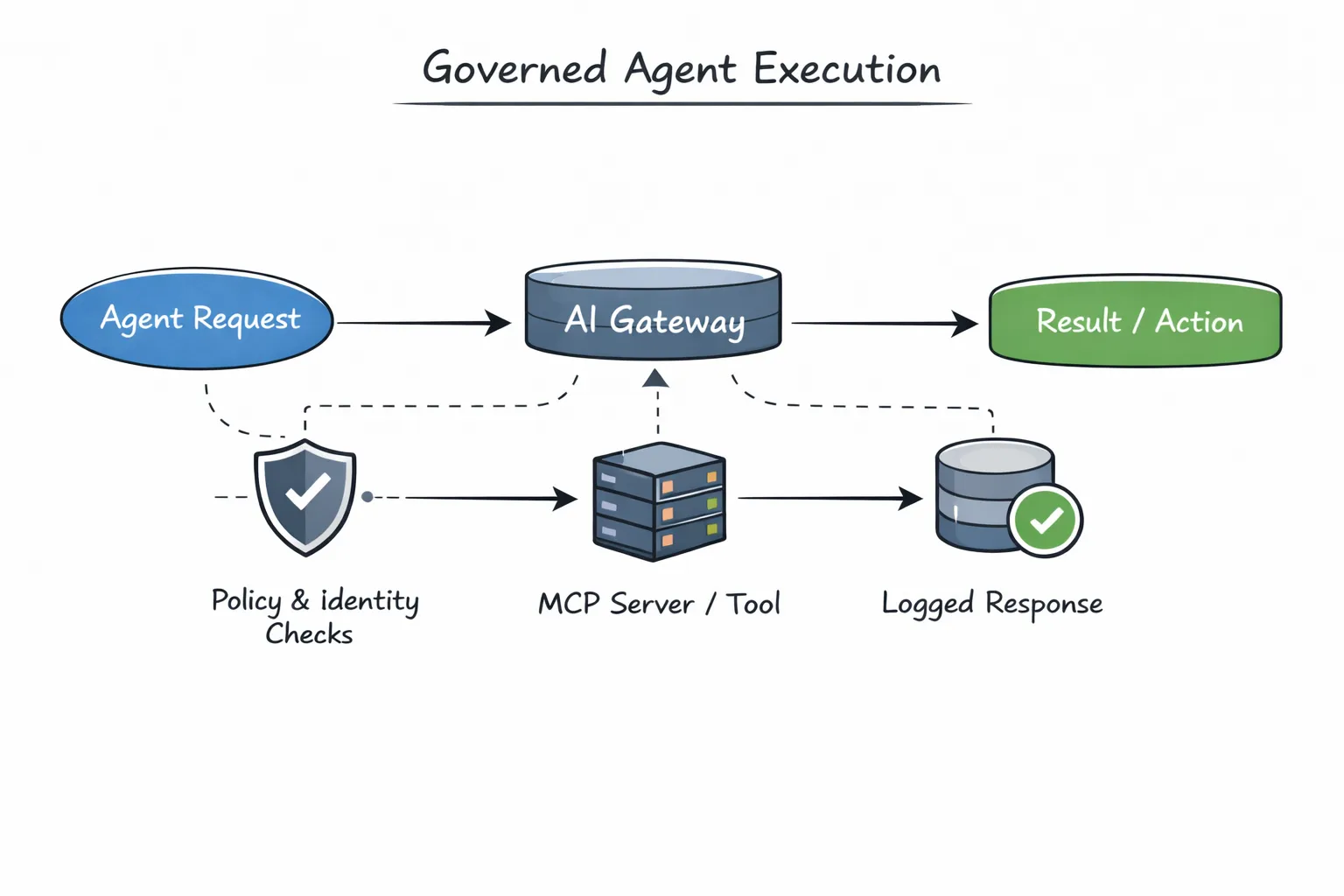
Because all execution flows through a shared gateway, enforcement becomes consistent by default. There’s no need for every agent to reimplement access checks, retries, or logging. Those concerns live where they belong, outside agent logic.
Tool access is where agent systems often become dangerous. Tools can write data, trigger external systems, or perform irreversible actions. When agents call tools directly, credentials and access logic tend to get copied around, creating security and compliance risks.
The Agent API integrates MCP servers through the gateway, which means tools are invoked under controlled conditions. Whether an MCP server is registered within the platform or provided externally, access is mediated, authenticated, and observable. Agents get the capabilities they need without carrying secrets or bypassing policy.
This is especially important in agent-to-agent workflows, where one agent’s decision can cascade into multiple tool invocations downstream.
Another benefit of explicit execution is visibility. Because agent invocations flow through a shared API and gateway, it becomes possible to trace behavior end to end. Teams can see which agent initiated an action, which downstream agents and tools were involved, how long execution took, and where costs accumulated.
In agent systems, cost is not just a billing concern, it’s a behavioral signal. A small change in reasoning can fan out into many calls. Without observability, teams lose the ability to understand or control that amplification.
Explicit execution restores that understanding.
The goal of agent APIs and gateways is not to limit what agents can do. It’s to make autonomous behavior operable.
Agents still reason independently. They still collaborate and delegate. But they do so within a system that can enforce rules, explain outcomes, and evolve safely over time.
At this point, the core pattern becomes clear. Agent-to-agent systems don’t scale on intelligence alone. They scale when autonomy is paired with infrastructure that can govern it.
That brings us to the final question: what actually determines success in an agent-to-agent economy over the long term?
As agent capabilities continue to improve, intelligence will become the least interesting part of the system. Better models will be easier to access. Prompting techniques will spread quickly. What feels advanced today will become baseline tomorrow.
The real differentiator won’t be how smart individual agents are. It will be whether the systems around them can support autonomy without losing control.
Agent-to-agent economies introduce a new class of complexity. Decisions propagate across agents. Actions trigger downstream effects. Costs and risks amplify faster than humans can intervene. Without infrastructure, these systems become opaque, fragile, and difficult to trust.
What makes agent systems sustainable is not more logic inside agents, but clear separation of concerns:
This is where platforms matter.
TrueFoundry’s Agent Hub and Agent API don’t try to make agents smarter. They provide the missing infrastructure layer that allows agent systems to behave like well-governed distributed systems instead of unpredictable collections of scripts. Agents become discoverable, composable, and operable. Autonomy becomes something teams can trust.
The agent-to-agent economy won’t be won by point solutions or clever demos. It will be built by platforms that make autonomy reliable at scale. Intelligence will commoditize. Infrastructure will differentiate.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








The latest news, articles, and resources sent to your inbox
.webp)
.webp)
.webp)







.png)
.webp)