




July 20, 2023
|
5 min read


احصل على وصول فوري إلى بيئة TrueFoundry مباشرة. انشر النماذج، ووجّه حركة مرور LLM، واستكشف المنصة بالكامل — بيئة الاختبار الخاصة بك جاهزة في ثوانٍ، ولا يلزم وجود بطاقة ائتمان.









Published: July 4, 2026

Blazingly fast way to build, track and deploy your models!
LLMOps، والمعروفة أيضًا باسم عمليات نماذج اللغة الكبيرة، تشمل الممارسات والعمليات المتخصصة الضرورية لإدارة وتشغيل نماذج اللغة الكبيرة (LLMs) بكفاءة. نماذج اللغة الكبيرة (LLMs) هي نماذج متقدمة لمعالجة اللغة الطبيعية لديها القدرة على توليد نصوص شبيهة بالبشر وأداء مجموعة واسعة من المهام المتعلقة باللغة. تُعد هذه النماذج تقدمًا كبيرًا في مجال الذكاء الاصطناعي وقد وجدت تطبيقات في مجالات مختلفة مثل روبوتات الدردشة، وخدمات الترجمة، وتوليد المحتوى، والمزيد.
يتمثل دور LLMOps في ضمان التطوير والنشر والصيانة السلسة لنماذج اللغة الكبيرة (LLMs) طوال دورة حياتها. وهي تتضمن مراحل مختلفة، بدءًا من جمع البيانات ومعالجتها المسبقة وصولاً إلى الضبط الدقيق للنموذج، ونشره في بيئة الإنتاج، ومراقبته وتحديثه باستمرار لضمان الأداء الأمثل.
يأتي تطوير ونشر نماذج اللغة الكبيرة مصحوبًا بمجموعة فريدة من التحديات نظرًا لتعقيدها وطبيعتها التي تتطلب موارد مكثفة:
بينما تتشارك عمليات نماذج اللغة الكبيرة (LLMOps) أوجه تشابه مع عمليات تعلم الآلة التقليدية (MLOps)، إلا أن هناك جوانب مميزة تفصل بينهما:
تُعد البيانات حجر الزاوية لكل نموذج لغوي كبير (LLM) ناجح - وهي أداة قوية أحدثت ثورة في معالجة اللغة الطبيعية. ومع ذلك، فإن الرحلة من البيانات الخام إلى نموذج لغوي كبير عالي الأداء تتضمن سلسلة من الخطوات الحاسمة في إدارة البيانات. في هذا القسم، سنتعمق في تعقيدات توفير البيانات ومعالجتها المسبقة وتصنيفها وتطوير النماذج، مسلطين الضوء على التحديات وأفضل الممارسات التي تواجهها فرق LLMOps في هذه المرحلة الحاسمة من تميز الذكاء الاصطناعي اللغوي.
يُعد جمع البيانات المتنوعة والممثلة تحديًا هائلاً يمكن أن يؤثر بشكل كبير على فعالية نموذج اللغة الكبيرة (LLM). تجوب فرق LLMOps مساحات الويب الشاسعة، وتجمع كميات هائلة من النصوص والمحادثات والوثائق لإنشاء مجموعة بيانات قوية وشاملة. تُمكّن الاستراتيجيات مثل استخلاص البيانات من الويب (web scraping)، والاستفادة من المستودعات مفتوحة المصدر، والتعاون مع خبراء المجال، الفرق من بناء مجموعات بيانات تعكس التعقيد الحقيقي للغة في العالم الواقعي.
بمجرد جمع البيانات، تخضع لمعالجة مسبقة صارمة لتكون جاهزة لتدريب نماذج اللغة الكبيرة (LLM). يتضمن تنظيف البيانات إزالة الضوضاء والمعلومات غير ذات الصلة، والتعامل مع الأخطاء الإملائية والنحوية. تقوم عملية الترميز (Tokenization) بتقسيم النص إلى وحدات ذات معنى، مثل الكلمات أو الوحدات الفرعية للكلمات، مما يسمح للنموذج بمعالجة اللغة وفهمها بشكل أفضل. تضمن عملية التوحيد (Normalization) التجانس عن طريق تحويل النص إلى تنسيق قياسي، مما يقلل من التناقضات المحتملة أثناء التدريب.
يتطلب التعلم الخاضع للإشراف بيانات مُصنفة، وتستثمر فرق LLMOps جهودًا كبيرة في إنشاء مجموعات بيانات مشروحة لمهام نماذج اللغة الكبيرة (LLM) المحددة. يساعد التوصيف اليدوي من قبل الخبراء البشريين أو منصات التعهيد الجماعي في توفير التصنيفات لتحليل المشاعر، والتعرف على الكيانات المسماة، والمزيد. تعمل تقنيات مثل التعلم النشط وزيادة البيانات على تحسين جهود التوصيف بشكل أكبر، مما يستغل الموارد بفعالية لتحقيق أداء أفضل للنموذج.
أصبحت نماذج اللغة الكبيرة (LLMs) ذات أهمية متزايدة في مجموعة متنوعة من التطبيقات، مثل معالجة اللغة الطبيعية، والترجمة الآلية، والإجابة على الأسئلة. ومع ذلك، يمكن أن تكون نماذج اللغة الكبيرة معقدة ويصعب إدارتها. يمكن أن تساعد قواعد بيانات المتجهات في تبسيط إدارة نماذج اللغة الكبيرة من خلال توفير طريقة لتخزين والبحث في تمثيلاتها المتجهية الكبيرة.
قاعدة بيانات المتجهات هي نوع من قواعد البيانات التي تخزن البيانات في شكل متجهات. المتجهات هي نوع من الكائنات الرياضية التي يمكن استخدامها لتمثيل البيانات المعقدة، مثل النصوص والصور والصوت. قواعد بيانات المتجهات مناسبة تمامًا لتخزين والبحث في نماذج اللغة الكبيرة لأنها تستطيع تخزين واسترجاع التمثيلات المتجهية الكبيرة التي تستخدمها نماذج اللغة الكبيرة بكفاءة.
يتوفر عدد من قواعد بيانات المتجهات، بما في ذلك Pinceone، Milvus، Vespa AI، Qdrant، Redis، SingleStore، Weviate إلخ. توفر قواعد بيانات المتجهات هذه مجموعة متنوعة من الميزات التي يمكن استخدامها لإدارة نماذج اللغة الكبيرة. فيما يلي بعض الأمثلة المحددة لكيفية استخدام قواعد بيانات المتجهات في عمليات نماذج اللغة الكبيرة (LLMOps):
يقع تطوير النموذج في صميم عمليات نماذج اللغة الكبيرة (LLMOps)، حيث تبدأ رحلة البحث عن الأداء الأمثل والتميز اللغوي. في هذه المرحلة المحورية، تشرع فرق LLMOps في رحلة اختيار البنية، والضبط الدقيق، وضبط المعلمات الفائقة لتشكيل نماذج اللغة إلى كيانات بارعة ومتعددة الاستخدامات. في هذا الاستكشاف الشامل، نتعمق في تعقيدات كل خطوة، مسلطين الضوء على التحديات والتقنيات المتطورة التي تدعم تميز الذكاء الاصطناعي اللغوي.
يعد اختيار بنية نموذج اللغة الكبيرة (LLM) الصحيحة عاملاً حاسمًا يؤثر بشكل عميق على قدراته. تقوم فرق LLMOps بتقييم دقيق لمختلف الخيارات المعمارية، مع الأخذ في الاعتبار عوامل مثل حجم النموذج، وتعقيده، والمتطلبات المحددة للمهام المقصودة. لقد أحدثت البنى القائمة على المحولات (Transformer)، مثل عائلة GPT (المحول التوليدي المدرب مسبقًا)، ثورة في مجال معالجة اللغة الطبيعية. ومع ذلك، يتم استكشاف البنى الجديدة التي تتضمن ابتكارات مثل آليات الانتباه، وتعزيز الذاكرة، والحسابات التكيفية باستمرار لمعالجة تحديات محددة، وتعزيز الأداء، وتلبية التطبيقات المتنوعة.
يعد تتبع التجارب جانبًا حاسمًا في عمليات نماذج اللغة الكبيرة (LLMOps)، حيث يمكّن الفرق من إدارة وتحليل العدد الهائل من التجارب التي تُجرى أثناء تطوير نماذج اللغة الكبيرة بشكل منهجي. من خلال تطبيق أطر تتبع قوية، تقوم فرق LLMOps بتسجيل تكوينات النموذج والمعلمات الفائقة والنتائج بكفاءة، مما يتيح اتخاذ قرارات تعتمد على البيانات. إنه يعزز قابلية التكرار والشفافية والتعاون، مما يساعد في عملية التحسين ومواءمة استجابات النموذج مع توقعات المستخدمين. يلعب تتبع التجارب دورًا محوريًا في نهج "الإنسان في الحلقة"، حيث يدمج الملاحظات القيمة ويدفعنا نحو تحقيق ذكاء الذكاء الاصطناعي اللغوي في أبهى صوره.
تُعد نماذج اللغة الكبيرة المدربة مسبقًا نقطة البداية للضبط الدقيق الخاص بالمهمة. تتضمن هذه العملية تكييف معرفة النموذج وفهمه للتفوق في المهام المستهدفة. تتنقل فرق عمليات نماذج اللغة الكبيرة (LLMOps) بمهارة في مشهد الضبط الدقيق، محققة التوازن الصحيح بين الاحتفاظ بالمعرفة المدربة مسبقًا للنموذج ودمج المعلومات الخاصة بالمهمة. يلعب اختيار المعاملات الفائقة المناسبة، بما في ذلك معدلات التعلم وأحجام الدفعات وخوارزميات التحسين، دورًا محوريًا في تحقيق الأداء المطلوب. علاوة على ذلك، يتم تحديد كمية بيانات التدريب الإضافية المطلوبة للضبط الدقيق بعناية لتجنب الإفراط في التخصيص أو الاستخدام الناقص لإمكانات النموذج.
تعمل المعاملات الفائقة كمفاتيح تحكم توجه سلوك النموذج أثناء التدريب. يُعد العثور على التكوين الأمثل لهذه المعاملات الفائقة خطوة حاسمة في زيادة أداء النموذج إلى أقصى حد. تستخدم فرق عمليات نماذج اللغة الكبيرة (LLMOps) مجموعة متنوعة من التقنيات للشروع في رحلة ضبط المعاملات الفائقة. من البحث الشبكي إلى التحسين البايزي والخوارزميات التطورية، تستكشف كل طريقة مساحة المعاملات الفائقة الشاسعة لتحديد النقطة المثلى التي يحقق فيها النموذج ذروة أدائه. بالإضافة إلى ذلك، يتم الاستفادة من الأساليب مثل جداول معدل التعلم وتضاؤل الأوزان لتعزيز التعميم والتخفيف من الإفراط في التخصيص.
تستفيد فرق عمليات نماذج اللغة الكبيرة (LLMOps) من نماذج التعلم الانتقالي والتعلم متعدد المهام لتعزيز قابلية النموذج للتكيف وكفاءته. يتضمن التعلم الانتقالي تدريب نموذج لغوي مسبقًا على مجموعة بيانات ضخمة، يليه ضبط دقيق خاص بالمهمة. تُمكّن هذه التقنية النموذج من الاستفادة من المعرفة المستخلصة من مجموعة متنوعة من البيانات اللغوية. يسمح التعلم متعدد المهام للنماذج بالتعلم المتزامن من مهام متعددة، مما يمكنها من الاستفادة من العلاقات والأنماط المشتركة عبر المهام، مما يؤدي إلى تعميم وأداء أفضل.
إن نجاح نماذج اللغة الكبيرة (LLMs) لا يعتمد فقط على قدراتها المثيرة للإعجاب، بل أيضًا على نشرها السلس وعملياتها الفعالة. في هذه المرحلة الحاسمة من عمليات نماذج اللغة الكبيرة (LLMOps)، يُعد التخطيط والتنفيذ الدقيقان أمرًا بالغ الأهمية. يتعمق هذا القسم في تعقيدات نشر نماذج الذكاء الاصطناعي واستراتيجياتها، وأهمية المراقبة والصيانة المستمرة، والدور الذي لا يقدر بثمن لملاحظات المستخدمين وهندسة الأوامر في تشكيل نماذج اللغة الكبيرة لتحقيق تميز اللغة في الذكاء الاصطناعي.
يتطلب نشر نماذج اللغة الكبيرة في بيئات الإنتاج اعتبارات استراتيجية لضمان الأداء الأمثل ورضا المستخدم. تقوم فرق عمليات نماذج اللغة الكبيرة (LLMOps) بتقييم استراتيجيات النشر بدقة، مع الأخذ في الاعتبار متطلبات البنية التحتية وقابلية التوسع واعتبارات الأداء. يوفر النشر المستند إلى السحابة مرونة وموارد حسب الطلب، بينما تلبي الحلول المحلية مخاوف خصوصية البيانات وأمنها. يُمكّن النشر على الحافة نماذج اللغة الكبيرة من العمل بالقرب من المستخدمين النهائيين، مما يقلل من زمن الاستجابة ويعزز التفاعل في الوقت الفعلي. يؤدي اعتماد استراتيجية النشر الأنسب إلى تعزيز توفر نماذج اللغة الكبيرة واستجابتها، وتلبية الاحتياجات المتنوعة للتطبيقات في العالم الحقيقي.
يتطلب نشر وتشغيل نماذج اللغة الكبيرة نهجًا شموليًا وتعاونيًا. تتعاون فرق عمليات نماذج اللغة الكبيرة (LLMOps) مع خبراء المجال وخبراء الأخلاق ومصممي واجهة المستخدم لمعالجة التحديات بشكل شامل. يضمن إشراك الخبراء من مختلف المجالات أن تكون نماذج اللغة الكبيرة مصممة لخدمة صناعات ومجالات محددة بفعالية. تلعب الاعتبارات الأخلاقية دورًا حاسمًا في التخفيف من التحيز وضمان نشر الذكاء الاصطناعي المسؤول، مما يؤدي إلى إنشاء نماذج لغة كبيرة عادلة وشاملة ومنصفة في تفاعلاتها مع المستخدمين. يعزز مصممو واجهة المستخدم تجربة المستخدم الشاملة، مما يجعل نماذج اللغة الكبيرة أكثر بديهية وسهولة في الاستخدام، ويعزز التفاعلات السلسة والمثمرة.
التكامل المستمر (CI) هو ممارسة أتمتة بناء واختبار التعليمات البرمجية في كل مرة يتم فيها إيداعها في نظام التحكم بالإصدارات. يساعد هذا في ضمان أن تكون التعليمات البرمجية دائمًا في حالة عمل وأن يتم تحديد أي تغييرات ومعالجتها بسرعة.
التسليم المستمر (CD) هو ممارسة أتمتة نشر التعليمات البرمجية إلى بيئة الإنتاج. يساعد هذا في ضمان إمكانية نشر التعليمات البرمجية بسرعة وموثوقية، وأن يتم التراجع عن أي تغييرات إذا لزم الأمر.
عند دمج التكامل المستمر والتسليم المستمر، فإنهما يشكلان مسار CI/CD. يمكن لمسار CI/CD أتمتة العملية بأكملها لبناء واختبار ونشر نماذج التعلم الآلي. يمكن أن يساعد هذا في تحسين الموثوقية والكفاءة والرؤية لعملية تطوير ونشر نماذج التعلم الآلي.
فيما يلي بعض فوائد استخدام CI/CD لعمليات نماذج اللغة الكبيرة (LLMOps):
فيما يلي بعض الأمثلة على أدوات CI/CD لعمليات LLMOps:
هذه ليست سوى عدد قليل من فوائد استخدام CI/CD لعمليات LLMOps. إذا كنت تتطلع إلى تحسين موثوقية وكفاءة ووضوح عملية تطوير ونشر نماذج التعلم الآلي لديك، فإن CI/CD هي أداة قيمة يجب أخذها في الاعتبار.
تُعد المراقبة المستمرة جوهر عمليات نماذج اللغة الكبيرة (LLM) الناجحة. فهي تتيح لفرق LLMOps تحديد المشكلات ومعالجتها على الفور، مما يضمن أقصى أداء وموثوقية. تشمل المراقبة مقاييس الأداء، مثل وقت الاستجابة، والإنتاجية، واستخدام الموارد، مما يتيح التدخل في الوقت المناسب في حالة وجود اختناقات أو تدهور في الأداء. بالإضافة إلى ذلك، يُعد اكتشاف التحيز أو المخرجات الضارة أمرًا بالغ الأهمية لنشر الذكاء الاصطناعي المسؤول. من خلال توظيف تقنيات المراقبة التي تراعي العدالة، تضمن فرق LLMOps أن نماذج اللغة الكبيرة تعمل بشكل أخلاقي، مما يقلل من التحيزات غير المقصودة ويعزز ثقة المستخدم. تضمن تحديثات النموذج المنتظمة وصيانته، والتي تسهلها خطوط الأنابيب الآلية، بقاء نموذج اللغة الكبيرة محدثًا بأحدث التطورات واتجاهات البيانات، مما يضمن كفاءة واستمرارية وقابلية للتكيف.
تُعد التغذية الراجعة البشرية قوة دافعة حاسمة في تحسين أداء نماذج اللغة الكبيرة (LLM). تتبنى فرق LLMOps نهجًا يشرك العنصر البشري، مما يتيح للخبراء والمستخدمين النهائيين تقديم ملاحظات قيمة حول مخرجات نموذج اللغة الكبيرة. تسهل هذه العملية التكرارية تحسين النموذج وضبطه بدقة، مما يواءم استجابات نموذج اللغة الكبيرة مع التوقعات البشرية والاحتياجات الواقعية. التعلم المعزز من التغذية الراجعة البشرية (RLHF) هو تقنية تعلم آلي تدرب النماذج على توليد نصوص تتوافق مع التفضيلات البشرية. يعمل RLHF عن طريق إعطاء النموذج إشارة مكافأة لتوليد نص يعتبر "جيدًا" من قبل مقيّم بشري. يتعلم النموذج بعد ذلك توليد نص يزيد من إشارة المكافأة. يمكن استخدام RLHF لتحسين أداء نماذج اللغة الكبيرة في مجموعة متنوعة من المهام، مثل تلخيص النصوص، والإجابة على الأسئلة، وتوليد الحوار. من خلال الجمع بين التغذية الراجعة البشرية والتعلم الآلي، يمكن لـ RLHF إنشاء نماذج أكثر دقة وإفادة وجاذبية.
علاوة على ذلك، تلعب هندسة المطالبات دورًا محوريًا في توجيه نماذج اللغة الكبيرة لإنتاج المخرجات المطلوبة. تساعد صياغة المطالبات المناسبة في توجيه استجابات النموذج، مما يتيح لفرق LLMOps تجربة المطالبات وتحسينها لحالات الاستخدام المختلفة والمجالات وتفضيلات المستخدمين. ونتيجة لذلك، تصبح نماذج اللغة الكبيرة أكثر قابلية للتحكم والتكيف والكفاءة في تقديم استجابات ذات معنى.
يُعد الاختبار جانبًا أساسيًا من عمليات نماذج اللغة الكبيرة (LLMOps) يضمن متانة وموثوقية نماذج اللغة الكبيرة في سيناريوهات العالم الحقيقي. تساعد إجراءات الاختبار الشامل فرق LLMOps على التحقق من أداء ودقة نموذج اللغة عبر مجموعة متنوعة من المهام وسيناريوهات الإدخال. تُستخدم منهجيات اختبار متنوعة، بما في ذلك اختبار الوحدات، واختبار التكامل، والاختبار الشامل، لتقييم جوانب مختلفة من وظائف نموذج اللغة الكبيرة. بالإضافة إلى ذلك، يساعد اختبار الإجهاد والاختبار العدائي في تحديد نقاط الضعف أو الثغرات المحتملة في استجابات النموذج، مما يضمن قدرته على التعامل مع المدخلات الصعبة والأمثلة العدائية بثبات. من خلال إجراء اختبار صارم، تغرس فرق LLMOps الثقة في قدرات النموذج، مما يعزز النشر المسؤول والمؤثر لنماذج اللغة الكبيرة في التطبيقات العملية.
يُعد تقييم أداء نماذج اللغة الكبيرة (LLMs) أمرًا بالغ الأهمية في تقييم قدراتها وإمكاناتها لمختلف مهام معالجة اللغة الطبيعية. توجد العديد من طرق التقييم، كل منها يسلط الضوء على جوانب مختلفة من فعالية النموذج. فيما يلي خمسة أبعاد تقييم شائعة الاستخدام تقدم رؤى قيمة حول أداء نماذج اللغة الكبيرة:
الحيرة هي مقياس أساسي يُستخدم بشكل متكرر لتقييم أداء نماذج اللغة. يقيس مدى فعالية النموذج في التنبؤ بعينة نص معينة. تشير درجة الحيرة الأقل إلى أن النموذج يمكنه التنبؤ بالكلمة التالية في التسلسل بشكل أفضل، مما يشير إلى مخرجات أكثر اتساقًا وسلاسة. يساعد هذا المقياس الباحثين والمطورين على ضبط نماذجهم لتحسين توليد اللغة وفهمها.
بينما تُعد المقاييس الآلية قيّمة، يلعب التقييم البشري دورًا محوريًا في تقييم الجودة الحقيقية لنماذج اللغة. لهذا النهج، يتم الاستعانة بمقيِّمين بشريين خبراء لمراجعة وتقييم الاستجابات المولدة بناءً على معايير متعددة، مثل الصلة، والسلاسة، والاتساق، والجودة الشاملة. يوفر الحكم البشري ملاحظات ذاتية ويلتقط الفروق الدقيقة التي قد تتجاهلها المقاييس الآلية. إنها خطوة حاسمة في فهم مدى أداء النموذج في سيناريوهات العالم الحقيقي وتمكن الباحثين من معالجة أي مخاكل أو قيود محددة.
يُستخدم BLEU بشكل أساسي في مهام الترجمة الآلية، حيث يقارن المخرجات المولدة بترجمة مرجعية واحدة أو أكثر لقياس التشابه بينها. تشير درجة BLEU الأعلى إلى أن الترجمة المولدة للنموذج تتوافق جيدًا مع الترجمات المرجعية المقدمة. يساعد في تقييم دقة الترجمة وفعالية النموذج.
ROUGE هي مجموعة من المقاييس المستخدمة على نطاق واسع لتقييم جودة تلخيص النصوص. يقيس التداخل بين الملخص المُولَّد وملخص مرجعي واحد أو أكثر، مع الأخذ في الاعتبار الدقة (precision) والاستدعاء (recall) ودرجة F1. توفر درجات ROUGE رؤى قيمة حول مدى قدرة نموذج اللغة على توليد ملخصات موجزة وغنية بالمعلومات، مما يجعله لا يقدر بثمن لمهام مثل تلخيص المستندات وتوليد المحتوى.
يُعد ضمان أن ينتج نموذج اللغة مخرجات متنوعة وفريدة أمرًا ضروريًا، خاصة في تطبيقات مثل روبوتات الدردشة أو أنظمة توليد النصوص. تتضمن مقاييس التنوع تحليل مقاييس مثل تنوع n-gram أو قياس التشابه الدلالي بين الاستجابات المولدة. تشير درجات التنوع الأعلى إلى أن النموذج يمكنه إنتاج نطاق أوسع من الاستجابات وتجنب المخرجات المتكررة أو الرتيبة.
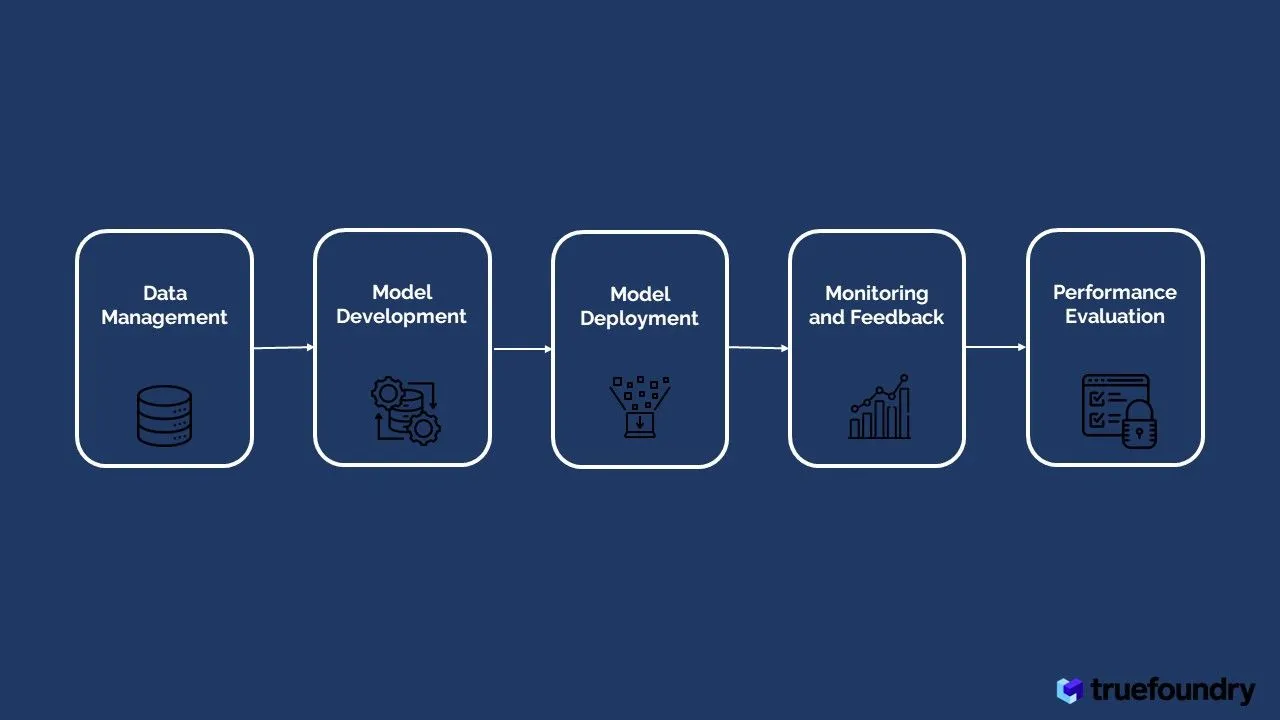
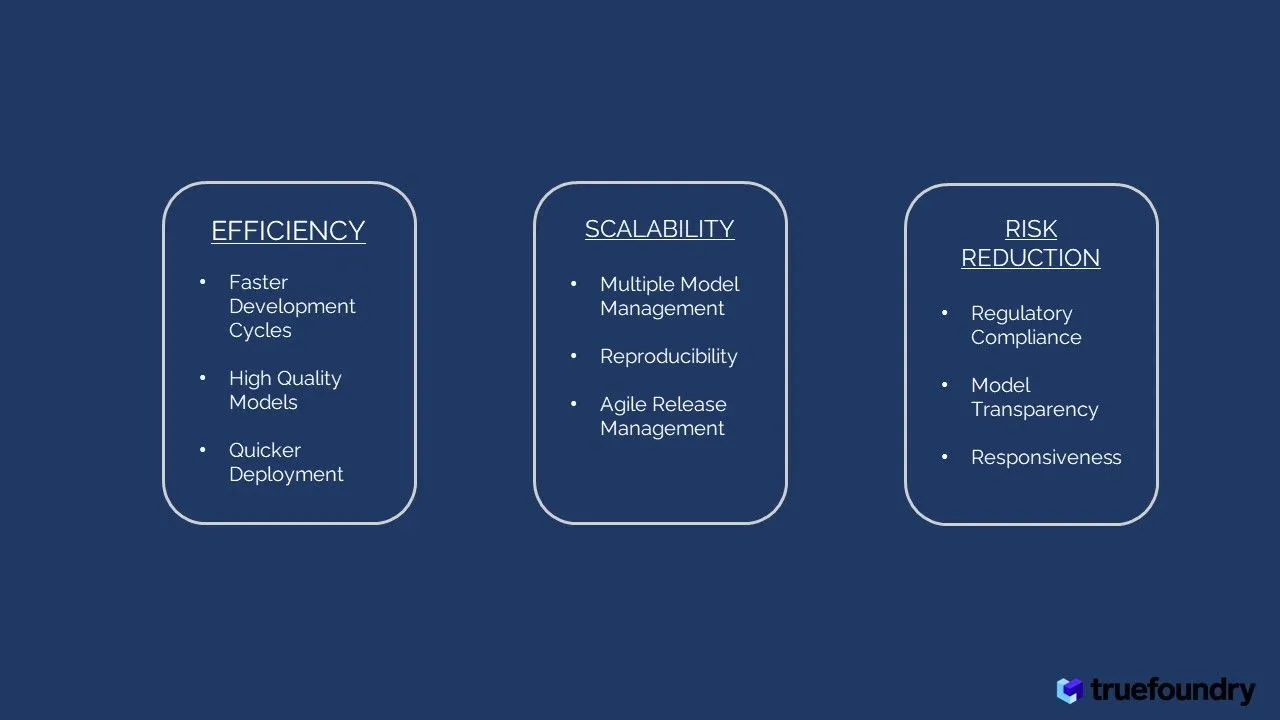
تبسط LLMOps عملية تطوير نماذج اللغة الكبيرة، مما يؤدي إلى العديد من الفوائد:
تدعم عمليات LLMOps قابلية التوسع وقابلية الاستنساخ لمسارات عمل نماذج اللغات الكبيرة (LLM):
تتناول عمليات LLMOps المخاطر المحتملة المرتبطة بنشر نماذج اللغات الكبيرة (LLM):
في الختام، تلعب عمليات LLMOps دورًا حيويًا في إدارة العملية المعقدة والمستهلكة للموارد لتطوير ونشر وصيانة نماذج اللغات الكبيرة. من خلال معالجة التحديات الفريدة والاستفادة من التقنيات المتخصصة، تضمن عمليات LLMOps الاستخدام الفعال والأخلاقي لهذه النماذج القوية للذكاء الاصطناعي في مختلف التطبيقات الواقعية.
مع نضوج منظومة نماذج اللغة الكبيرة (LLM)، غالبًا ما تقوم الفرق بتقييم منصات مختلفة لتحديد الـ أفضل أدوات LLMOps لسير عملهم المحدد—سواء كان ذلك يتضمن تتبع التجارب، أو تقديم النماذج، أو تصنيف البيانات، أو مراقبة الإنتاج.
هاجينج فيس هي منصة مفتوحة المصدر لبناء واستخدام نماذج اللغة الكبيرة. توفر مكتبة من النماذج المدربة مسبقًا، وواجهة سطر أوامر، وتطبيق ويب لتجربة النماذج. يتميز هاجينج فيس بتركيزه على جعل نماذج اللغة الكبيرة في متناول الجميع.
تتضمن مكتبة هاجينج فيس من النماذج المدربة مسبقًا مجموعة واسعة من النماذج، من BERT إلى GPT-3. يمكن استخدام هذه النماذج لمجموعة متنوعة من المهام، مثل فهم اللغة الطبيعية، وتوليد اللغة الطبيعية، والإجابة على الأسئلة. تسهل واجهة سطر الأوامر الخاصة بهاجينج فيس تحميل هذه النماذج واستخدامها، ويوفر تطبيق الويب الخاص بها واجهة مرئية لتجربة النماذج.
كلير إم إل هي منصة لإدارة تجارب التعلم الآلي. توفر طريقة لتتبع التجارب وتخزين البيانات وتصور النتائج. يتميز كلير إم إل بقدرته على تتبع التجارب عبر منصات تعلم آلي متعددة. تسهل ميزات تتبع التجارب في كلير إم إل متابعة تقدم مشاريع التعلم الآلي الخاصة بك. يمكنك تتبع المعلمات التي استخدمتها، والمقاييس التي قمت بقياسها، والنتائج التي حققتها. يتيح لك كلير إم إل أيضًا تخزين البيانات من تجاربك، بحيث يمكنك بسهولة إعادة إنتاج نتائجك.
AWS SageMaker هي منصة مُدارة بالكامل توفر مجموعة شاملة من الإمكانيات لبناء وتدريب ونشر نماذج التعلم الآلي. تتضمن مجموعة متنوعة من الأدوات والخدمات لإدارة دورة حياة التعلم الآلي بأكملها، من إعداد البيانات إلى نشر النماذج. يُعد SageMaker خيارًا شائعًا لـ LLMOps لأنه يوفر عددًا من الميزات المصممة خصيصًا لنماذج اللغة الكبيرة، مثل:
بيدروك هي منصة جديدة من AWS مصممة خصيصًا للذكاء الاصطناعي التوليدي. توفر عددًا من الميزات المصممة لتسهيل بناء وتدريب ونشر نماذج الذكاء الاصطناعي التوليدي، بما في ذلك:
خدمات Azure OpenAI هي مجموعة من الخدمات التي تتيح لك استخدام نماذج اللغة الكبيرة من OpenAI في Azure. تتضمن هذه الخدمات نقطة نهاية مُدارة لعائلة نماذج GPT-3، وخدمة تحويل النص إلى تعليمات برمجية، وخدمة الإجابة على الأسئلة. تتميز خدمات Azure OpenAI بتكاملها مع Azure. تسهل خدمات Azure OpenAI استخدام نماذج اللغة الكبيرة من OpenAI في تطبيقات Azure الخاصة بك. يمكنك استخدام نقطة النهاية المُدارة للوصول إلى نموذج GPT-3، أو يمكنك استخدام خدمة تحويل النص إلى تعليمات برمجية لإنشاء تعليمات برمجية من أوصاف اللغة الطبيعية. توفر خدمات Azure OpenAI أيضًا خدمة الإجابة على الأسئلة، بحيث يمكنك طرح أسئلة حول نماذج OpenAI والحصول على إجابات.
واجهة برمجة تطبيقات GCP Palm هي واجهة برمجة تطبيقات لمعالجة اللغة الطبيعية يمكن استخدامها لإنشاء النصوص وترجمة اللغات والإجابة على الأسئلة. تستند إلى نماذج اللغة الكبيرة من Google، مثل BERT وGPT-3. تتميز واجهة برمجة تطبيقات GCP Palm بقدرتها على إنشاء النصوص وترجمة اللغات والإجابة على الأسئلة. توفر واجهة برمجة تطبيقات GCP Palm مجموعة متنوعة من الميزات لإنشاء النصوص وترجمة اللغات والإجابة على الأسئلة. يمكنك استخدامها لإنشاء نصوص واقعية، وترجمة اللغات بدقة، والإجابة على الأسئلة بطريقة شاملة وغنية بالمعلومات. تعد واجهة برمجة تطبيقات GCP Palm أداة قوية للمطورين الذين يحتاجون إلى استخدام معالجة اللغة الطبيعية في تطبيقاتهم.
LlamaIndex هي منصة لفهرسة نماذج اللغة الكبيرة والبحث فيها. LlamaIndex مناسبة بشكل خاص لعمليات LLM (LLMOps)، حيث توفر مجموعة متنوعة من الميزات لفهرسة نماذج اللغة الكبيرة والبحث فيها، بما في ذلك الاستعلام السريع، وترتيب الصلة، والتصفية حسب المعايير. تتيح لك ميزة الاستعلام السريع في LlamaIndex البحث بسرعة في نماذج اللغة الكبيرة الخاصة بك عن المعلومات التي تحتاجها. تتيح لك ميزة ترتيب الصلة ترتيب نتائج عمليات البحث بناءً على صلتها باستعلامك. تتيح لك ميزة التصفية حسب المعايير تصفية نتائج عمليات البحث حسب معايير مختلفة.
LangChain هي منصة لعمليات LLM (LLMOps) تساعد الفرق على بناء ونشر وإدارة نماذج اللغة الكبيرة (LLMs) على نطاق واسع. توفر مجموعة متنوعة من الميزات لإدارة نماذج اللغة الكبيرة، بما في ذلك التحكم في الإصدارات، وتتبع التجارب، والنشر في بيئة الإنتاج. تتميز LangChain بقدرتها على توسيع نطاق نماذج اللغة الكبيرة للتعامل مع كميات كبيرة من البيانات. كما توفر مجموعة متنوعة من الميزات لمراقبة نماذج اللغة الكبيرة، حتى تتمكن الفرق من ضمان أدائها كما هو متوقع.
Toloka هي منصة للتمويل الجماعي تتيح لك تصنيف البيانات لنماذج التعلم الآلي. Toloka مناسبة بشكل خاص لعمليات LLM (LLMOps)، حيث يمكن استخدامها لتصنيف كميات كبيرة من البيانات بسرعة وكفاءة. لدى Toloka مجموعة كبيرة من العمال المتاحين لتصنيف البيانات على مدار الساعة طوال أيام الأسبوع. تساعد المنصة في الحصول على مدخلات بشرية في جميع مراحل تطوير نماذج اللغة الكبيرة: التدريب المسبق، والضبط الدقيق، والتعلم المعزز من ردود الفعل البشرية (RLHF).
LabelBox هي منصة قائمة على السحابة لتصنيف البيانات لنماذج التعلم الآلي. LabelBox مناسبة بشكل خاص لعمليات LLM (LLMOps)، حيث توفر مجموعة متنوعة من الأدوات والميزات لتصنيف البيانات، بما في ذلك واجهة مستخدم قائمة على الويب، وتطبيق جوال، وواجهة برمجة تطبيقات REST. واجهة المستخدم القائمة على الويب في LabelBox سهلة الاستخدام ويمكن الوصول إليها من أي جهاز. يتيح لك تطبيق الجوال تصنيف البيانات أثناء التنقل. تتيح لك واجهة برمجة تطبيقات REST دمج LabelBox مع سير عملك الحالي.
أرجيلا هي منصة لإدارة ونشر نماذج التعلم الآلي. أرجيلا مناسبة بشكل خاص لعمليات LLMOps، حيث توفر منصة مفتوحة المصدر لتنظيم البيانات لنماذج اللغة الكبيرة (LLMs) باستخدام حلقات التغذية الراجعة البشرية والآلية. تتميز أرجيلا أيضًا بمجموعة متنوعة من الميزات لإدارة النماذج، بما في ذلك إدارة الإصدارات، وتتبع التجارب، والنشر في بيئة الإنتاج. يتيح لك نظام إدارة الإصدارات الخاص بـ أرجيلا تتبع التغييرات على نماذجك بمرور الوقت. يتيح لك نظام تتبع التجارب تسجيل المعلمات الفائقة (hyperparameters) ونتائج تجاربك. يتيح لك نظام النشر في بيئة الإنتاج نشر نماذجك في بيئات الإنتاج.
سيرج هي منصة لنشر نماذج التعلم الآلي في بيئة الإنتاج. تمتلك سيرج منصة مخصصة لـ RLHF مع ميزات رئيسية مثل مصنفي الخبراء في المجال، وواجهة التجارب السريعة، وخبرة RLHF ونماذج اللغة. تخدم سيرج مجموعة واسعة من حالات الاستخدام مثل تقييم البحث والإشراف على المحتوى. سيرج مناسبة بشكل خاص لعمليات LLMOps، حيث توفر ميزات متنوعة لنشر النماذج في بيئة الإنتاج، بما في ذلك التحجيم التلقائي والمراقبة والتنبيهات. تتيح لك ميزة التحجيم التلقائي في سيرج توسيع أو تقليص نماذجك تلقائيًا بناءً على الطلب. تتيح لك ميزة المراقبة تتبع أداء نماذجك في بيئة الإنتاج. تتيح لك ميزة التنبيهات تلقي إشعارات عند وجود مشاكل في نماذجك.
سكيل هي منصة متكاملة تدعم استراتيجية الذكاء الاصطناعي التوليدي—بما في ذلك الضبط الدقيق، وهندسة الأوامر (prompt engineering)، والأمان، وسلامة النماذج، وتقييم النماذج، وتطبيقات المؤسسات. كما توفر دعمًا لـ RLHF، وتوليد البيانات، والأمان، والمحاذاة. سكيل مناسبة بشكل خاص لعمليات LLMOps، حيث توفر مجموعة متنوعة من الميزات لإدارة النماذج على نطاق واسع، بما في ذلك التحجيم التلقائي، وموازنة التحميل، وتحمل الأخطاء. تتيح لك ميزة التحجيم التلقائي في سكيل توسيع أو تقليص نماذجك تلقائيًا بناءً على الطلب. توزع ميزة موازنة التحميل حركة المرور عبر نماذجك لضمان عدم تحميلها الزائد. تتيح ميزة تحمل الأخطاء لنماذجك الاستمرار في العمل حتى لو تعطل بعضها.
أصدرت داتابريكس مؤخرًا نموذج اللغة الكبير (LLM) الخاص بها والمُعدّل بالتعليمات المفتوحة، Dolly. داتابريكس MLFlow مناسب بشكل خاص لعمليات LLMOps، حيث يمكن استخدامه لتتبع أداء نماذج اللغة الكبيرة (LLMs) بمرور الوقت ونشرها في بيئات الإنتاج. يوفر مستودعًا مركزيًا لتخزين تجارب التعلم الآلي والنماذج والمخرجات. كما يوفر داتابريكس MLFlow مجموعة متنوعة من الميزات لتتبع أداء نماذج التعلم الآلي، بما في ذلك تتبع التجارب، وإدارة إصدارات النماذج، وإدارة المخرجات.
فيما يلي بعض الميزات الرئيسية لـ Databricks MLFlow:
مجموعة من أدوات LLMOps ضمن منصة W&B MLOps الموجهة للمطورين. استفد من W&B Prompts لتصور وفحص تدفق تنفيذ نماذج اللغة الكبيرة (LLM)، وتتبع المدخلات والمخرجات، وعرض النتائج الوسيطة، وإدارة الأوامر وتكوينات سلاسل نماذج اللغة الكبيرة (LLM chain) بشكل آمن. كما يتيح لك W&B مشاركة تجاربك مع فرق أخرى، مما يمكن أن يكون مفيدًا للتعاون وتبادل المعرفة. W&B مناسب بشكل خاص لعمليات LLMOps، حيث يمكن استخدامه لتتبع أداء نماذج اللغة الكبيرة (LLMs) بمرور الوقت ومشاركتها مع فرق أخرى.
فيما يلي بعض الميزات الرئيسية لـ W&B:
TrueLens هي منصة لإدارة ونشر نماذج اللغة الكبيرة (LLMs). توفر TrueLens مجموعة متنوعة من الميزات لإدارة نماذج اللغة الكبيرة (LLMs)، بما في ذلك تحديد الإصدارات، وتتبع التجارب، والنشر للإنتاج. تستخدم TrueLens وظائف التغذية الراجعة لقياس جودة وفعالية تطبيق نماذج اللغة الكبيرة (LLM) الخاص بك. تتيح لك TrueLens أيضًا نشر نماذج اللغة الكبيرة (LLMs) على مجموعة متنوعة من موفري الخدمات السحابية، مما قد يكون مفيدًا لقابلية التوسع والموثوقية. تُعد TrueLens مناسبة بشكل خاص للفرق التي تستخدم مجموعة متنوعة من أطر عمل تعلم الآلة، حيث يمكن استخدامها لإدارة النماذج من أطر عمل مختلفة.
فيما يلي بعض الميزات الرئيسية لـ TrueLens:
تتيح لك MosaicML تنفيذ نماذج مفتوحة المصدر ومرخصة تجارياً. يمكنك دمج نماذج اللغة الكبيرة (LLMs) بسهولة في تطبيقاتك. كما تتيح لك نشر النماذج الجاهزة أو ضبطها بدقة على بياناتك. Mosaic ML هي منصة لبناء ونشر وإدارة نماذج تعلم الآلة على نطاق واسع. توفر Mosaic ML مجموعة متنوعة من الميزات لإدارة النماذج على نطاق واسع، بما في ذلك التحجيم التلقائي، وموازنة التحميل، وتحمل الأخطاء. تتيح لك Mosaic ML أيضًا مراقبة أداء نماذجك في بيئة الإنتاج، مما يمكن أن يساعدك في تحديد المشكلات وحلها بسرعة.
فيما يلي بعض الميزات الرئيسية لـ Mosaic ML:
انشر أدوات LLMOps مثل قواعد بيانات المتجهات (Vector DBs) وخوادم التضمين (Embedding server) وغيرها على البنية التحتية الخاصة بك من Kubernetes (EKS, AKS, GKE, On-prem) بما في ذلك نشر النماذج اللغوية الكبيرة مفتوحة المصدر (LLM Models)، وضبطها بدقة، وتتبع المطالبات، وتقديمها مع أمان بيانات كامل وإدارة مثالية لوحدات معالجة الرسوميات (GPU). درب وأطلق تطبيقك للنماذج اللغوية الكبيرة (LLM) على نطاق الإنتاج بأفضل ممارسات هندسة البرمجيات. توفر TrueFoundry ضبطًا دقيقًا أسرع بخمس مرات وعمليات نشر أسرع بعشر مرات لنماذج LLM. تركز TrueFoundry أيضًا على تقليل التكاليف (أقل بنسبة 50%) وأمان البيانات لعمليات نماذجك اللغوية الكبيرة.
Run:AI هي منصة لإدارة دورة حياة النماذج اللغوية الكبيرة (LLM) الشاملة، مما يمكّن الشركات من ضبط نماذج LLM بدقة، وهندسة المطالبات، ونشرها بسهولة. إنها مناسبة بشكل خاص لعمليات النشر واسعة النطاق، حيث يمكنها التوسع للتعامل مع أي حجم من حركة المرور. تخصص Run:AI هو قدرتها على أتمتة دورة حياة تعلم الآلة (ML) بأكملها، من إعداد البيانات إلى نشر النماذج ومراقبتها. يمكن أن يوفر هذا الوقت والجهد، ويساعد على ضمان إنجاز مشاريع تعلم الآلة في الوقت المحدد وفي حدود الميزانية.
ZenML هي منصة لبناء وإدارة و نشر النماذج اللغوية الكبيرة (LLMs). إنها مناسبة بشكل خاص للفرق التي ترغب في أتمتة سير عمل LLMOps الخاص بها. تخصص ZenML هو سهولة استخدامها. فهي توفر واجهة سحب وإفلات ومكتبة من المكونات الجاهزة، بحيث يمكن للفرق بناء ونشر مسارات تعلم الآلة (ML) بسرعة وسهولة.
تمكّن Iguazio الجوانب الرئيسية لـ LLMOps: أتمتة سير العمل، المعالجة على نطاق واسع، التحديثات المتجددة، التطوير والنشر السريع للمسارات، ومراقبة النماذج. على الرغم من ذلك، تحتاج بعض الخطوات إلى التكيف. على سبيل المثال، تحتاج خطوات التضمين (embeddings)، والترميز (tokenization)، وتنظيف البيانات إلى التعديل، على سبيل المثال لا الحصر. إنها مناسبة بشكل خاص للفرق التي تحتاج إلى نشر تطبيقات تعلم الآلة (ML) عبر سحابات متعددة. تخصص Iguazio هو قدرتها على توسيع نطاق تطبيقات تعلم الآلة للتعامل مع أي حجم من حركة المرور. كما توفر منصة واحدة لإدارة جميع عمليات نشر تعلم الآلة للفريق، مما يوفر الوقت والجهد.
Aviary من Anyscale هي بنية تحتية لخدمة النماذج اللغوية الكبيرة (LLM) مفتوحة المصدر بالكامل ومجانية وقائمة على السحابة، مصممة لمساعدة المطورين على اختيار ونشر التقنيات والنهج الصحيح لتطبيقاتهم القائمة على LLM. تسهل Aviary من Anyscale التقييم المستمر لأداء نماذج LLM المتعددة مقابل بياناتك واختيار ونشر النموذج المناسب لتطبيقاتك. تخصص Anyscale هو خدمة Kubernetes المدارة الخاصة بها. وهذا يسهل توسيع نطاق أعباء عمل تعلم الآلة ويضمن توفرها دائمًا.
Arize هي منصة LLMOps تساعد الفرق على بناء ونشر وإدارة نماذج اللغة الكبيرة (LLMs) لمجموعة متنوعة من المهام، بما في ذلك فهم اللغة الطبيعية، وتوليد اللغة الطبيعية، والإجابة على الأسئلة. توفر مجموعة متنوعة من الميزات لإدارة نماذج اللغة الكبيرة، بما في ذلك التحكم في الإصدار، وتتبع التجارب، والنشر في بيئة الإنتاج. يتميز Arize بقدرته على التكامل مع مجموعة متنوعة من منصات التعلم الآلي الأخرى، بحيث يمكن للفرق استخدام بنيتها التحتية الحالية. كما يوفر مجموعة متنوعة من الميزات لمراقبة نماذج اللغة الكبيرة، بحيث يمكن للفرق التأكد من أنها تعمل كما هو متوقع.
تم تصميم أدوات LLMOps من Comet للسماح للمستخدمين بالاستفادة من أحدث التطورات في إدارة المطالبات (Prompt Management) ونماذج الاستعلام في Comet للتكرار بشكل أسرع، وتحديد اختناقات الأداء، وتصور الحالة الداخلية لسلاسل المطالبات (Prompt Chains). يوفر Comet أيضًا تكاملات مع نماذج ومكتبات اللغة الكبيرة الرائدة مثل LangChain وOpenAI’s Python SDK. يتميز Comet بقدرته على تتبع التجارب عبر منصات تعلم آلي متعددة. كما يوفر مجموعة متنوعة من الميزات لإدارة مشاريع التعلم الآلي، بحيث يمكن للفرق تتبع تقدمها والتعاون بفعالية.
PromptLayer هي منصة لبناء ونشر نماذج اللغة الكبيرة (LLMs) كواجهات برمجة تطبيقات (APIs). توفر مجموعة متنوعة من الميزات لبناء نماذج اللغة الكبيرة، بما في ذلك مكتبة من المكونات الجاهزة وواجهة سحب وإفلات. يتميز PromptLayer بقدرته على نشر نماذج اللغة الكبيرة كواجهات برمجة تطبيقات. وهذا يسهل استخدام نماذج اللغة الكبيرة في مجموعة متنوعة من التطبيقات، مثل روبوتات الدردشة وأنظمة الإجابة على الأسئلة.
OpenPrompt هو إطار عمل مفتوح المصدر لبناء ونشر نماذج اللغة الكبيرة (LLMs). يوفر مجموعة متنوعة من الميزات لبناء نماذج اللغة الكبيرة، بما في ذلك مكتبة من المكونات الجاهزة وواجهة سطر أوامر. يتميز OpenPrompt بطبيعته مفتوحة المصدر. وهذا يسهل على الفرق تخصيص OpenPrompt لتلبية احتياجاتهم الخاصة.
Orquesta هي منصة لتنسيق مسارات التعلم الآلي. توفر مجموعة متنوعة من الميزات لتنسيق المسارات، بما في ذلك واجهة سحب وإفلات ومكتبة من المكونات الجاهزة. يتميز Orquesta بقدرته على تنسيق المسارات عبر منصات تعلم آلي متعددة. وهذا يسهل نشر مسارات التعلم الآلي في بيئة الإنتاج.
Pinceone هو محرك بحث متجهي مصمم لنماذج اللغة الكبيرة (LLMs). يمكن استخدامه للبحث عن نماذج اللغة الكبيرة بواسطة تمثيلاتها المتجهية، مما يسهل العثور على نموذج اللغة الكبيرة الأكثر تشابهاً لاستعلام معين. يتميز Pinceone بقدرته على البحث عن نماذج اللغة الكبيرة بواسطة تمثيلاتها المتجهية. على سبيل المثال، إذا كنت مهتمًا باستخدام نموذج اللغة GPT-3، يمكنك استخدام Pinceone للبحث عن نماذج اللغة الكبيرة المشابهة لـ GPT-3. سيعرض Pinceone بعد ذلك قائمة بنماذج اللغة الكبيرة التي لها تمثيلات متجهية مشابهة لـ GPT-3. وهذا سيتيح لك العثور بسهولة على نموذج اللغة الكبيرة الأنسب لاحتياجاتك.
Zilliz هي قاعدة بيانات متجهية مصممة لنماذج اللغة الكبيرة (LLMs). يمكن استخدامها لتخزين نماذج اللغة الكبيرة والاستعلام عنها، بالإضافة إلى تتبع أداء نماذج اللغة الكبيرة بمرور الوقت. يتميز Zilliz بقدرته على تخزين نماذج اللغة الكبيرة والاستعلام عنها بكفاءة. يعد Zilliz خيارًا جيدًا لتخزين نماذج اللغة الكبيرة والاستعلام عنها لأنه مصمم ليكون فعالاً مع كميات كبيرة من البيانات. وهذا يعني أنه يمكنك تخزين نماذج اللغة الكبيرة والاستعلام عنها في Zilliz دون الحاجة إلى القلق بشأن مشكلات الأداء.
Milvus هي قاعدة بيانات متجهية مصممة لتطبيقات التعلم الآلي واسعة النطاق. يمكن استخدامها لتخزين المتجهات والاستعلام عنها، بالإضافة إلى إجراء عمليات البحث عن التشابه. يتميز Milvus بقدرته على إجراء عمليات البحث عن التشابه بكفاءة. يعد Milvus خيارًا جيدًا لإجراء عمليات البحث عن التشابه على مجموعات البيانات الكبيرة لأنه مصمم ليكون فعالاً مع كميات كبيرة من البيانات. وهذا يعني أنه يمكنك إجراء عمليات البحث عن التشابه على مجموعات البيانات الكبيرة في Milvus دون الحاجة إلى القلق بشأن مشكلات الأداء.
Elastic هو محرك بحث مصمم لمجموعة متنوعة من التطبيقات، بما في ذلك البحث المتجهي. يمكن استخدامه للبحث عن المتجهات بواسطة تمثيلاتها المتجهية، بالإضافة إلى إجراء بحث التشابه. يتميز Elastic بمرونته وقابليته للتوسع. يعد Elastic خيارًا جيدًا للبحث المتجهي لأنه مرن وقابل للتوسع. وهذا يعني أنه يمكنك استخدام Elastic لمجموعة متنوعة من تطبيقات البحث المتجهي، ويمكنك توسيع نطاق Elastic لتلبية احتياجاتك.
فيسبا للذكاء الاصطناعي هو محرك بحث مصمم لتطبيقات التعلم الآلي واسعة النطاق. يمكن استخدامه لتخزين المتجهات والاستعلام عنها، بالإضافة إلى إجراء البحث عن التشابه. يتميز فيسبا للذكاء الاصطناعي بقدرته على إجراء البحث عن التشابه بكفاءة على نطاق واسع. يعد فيسبا للذكاء الاصطناعي خيارًا جيدًا للبحث عن التشابه واسع النطاق لأنه مصمم ليكون فعالاً مع كميات كبيرة من البيانات. هذا يعني أنه يمكنك إجراء البحث عن التشابه على مجموعات بيانات كبيرة في فيسبا للذكاء الاصطناعي دون الحاجة للقلق بشأن مشكلات الأداء.
سيرشيوم للذكاء الاصطناعي هو محرك بحث مصمم لتطبيقات معالجة اللغة الطبيعية. يمكن استخدامه للبحث عن المستندات النصية، بالإضافة إلى إجراء البحث عن التشابه في النصوص. يتميز سيرشيوم للذكاء الاصطناعي بقدرته على إجراء البحث عن التشابه في المستندات النصية. يعد سيرشيوم للذكاء الاصطناعي خيارًا جيدًا لتطبيقات معالجة اللغة الطبيعية لأنه مصمم ليكون فعالاً مع البيانات النصية. هذا يعني أنه يمكنك إجراء البحث عن التشابه في المستندات النصية في سيرشيوم للذكاء الاصطناعي دون الحاجة للقلق بشأن مشكلات الأداء.
كرومَا هو محرك بحث متجه مصمم لتطبيقات معالجة اللغة الطبيعية. يمكن استخدامه للبحث عن المستندات النصية، بالإضافة إلى إجراء البحث عن التشابه في النصوص. يتميز كرومَا بقدرته على إجراء البحث عن التشابه في المستندات النصية في الوقت الفعلي. يعد كرومَا خيارًا جيدًا للبحث عن التشابه في الوقت الفعلي لأنه مصمم ليكون فعالاً مع البيانات النصية. هذا يعني أنه يمكنك إجراء البحث عن التشابه في المستندات النصية في كرومَا دون الحاجة للقلق بشأن مشكلات الأداء.
فيرتش هو قاعدة بيانات متجهات مصممة لتطبيقات معالجة اللغة الطبيعية. يمكن استخدامه لتخزين المستندات النصية والاستعلام عنها، بالإضافة إلى إجراء البحث عن التشابه في النصوص. يتميز فيرتش بقدرته على تخزين المستندات النصية والاستعلام عنها بكفاءة. يعد فيرتش خيارًا جيدًا لتخزين المستندات النصية والاستعلام عنها لأنه مصمم ليكون فعالاً مع البيانات النصية. هذا يعني أنه يمكنك تخزين المستندات النصية والاستعلام عنها في فيرتش دون الحاجة للقلق بشأن مشكلات الأداء.
كوادرانت هو قاعدة بيانات متجهات مصممة لتطبيقات التعلم الآلي واسعة النطاق. يمكن استخدامه لتخزين المتجهات والاستعلام عنها، بالإضافة إلى إجراء عمليات البحث عن التشابه. يتميز كوادرانت بقدرته على إجراء البحث عن التشابه بكفاءة على نطاق واسع ودعمه للحوسبة الموزعة. يعد كوادرانت خيارًا جيدًا للبحث عن التشابه واسع النطاق والحوسبة الموزعة لأنه مصمم ليكون فعالاً مع كميات كبيرة من البيانات ويدعم الحوسبة الموزعة. هذا يعني أنه يمكنك إجراء البحث عن التشابه على مجموعات بيانات كبيرة في كوادرانت دون الحاجة للقلق بشأن مشكلات الأداء.
مع تزايد انتشار نماذج اللغة الكبيرة في مختلف التطبيقات، أصبح ضمان خصوصية البيانات مصدر قلق كبير. ستؤكد الاتجاهات المستقبلية في LLMOps على اعتماد تقنيات الحفاظ على الخصوصية لحماية البيانات الحساسة. التعلم الموحد هو أحد هذه الأساليب التي تكتسب زخمًا، حيث يتم تدريب النماذج مباشرة على أجهزة المستخدمين، ويتم مشاركة تحديثات النموذج المجمعة فقط مع الخادم المركزي. بهذه الطريقة، يمكن لـ LLMOps تخفيف مخاطر الخصوصية وبناء نماذج أكثر جدارة بالثقة دون المساس ببيانات المستخدم.
تتطلب الطبيعة كثيفة الموارد لنماذج اللغة الكبيرة جهودًا مستمرة لتحسين وضغط هذه النماذج. ستركز LLMOps المستقبلية على تطوير معماريات وخوارزميات أكثر كفاءة تحافظ على أداء عالٍ مع تقليل متطلبات الذاكرة والحوسبة. ستلعب تقنيات مثل التكميم (quantization) والتقطير (distillation) والتقليم (pruning) دورًا حاسمًا في إنشاء نماذج لغة كبيرة خفيفة الوزن ولكنها قوية، تكون أكثر قابلية للنشر والتوسع عبر مختلف الأجهزة والمنصات.
ستستمر المساهمات مفتوحة المصدر في دفع الابتكار والتعاون داخل مجتمع LLMOps. مع تحول نماذج اللغة الكبيرة إلى جزء أساسي من مشهد الذكاء الاصطناعي، سيساهم الباحثون والمطورون والممارسون بنشاط في أدوات ومكتبات وأطر عمل LLMOps. سيسرع هذا الجهد التعاوني من ممارسات LLMOps، ويحسن الضبط الدقيق للنماذج، ويعزز تطوير التطبيقات المتطورة.
مع تزايد اعتماد نماذج اللغة الكبيرة في التطبيقات الحيوية، يرتفع الطلب على قابلية التفسير والشرح. ستركز LLMOps المستقبلية على تقنيات لجعل هذه النماذج أكثر شفافية وقابلية للفهم. ستساعد طرق مثل تصور الانتباه، وخرائط البروز، والتفسيرات الخاصة بالنموذج في تقديم رؤى حول كيفية وصول نماذج اللغة الكبيرة إلى قراراتها، مما يعزز ثقة المستخدم ويمكّن من تصحيح الأخطاء وتحسين النماذج بشكل أفضل.
نماذج اللغة الكبيرة هي مجرد مكون واحد من أنظمة الذكاء الاصطناعي المعقدة. في المستقبل، ستمتد عمليات نماذج اللغة الكبيرة (LLMOps) إلى ما هو أبعد من الضبط الدقيق ونشر نماذج اللغة الكبيرة الفردية لتشمل التكامل السلس مع تقنيات الذكاء الاصطناعي الأخرى. سيسهل هذا التكامل أنظمة الذكاء الاصطناعي متعددة الوسائط، التي تجمع بين قدرات معالجة الرؤية والكلام واللغة لإنشاء حلول ذكاء اصطناعي أكثر شمولية وقوة.
لقد أحدث تطور نماذج اللغة الكبيرة ثورة في معالجة اللغة الطبيعية ومكّن من ظهور تطبيقات ذكاء اصطناعي رائدة. ومع ذلك، تتطلب إدارتها الفعالة ممارسات وعمليات متخصصة تندرج تحت مظلة عمليات نماذج اللغة الكبيرة (LLMOps).
تلعب LLMOps دورًا حاسمًا في مواجهة تحديات تطوير ونشر وصيانة نماذج اللغة الكبيرة. من خلال الالتزام بأفضل الممارسات، واعتماد أدوات ومنصات متخصصة، والاستفادة من التقنيات المتقدمة، يمكن لفرق LLMOps التغلب على التحديات الحسابية، وضمان جودة البيانات، وتحسين أداء النموذج.
مع استمرار تقدم مجال الذكاء الاصطناعي بوتيرة سريعة، ستظل LLMOps في طليعة الابتكار. ستركز الاتجاهات المستقبلية في LLMOps على تقنيات الحفاظ على الخصوصية، وتحسين النماذج، وقابلية التفسير لمعالجة المخاوف الأخلاقية والمتطلبات التنظيمية. ستعزز المساهمات مفتوحة المصدر التعاون وتبادل المعرفة داخل مجتمع LLMOps، مما يدفع تطوير أدوات وأطر عمل أكثر قوة.
علاوة على ذلك، سيؤدي تكامل نماذج اللغة الكبيرة مع تقنيات الذكاء الاصطناعي الأخرى إلى تطورات مثيرة، مما يتيح أنظمة ذكاء اصطناعي متعددة الوسائط ذات قدرات تحويلية. ومع تطور LLMOps، ستلعب دورًا حاسمًا في إطلاق العنان للإمكانات الكاملة لنماذج اللغة الكبيرة، مما يجعلها أكثر سهولة وكفاءة ومسؤولية في تطبيقات متنوعة في العالم الحقيقي.
ختامًا، تُعد LLMOps العمود الفقري للإدارة الناجحة لنماذج اللغة الكبيرة، ضمانًا لاستخدامها المسؤول وإطلاق العنان لقوتها في تشكيل مستقبل الذكاء الاصطناعي. ومع استمرار تقدم الذكاء الاصطناعي، ستُمهد LLMOps الطريق لتطبيقات ذكاء اصطناعي لغوية أكثر كفاءة وجدارة بالثقة وتحويلية.
TrueFoundry هي منصة كخدمة (PaaS) لنشر تعلم الآلة (ML) فوق Kubernetes تمكّن فرق تعلم الآلة من نشر ومراقبة النماذج في 15 دقيقة بموثوقية 100% وقابلية للتوسع، والقدرة على التراجع في ثوانٍ. إذا كنت تحاول الاستفادة من MLOps في مؤسستك، يسعدنا التحدث وتبادل الأفكار.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








أحدث الأخبار والمقالات والموارد تصلك مباشرة إلى بريدك الوارد
© 2026 جميع الحقوق محفوظة.











.png)
.webp)










.webp)
