.webp)
July 10, 2026
|
5 min read

Published: March 13, 2026
.webp)
Blazingly fast way to build, track and deploy your models!
Here is a scenario that is happening in production environments right now.
You deploy the standard, open-source GitHub MCP server. The goal is simple: you want your engineering support agent to read issue comments and summarize them for the team. It works perfectly. The agent connects, performs a list_tools handshake, and starts fetching data.
Two days later, that same agent hallucinates. Instead of summarizing a thread, it decides the repository is "deprecated" based on a misunderstood comment and calls delete_repo.
Why did this happen? It wasn’t a prompt injection attack. It wasn’t a malicious insider. It was a fundamental architectural failure.
The standard GitHub MCP server like the Stripe, Postgres, and Kubernetes servers you find on GitHub is binary. It exposes every API endpoint it wraps. If the server supports delete_repo, and you give the agent the connection string, the agent has delete_repo. There is no native .gitignore for tool capabilities. There is no chmod for JSON-RPC tool definitions.
Yet, we are routinely deploying agents with "Root Access" to our most critical infrastructure because the standard MCP implementation lacks granularity.
This is a non-starter for enterprise adoption. We don’t need more "AI policy documents" or stern warnings in system prompts. We need an architectural pattern that slices MCP servers into safe, scoped interfaces.
We call this the Virtual MCP Server.
To solve this, we have to look at how we route traffic between the LLM and the tools. Right now, there are two dominant patterns emerging in the ecosystem (often cited in Gartner and TrueFoundry documentation): the Aggregator and the Proxy.
The Proxy performs payload inspection before requests ever reach the backend, allowing unsafe tools to be removed at discovery time. It allows us to intercept the tools/list JSON-RPC response and surgically remove the tools the agent shouldn't know exist.
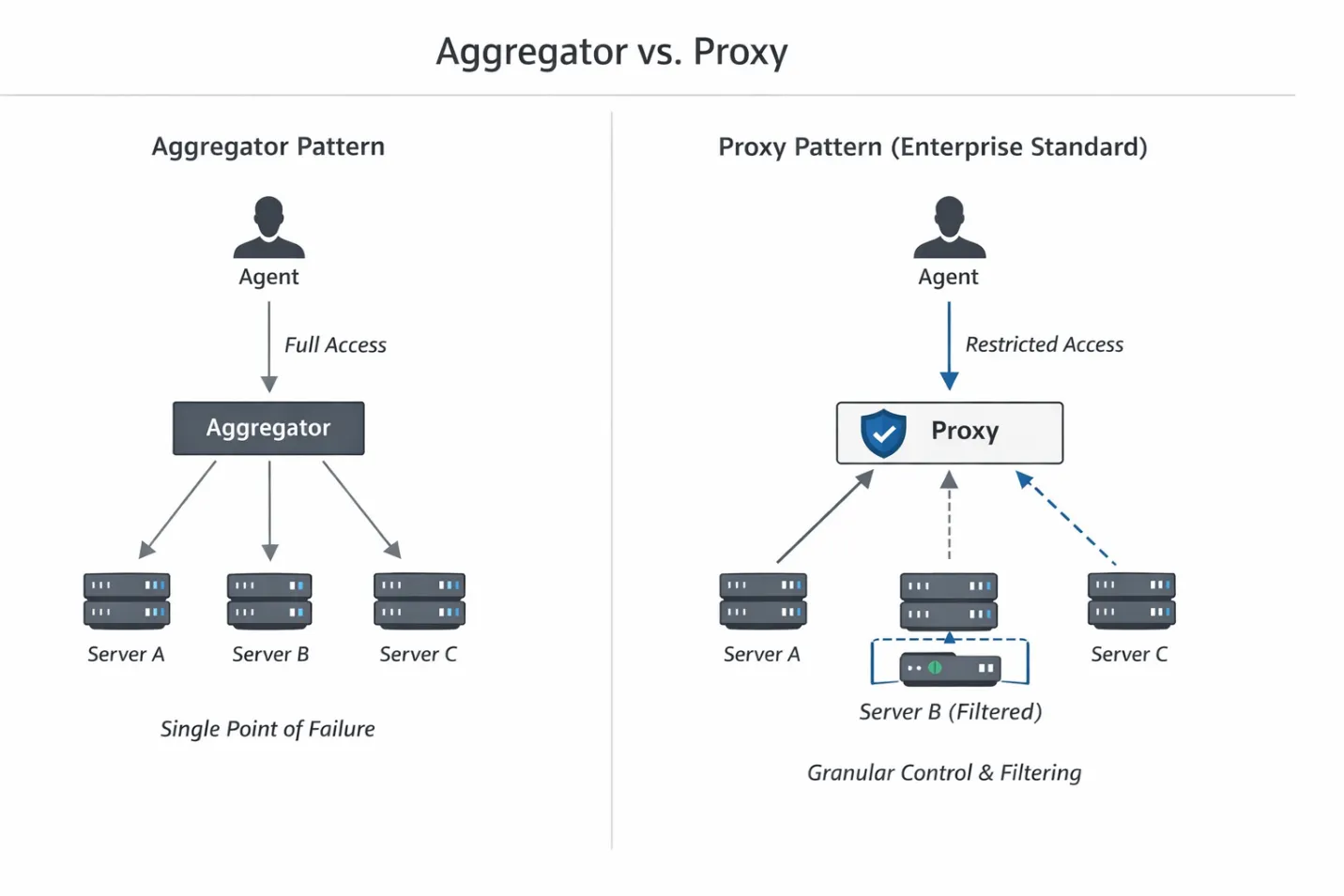
This brings us to the core implementation pattern: the Virtual MCP Server.
A Virtual MCP Server is a logical construct. It references specific tools from physical MCP servers without duplicating their execution logic or redeploying infrastructure. This is where MCP vs API becomes practical for enterprise teams: traditional APIs usually restrict access at the endpoint level, while MCP must also decide which tools are visible during discovery before an agent ever makes a call. Think of it like a VIEW in SQL: it allows you to present a restricted subset of data (or in this case, capabilities) to a specific user (the agent) without altering the underlying table (the physical server).
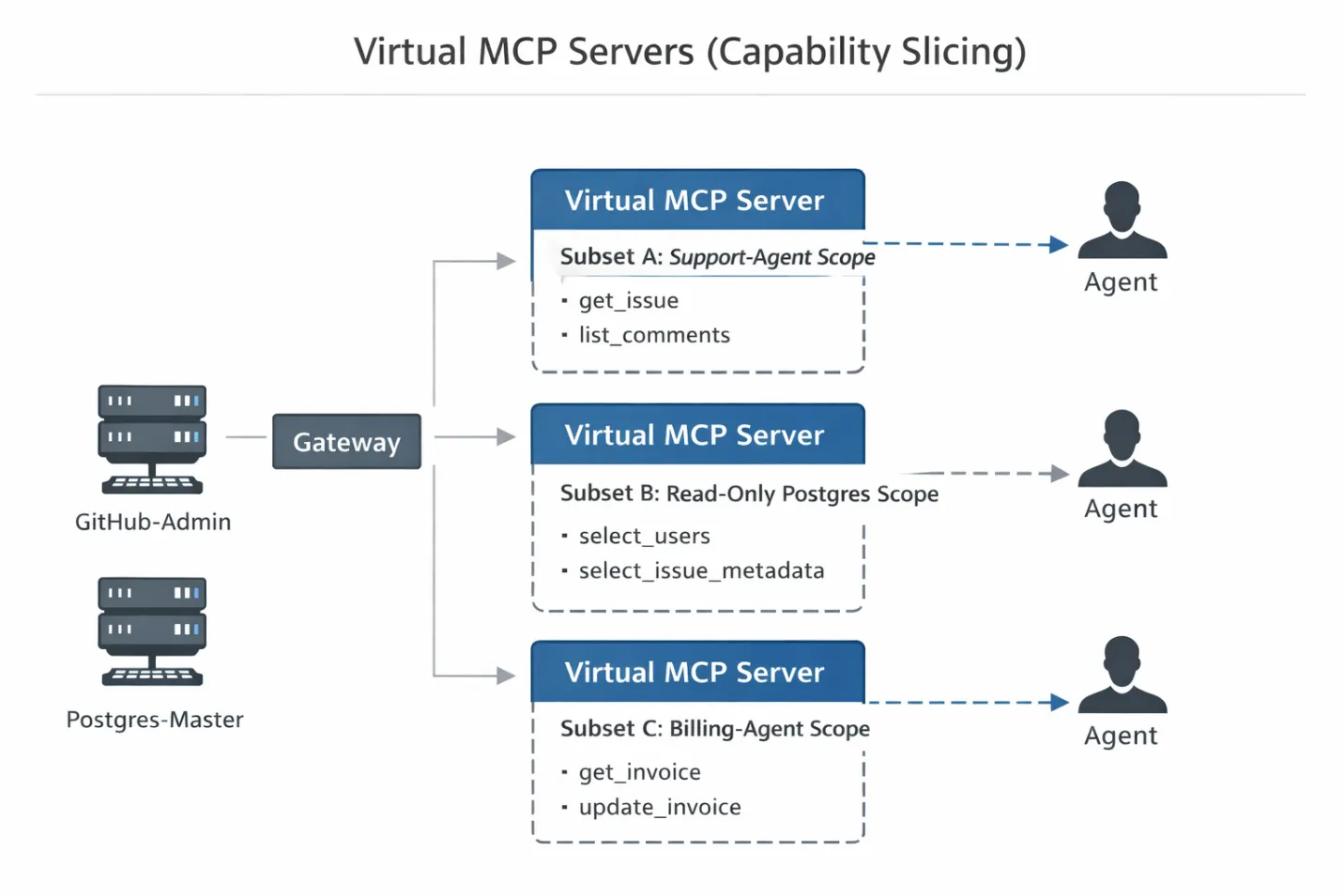
Here is how you implement this pattern in a production Gateway architecture:
Step 1: The Backend Connection (The "Service Account") First, you connect your raw, high-privilege MCP servers to the Gateway.
Step 2: The Slice (The Manifest) Next, you define a Virtual Server manifest. This is a configuration file (typically YAML or JSON) that defines exactly which tools from the physical servers are exposed to a specific agent scope.
Instead of granting access to github-all, you create a slice. Here is what a typical Virtual Server configuration looks like:

Step 3: The Client View (The Handshake) When the Agent initializes its connection, it performs the standard JSON-RPC tools/list handshake with the Gateway.
Because the Agent is connected to the support-agent-scope Virtual Server, the Gateway intercepts this request. It filters the master list against the manifest defined in Step 2 and returns a sanitized list.
The result? It is technically impossible for the agent to hallucinate a call to delete_repo. That function simply does not exist in its context window. You haven't just told the model "don't do it, "you have removed the hands it would use to do it.
So where does TrueFoundry actually sit in this architecture?
Not as a hosting layer, and not as a convenience wrapper. In a production MCP stack, TrueFoundry functions as the protocol gateway and control plane. It sits directly in the execution path between the LLM runtime and the tools, where enforcement is still possible.
This positioning matters. Because the gateway terminates the MCP connection, it can parse and reason about the JSON-RPC payload in real time. It is not just forwarding requests. It is interpreting intent, identity, and scope before any tool ever executes.
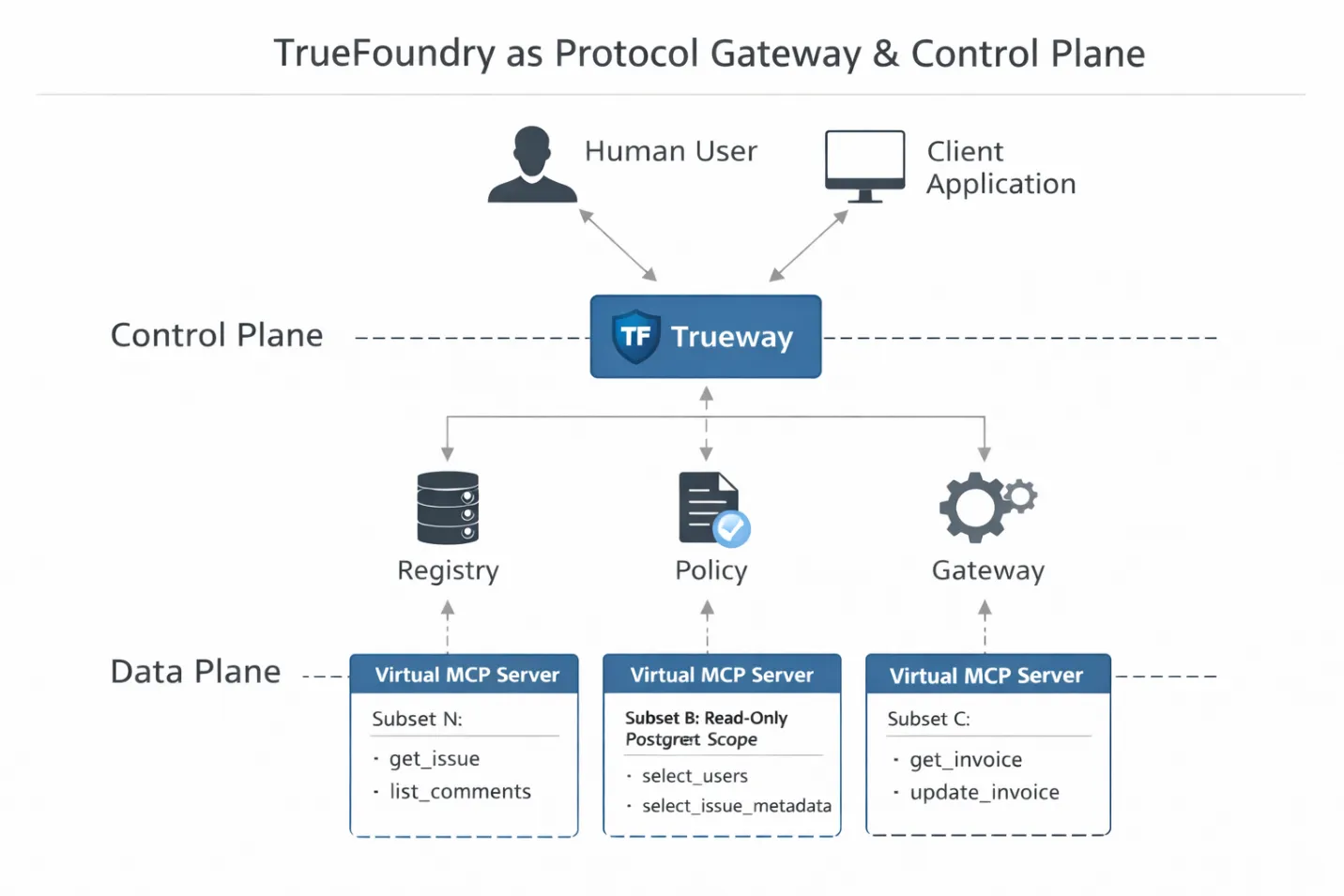
That enables three concrete engineering capabilities.
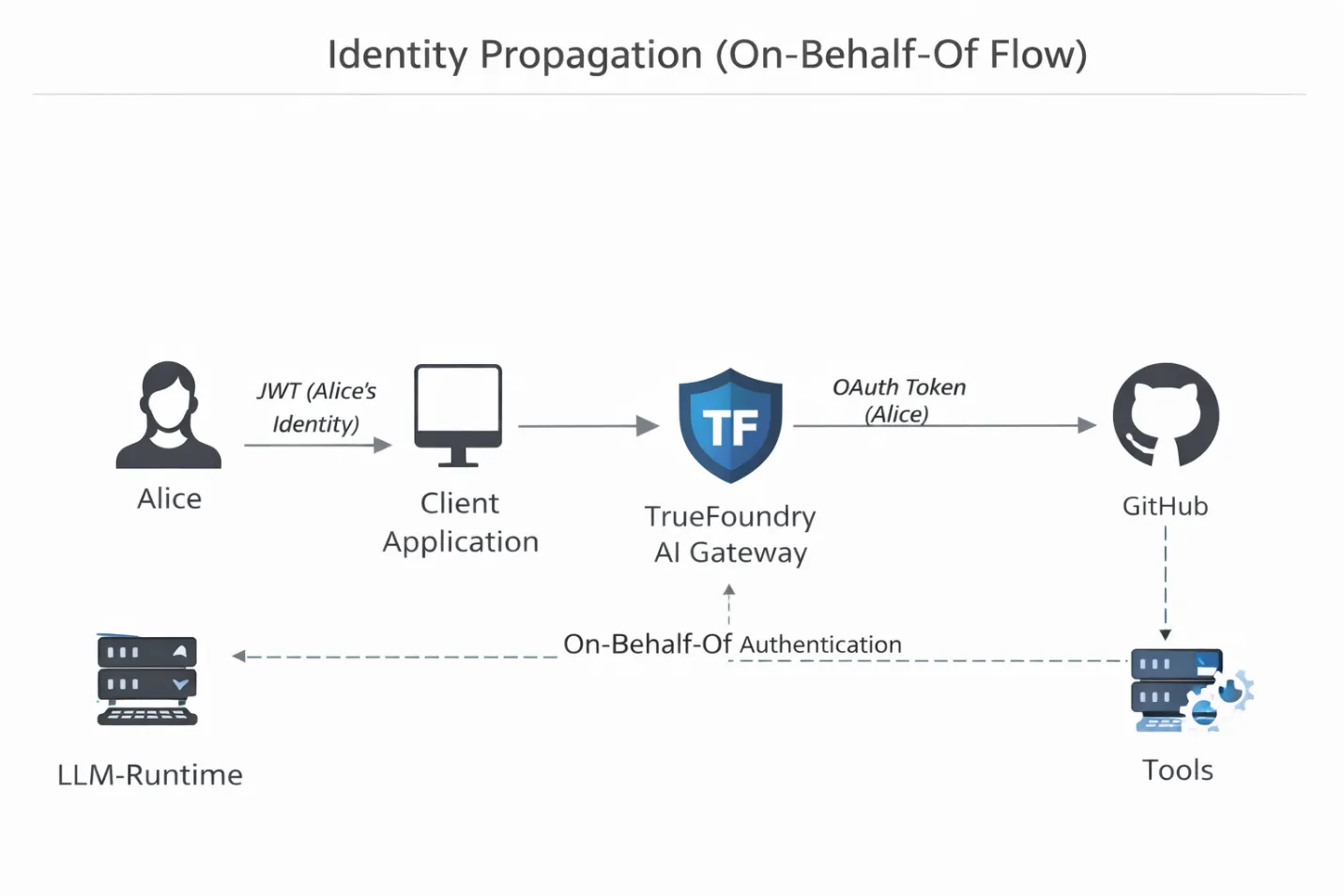
Most DIY agent stacks suffer from the “generic key” problem. Agents run with a shared API token, so when something goes wrong, all you see in the logs is “the agent did it.” There is no accountability. TrueFoundry’s gateway inspects the incoming client JWT, maps it to the authenticated human user, and injects the correct OAuth or service token downstream. If Alice cannot delete a repository, neither can the agent acting on her behalf. The agent’s authority is no longer theoretical. It is cryptographically bound.
The gateway is where Virtual MCP Servers become real. TrueFoundry maintains the routing tables that map a virtual server scope to physical MCP servers and allowed tools. If an agent attempts to call something outside its declared slice, the gateway returns a structured JSON-RPC error. The model does not get a silent failure. It gets a clear “tool not found,” which helps it self-correct instead of hallucinate.
Because the gateway terminates the connection, it can buffer and trace MCP traffic. This enables PCAP-style inspection of tool interactions. When an agent gets stuck in a loop or makes a bad decision, you can replay the exact tool call sequence without rerunning the expensive inference steps that led to it. Debugging shifts from guesswork to inspection.
Taken together, this is the difference between hoping an agent behaves and enforcing that it cannot misbehave. Access control moves out of prompts and into infrastructure, where it belongs.
Virtual Servers control which tools an agent can see. Guardrails control how those tools are used. Just because an agent is allowed to call sql_query, doesn't mean it should be allowed to run SELECT * FROM users and dump the entire customer database into its context window.
This is where Guardrails come in. In the TrueFoundry architecture, guardrails operate as middleware that intercepts the JSON-RPC payload at the protocol layer, inspecting traffic before it is executed.
Input Guardrails (The "WAF" for Agents) We can write Python middleware or simple regex rules that validate tool arguments before the request reaches the backend container.
Output Guardrails (Data Loss Prevention) Agents are prone to "verbose leaking," fetching more data than they need and summarizing it.
In traditional software, if an API call fails, you check the logs. You see a 500 Internal Server Error and a stack trace.
In agentic systems, "failure" is often silent. The agent calls a tool, gets a result, but misinterprets it. Or it calls the tool with slightly wrong arguments that technically work but return garbage data. Standard application logs show "200 OK," but the outcome is wrong.
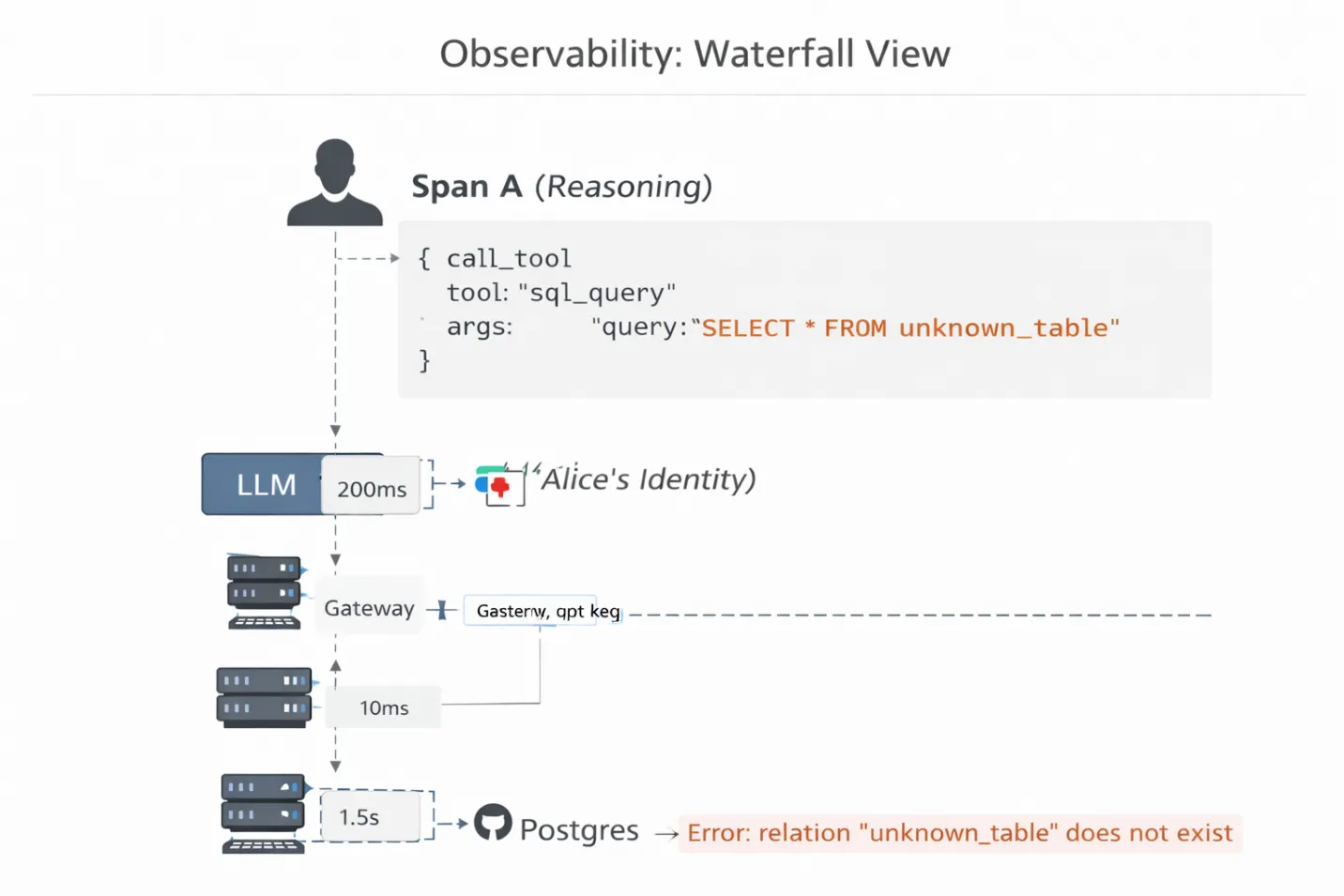
To debug this, you need Distributed Tracing for MCP.
TrueFoundry provides a waterfall visualization of the agent's execution chain. You don't just see "Request Failed." You see the latency and payload at every hop:
Why this matters: You can drill down into Span C and see the exact SQL query the agent generated. You might realize the agent is hallucinating a table name that doesn't exist, or using a deprecated API parameter. Without this protocol-level visibility, you are debugging a black box by guessing.
The transition from "Chatbot" to "Agent" is effectively the transition from "Text Generation" to "Remote Code Execution." That reality is exactly what keeps most enterprise pilots grounded in the PoC phase.
TrueFoundry bridges that gap. When you implement the Virtual MCP Server pattern via the AI Gateway, you stop asking your security team to trust a probabilistic model and start showing them a deterministic architecture. You aren't just deploying a tool; you are deploying a scoped, identity-aware interface that inherently limits blast radius.
For enterprises, TrueFoundry doesn't only provide the "pipes" for MCP; it provides the valves, gauges, and locks. It turns a reckless "Root Access" agent into a trusted digital employee. You wouldn't run a production Kubernetes cluster without RBAC; you shouldn't run an enterprise agent stack without TrueFoundry.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








The latest news, articles, and resources sent to your inbox
.webp)
.webp)
.webp)







.png)
.webp)