




November 5, 2025
|
5 min read


احصل على وصول فوري إلى بيئة TrueFoundry مباشرة. انشر النماذج، ووجّه حركة مرور LLM، واستكشف المنصة بالكامل — بيئة الاختبار الخاصة بك جاهزة في ثوانٍ، ولا يلزم وجود بطاقة ائتمان.









Published: July 4, 2026
Blazingly fast way to build, track and deploy your models!
لقد اجتاحت نماذج اللغة الكبيرة مثل ChatGPT ونماذج الانتشار مثل Stable Diffusion العالم في أقل من عام واحد. وبدأت المزيد والمزيد من المؤسسات الآن في الاستفادة من الذكاء الاصطناعي التوليدي لحالات الاستخدام الحالية والجديدة والمثيرة. بينما يمكن لمعظم الشركات البدء مباشرة في استخدام واجهات برمجة التطبيقات (APIs) التي توفرها شركات مثل OpenAI وAnthropic وCohere وغيرها، فإن هذه الواجهات تأتي أيضًا بتكلفة باهظة. على المدى الطويل، ترغب العديد من الشركات في ضبط إصدارات صغيرة إلى متوسطة الحجم من نماذج اللغة الكبيرة مفتوحة المصدر المكافئة مثل Llama وFlan-T5 وFlan-UL2 وGTP-Neo وOPT وBloom وغيرها، مثلما فعلت مشاريع ألبكة و GPT4All هذه المشاريع.
يمكن أن يكون ضبط النماذج الأصغر باستخدام مخرجات من النماذج الأكبر مفيدًا بعدة طرق:
لتمكين كل هذا، أصبحت وحدات معالجة الرسوميات (GPUs) بمثابة أداة عمل أساسية في أي شركة تعمل مع هذه النماذج التأسيسية. مع تزايد أحجام النماذج ووصولها إلى تريليونات المعلمات، أصبح التدريب الموزع عبر وحدات معالجة رسوميات متعددة هو المعيار الجديد ببطء. تقود Nvidia مجال الأجهزة ببطاقاتها الأحدث من سلسلتي Ampere وHopper. تسمح وصلات NVLink وInfiniband عالية السرعة بربط ما يصل إلى 256 وحدة Nvidia A100 أو Nvidia H100 (وحوالي 4 آلاف في مجموعات Super Pod) للتدريب والاستدلال باستخدام نماذج أكبر من أي وقت مضى في أوقات قياسية.
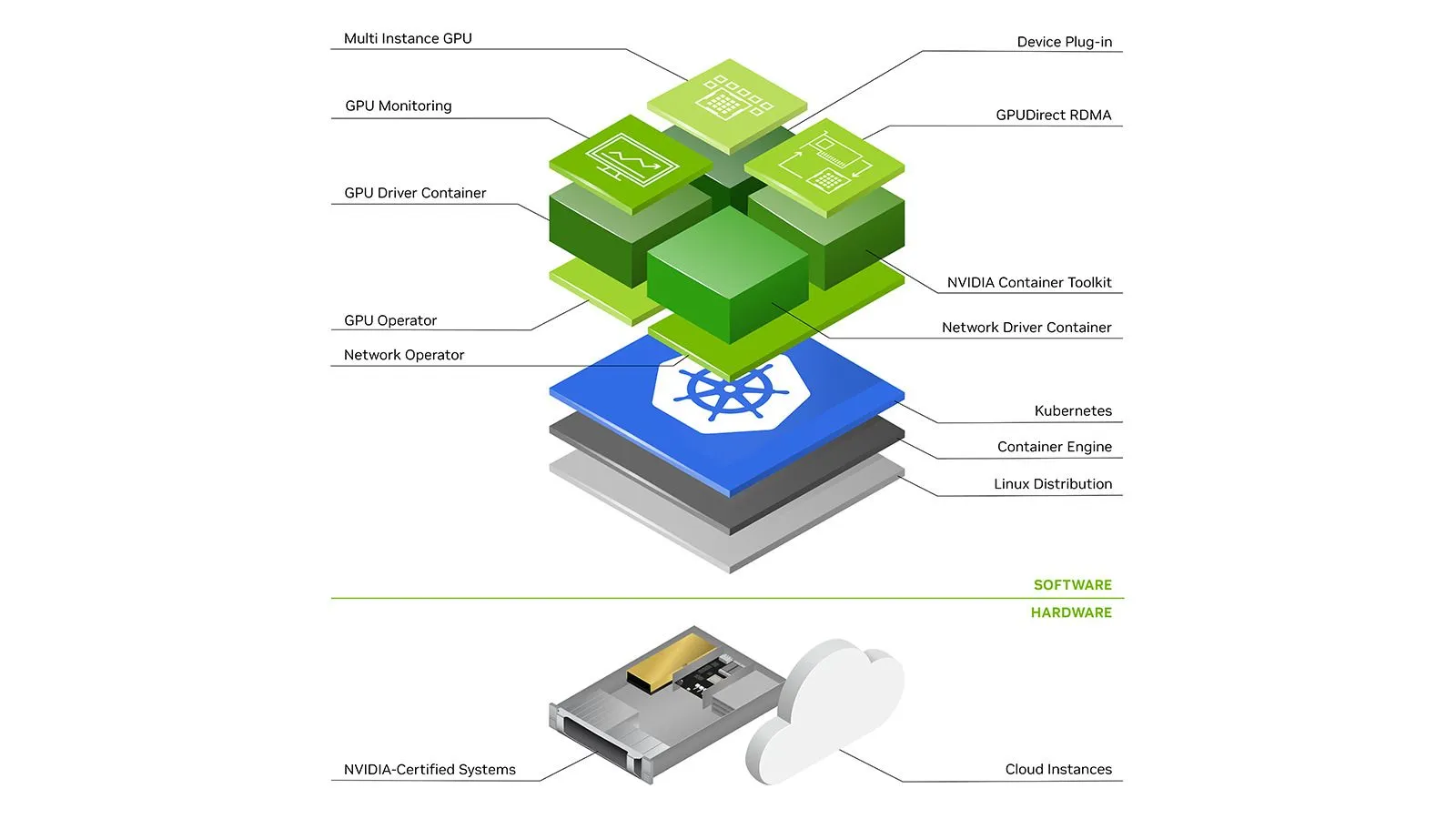
سنتناول الآن المكونات اللازمة لاستخدام وحدات معالجة الرسوميات (GPUs) مع Kubernetes - بشكل أساسي على AWS EKS وGCP GKE (القياسي أو Autopilot) ولكن المكونات المذكورة ضرورية على أي مجموعة K8s.
يمتلك مزود الخدمة السحابية الخاص بك أجهزة افتراضية لوحدات معالجة الرسوميات (GPU VMs)، كيف يمكننا إحضارها إلى مجموعة K8s؟ إحدى الطرق هي تكوين مجموعات العقد لوحدات معالجة الرسوميات (GPU Nodepools) يدويًا بحجم ثابت أو باستخدام موسع الكتلة التلقائي الذي يمكنه جلب عقد GPU عند الحاجة والتخلي عنها عند عدم الحاجة. ومع ذلك، لا يزال هذا يتطلب تهيئة يدوية لعدة مجموعات عقد مختلفة. الحل الأفضل هو تهيئة أنظمة التوفير التلقائي مثل AWS Karpenter أو موفري العقد التلقائيين في GCP. نتحدث عن هذه في مقالنا السابق: التوسيع التلقائي للمجموعات للسحابات الثلاث الكبرى ☁️
apiVersion: karpenter.sh/v1alpha5
kind: Provisioner
metadata:
name: gpu-provisioner
namespace: karpenter
spec:
weight: 10
kubeletConfiguration:
maxPods: 110
limits:
resources:
cpu: "500"
requirements:
- key: karpenter.sh/capacity-type
operator: In
values:
- spot
- on-demand
- key: topology.kubernetes.io/zone
operator: In
values:
- ap-south-1
- key: karpenter.k8s.aws/instance-family
operator: In
values:
- p3
- p4
- p5
- g4dn
- g5
taints:
- المفتاح: "nvidia.com/gpu"
التأثير: "NoSchedule"
مرجع المزود:
الاسم: default
مدة البقاء بالثواني بعد التفريغ: 30
مثال على إعدادات موفر العقد التلقائي لـ GCP
حدود الموارد:
- نوع المورد: 'cpu'
الحد الأدنى: 0
الحد الأقصى: 1000
- نوع المورد: 'memory'
الحد الأدنى: 0
الحد الأقصى: 10000
- نوع المورد: 'nvidia-tesla-v100'
الحد الأدنى: 0
الحد الأقصى: 4
- نوع المورد: 'nvidia-tesla-t4'
الحد الأدنى: 0
الحد الأقصى: 4
- نوع المورد: 'nvidia-tesla-a100'
الحد الأدنى: 0
الحد الأقصى: 4
مواقع التوفير التلقائي:
- us-central1-c
الإدارة:
الإصلاح التلقائي: true
الترقية التلقائية: true
تكوين المثيل المدرع:
تمكين التمهيد الآمن: true
تمكين مراقبة التكامل: true
حجم القرص بالجيجابايت: 100
تجدر الإشارة هنا إلى أنه يمكننا أيضًا تكوين أدوات التزويد لدينا لاستخدام الفوري من المثيلات للحصول على توفير في التكاليف يتراوح بين 30-90% للتطبيقات عديمة الحالة.
لكي تستخدم أي آلة افتراضية وحدات معالجة الرسوميات (GPUs)، يجب تثبيت برامج التشغيل الخاصة بها على المضيف. لحسن الحظ، في كل من AWS EKS و GCP GKE، يتم تهيئة العقد مسبقًا بإصدارات معينة من برامج تشغيل Nvidia.
لأن كل إصدار CUDA أحدث يتطلب إصدار برنامج تشغيل أدنى أعلى، قد ترغب حتى في التحكم في إصدار برنامج التشغيل لجميع العقد. يمكن تحقيق ذلك عن طريق تزويد العقد بصور مخصصة لا تحتوي على برنامج التشغيل والسماح لـ Nvidia gpu-operator تثبيت إصدار محدد. ومع ذلك، قد لا يكون هذا مسموحًا به في جميع موفري الخدمات السحابية، لذا كن على دراية بإصدارات برامج التشغيل على العقد الخاصة بك لتجنب مشاكل التوافق.
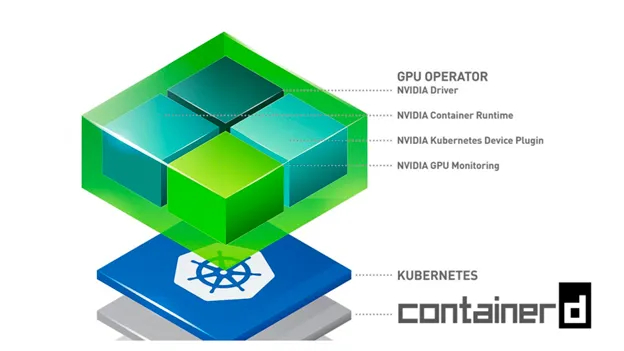
نتحدث عن الـ gpu-operator لاحقًا أدناه.
في Kubernetes، بما أن كل شيء يعمل داخل الحاويات (Pods) (مجموعة من الحاويات)، فإن مجرد تثبيت برامج التشغيل على المضيف لا يكفي. توفر Nvidia مكونًا مستقلاً يسمى nvidia-container-toolkit يقوم بتثبيت خطاطيف لـ containerd runC لجعل برامج تشغيل ووحدات معالجة الرسوميات (GPU) الخاصة بالمضيف متاحة للحاويات التي تعمل على العقدة. راجع هذه المقالة للحصول على شرح أكثر تفصيلاً.
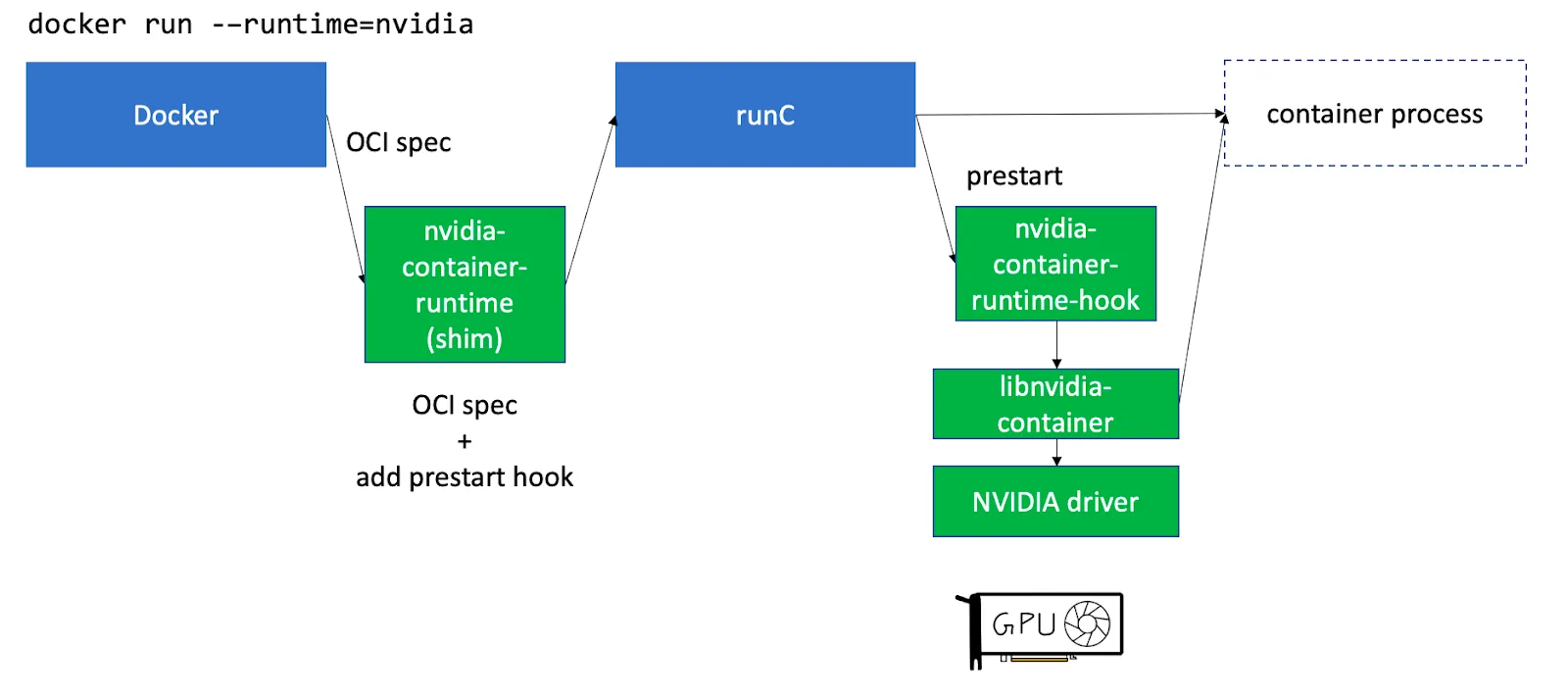
nvidia-container-toolkit يمكن تثبيته ليعمل كـ Daemonset على عقد وحدات معالجة الرسوميات (GPU).
وجود وحدات معالجة الرسوميات (GPUs) على العقدة لا يكفي، فجدولة Kubernetes تحتاج إلى معرفة أي عقدة لديها كم عدد وحدات معالجة الرسوميات المتاحة. يمكن القيام بذلك باستخدام Device Plugin. يسمح مكون الجهاز الإضافي (Device Plugin) بالإعلان عن موارد الأجهزة المخصصة لمستوى التحكم، على سبيل المثال nvidia.com/gpu . نشرت Nvidia مكون إضافي للجهاز يعلن عن وحدات معالجة رسوميات (GPUs) قابلة للتخصيص على عقدة. يمكن تشغيل هذا المكون الإضافي مرة أخرى كـ Daemonset.
بمجرد تهيئة المكونات المذكورة أعلاه، نحتاج إلى إضافة بعض الأمور إلى مواصفات الـ pod لجدولتها على عقدة GPU - وبشكل رئيسي الموارد , التقارب و التسامحات
على سبيل المثال، على GCP GKE يمكننا القيام بما يلي:
spec:
# نحدد عدد وحدات معالجة الرسوميات (GPUs) التي نريدها للـ pod
resources:
limits:
nvidia.com/gpu: 2
# تساعدنا التقاربات في وضع الـ pod على عقد GPU
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
# تحديد عائلة المثيل المطلوبة
- operator: In
key: cloud.google.com/machine-family
values:
- a2
# تحديد نوع وحدة معالجة الرسوميات (GPU) المطلوبة
- operator: In
key: cloud.google.com/gke-accelerator
values:
- nvidia-tesla-a100
# تحديد أننا نريد جهازًا افتراضيًا فوريًا (Spot VM)
- operator: In
key: cloud.google.com/gke-spot
values:
- "true"
tolerations:
# الأجهزة الافتراضية الفورية (Spot VMs) تحتوي على "taint"، لذا نذكر "toleration" لها
- key: cloud.google.com/gke-spot
المشغل: يساوي
القيمة: "true"
التأثير: عدم الجدولة
# نضع علامة تلوث على عقد GPU، لذا نذكر تسامحًا لذلك
- المفتاح: nvidia.com/gpu
المشغل: موجود
التأثير: عدم الجدولة
resources.limits القسملاحظ أن هذه التكوينات ستختلف بناءً على طرق التزويد ومقدمي الخدمات السحابية التي تستخدمها (على سبيل المثال، Karpenter على AWS مقابل NAP على GKE)
تعد مراقبة مقاييس وحدة معالجة الرسوميات (GPU) مثل الاستخدام، واستهلاك الذاكرة، وسحب الطاقة، ودرجة الحرارة، وما إلى ذلك، أمرًا مهمًا لضمان سير العمل بسلاسة وكذلك لإجراء المزيد من التحسينات.
لحسن الحظ، لدى Nvidia مكون يسمى dcgm-exporter يمكن تشغيله كـ Daemonset على عقد GPU وينشر المقاييس عند نقطة نهاية. يمكن بعد ذلك جمع هذه المقاييس باستخدام Prometheus واستهلاكها. فيما يلي مثال لتكوين الجمع (scrape config):
- اسم_المهمة: gpu-metrics
فترة_التجميع: 15 ثانية
مهلة_التجميع: 10 ثوانٍ
مسار_المقاييس: /metrics
المخطط: http
إعدادات_اكتشاف_خدمة_كوبيرنيتيس:
- الدور: نقاط_النهاية
مساحات_الأسماء:
الأسماء:
- <dcgm-exporter-namespace-here>
إعدادات_إعادة_التسمية:
- تسميات_المصدر: [__meta_kubernetes_pod_node_name]
الإجراء: استبدال
التسمية_المستهدفة: kubernetes_node
ومع ذلك، لاحظ أن dcgm-exporter يحتاج إلى التشغيل مع hostIPC: true وامتيازات securityContext. هذا جيد لـ EKS و GKE Standard. ومع ذلك، لا يسمح GKE Autopilot بهذا الوصول، وبدلاً من ذلك، ينشر GKE المقاييس على الـ مُعد مسبقًا nvidia-device-plugin Daemonsets والتي يمكن جمعها أو عرضها في GCP Cloud Monitoring.
AWS EKSGCP GKE StandardGCP GKE AutopilotالتوفيرKarpenter / يدويGCP Node Auto Provisioner / يدويالتوفير التلقائيبرامج التشغيلمثبت مسبقًا/التثبيت عبر gpu-operatorمُعد مسبقًا مُعد مسبقًا مجموعة أدوات الحاوياتnvidia-container-toolkitعبر gpu-operatorمُعد مسبقًا مُعد مسبقًا مكون الجهاز الإضافيnvidia-device-pluginعبر gpu-operatorDaemonset مُعد مسبقًا Daemonset مُعد مسبقًا المقاييسnvidia-dcgm-exporterعبر gpu-operatorمستقل nvidia-dcgm-exporter / كشط مخصص
الـ gpu-operator المذكور أعلاه لمعظم الأجزاء على AWS EKS هو مجموعة من مكونات Nvidia المستقلة مثل برامج التشغيل (drivers)، ومجموعة أدوات الحاويات (container-toolkit)، والمكون الإضافي للجهاز (device-plugin)، ومصدر المقاييس (metrics exporter)، وغيرها، وكلها مدمجة ومُكوّنة للاستخدام معًا عبر مخطط Helm واحد. الـ gpu-operator يقوم بتشغيل pod رئيسي على مستوى التحكم يمكنه اكتشاف عقد GPU في المجموعة. عند اكتشاف عقدة GPU، يقوم بنشر Daemonset عامل يقوم بجدولة pods إضافية لتثبيت برامج التشغيل (drivers)، ومجموعة أدوات الحاويات (container toolkit)، والمكون الإضافي للجهاز (device-plugin)، ومجموعة أدوات CUDA (CUDA toolkit)، ومصدر المقاييس (metrics exporter)، والمُدققات (validators) اختياريًا. يمكنك قراءة المزيد عنه هنا.
بشكل عام، من الممكن تثبيت مجموعة أدوات CUDA على الجهاز المضيف وجعلها متاحة للـ pod عبر تحميل وحدة التخزين (volume mounting)، ومع ذلك، نجد أن هذا يمكن أن يكون هشًا للغاية لأنه يتطلب التلاعب بـ PATH و LD_LIBRARY_PATH المتغيرات. علاوة على ذلك، يجب أن تستخدم جميع الـ pods على نفس العقدة نفس إصدار مجموعة أدوات CUDA، وهو ما يمكن أن يكون مقيدًا للغاية. لذلك، من الأفضل وضع مجموعة أدوات CUDA (أو أجزاء منها فقط) داخل صورة الحاوية.
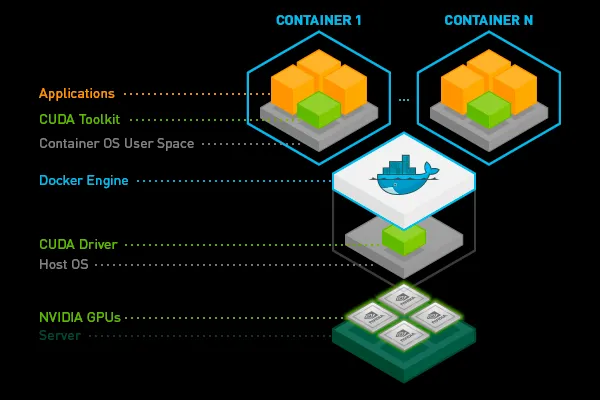
يمكنك البدء من الصور المُنشأة مسبقًا والمقدمة من قبل Nvidia أو التعلم العميق المفضل لديك إطار العمل أو إضافته باستخدام سطر واحد على منصة Truefoundry
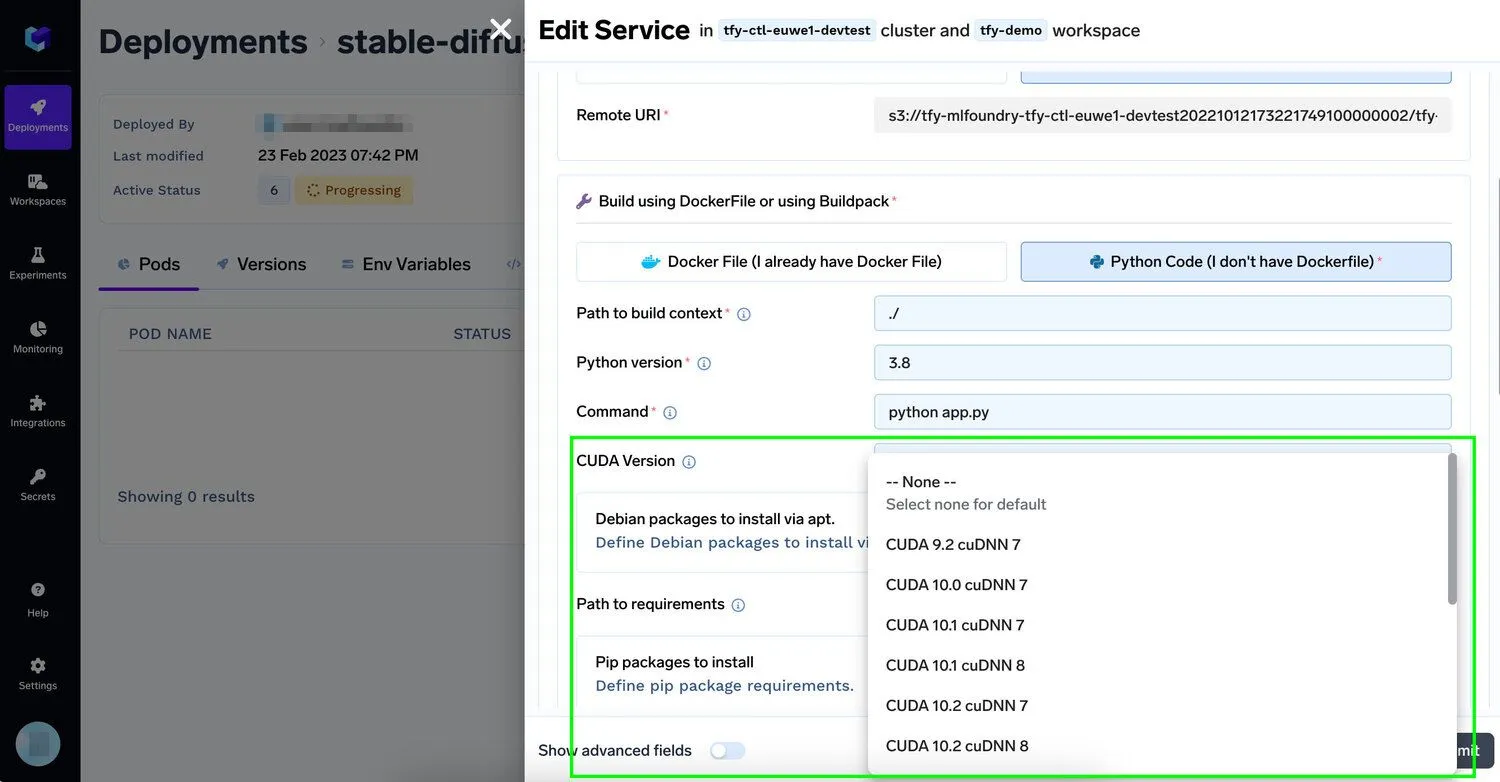
لتمكين المؤسسات من ضبط ونشر نماذج الذكاء الاصطناعي التوليدي الخاصة بها بشكل أسرع على بنيتها التحتية الحالية، تتيح منصة TrueFoundry للمطورين إضافة وحدة أو أكثر من وحدات معالجة الرسوميات (GPUs) من Nvidia إلى تطبيقاتهم بأقل جهد ممكن، مع دعم سير العمل المستخدمة جنبًا إلى جنب مع أفضل أدوات هندسة الأوامر (prompt engineering). يحتاج المطورون فقط إلى تحديد عدد النسخ التي يحتاجونها من بعض أفضل وحدات معالجة الرسوميات (GPUs) للتعلم الآلي مثل V100، P100، A100 40GB، A100 80GB (المثالية للتدريب) أو T4، A10 (المثالية للاستدلال)، ونحن نتولى الباقي. اقرأ المزيد على وثائقنا. مع انتقال أعباء عمل الذكاء الاصطناعي المدعومة بوحدات معالجة الرسوميات (GPUs) إلى مرحلة الإنتاج، يصبح هذا النوع من التحكم في البنية التحتية مهمًا أيضًا لمنصات أمان الذكاء الاصطناعيالأوسع، حيث يجب أن تعمل عزل الحوسبة، وحوكمة الوصول، وإمكانية مراقبة أعباء العمل معًا.
وحدات معالجة الرسوميات (GPUs) هي تقنية رائعة وهذه مجرد البداية بالنسبة لنا. نحن نعمل بنشاط على المشكلات التالية:
إذا كان أي من هذا يبدو مثيراً للاهتمام، يرجى التواصل معنا للعمل لبناء أفضل منصة MLOps.
TrueFoundry هي منصة كخدمة (PaaS) لنشر تعلم الآلة (ML) تعمل فوق Kubernetes لتسريع سير عمل المطورين، مع منحهم مرونة كاملة في اختبار ونشر النماذج، وضمان الأمان والتحكم الكاملين لفريق البنية التحتية. من خلال منصتنا، نمكّن فرق تعلم الآلة من نشر ومراقبة النماذج في 15 دقيقة بموثوقية 100%، وقابلية للتوسع، والقدرة على التراجع في ثوانٍ - مما يسمح لهم بتوفير التكلفة وإطلاق النماذج إلى الإنتاج بشكل أسرع، وتحقيق قيمة تجارية حقيقية.
ناقش تحديات مسار عمل تعلم الآلة (ML Pipeline) الخاص بك معنا هنا
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








أحدث الأخبار والمقالات والموارد تصلك مباشرة إلى بريدك الوارد
© 2026 جميع الحقوق محفوظة.











.png)
.webp)










.webp)
