




July 4, 2026
|
5 min read


احصل على وصول فوري إلى بيئة TrueFoundry مباشرة. انشر النماذج، ووجّه حركة مرور LLM، واستكشف المنصة بالكامل — بيئة الاختبار الخاصة بك جاهزة في ثوانٍ، ولا يلزم وجود بطاقة ائتمان.









Published: July 4, 2026

Blazingly fast way to build, track and deploy your models!
في معظم برامج الذكاء الاصطناعي للمؤسسات، تأتي لحظة يظهر فيها عبء عمل لا يمكنه إرسال بياناته إلى واجهة برمجة تطبيقات تابعة لجهة خارجية — مثل مجموعة بيانات منظمة، أو متطلب سيادة، أو منحنى تكلفة أصبح مخيفًا على نطاق واسع. الحل هو نموذج مفتوح الوزن تديره بنفسك. السبب الذي يجعل الفرق تخشى ذلك ليس النموذج نفسه؛ بل لأن الاستضافة الذاتية تعني عادةً مكدسًا (stack) ثانيًا ومختلفًا — مثل واجهة برمجة تطبيقات غير تابعة لـ OpenAI، وطبقة خدمة، وعمليات وحدات معالجة الرسوميات (GPU) — يتم ربطها بمنصة مبنية حول واجهات برمجة التطبيقات التجارية. تشرح هذه المقالة كيف تعمل البوابة على تبسيط ذلك، مما يجعل نموذج Llama أو Mistral المستضاف ذاتيًا قابلاً للدمج بسهولة مع النماذج التجارية التي تستخدمها بالفعل.
رافي، مهندس منصة تعلم آلة، تلقى الطلب الذي كان يتوقعه: عبء عمل جديد سيعالج سجلات لا يمكنها، بموجب السياسة، مغادرة سحابة الشركة. لم تكن أي واجهة برمجة تطبيقات تجارية خيارًا. كان النموذج مفتوح الوزن الذي يعمل في شبكتهم الافتراضية الخاصة (VPC) هو الحل الواضح — لكن قلب رافي غاص قليلاً، لأن التطبيق الذي يحتاجه كان مكتوبًا باستخدام واجهة برمجة تطبيقات OpenAI، ولم يكن لدى الفريق مكدس خدمة، وكان بإمكانه بالفعل تخيل عالم موازٍ من حزمة تطوير برامج (SDK) ثانية، ومجموعة ثانية من لوحات المعلومات، ومشكلة توسيع تلقائي لوحدات معالجة الرسوميات (GPU) لم يحلها أحد. كان النموذج هو القرار السهل. أما المكدس المحيط به فكان هو مصدر القلق.
ما غير أسبوع رافي هو إدراكه أن النموذج المستضاف ذاتيًا لا يجب أن يكون مكدسًا مختلفًا على الإطلاق. إذا كان يقع خلف نفس البوابة مثل النماذج التجارية، ويتحدث نفس واجهة برمجة التطبيقات المتوافقة مع OpenAI، فبالنسبة للتطبيق كان مجرد اسم نموذج آخر — وبالنسبة للمنصة كان نقطة نهاية أخرى تحكمها نفس القواعد. تم تلبية متطلب السيادة دون الحاجة إلى فصل (forking) البنية. تشرح هذه المقالة كيف يعمل ذلك، وأين تكمن الهندسة الحقيقية.
نادرًا ما تكون الاستضافة الذاتية لنموذج مفتوح الوزن تتعلق بالجودة — فواجهات برمجة التطبيقات الرائدة ممتازة وتتحسن باستمرار. إنها تتعلق بأربعة أمور أخرى. السيادة: بعض البيانات لا يمكنها قانونيًا أو تعاقديًا مغادرة بيئتك، وهو ما يحققه نموذج يعمل في شبكتك الافتراضية الخاصة (VPC) أو في موقعك (on-prem) بطبيعته. التكلفة على نطاق واسع: بعد حجم ثابت معين، يمكن لوحدات معالجة الرسوميات (GPUs) المستهلكة أن تقلل من تكلفة التسعير لكل رمز (token)، خاصة لأعباء العمل عالية الإنتاجية والقابلة للتنبؤ. التحكم: يمكنك اختيار إصدار النموذج، ويمكنك ضبطه بدقة (fine-tune) على بيانات خاصة، ولست خاضعًا لمزود يقوم بإيقاف أو تغيير نموذج دون علمك. التوفر: لم يعد مسار الاستدلال الخاص بك مرتبطًا بشكل مباشر بوقت تشغيل مزود واجهة برمجة تطبيقات النموذج — على الرغم من أنه يعتمد الآن على البنية التحتية الخاصة بك وسلسلة توريد النشر.
المقابل الصادق هو أنك الآن تمتلك عمليات الاستدلال: سعة وحدات معالجة الرسوميات (GPU)، ومكدس الخدمة، والتوسع، والموثوقية — وهو عمل تخفيه واجهة برمجة التطبيقات التجارية بالكامل. تستحق الاستضافة الذاتية العناء عندما يكون أحد هذه الدوافع الأربعة حقيقيًا وتكون التكلفة التشغيلية محتواة. تنتهي معظم المؤسسات إلى حل هجين: واجهات برمجة تطبيقات تجارية للحركة العامة، ونماذج مستضافة ذاتيًا للشرائح السيادية أو ذات الحجم الكبير. الهدف ليس استبدال أحدهما بالآخر؛ بل تشغيل كليهما دون الحاجة إلى تشغيل كل شيء مرتين.
يستحق التخصيص أن يُفصل عن تلك القائمة، لأنه غالبًا ما يكون الدافع الذي يدفع الفريق نحو النماذج مفتوحة الوزن على وجه التحديد. تمنحك واجهة برمجة التطبيقات التجارية نموذجًا دربه شخص آخر للجميع؛ بينما النموذج مفتوح الوزن يمكنك تكييفه مع مجالك، وتنسيقاتك، ونبرتك، وحالاتك الخاصة عن طريق الضبط الدقيق (fine-tuning) على بيانات لا يمكنك أو لن ترسلها إلى أي مكان. للمهام الضيقة والمتكررة، يمكن لنموذج مفتوح أصغر ومُضبط بدقة أن يضاهي أو يتفوق على نموذج عام أكبر بكثير بجزء بسيط من تكلفة الخدمة — مما يعيد دمج دافع التخصيص في دافع التكلفة. المشكلة هي أن الضبط الدقيق (fine-tuning) هو مسار عمل خاص به: إعداد البيانات، وتشغيل التدريب، والتقييم، وتحديد الإصدارات، ثم خدمة النتيجة مثل أي نموذج آخر. تدعم TrueFoundry الضبط الدقيق بدون تعليمات برمجية (no-code) ومع تعليمات برمجية كاملة (full-code) جنبًا إلى جنب مع مكدس الخدمة الخاص بها، بحيث يصل النموذج المُضبط إلى نفس نقطة نهاية البوابة مثل أي شيء آخر بدلاً من أن يصبح كيانًا منفصلاً يجب عليك تشغيله يدويًا. النقطة ليست أن الضبط الدقيق يستحق العناء دائمًا — فغالبًا ما لا يكون كذلك، وغالبًا ما يفوز نموذج أساسي جيد مع توجيه قوي — ولكن عندما يكون كذلك، فإن امتلاك الأوزان هو ما يجعله ممكنًا على الإطلاق.
هناك تحذير يجب أن يكون جزءًا من هذا القرار، وليس بعده: النموذج مفتوح الوزن لا يعني أنه خالٍ من الالتزامات. قبل الاستضافة الذاتية أو الضبط الدقيق، تحقق من ترخيص النموذج، وسياسة الاستخدام المقبول، وشروط إعادة التوزيع، ومتطلبات الإسناد، وأي قيود على الاستخدام المنظم أو التجاري — فبعض النماذج مفتوحة الوزن الشائعة تحمل حدودًا للاستخدام أو قيودًا على مجال الاستخدام تهم على مستوى المؤسسة. تعامل مع مراجعة الترخيص كجزء من قائمة التحقق من النشر، وليس كحاشية سفلية يتم اكتشافها بعد أن يكون النموذج قيد الإنتاج بالفعل.
كان قلق رافي مبررًا، لأن الطريقة الساذجة للاستضافة الذاتية تنتج بالضبط ذلك المكدس الثاني. يعرض النموذج مفتوح الوزن شكل واجهة برمجة التطبيقات الخاصة به، لذلك يحتاج التطبيق إلى مسار كود خاص به. يحتاج إلى محرك خدمة، وهو بيئة تشغيلية خاصة به. يحتاج إلى التحجيم التلقائي لوحدات معالجة الرسوميات (GPU)، والذي لا يشبه على الإطلاق تحجيم خدمة ويب عديمة الحالة. ويحتاج إلى إمكانية المراقبة الخاصة به، لأن لوحات معلومات واجهة برمجة التطبيقات التجارية لا تراه. اضرب ذلك في عدد قليل من النماذج وستحصل على منصة موازية وظيفتها الوحيدة هي أن تكون مختلفة عن تلك التي تديرها بالفعل.
الفكرة التي تبدد هذا هي أن لا شيء تقريبًا من هذا الاختلاف يحتاج إلى الوصول إلى التطبيق أو واجهة التحكم بالمنصة. محرك الخدمة والتحجيم التلقائي لوحدات معالجة الرسوميات حقيقيان ولا مفر منهما — إنهما العمل الحقيقي للاستضافة الذاتية. لكن شكل واجهة برمجة التطبيقات، والتوجيه، والحوكمة، وإمكانية المراقبة يمكن جعلها مطابقة للمسار التجاري بوضع نفس البوابة أمامها. بقية هذا المنشور يفصل الاختلاف الجوهري (الخدمة، وحدات معالجة الرسوميات) عن الاختلاف العرضي (كل ما يمكن للبوابة استيعابه).
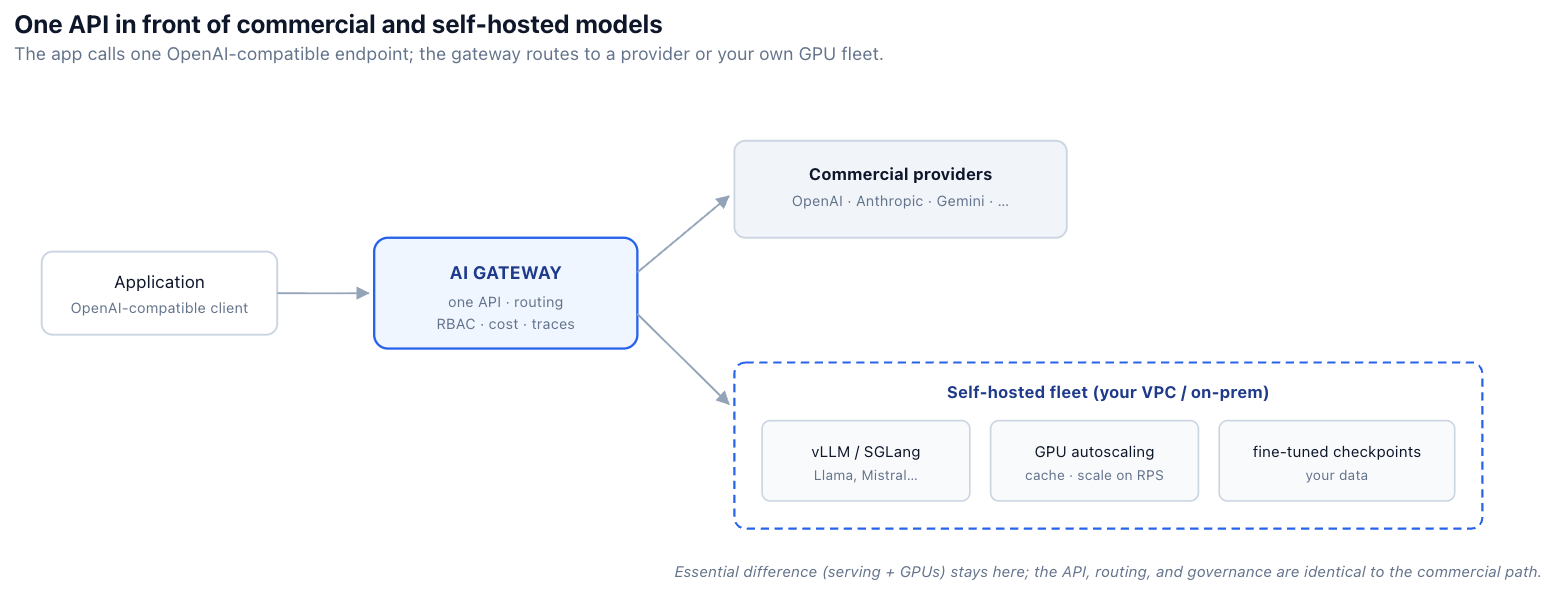
الخطوة التي تجعل الاستضافة الذاتية سهلة هي عرض النموذج المستضاف ذاتيًا من خلال نفس واجهة برمجة التطبيقات المتوافقة مع OpenAI التي يستخدمها التطبيق بالفعل. عندما يستجيب نموذج Llama المستضاف ذاتيًا لنفس شكل الطلب مثل النموذج التجاري، فإن التبديل بينهما هو تغيير في التكوين، وليس تغييرًا في الكود — ويتم تطبيق التوجيه، والعودة الاحتياطية، والتحكم في الوصول المستند إلى الدور (RBAC)، والميزانيات، والتتبع بشكل موحد لأنها، من منظور البوابة، مجرد نموذج آخر خلف نفس الواجهة.
نفس العميل، نفس الاستدعاء — يتغير اسم النموذج فقط (توضيحي)
# Commercial model:
client.chat.completions.create(model="commercial-chat-model", messages=msgs)
# Self-hosted open-weight model — same API, same code, different name:
client.chat.completions.create(model="llama-3-70b-internal", messages=msgs)
# The gateway resolves the name to a commercial provider or your GPU fleet,
# and applies the same routing, RBAC, budgets, and tracing either way.هذا هو نفس التوحيد الذي تغطيه منشور التوجيه ، مطبقًا على حالة الاستضافة الذاتية: يتم فصل التطبيق عن مكان تشغيل النموذج فعليًا. تشير حمولة عمل رافي المنظمة إلى اسم نموذج مستضاف ذاتيًا؛ وكل شيء آخر في منصته يستمر في العمل دون تغيير. تم تصميم بوابة TrueFoundry للذكاء الاصطناعي لتكون بالضبط هذه الواجهة المركزية لكل من النماذج المستضافة ذاتيًا ونماذج الطرف الثالث.
هذا هو الاختلاف الذي يخصك حقًا. النموذج مفتوح الوزن لا يخدم نفسه؛ بل يعمل داخل محرك استدلال، والمحرك الذي تختاره يؤثر بشكل كبير على الإنتاجية، وزمن الاستجابة، وكفاءة الذاكرة. شاع vLLM التجميع المستمر والانتباه المصفح لتحقيق إنتاجية عالية؛ ويتفوق SGLang في أعباء العمل المنظمة وعالية التزامن؛ وTGI هو خادم ناضج ومنتشر على نطاق واسع؛ ويستخرج TRT-LLM (Triton) أداءً خاصًا بالأجهزة من وحدات معالجة الرسوميات (GPUs) من NVIDIA. لا يوجد أفضل حل عالميًا.
الانضباط المهم هو قياس الأداء: شغّل نموذجك الفعلي، بأطوال تسلسلاتك وتزامنك الفعليين، على المحركات ووحدات معالجة الرسوميات المرشحة، واختر بناءً على الأرقام بدلاً من السمعة. وثائق TrueFoundry الخاصة بـ نشر نماذج اللغات الكبيرة تدرج vLLM وSGLang وTRT-LLM كخوادم نماذج مدعومة (يظهر TGI وTriton ضمن الواجهات الخلفية المستضافة ذاتيًا للبوابة)، وتهدف المنصة إلى اختيار تكوين GPU معقول لنموذج معين تلقائيًا — مما يحول سؤال "أي محرك وكم عدد وحدات معالجة الرسوميات" من مشروع بحثي إلى خيار تتحقق منه مقابل معايير الأداء الخاصة بك. المحرك هو تعقيد أساسي؛ والهدف هو جعل اختياره وتشغيله أمرًا روتينيًا.
التحجيم التلقائي لنموذج لغة كبير (LLM) مستضاف ذاتيًا لا يشبه التحجيم التلقائي لخدمة ويب، لسبب جوهري واحد: الأوزان ضخمة — تتراوح من بضعة غيغابايت إلى أكثر من مائة بكثير. سيقضي أداة تحجيم تلقائي ساذجة تقوم بتنزيل نموذج بحجم 100 غيغابايت في كل مرة تضيف فيها نسخة متماثلة دقائق وتكاليف شبكة باهظة قبل أن يقدم الـ pod الجديد رمزًا واحدًا، مما يجعل التوسع أثناء ذروة حركة المرور عديم الفائدة تقريبًا. البدء البارد هو المشكلة التشغيلية الأساسية للاستدلال المستضاف ذاتيًا.
الإصلاحات غير جذابة ولكنها حاسمة. يقوم التخزين المؤقت للنموذج بتنزيل الأوزان مرة واحدة وتركيبها على كل pod، بحيث تبدأ النسخة المتماثلة الجديدة من نسخة محلية بدلاً من تنزيل جديد. يسحب تدفق الصور صورة الخدمة أسرع بكثير من السحب البارد. تحافظ وحدات تخزين النماذج المشتركة على الأوزان خارج كل صورة تمامًا. معًا، يمكن لهذه الإجراءات أن تنقل البدء البارد من "تنزيل كل شيء من الصفر" نحو مسار توسع سريع بما يكفي لتتبع التحجيم التلقائي القائم على RPS للطلب — على الرغم من أن وقت البدء الفعلي لا يزال يعتمد على حجم النموذج، وفئة التخزين، وموقع السجل، ودفء العقدة، وجدولة GPU. وثائق TrueFoundry تصف التخزين المؤقت للنموذج (الأوزان التي يتم تنزيلها مرة واحدة وتركيبها على كل pod)، وتدفق الصور لسحب صور vLLM وSGLang بشكل أسرع بكثير، ووحدات التخزين المشتركة لهذا السبب تحديدًا؛ إنه الفرق بين التحجيم التلقائي الفعال والتحجيم التلقائي النظري.
تنقل الاستضافة الذاتية أيضًا مسؤولية سلسلة التوريد إليك. أصبحت الأوزان، وصورة الخدمة، واعتمادياتها الآن عناصر تملكها وتشحنها. ثبّت إصدارات النموذج والصورة بدلاً من تتبع علامة متحركة، وتحقق من المجاميع الاختبارية أو التوقيعات حيثما يوفرها المصدر، وتحكم في من يمكنه نشر نقاط فحص النموذج وصور الخدمة إلى سجلك، وافحص تلك الصور مثل أي حاوية إنتاج أخرى، واحتفظ بمسار للعودة إلى إصدار سابق لكل من المحرك والأوزان. تتحكم البوابة في من يمكنه استدعاء النموذج؛ وهذا هو الانضباط الذي يحكم ما تقوم بتشغيله فعليًا خلفها.
نموذج مستضاف ذاتيًا كنشر مُدار (إعداد توضيحي)
name: llama-3-70b-internal
model: meta-llama/Llama-3-70B # from Hugging Face / private registry
server: vllm # or sglang / tgi / trt-llm — benchmark first
gpu: { type: H100, count: 2 }
cache: shared_volume # download once, mount to all pods
autoscaling:
metric: rps # scale on requests/sec
min_replicas: 1
max_replicas: 8
scale_to_zero_after: 30m # idle policy — release GPUs when unused
تتيح الاستضافة الذاتية تحسينًا تخفيه واجهات برمجة التطبيقات التجارية عنك إلى حد كبير: التحكم في كيفية توجيه الطلبات إلى وحدات معالجة الرسوميات (GPUs). عندما يعالج نموذج ما تسلسلاً، فإنه يبني ذاكرة تخزين مؤقت للمفتاح-القيمة لحسابات الانتباه الخاصة به. إذا كان الطلب التالي يشترك في بادئة — نفس المطالبة النظامية، نفس المحادثة حتى الآن — فإن توجيهه إلى نفس مثيل وحدة معالجة الرسوميات يتيح للمحرك إعادة استخدام هذا الحساب المخزن مؤقتًا بدلاً من إعادة حسابه، مما يقلل زمن الاستجابة بشكل كبير في حركة المرور الكثيفة بالبادئات.
يتطلب تحقيق هذه الفائدة توجيهًا ثابتًا (لاصقًا) مدركًا للبادئة: تقوم البوابة بتوجيه الطلبات ذات البادئة المشتركة إلى نفس المثيل بدلاً من توزيعها بالتناوب. تصف وثائق TrueFoundry وثائق هذا بالضبط — توجيهًا ثابتًا يرسل الطلبات ذات البادئة نفسها إلى نفس جهاز وحدة معالجة الرسوميات للاستفادة من تحسين ذاكرة التخزين المؤقت للمفتاح-القيمة (KV-cache) — وهو النظير المستضاف ذاتيًا على مستوى وحدة معالجة الرسوميات للتخزين المؤقت الدلالي على مستوى البوابة في منشور التخزين المؤقتالخاص بنا. أحدهما يعيد استخدام الحساب داخل محرك الخدمة؛ والآخر يعيد استخدام الاستجابات الكاملة عند البوابة. في أعباء العمل القائمة على المحادثة أو المطالبات النظامية المشتركة، يتضاعف تأثير الاثنين.
بمجرد أن تعمل النماذج المستضافة ذاتيًا والتجارية خلف واجهة برمجة تطبيقات واحدة، تنطبق آليات التوجيه والموثوقية من الأجزاء السابقة من السلسلة على الأسطول بأكمله دفعة واحدة. يمكنك توجيه عبء عمل سيادي إلى النموذج المستضاف ذاتيًا وفقًا للسياسة، وإرسال حركة المرور العامة إلى واجهة برمجة تطبيقات تجارية، والأهم من ذلك — التراجع عبر الحدود: إذا كان الأسطول المستضاف ذاتيًا مشبعًا أثناء ذروة الطلب، فقم بالتحول إلى نموذج تجاري بدلاً من الانتظار في قائمة الانتظار، وإذا تعرض مزود لانقطاع، فقم بالتحويل إلى النموذج المستضاف ذاتيًا.
التوجيه الذي يتعامل مع المستضاف ذاتيًا والتجاري كأسطول واحد (توضيحي)
routes:
- match: { tag: "regulated" } # sovereignty: must stay in-VPC
target: llama-3-70b-internal
fallback: [] # no commercial fallback for this class
- match: { tag: "general" }
target: llama-3-70b-internal # prefer self-hosted for cost
fallback: [commercial-chat-model] # burst to commercial under load/outageهذا هو التوجيه و تجاوز الفشل من المدونتين 11 و 12، ويمتد الآن عبر الفجوة بين التجاري والمستضاف ذاتيًا — مع قيد مهم تم توضيحه في السياسة: يجب أن يكون المسار المنظم لا يتراجع إلى مزود تجاري، لأن التوفر لا يطغى أبدًا على السيادة. إن ترميز ذلك كقاعدة، بدلاً من الثقة في تذكر الجميع لها، هو نوع الحماية التي توجد البوابة لفرضها.
الفكرة الأساسية هي أن الاستضافة الذاتية تنقسم بوضوح إلى نوعين من العمل. النوع الأساسي — محرك الخدمة ووحدات معالجة الرسوميات — حقيقي، والمنشور التالي في هذه السلسلة يدور حول اقتصاداته. أما النوع العرضي — واجهة برمجة تطبيقات مختلفة، توجيه منفصل، حوكمة منفصلة، قابلية مراقبة منفصلة — فهو ما تستوعبه البوابة بكونها نقطة الوصل الوحيدة بين تطبيقاتك وكل نموذج، أينما كان يعمل.
ضع البوابة هناك ويتوقف النموذج المستضاف ذاتيًا عن كونه منصة موازية ليصبح نقطة نهاية أخرى خاضعة للإدارة: نفس واجهة برمجة التطبيقات المتوافقة مع OpenAI، نفس قواعد التوجيه والاحتياطي، نفس التحكم في الوصول المستند إلى الأدوار (RBAC) والميزانيات، نفس آثار التتبع. TrueFoundry مبني على هذا التقسيم بالضبط — تقديم خدمة عالية الأداء على vLLM وSGLang وTGI وTRT-LLM مع البنية التحتية لوحدات معالجة الرسوميات (GPU) والتخزين المؤقت لجعلها قابلة للتشغيل، وتتصدّرها بوابة ذكاء اصطناعي تجعل النتيجة لا يمكن تمييزها عن نموذج تجاري لأي شيء في المراحل الأولية. بالنسبة لرافي، هذا هو الفرق بين تلبية متطلب السيادة وإعادة بناء منصته لتحقيق ذلك.
هل الاستضافة الذاتية أرخص من واجهة برمجة التطبيقات التجارية؟
أحيانًا، بعد تجاوز عتبة معينة. لحركة المرور الثابتة وعالية الحجم والقابلة للتنبؤ، يمكن لوحدات معالجة الرسوميات (GPUs) ذات التكلفة الموزعة (خاصة مع المشاركة الجزئية والسعة الفورية) أن تقلل من تكلفة التسعير لكل رمز؛ أما لحركة المرور المتقطعة أو منخفضة الحجم، فعادة ما تكون واجهة برمجة التطبيقات التجارية أرخص لأنك لا تدفع مقابل وحدات معالجة الرسوميات الخاملة. الإجابة الصادقة هي تقدير حجم استخدامك الخاص — وهو موضوع منشور اقتصاديات وحدات معالجة الرسوميات الذي يترافق مع هذا المنشور. التكلفة هي أحد الأسباب الأربعة للاستضافة الذاتية، وليست السبب الوحيد.
هل يجب علي إعادة كتابة تطبيقي لاستخدام نموذج مستضاف ذاتيًا؟
ليس إذا كان النموذج مدعومًا ببوابة متوافقة مع OpenAI. يستمر التطبيق في استدعاء نفس واجهة برمجة التطبيقات ويتغير اسم النموذج فقط؛ تقوم البوابة بتحويل هذا الاسم إلى أسطول وحدات معالجة الرسوميات (GPU) الخاص بك وتطبق نفس التوجيه والتحكم في الوصول المستند إلى الأدوار (RBAC) والتتبع كما هو الحال بالنسبة للنماذج التجارية. الهدف الأساسي هو أن التطبيق لا يعرف أو يهتم بمكان تشغيل النموذج.
ما هو محرك الخدمة الذي يجب أن أستخدمه؟
قم بإجراء اختبارات الأداء لتحديد — لا يوجد فائز عالمي. تختلف الواجهات الخلفية الموثقة — vLLM وSGLang وTRT-LLM، بالإضافة إلى KServe وTriton — في الإنتاجية وزمن الاستجابة وكفاءة الذاكرة ودعم الميزات، ويعتمد الاختيار الصحيح على نموذجك وأطوال التسلسل والتزامن. قم بتشغيل عبء عملك الحقيقي على الخيارات المتاحة واختر بناءً على الأرقام المقاسة. تتيح لك المنصة التي تدعمها جميعًا التبديل دون إعادة هيكلة.
ما هو أصعب جزء تشغيلي؟
البدء البارد. أوزان نماذج اللغة الكبيرة (LLM) ضخمة، لذا فإن مقياسًا تلقائيًا يعيد تنزيل النموذج لكل نسخة متماثلة يكون بطيئًا جدًا لتتبع الطلب. التخزين المؤقت للنماذج، وتدفق الصور، ووحدات التخزين المشتركة هي ما يجعل التوسع عمليًا — فهي تحول البدء البارد الذي يستغرق عدة دقائق إلى شيء سريع بما يكفي لكي تعمل سياسات التحجيم التلقائي القائمة على طلبات في الثانية (RPS) وسياسات التحجيم إلى الصفر عند الخمول بفعالية.
هل يمكنني دمج النماذج المستضافة ذاتيًا والتجارية؟
هذه هي الحالة النهائية الشائعة، وهي قوة دعم كليهما ببوابة واحدة. وجّه حركة المرور السيادية أو عالية الحجم إلى النماذج المستضافة ذاتيًا، وحركة المرور العامة إلى واجهات برمجة التطبيقات التجارية، وقم بالتحويل التلقائي عبر الحدود تحت الضغط أو عند حدوث انقطاع — مع استثناء صريح بأن المسارات المنظمة يجب ألا تعود إلى مزود تجاري. أسطول واحد، مجموعة واحدة من القواعد، نوعان من الواجهات الخلفية.
لم تتطلب مشكلة السيادة لدى رافي منصة ثانية؛ بل تطلبت تشغيل نموذج واحد في مكان محدد وبقاء كل شيء آخر كما هو. هذا ما توفره لك البوابة: حرية وضع النموذج حيثما تتطلب السيادة أو التكلفة أو التحكم أو التوفر، بينما يرى التطبيق والمنصة واجهة متسقة واحدة. امتلك خدمة التقديم ووحدات معالجة الرسوميات — فهذا هو العمل الحقيقي — ودع البوابة تتولى الباقي.
رافي هو مثال توضيحي. يتم تلخيص قدرات TrueFoundry للخدمة والبوابة — محركات الاستدلال المدعومة، والتخزين المؤقت للنماذج، وبث الصور، والتوجيه الثابت المدرك للبادئة، والتحجيم التلقائي — من وثائق المنتج العامة اعتبارًا من منتصف عام 2026 وستتطور؛ يرجى التحقق من التفاصيل مقابل الوثائق الحالية. تعتمد مقارنات التكلفة بين النماذج المستضافة ذاتيًا والتجارية بالكامل على حجمك وعتادك الخاص ويجب نمذجتها مباشرة. تعتبر عينات التعليمات البرمجية والتكوين توضيحية للأنماط الموثقة، وليست منسوخة من تطبيق مرجعي.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








أحدث الأخبار والمقالات والموارد تصلك مباشرة إلى بريدك الوارد
© 2026 جميع الحقوق محفوظة.







.png)
.webp)










.webp)
