




July 4, 2026
|
5 min read


احصل على وصول فوري إلى بيئة TrueFoundry مباشرة. انشر النماذج، ووجّه حركة مرور LLM، واستكشف المنصة بالكامل — بيئة الاختبار الخاصة بك جاهزة في ثوانٍ، ولا يلزم وجود بطاقة ائتمان.









Published: July 4, 2026
Blazingly fast way to build, track and deploy your models!
Large language models are rapidly becoming a core layer of enterprise software. What began as cloud-based experimentation with hosted APIs is now evolving into production-grade systems embedded across internal tools, customer-facing applications, and automated workflows.
As this shift happens, many organizations are encountering a hard reality: not all AI workloads can run in the public cloud.
Sensitive enterprise data, proprietary intellectual property, regulated workloads, latency-critical applications, and compliance obligations are driving teams to deploy LLMs within on-premise or private infrastructure. However, simply self-hosting models does not solve the larger operational problem. As more teams, applications, and models come online, organizations need a consistent way to control access, enforce policies, monitor usage, and manage costs across their LLM ecosystem.
This is where an LLM Gateway on-premise infrastructure becomes foundational.
Rather than allowing every application to integrate directly with individual models, an LLM Gateway introduces a centralized control layer that governs how models are accessed and used. In on-prem environments, this gateway becomes the backbone that enables enterprises to scale LLM adoption securely, compliantly, and efficiently without sacrificing visibility or control.
An LLM Gateway is a centralized access and governance layer that sits between applications and language models. Instead of applications calling models directly, all LLM requests flow through the gateway, which enforces security, routing, observability, and policy controls in one place.
In an on-premise setup, both the gateway and the models run entirely within the organization’s infrastructure - such as a data center, private cloud (VPC), or air-gapped environment. This ensures that prompts, responses, embeddings, and metadata never leave controlled boundaries.
At a high level, an on-prem LLM Gateway provides:
By abstracting model access behind a standardized API, the gateway decouples application development from model infrastructure. Teams can switch models, introduce fine-tuned versions, or enforce new governance rules without modifying application code.
In on-prem environments where infrastructure is finite, compliance requirements are strict, and operational complexity is high, this centralized gateway layer is what makes large-scale LLM adoption viable. It transforms self-hosted models from isolated deployments into a governed, production-ready AI platform.
Key Metrics for Evaluating Gateway
| Criteria | What should you evaluate ? | Priority | TrueFoundry |
|---|---|---|---|
| Latency | Adds <10ms p95 overhead for time-to-first-token? | Must Have | ✅ Supported |
| Data Residency | Keeps logs within your region (EU/US)? | Depends on use case | ✅ Supported |
| Latency-Based Routing | Automatically reroutes based on real-time latency/failures? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |

Running LLMs on-premise is rarely just an infrastructure decision. It is usually driven by non-negotiable enterprise requirements around data control, security, and governance. An LLM Gateway is what makes these deployments practical at scale.
Enterprises often handle sensitive inputs such as internal documents, customer records, source code, or classified data. In regulated environments, even transient prompt data leaving controlled infrastructure is unacceptable.
An on-prem LLM Gateway ensures that:
This is especially critical for organizations operating under strict data localization or sovereignty requirements.
Direct application-to-model integrations create fragmented security boundaries. Each service ends up managing its own credentials, permissions, and access logic making it difficult to enforce uniform security standards.
An LLM Gateway centralizes:
By routing all traffic through a single control layer, enterprises significantly reduce their attack surface and gain confidence in how models are accessed.
Regulatory frameworks increasingly require organizations to answer questions like:
An on-prem LLM Gateway provides built-in audit trails by default. Every request can be logged, metered, and traced without relying on individual application teams to implement compliance logic correctly.
This is essential for environments subject to GDPR, ITAR, HIPAA, or internal governance standards.
On-prem GPU resources are finite and expensive. Without centralized controls, teams can easily over-consume inference capacity or deploy inefficient workloads.
An LLM Gateway enables:
This allows organizations to treat LLM inference as a managed resource rather than an uncontrolled expense.
An on-prem LLM Gateway is not a single service.it is a layered infrastructure stack designed to control how models are accessed, governed, and operated within enterprise environments.
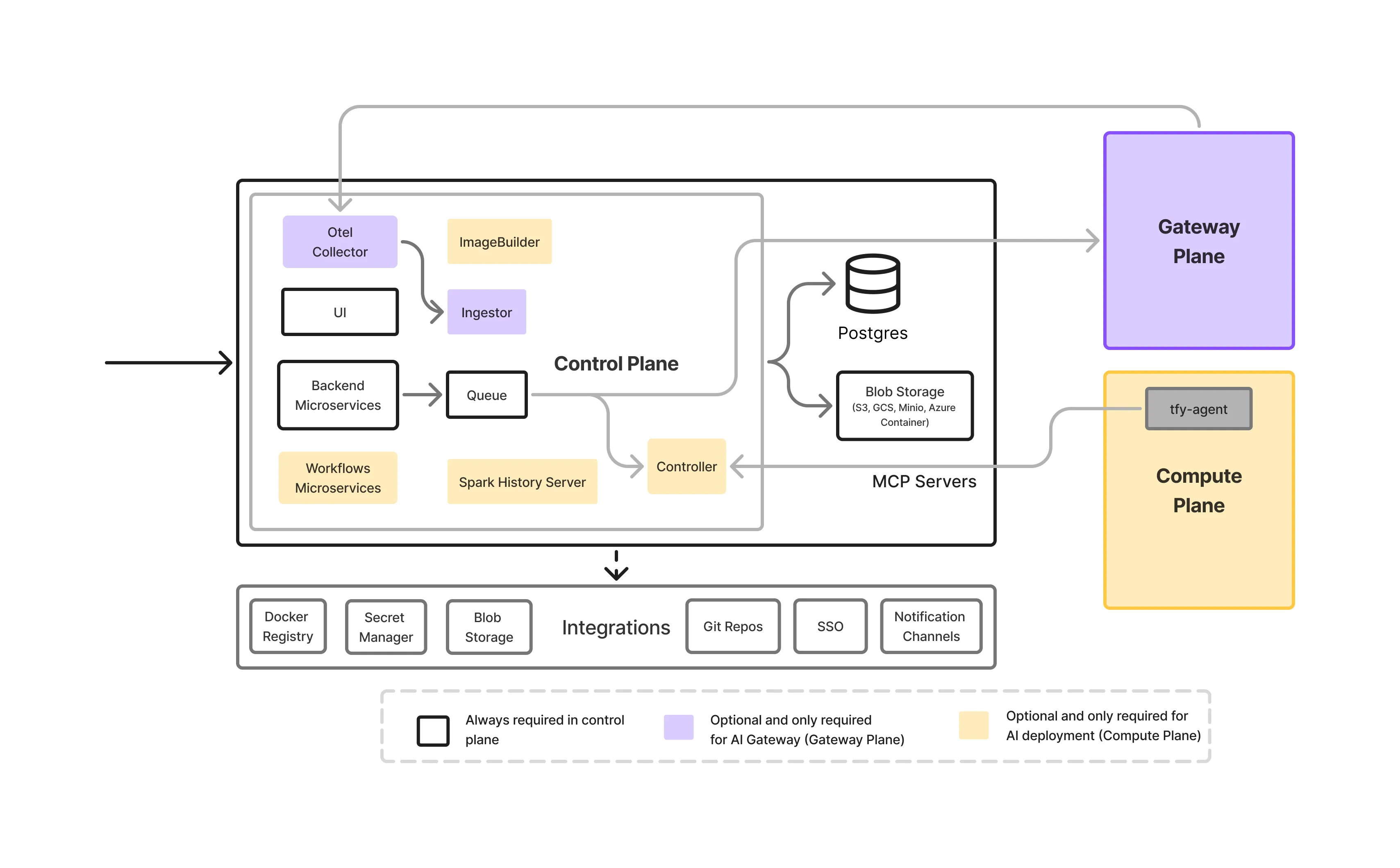
This is the front door for all LLM traffic.
It handles authentication, authorization, request validation, and routing decisions. By enforcing policies centrally, the control plane removes the need for application teams to embed security or governance logic in their code.
This layer is responsible for model serving, hosting the actual LLMs running on-premise and exposing them for low-latency, GPU-accelerated inference, including:
The gateway abstracts these models behind a unified API, allowing teams to change or upgrade models without impacting applications.
Visibility is critical in on-prem environments where resources are limited.
The gateway provides:
This enables teams to understand how models are being used and identify performance or cost issues early.
Governance rules are defined once and enforced everywhere.
This includes:
Centralized governance prevents policy drift across teams and applications.
تعمل خدمات البوابة والنماذج عادةً على بنية تحتية قائمة على Kubernetes مع دعم وحدات معالجة الرسوميات (GPU). توفر هذه الطبقة:
يضمن ذلك عمل البوابة بشكل موثوق كجزء من مكدس الذكاء الاصطناعي المحلي الأوسع.
في إعداد محلي، تعمل بوابة نماذج اللغة الكبيرة (LLM) كـ طبقة التحكم المركزية بين التطبيقات والنماذج المستضافة ذاتيًا. تمر جميع الطلبات عبر هذه الطبقة، مما يضمن أمانًا وحوكمة وقابلية مراقبة متسقة.
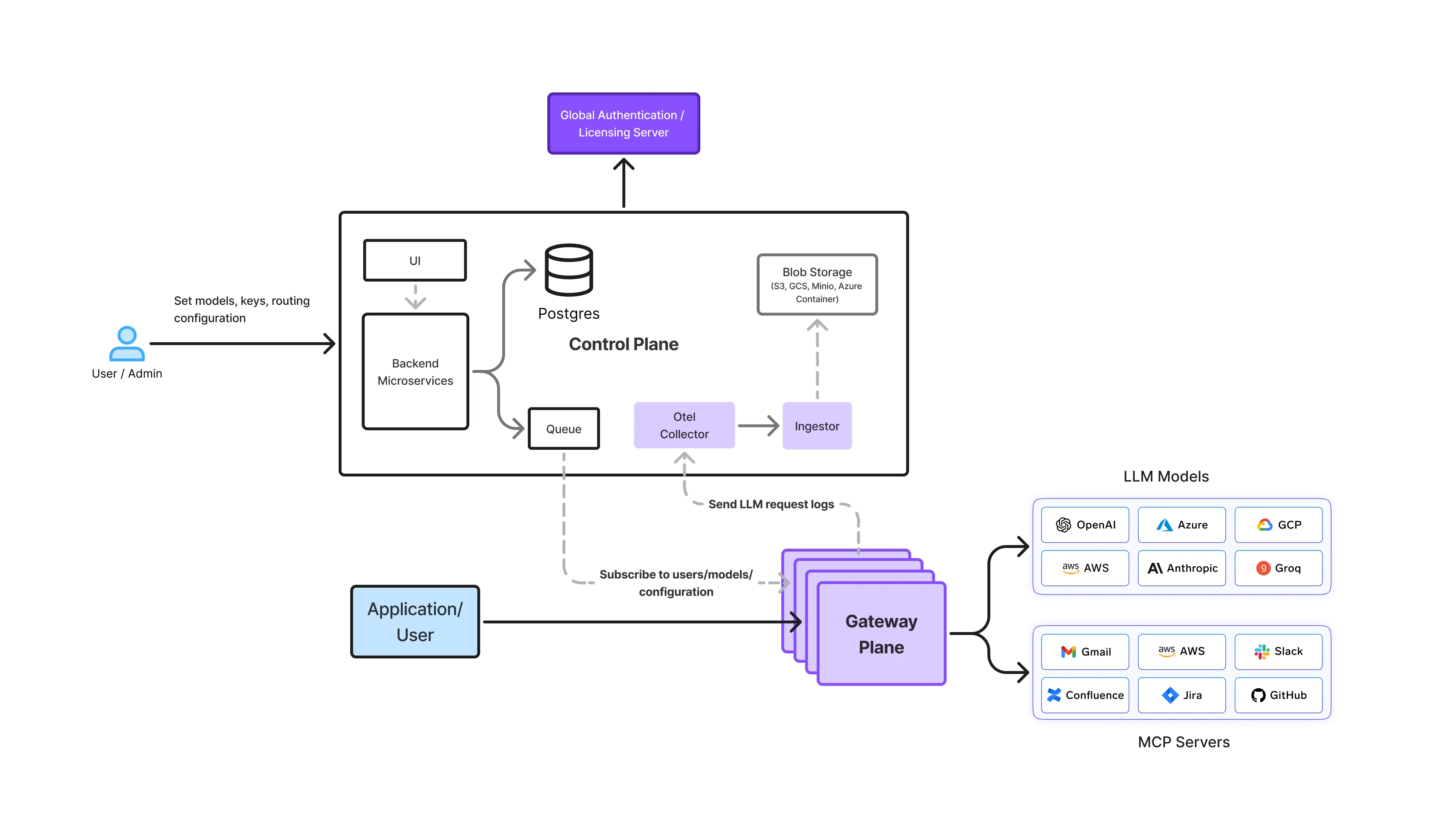
تنشر الشركات بوابات LLM المحلية بطرق مختلفة اعتمادًا على متطلبات الأمان والامتثال والاتصال. تظل بنية البوابة كما هي، ويتغير نموذج النشر.
في البيئات شديدة التنظيم، تعمل البنية التحتية بـ عدم وجود وصول لشبكة خارجية.
في هذه الإعدادات، توفر بوابة LLM تحكمًا كاملاً مع تلبية متطلبات العزل الصارمة.
تنشر العديد من الشركات بوابات LLM داخل حساباتها السحابية الخاصة أو شبكاتها الخاصة.
هذا النموذج شائع لمؤسسات SaaS المنظمة وخدمات المالية.
تقسم بعض المؤسسات أعباء العمل بناءً على حساسيتها.
تضمن البوابة سياسات متسقة حتى عند وجود بيئات تنفيذ متعددة.
بينما توفر بوابات LLM المحلية التحكم والامتثال، فإنها تقدم أيضًا تحديات تشغيلية يجب على الشركات التخطيط لها.
تتطلب إدارة أعباء عمل الاستدلال المدعومة بوحدات معالجة الرسوميات (GPU) محليًا تخطيطًا دقيقًا للقدرة. بدون أتمتة، يمكن أن يصبح توسيع النماذج أو التعامل مع ذروات حركة المرور مرهقًا من الناحية التشغيلية.
تتمتع البيئات المحلية بقدرة حوسبة محدودة. يمكن أن يؤدي التوجيه السيئ أو نقص ضوابط الطلبات إلى مشكلات في زمن الاستجابة أو وحدات معالجة رسوميات (GPU) غير مستغلة بالكامل. تعد إدارة حركة المرور المركزية ضرورية لتحقيق التوازن بين الأداء والكفاءة.
مع اعتماد فرق متعددة لـ LLMs، يمكن أن تنحرف قواعد الحوكمة بسهولة إذا تم تطبيقها على مستوى التطبيق. يصعب الحفاظ على ضوابط وصول وسياسات استخدام متسقة عبر البيئات بدون بوابة مركزية.
يجب على الشركات الاحتفاظ بسجلات واضحة لاستخدام LLM دون إرهاق التخزين أو التأثير على الأداء. تحقيق التوازن الصحيح بين قابلية المراقبة والتكاليف الإضافية يمثل تحديًا شائعًا.
الشركات التي تنجح في عمليات نشر LLM المحلية تتعامل مع البوابة على أنها بنية تحتية أساسية، وليست مجرد وكيل واجهة برمجة تطبيقات (API).
يجب على جميع التطبيقات والوكلاء الوصول إلى النماذج حصريًا عبر البوابة. وهذا يلغي عمليات التكامل الخفية ويضمن أمانًا وحوكمة موحدين.
يجب ألا تعتمد التطبيقات أبدًا على نقاط نهاية نماذج محددة. فتجريد النماذج خلف البوابة يسمح للفرق بتبديل النماذج أو ترقيتها أو ضبطها بدقة دون تغييرات في الكود.
يجب أن تكون ضوابط الوصول، وحدود المعدل، وقواعد الاستخدام موجودة في طبقة البوابة - وليس داخل منطق التطبيق. وهذا يمنع تباين السياسات عبر الفرق والبيئات.
يجب عزل بيئات التطوير والاختبار والإنتاج على مستوى البنية التحتية والسياسات. وهذا يقلل المخاطر ويجعل التجريب أكثر أمانًا.
اجمع بيانات القياس عن بعد الكافية للمراجعة والتحسين، مع إخفاء أو تقييد بيانات المطالبات الحساسة عند الضرورة. يجب أن تُمكّن المراقبة من التحكم، لا أن تُدخل مخاطر جديدة.
يضمن اتباع هذه الممارسات أن تظل بوابات نماذج اللغة الكبيرة المحلية آمنة وقابلة للتطوير وسهلة الإدارة مع تزايد الاعتماد عليها.
مع تجاوز الشركات مرحلة التجريب ودمج نماذج اللغة الكبيرة في الأنظمة الأساسية، يصبح التحكم بنفس أهمية الإمكانية. تعالج عمليات النشر المحلية احتياجات إقامة البيانات والأمان والامتثال، ولكن بدون طبقة وصول مركزية، سرعان ما تتجزأ ويصعب إدارتها.
توفر بنية تحتية لبوابة نماذج اللغة الكبيرة المحلية مستوى التحكم المفقود هذا. فهي توحد طريقة تفاعل التطبيقات مع النماذج، وتفرض سياسات متسقة، وتوفر الرؤية اللازمة لتشغيل نماذج اللغة الكبيرة بمسؤولية وعلى نطاق واسع.
اختيار الـ أفضل بوابة LLM يتطلب النشر المحلي الموازنة بين الحوكمة والأداء والبساطة التشغيلية، بدلاً من الاقتصار على توجيه الطلبات.
بدلاً من التعامل مع النماذج المستضافة ذاتيًا كخدمات معزولة، تقوم المؤسسات التي تتبنى نهج البوابة أولاً بتحويل نماذج LLM إلى بنية تحتية مؤسسية مُدارة - آمنة وقابلة للمراقبة وجاهزة للنمو على المدى الطويل.
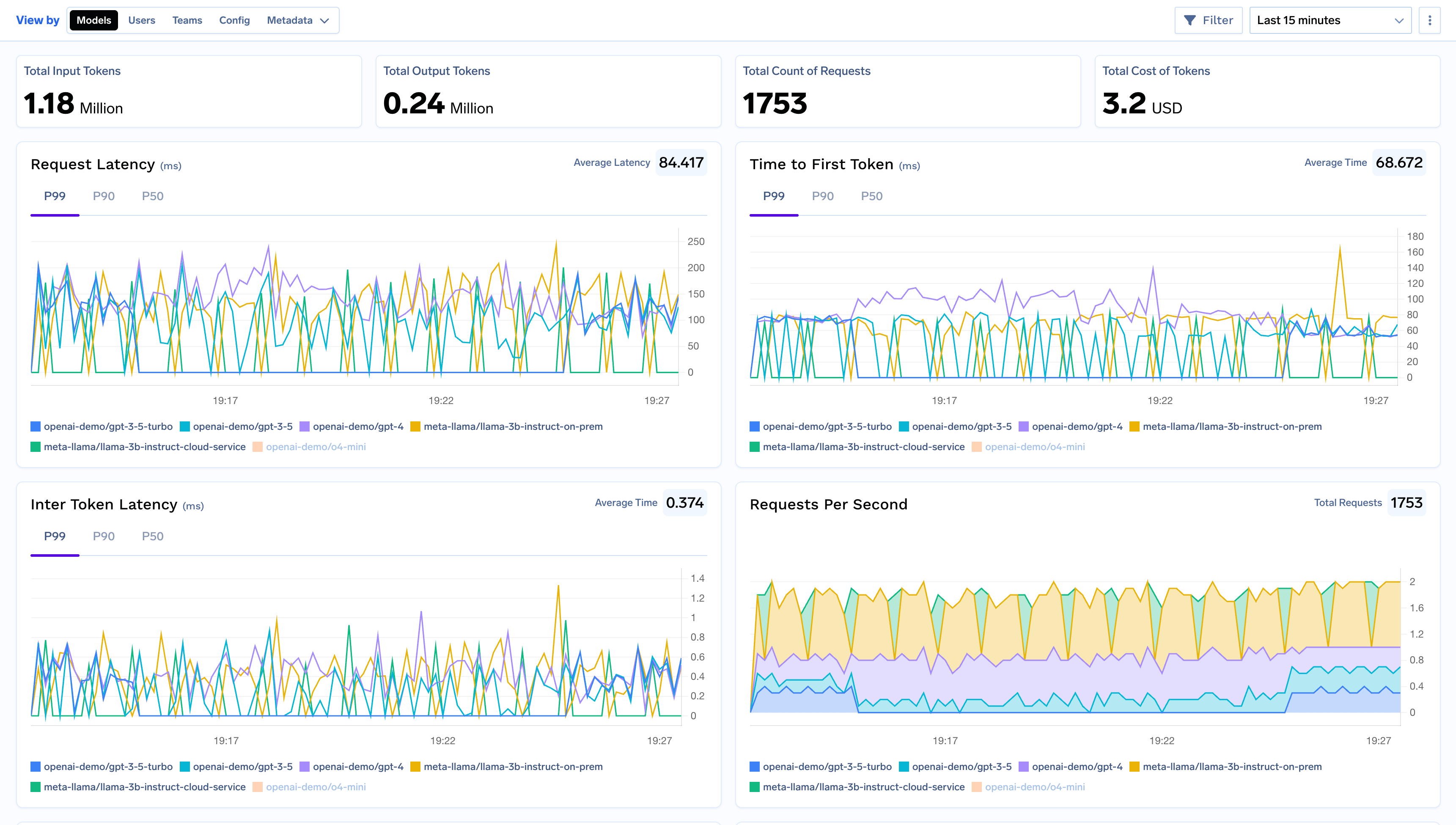
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








أحدث الأخبار والمقالات والموارد تصلك مباشرة إلى بريدك الوارد
© 2026 جميع الحقوق محفوظة.







.png)
.webp)










.webp)
