














November 5, 2025
|
5 min read

Published: March 13, 2026
%20(11).webp)
Blazingly fast way to build, track and deploy your models!
Prompting, Fine-tuning, and Retrieval-Augmented Generation (RAG) are the most popular LLM learning techniques. Choosing the right technique involves a careful evaluation of your project’s requirements, resources, and desired outcomes.
In the following sections, we’ll dive deeper into each technique, discussing their intricacies, applications, and how to decide which is best suited for your needs

The first step in deciding between prompting, fine-tuning, and RAG is to closely examine the data at your disposal and the specific problem you aim to solve. Consider whether your task involves common knowledge, specialized information, or requires up-to-date data from external sources. The complexity of the problem, the style and tone of the desired output, and the level of customization needed are also critical factors.
If you’re dealing with highly specialized or niche topics, fine-tuning or RAG might be necessary to achieve the desired level of accuracy and relevance. On the other hand, if your project involves more general queries or content creation, prompting could be sufficient and more cost-effective.
The choice between prompting, fine-tuning, and RAG also depends on budgetary constraints. Prompting is generally the least resource-intensive, as it uses the model as-is. Fine-tuning requires additional data and computational resources for training, leading to higher costs. RAG can be resource-intensive as well, especially if it involves setting up and maintaining an external database for retrieval.
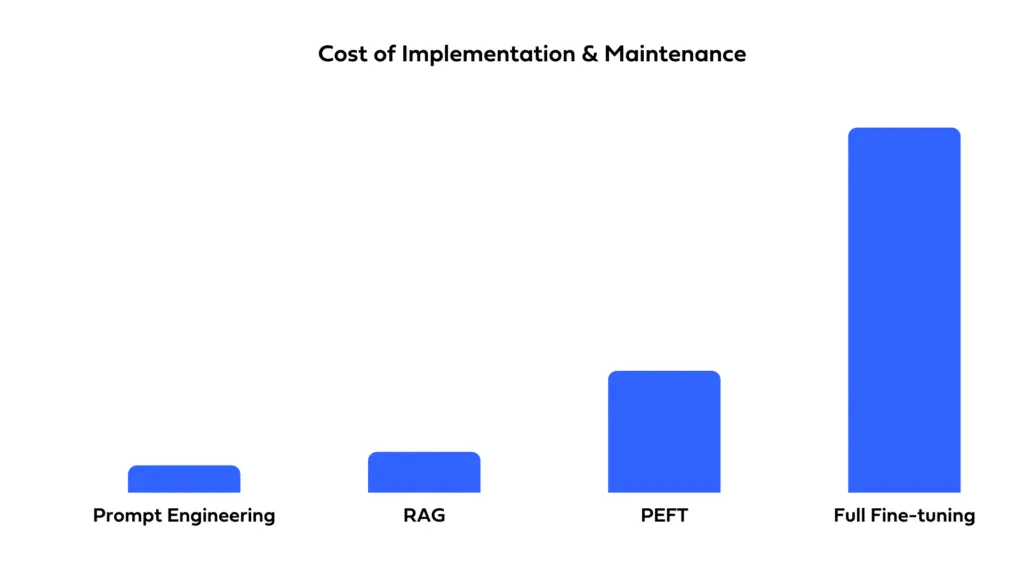
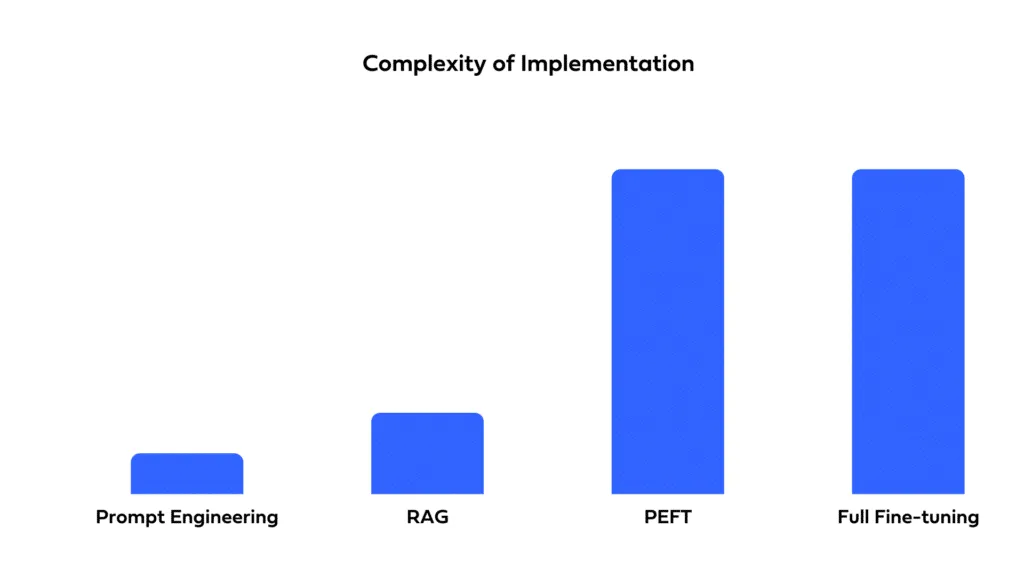
Consider how quickly you need to deploy your solution and the resources you have available. Prompting allows for rapid deployment with minimal setup time. Fine-tuning, while potentially offering better performance, requires time for training and optimization. RAG involves the complexity of integrating external data sources, which can extend development timelines and require specialized expertise.
RAG facilitates source attribution, empowering users to discern the origin of the information utilized in generating the response. Prompting and Finetuning act as a black box making it difficult to trace back the responses.

Prompting is ideal for projects that require quick, cost-effective solutions and can rely on the general knowledge base of pre-trained models. It suits applications like:
While prompting is highly accessible, it may not always provide the precision or customization needed for specialized tasks. The quality of outputs can vary significantly based on the prompt’s design, requiring careful crafting and testing.
Fine-tuning is the method of choice when your project demands a high degree of specificity or needs to align closely with particular styles, tones, or domain-specific knowledge. It’s particularly effective for:
The decision to fine-tune should consider the trade-off between the improved performance and the additional costs and resources required. It’s essential for projects where the value of customization and accuracy outweighs these considerations.
RAG excels in situations where responses must be augmented with the latest information or detailed data from specific domains. It is particularly suitable for:
RAG can offer superior results for complex queries and specialized knowledge areas but comes with increased complexity and resource needs. It’s the right choice when the project’s scope justifies the investment in setting up and maintaining the necessary infrastructure for real-time data retrieval
Prompting is enabled by our LLM Gateway module, which supports workflows often associated with the best prompt engineering tools used for production LLM applications. LLM Gateway offers a unified API that allows users to access various LLM providers, including their own self-hosted models, via a single platform. It features centralized key management, authentication and cost attribution functionalities. Additionally, it provides support for fallback, retries as well as integration with guardrails.
We've templatized the workflow to setup RAG with just a few clicks. Read our blog on how to deploy a RAG based chatbot using TrueFoundry. It takes care of the end to end process of spinning up a vector database, embedding model, LLMs and so on while giving you the right controls to customize the workflow according to your needs.
TrueFoundry has simplified the finetuning process by abstracting away all the intricacies and configuring the right resource configurations for LoRA/QLoRA techniques. You can deploy a fine-tuning Jupyter notebook for experimentation or launch a dedicated fine-tuning job. Please read the detailed guide here.
We at TrueFoundry support all the three LLM learning techniques - prompting, RAG and Fine-tuning in an extremely streamlined manner.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








The latest news, articles, and resources sent to your inbox






.webp)



.webp)
.png)
.webp)
.webp)
.webp)



.webp)


