













August 3, 2026
|
5 min read

Published: June 12, 2026

Blazingly fast way to build, track and deploy your models!
AWS Bedrock serves as a managed layer for accessing foundation models within the AWS VPC boundary. For engineering teams, it removes the operational overhead of provisioning GPU instances or managing Kubernetes clusters for inference. The service offers immediate access to models like Claude 3.5 Sonnet, Llama 3, and Amazon Titan via a unified API.
However, AWS Bedrock pricing is not a flat rate. It functions as a complex menu where the final cost is a function of model variance, token distribution, regional traffic capabilities, and the operational overhead of supporting services like CloudWatch and OpenSearch. This report dissects the unit economics of AWS Bedrock, identifies where costs spike at scale, and analyzes the architectural trade-offs between managed inference and self-hosted alternatives using platforms like TrueFoundry.
Before examining detailed costs, it’s important to understand the overall AWS Bedrock pricing model. AWS Bedrock follows a pure usage-based pricing approach with no upfront platform or subscription fees.
You don't pay to turn the service on. Instead, you are billed primarily for model inference, measured through tokens or generated outputs. However, the price per unit varies significantly depending on the foundation model provider; an Anthropic model costs significantly more than a Meta or Mistral model, even if the token count is identical.
AWS Bedrock pricing is driven by how models consume resources during inference. While most text models bill per token, multimodal models differ.
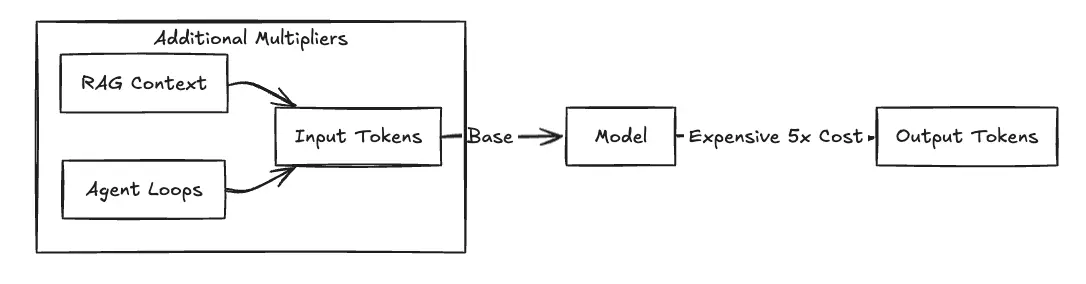
You must distinguish between Input Tokens and Output Tokens. Input tokens consist of the prompt payload, including system instructions, user queries, and—crucially—retrieved context from RAG pipelines. Output tokens are the generated response.
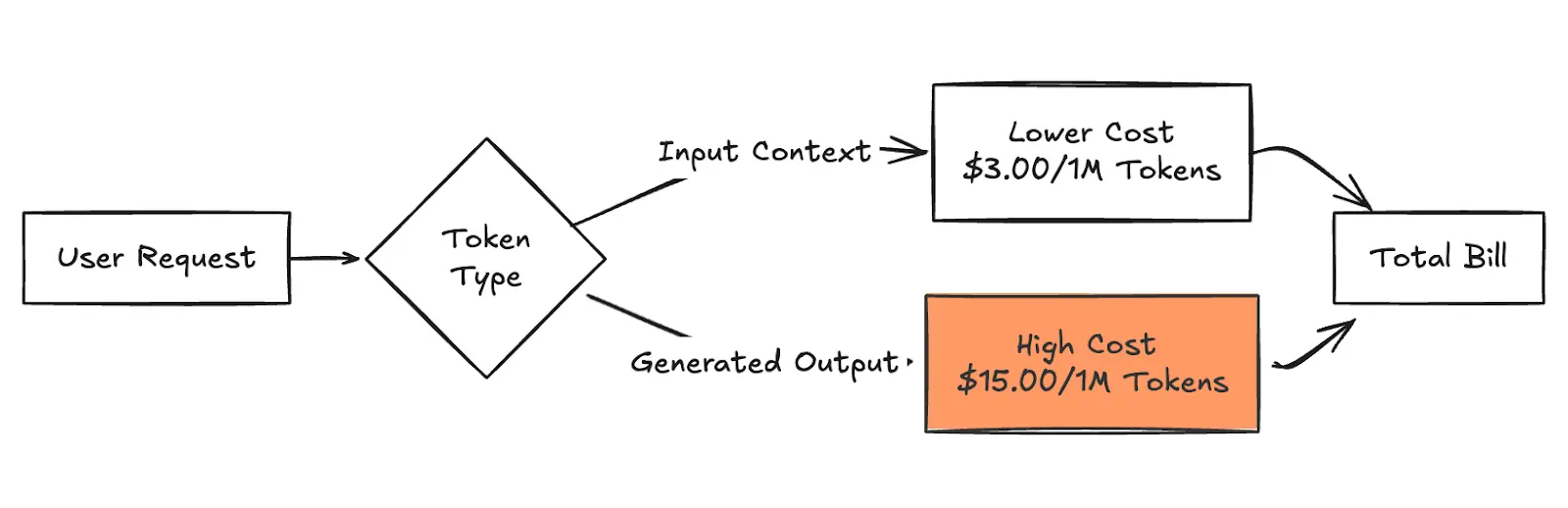
Operational reality dictates that output tokens are significantly more expensive because the computational cost of generation (next-token prediction) is higher than processing input context. For example, with Claude Sonnet 4.5 in us-east-1, you pay $3.00 per million input tokens but $15.00 per million output tokens—a 5x multiplier. For multimodal models like Amazon Titan Image Generator, billing shifts to a per-image basis, calculated on resolution and step count.
Fig 1: The Cost Multiplier Effect
AWS Bedrock pricing isn't just "pay per token." Teams must choose between two pricing models that trade flexibility for guaranteed capacity.
Fig 2: Decomposition of Total Bill
Pricing reflects AWS Bedrock On-Demand rates for Anthropic Claude 3.5 Sonnet in the us-east-1 region as of Jan 2026. Prices may vary by region or model version.
On-Demand pricing is the default option for most AWS Bedrock users. It offers flexibility but comes with operational risks. You are charged strictly per 1,000 tokens processed, which is perfect for variable traffic patterns or early experimentation where usage patterns are "bursty." However, the downside is reliability. AWS enforces throttling limits, meaning that during peak demand, your requests may face throttling.
Provisioned Throughput pricing is designed for teams that need guaranteed model availability at scale. It introduces predictability but requires a financial commitment. Instead of paying per token, you purchase a dedicated model unit to reserve inference capacity and guarantee a specific throughput pricing tier.
The catch is that you are charged a fixed hourly fee regardless of whether you send zero requests or max out the unit. This model operates like a reserved instance; it typically requires a 1- to 6-month commitment, reducing your ability to switch models quickly if a better one is released next week.
Unlike OpenAI, where you pay one vendor, Bedrock is a marketplace. Pricing strategies differ by vendor.
Amazon Titan models are AWS-native foundation models designed for general-purpose AI workloads. Because they are first-party models, they are typically priced lower than third-party alternatives. This makes them suitable for cost-sensitive production use cases like embedding generation or simple classification, where "good enough" performance at a low price point is the goal.
AWS Bedrock also provides access to models from external providers like Anthropic, Cohere, and AI21 Labs. Pricing here is generally higher due to the advanced capabilities and external licensing involved. Be aware of the cost premium on high-reasoning models like Claude 4.5 Sonnet, where output tokens are significantly more expensive. Costs here can rise quickly for chat-heavy applications where the model "thinks" or generates long, verbose responses.
Your application design impacts your bill just as much as the model price tag.
The base token price is often just the tip of the iceberg. Real-world AI applications use "Knowledge Bases" and "Agents," which carry their own separate meters.
Fig 3: The Additional Cost Stack
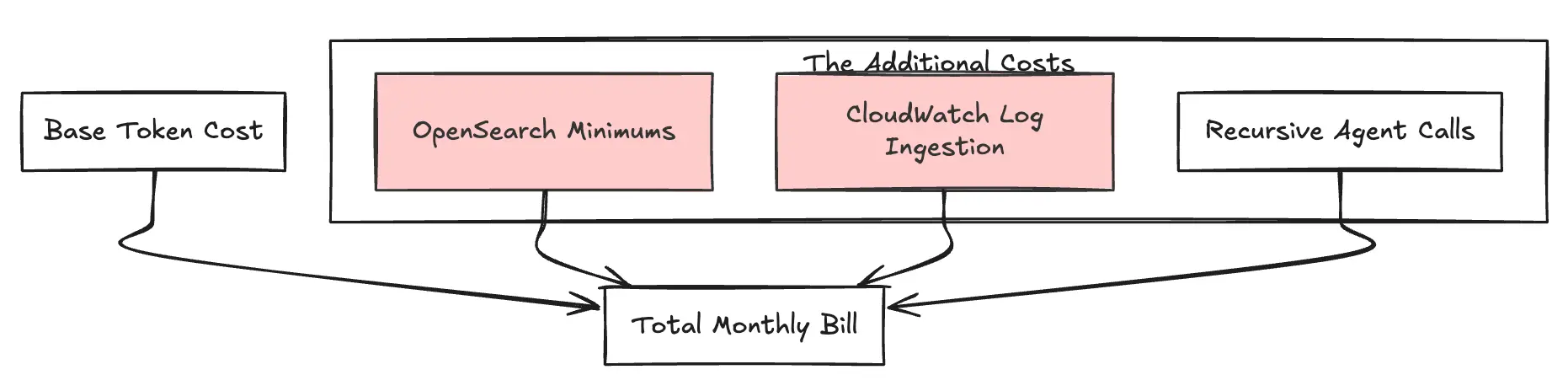
Bedrock Knowledge Bases abstract away the RAG pipeline but provision infrastructure in the background. Typically, this spins up an OpenSearch Serverless vector store. Engineering teams often overlook the minimum floor cost: OpenSearch Serverless requires a minimum of 2 OCUs (OpenSearch Compute Units) for redundancy in production. At ~$0.24 per OCU/hour (in us-east-1), this results in a baseline cost of approximately $350/month (for a standard redundant setup) for the index to exist, even with zero query traffic.
"Agents" perform multiple steps to answer one user query (Thinking → Searching → Summarizing). The impact is that a single user question might trigger 10x the tokens you expected due to this internal looping and reasoning trace. You pay for the input and output of every intermediate thought, which creates a multiplier effect on your invoice.
Auditability is mandatory for enterprise AI, but Bedrock’s integration with CloudWatch Logs is verbose. It logs full prompt and response payloads. CloudWatch ingestion in regions like us-east-1 costs $0.50 per GB, and storage adds another $0.03 per GB. High-volume text generation applications can easily generate hundreds of gigabytes of log data, quietly adding significant overhead to the monthly bill.
Many teams underestimate AWS Bedrock pricing during early experimentation because the variables are hard to isolate. Token usage varies widely based on user behavior; one user might ask a simple question while another pastes a 50-page PDF for summarization. Additionally, developers love to experiment, and switching from Claude Haiku to Claude Sonnet changes your pricing tier instantly, often without Finance realizing until the end of the month. Finally, AWS budgets operate at the account level, making it very difficult to see "How much did the Marketing Bot spend vs. the Engineering Bot?" without complex tagging strategies.
Despite its complexity, AWS Bedrock pricing works well for certain scenarios. If you are already standardized on AWS, the "native integration" tax is worth it for the security and compliance benefits like IAM and PrivateLink. For applications with spiky traffic that are used infrequently or unpredictably, the On-Demand model is perfect because you pay nothing when the app sits idle. It allows early-stage projects to launch quickly without managing GPUs or Kubernetes clusters, validating product-market fit before optimizing costs.
As AI workloads mature, teams often encounter structural limitations. At high volumes (millions of requests), the per-token markup becomes expensive compared to owning the compute. Fine-tuning on Bedrock often requires purchasing Provisioned Throughput, which dramatically raises the barrier to entry compared to fine-tuning Llama 3 on your own GPU. Furthermore, multi-team environments lack fine-grained budget enforcement at the application level, leading to "tragedy of the commons" usage where one team drains the shared budget.
TrueFoundry offers an alternative architectural pattern for teams hitting the ceiling of Bedrock's unit economics. Rather than renting the model API with a markup, TrueFoundry orchestrates the deployment of open-source models (Llama 3, Mistral, Qwen) directly onto your own AWS EC2 or EKS clusters.
This unlocks the ability to utilize AWS Spot Instances. By running inference on Spot capacity—spare AWS compute available at steep discounts—you can reduce raw inference costs by 60-70% compared to On-Demand Bedrock rates. TrueFoundry manages the operational risk of Spot interruptions by automating the fallback to On-Demand instances if Spot capacity is reclaimed, ensuring reliability without the 6-month lock-in of Provisioned Throughput.
This is a factual comparison focusing on the economics of serving models.
As AI adoption grows, pricing clarity becomes critical for sustainable scaling. AWS Bedrock pricing shouldn't have to choose between innovation and bankruptcy.
TrueFoundry gives you the power to control your AI spend, offering granular visibility into every model and the flexibility to run workloads on the most cost-effective infrastructure available.
AWS Bedrock pricing varies by foundation model and token usage. While low-volume model inference is accessible, high-scale model inference becomes costly due to managed service markups. TrueFoundry enables better cost optimization by running models on AWS Spot Instances, significantly reducing your total monthly cost compared to Bedrock’s rates.
Yes, AWS Bedrock cost follows a pay-as-you-go pricing model. You are billed for every number of tokens processed for input tokens and output tokens. For heavy generative AI applications, these fees accumulate quickly. TrueFoundry offers a more economical approach by utilizing raw compute rates on your own infrastructure.
Amazon Bedrock pricing does not include a permanent free mode. While a new AWS account might offer general credits, Bedrock charges for model inference immediately. TrueFoundry helps minimize bedrock costs by allowing you to use cheaper spot instances for your specific use cases and batch jobs.
No dedicated free tier exists for AWS Bedrock. Users pay for all text generation and image generation usage. To avoid unpredictable AWS Bedrock costs, teams switch to TrueFoundry, which leverages autoscaling and batch inference to manage generative AI expenses more effectively than the managed service.
TrueFoundry is a superior equivalent to this fully managed service. It allows you to deploy any custom model (such as Mistral AI) or an Amazon Titan model to your own cloud. Unlike Bedrock, it simplifies cost management by using spot instances and data automation, avoiding vendor lock-in for custom model imports.
There is no free version of Amazon Bedrock; you pay to access every foundation model. For better long-term value, TrueFoundry allows you to run open-source models with prompt caching and model distillation on your own hardware, drastically lowering the entry barrier for generative AI adoption.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








The latest news, articles, and resources sent to your inbox








.webp)




.webp)



