




July 20, 2023
|
5 min read


احصل على وصول فوري إلى بيئة TrueFoundry مباشرة. انشر النماذج، ووجّه حركة مرور LLM، واستكشف المنصة بالكامل — بيئة الاختبار الخاصة بك جاهزة في ثوانٍ، ولا يلزم وجود بطاقة ائتمان.









Published: July 4, 2026
Blazingly fast way to build, track and deploy your models!
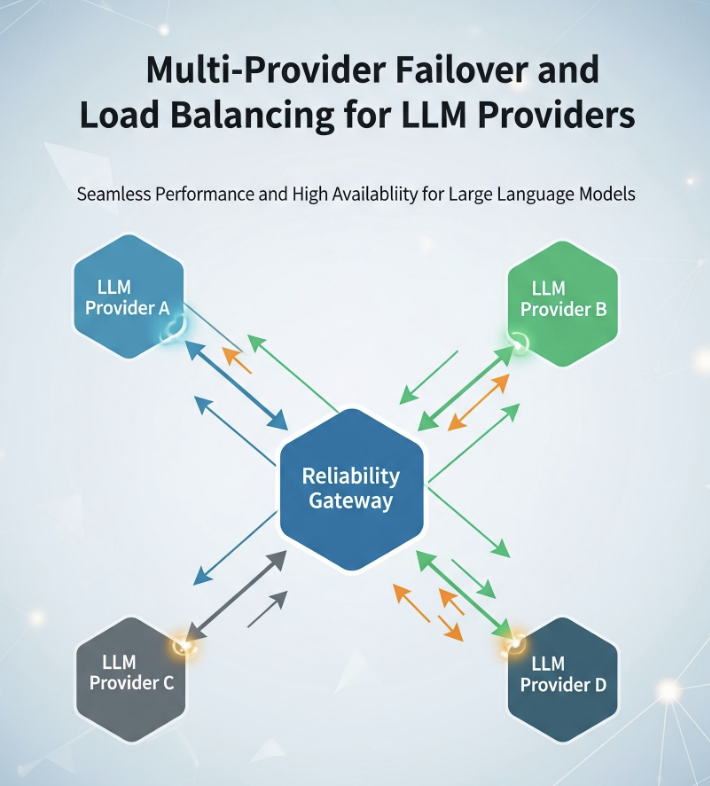
Every model provider has bad days — regional outages, rate-limit storms under load, latency that degrades without quite failing. If your application calls one provider directly, that provider's worst day is your worst day. This post is the reliability layer that prevents it: a taxonomy of how LLM calls fail, retries that don't make things worse, fallback chains across providers, health-aware load balancing, circuit breakers that fail fast, and the genuinely hard case of failing over mid-stream.
2:14 a.m. at Northwind. Nadia, an SRE, woke to a page: the customer-facing support agent was returning errors to every user. Not some users — every user. Northwind's own services were healthy; CPU, memory, and queues were all nominal. The errors were identical: 503 from the model provider. A regional incident on the provider's side had taken its inference endpoint down, and Northwind's agent called that endpoint directly. Every request hit the dead endpoint, failed, and returned an error to the customer. For forty minutes, until the provider recovered, there was nothing to do but wait — the agent had exactly one way to get a completion, and it was down.
The postmortem's action item wasn't "pick a more reliable provider." Every provider has incidents. It was "never depend on a single provider for a request that has to succeed." That is a gateway problem, and this post is how to solve it: retries that don't make things worse, fallback chains across providers, health-aware load balancing, and circuit breakers that fail fast instead of dragging your whole system down with the provider.
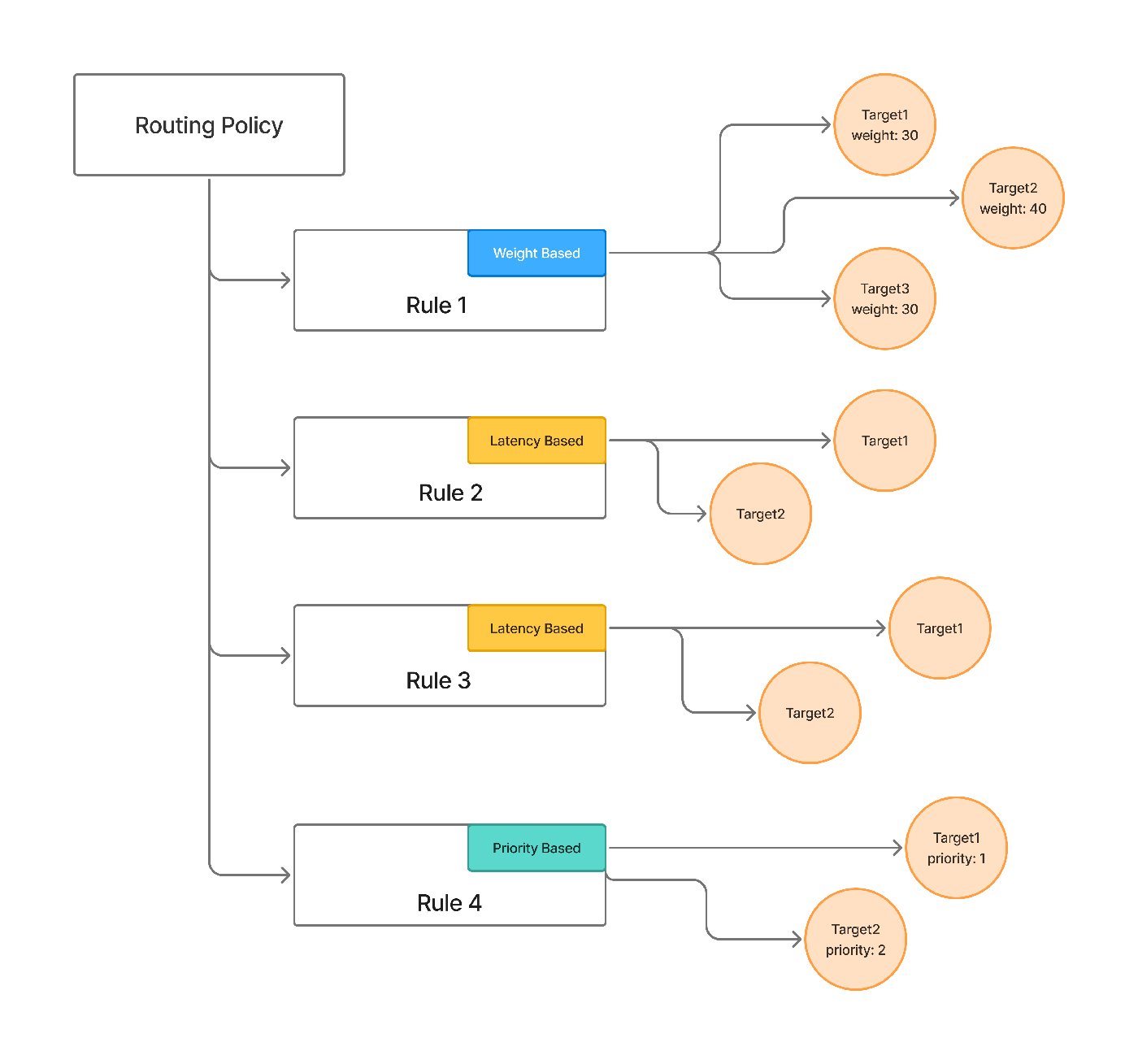
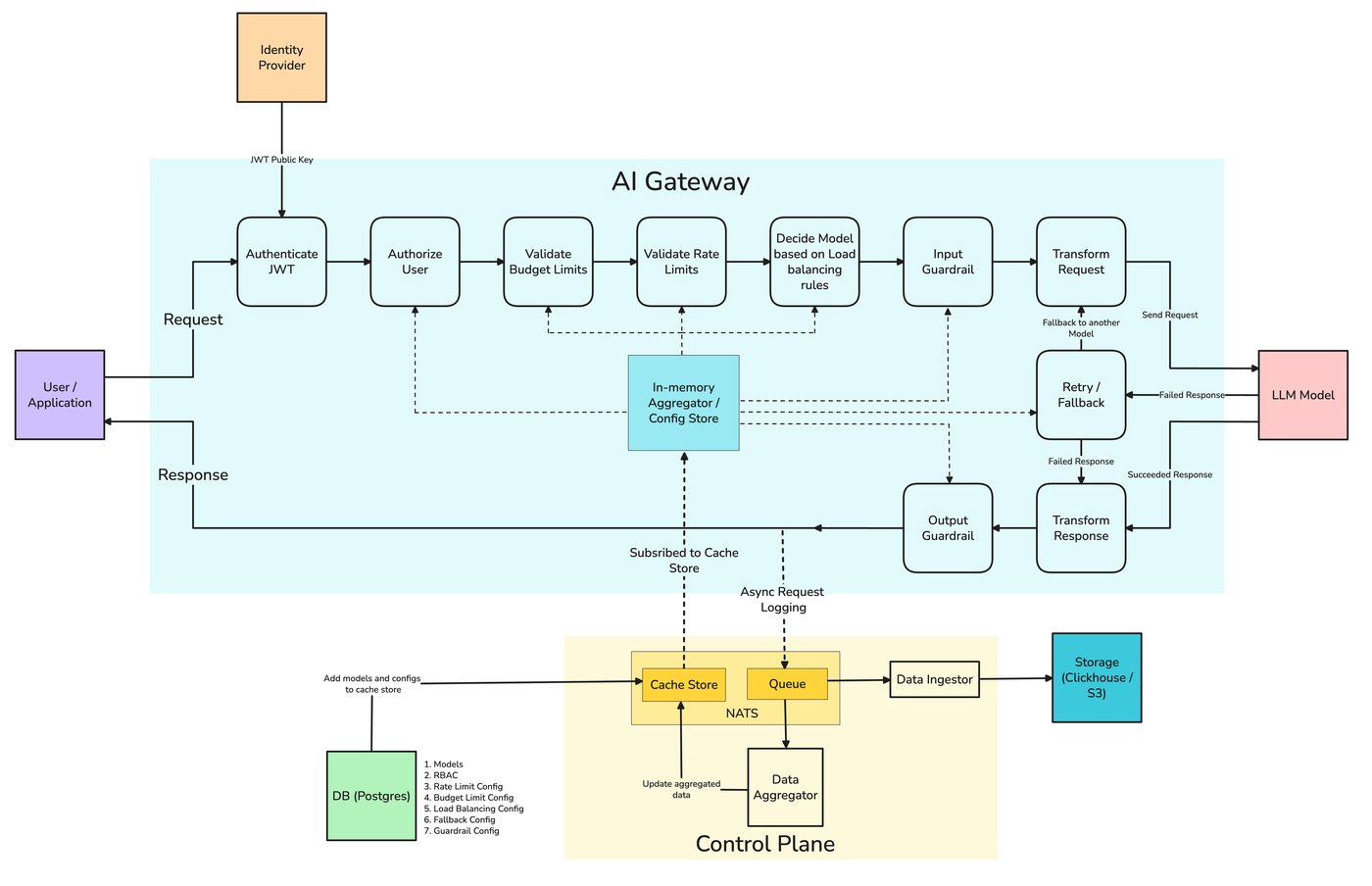
Everything in this post — retries, fallback chains, health-aware load balancing — is something TrueFoundry's AI Gateway expresses as configuration rather than per-service code. Its routing configuration defines load-balancing, fallback, and retry rules in YAML, evaluates them in order so the first matching rule wins, and applies them centrally to every request instead of being reimplemented in each app.
The pieces map onto the failure taxonomy below. Each target carries its own retry_config — attempts, delay, and the status codes worth retrying (429/500/502/503 by default) — and a separate fallback_status_codes list moves the request to the next target when retries won't help. Priority-based routing gives an ordered failover chain; latency-based routing favors the lowest-latency healthy target; and an unhealthy target is detected from its requests-, tokens-, and failures-per-minute and sidelined for a cooldown. The docs even cover the hard streaming case from section 8 — provider-specific stream-overload handling so a fall-through can happen before any user-visible tokens are emitted.
Calling the gateway from an application is a one-line change for anything already using the OpenAI SDK — same client, different base URL and key — so the reliability policy lives in config, not code:
# Calling the gateway from Python (OpenAI-compatible API)
from openai import OpenAI
client = OpenAI(
base_url="https://<your-truefoundry-gateway-url>", # your gateway endpoint
api_key="<your-personal-access-token>", # Bearer-auth'd JWT
)
resp = client.chat.completions.create(
model="gpt-5.5", # the gateway resolves retries + fallback per the config
messages=[{"role": "user", "content": "Summarize the document."}],
)
print(resp.choices[0].message.content)Production LLM applications depend on infrastructure they don't control. Providers have regional and global outages, they return 429s when you exceed a rate limit (and sometimes when they're simply overloaded), and their latency degrades under load without returning an error at all. A direct integration makes the provider a single point of failure: there is no path to a completion except the one that's down.
The work that fixes this — retries, fallback, load balancing, circuit breaking — is cross-cutting. Every service that calls a model needs it, and implementing it per service means each one reimplements the same logic and drifts from the others, so the agent team's retry policy and the search team's are subtly different and both are subtly wrong. The gateway is the one component that sees every provider, holds every key, and normalizes the API to a single shape — which is exactly what failing over from one provider to another requires. Centralizing reliability at TrueFoundry's AI Gateway means one policy, applied uniformly, with the failover events landing on the same request traces as the rest of your telemetry.
The most common reliability mistake is treating every failure as "error, retry." Different failures want different responses, and the table below is the map. Getting this wrong is how a rate limit becomes an outage.
The last row is the one teams get wrong most often: a content-filter rejection is a property of the request, not a transient fault. Retrying it wastes time and money, and failing over to another provider often just produces the same rejection — so it should be classified as non-retryable and surfaced, not silently looped. A separate remediation path may rewrite the prompt, ask the user to clarify, or route to a safer workflow, but that is a policy flow, not failover. Encoding this table once at the gateway — which signal maps to retry, fall back, or surface — means every service inherits the same classification rather than reinventing it; applying that mapping uniformly is part of what TrueFoundry's AI Gateway centralizes.
Retries are the first line of defense and the easiest to weaponize against yourself. Three rules make them safe: exponential backoff (wait longer after each failure), jitter (randomize the wait so clients don't retry in lockstep), and honoring the provider's rate-limit headers — Retry-After where it's sent, or remaining/reset headers like x-ratelimit-* where that's the provider's contract (when the server tells you when to come back, listen).
The failure they prevent is the thundering herd. When a provider starts returning 429s under load and every client retries immediately and in sync, the retries themselves sustain the overload — a self-inflicted denial of service that keeps the provider pinned exactly when you need it to recover. Jitter de-synchronizes the retries, backoff reduces the pressure over time, and Retry-After respects the provider's own signal about when capacity will return. Equally important is not retrying what won't succeed: a malformed request or a content-filter rejection is a 4xx that will fail identically on the next attempt, so retrying it just adds latency and cost.
# Exponential backoff with jitter; honor Retry-After; cap attempts
for attempt in range(MAX_ATTEMPTS): # keep MAX small — 2–3 — then fall back
resp = call(provider, req)
if resp.ok:
return resp
if resp.status == 429 and resp.retry_after:
sleep(resp.retry_after) # respect the server's hint
elif resp.retryable: # 5xx, timeout
sleep(min(CAP, BASE * 2 ** attempt) * random.uniform(0.5, 1.0))
else:
break # non-retryable (4xx, content filter) — stop
raise Exhausted(provider) # hand off to the fallback chain
A consistent retry policy is exactly the kind of thing that drifts when each service owns its own. Applied at TrueFoundry's AI Gateway, the backoff, jitter, and Retry-After handling are uniform across every service that routes through it, and the retry-then-fall-back boundary is one configured behavior rather than five slightly different ones.
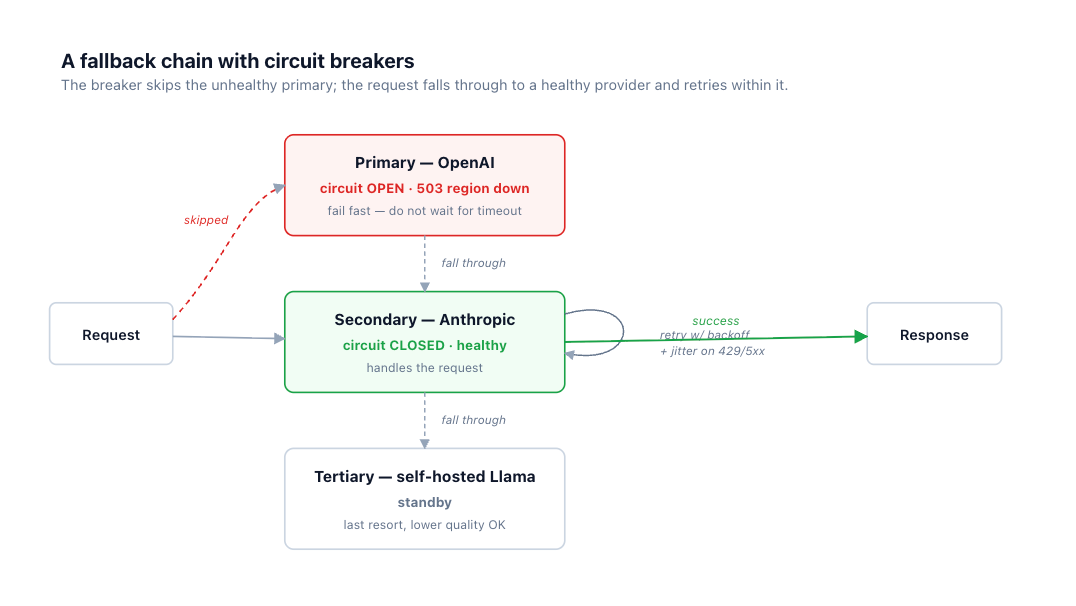
When retries against the primary are exhausted, a fallback chain keeps the request alive: primary, then secondary, then tertiary. There are two axes. Across providers (Claude, then GPT, then Gemini) gives independent failure domains — different infrastructure, different incidents, so the secondary is unlikely to be down for the same reason as the primary. Within a provider (an alternate region or deployment) is cheaper to set up but shares a failure domain, so it protects against a localized issue rather than a provider-wide one.
Illustrative fallback chain (conceptual — exact schema is gateway-specific)
fallbacks:
- provider: openai/gpt-5.5
- provider: anthropic/claude-sonnet-4-6 # different vendor = independent failure domain
- provider: self-hosted/llama-3.x # last resort; lower quality acceptable to stay up
trigger_on: [5xx, timeout, circuit_open] # NOT content-filter rejections
This isn't only a pattern — it's how TrueFoundry's AI Gateway is configured. A fallback chain is a priority-based routing rule: each target gets a priority, its own retry policy, and the status codes that should trigger a fall-through to the next target — spanning hosted and self-hosted models behind one OpenAI-compatible API, so the fallback can be a different vendor or your own model without the application knowing:
How TrueFoundry expresses the same chain (gateway-load-balancing-config)
name: reliability-config
type: gateway-load-balancing-config
rules:
- id: chat-failover
type: priority-based-routing # ordered chain: priority 0, then 1, then 2
when:
models: [gpt-5.5]
load_balance_targets:
- target: openai/gpt-5.5
priority: 0
retry_config: { attempts: 2, on_status_codes: ["429","500","502","503"] }
fallback_status_codes: ["429","500","502","503"]
- target: anthropic/claude-sonnet-4-6 # different vendor = independent failure domain
priority: 1
- target: self-hosted/llama-3.x # last resort; lower quality OK
priority: 2Retries happen within a target via retry_config; fallback_status_codes decide when to give up and move to the next. The gateway's request-level view records which targets were tried and why a fall-through happened, so failover is debuggable rather than inferred — and the full schema, including weight- and latency-based strategies, is in the routing config docs.
A second pattern worth seeing — an on-prem primary with a cloud fallback, the layout most regulated workloads land on — drops in the same way:
On-prem primary with cloud fallback (from the docs)
name: loadbalancing-config
type: gateway-load-balancing-config
rules:
- id: priority-failover
type: priority-based-routing
when:
models: [gpt-4]
load_balance_targets:
- target: onprem/llama
priority: 0
fallback_status_codes: ["429", "500", "502", "503"]
- target: bedrock/llama
priority: 1
retry_config:
attempts: 2
delay: 100Under the hood, the failover system has to be more reliable than what it protects — so the gateway runs every rate-limit, load-balancing, and auth check in memory, with no external hop on the request path, and ships logs and metrics asynchronously through a NATS queue so a downed log pipeline never fails a live request. The published benchmark is 350 RPS on 1 vCPU / 1 GB RAM with ~7 ms overhead at 200 RPS even with tracing on. The gateway plane is also stateless and keeps serving traffic from its last synced config if the control plane is briefly unavailable — useful precisely when an incident is in progress. TrueFoundry packages these properties into truefailover™, an outage-resilience product layered on the gateway that adds multi-region, multi-cloud, and degradation-aware routing on top of the multi-model failover above.
Load balancing does two jobs: spread traffic so no single backend or key becomes the bottleneck, and keep traffic off backends that are unhealthy. The common strategies are weighted round-robin (split by capacity), least-latency (favor the fastest healthy backend), and least-loaded (favor the one with the fewest in-flight requests).
There's a throughput point worth getting right: headroom comes from independent quota pools, not from extra keys. Separate providers, deployments, regions, or separately provisioned projects and accounts each carry their own limits, so distributing load across them genuinely adds capacity. What does not work is assuming more API keys inside the same organization multiply your quota — most providers enforce rate limits at the organization, project, or model-family level, so keys under one org share one pool. (OpenAI, for instance, states that additional keys under the same organization do not raise your limits, and some model families share a pool.) The balancer should route against the real remaining capacity reported in provider rate-limit headers, not a per-key assumption. Health checks come in two flavors: active (periodically probe each backend) and passive (watch real traffic and mark a backend unhealthy when its error rate crosses a threshold — which is circuit breaking, the next section). Passive is cheaper and reflects the conditions your actual requests are hitting. Balancing across providers and keys is a core function of TrueFoundry's AI Gateway, which is the natural place to do it because it already holds the keys and sees the per-backend latency and error rates the balancer needs.
When a provider is down, continuing to send it traffic is actively harmful. Every request waits for a timeout before failing, those waiting requests pile up, your queues back up, and the provider's outage cascades into your own latency and resource exhaustion. A circuit breaker stops this by failing fast.
It's a small state machine. Closed is normal operation. After errors cross a threshold — a high error rate over a window, or N consecutive failures — the breaker trips to open: requests to that provider fail immediately (or skip straight to the fallback) without waiting for a timeout. After a cooldown, it moves to half-open and lets a single probe request through; if the probe succeeds, the breaker closes and normal traffic resumes, and if it fails, the breaker re-opens for another cooldown. The effect is that a dead provider costs you one fast rejection per request instead of one full timeout, which is the difference between a clean failover and a cascading slowdown.
Circuit breaker — stop sending to a provider that's failing
if breaker.state == "open":
if breaker.cooldown_elapsed():
breaker.state = "half_open" # probe with one request
else:
raise SkipProvider # fail fast → fall through to the chain
resp = call(provider, req)
breaker.record(resp) # closes on success, re-opens on failed probe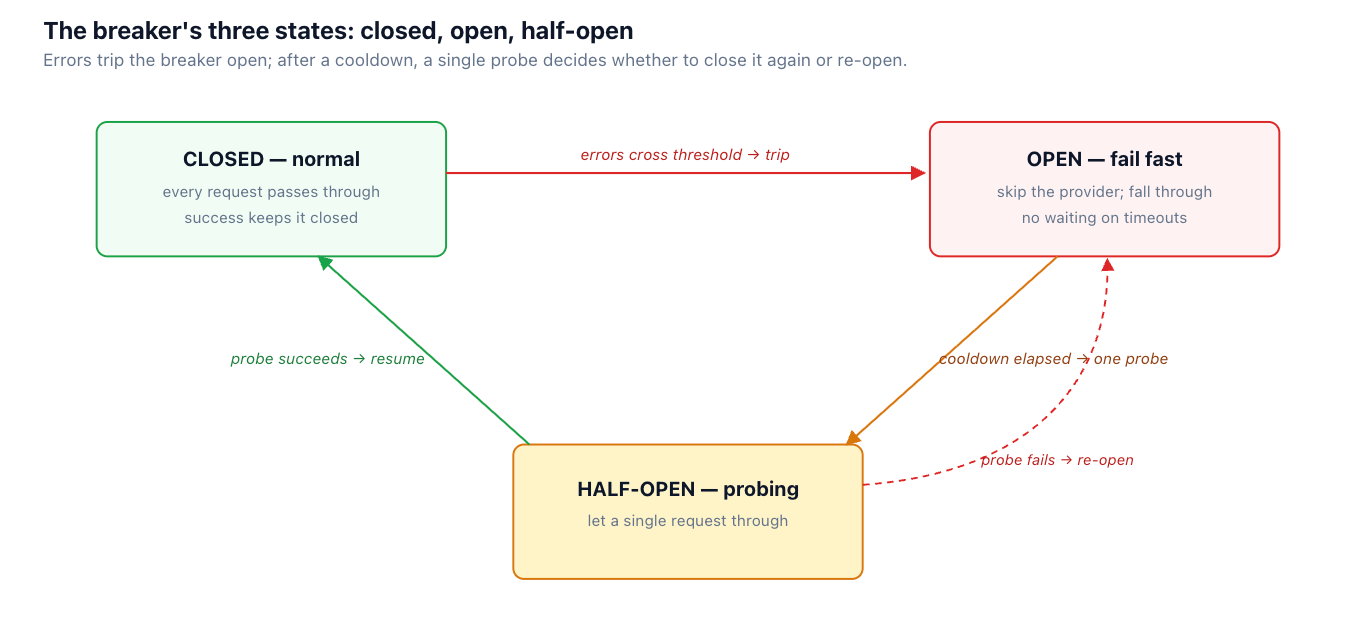
As in the fallback diagram earlier, the primary's breaker is open after a run of 503s, which is why the request skips it without waiting. Health-aware routing at TrueFoundry's AI Gateway applies this across providers so an unhealthy backend is bypassed at the gateway rather than rediscovered, request by request, inside every service.
Some reliability problems aren't outages — they're the tail. Most requests are fast, but p99 is slow because a few of them happen to hit a provider during a slow moment. Hedging attacks the tail: after a short delay, send the same request to a second provider and take whichever response comes back first. The slow tail gets cut because you're no longer hostage to one provider's worst-case latency on any given call.
The cost is real and worth stating plainly: when the hedge fires, you pay for two calls. Cancel the loser once the winner returns, but don't assume cancellation makes it free — depending on the provider and how far generation progressed, the cancelled call can still bill for partial tokens, so track both attempts. The way to keep that affordable is to fire the hedge only after a delay tuned to your latency profile — say, around the p95 — so you hedge only the slow tail rather than every request. Two caveats: hedging duplicates any side effects if the call isn't idempotent (a non-issue for pure completions, something to think about for tool-calling agents), and it adds load to providers, so it's a tail-latency tool, not a default. Hedging is naturally a gateway concern for the same reason load balancing is — the gateway already sees both providers and can fire and reconcile the second call — so it belongs as a per-route policy alongside the fallback and load-balancing controls TrueFoundry's AI Gateway already centralizes, rather than as bespoke per-service code.
None of these controls has a universal value, but here are defensible starting points to tune from — not settings to copy blindly:
كل ما سبق يفترض أنه يمكنك إعادة محاولة أو إعادة توجيه الطلب بسلاسة. البث يكسر هذا الافتراض. إذا كنت قد قمت بالفعل ببث مائتي رمز للمستخدم وتوقف البث، فلا يمكنك التبديل بين المزودين بشفافية — فالمزود الجديد يبدأ من البداية، لذا إما أن تعيد تشغيل الإخراج المرئي (مما يسبب إرباكًا) أو تحاول دمج مخرجات نموذجين معًا (مما يؤدي إلى عدم الاتساق). لا يوجد حل عالمي واضح لهذه المشكلة.
الخيارات العملية هي مجموعة من المقايضات. يمكنك تخزين البث مؤقتًا على جانب الخادم وإصداره فقط عند اكتماله أو التحقق منه، مما يجعل تجاوز الفشل سلسًا ولكنه يتخلى عن فائدة زمن الاستجابة المتصور التي دفعتك إلى استخدام البث في المقام الأول. يمكنك قبول أن حالات الفشل في منتصف البث تؤدي إلى إعادة التشغيل وتصميم تجربة المستخدم لتحمل ذلك. أو، في المسارات الحيوية، يمكنك التأكد من أن المزود يعمل برمز أول غير مبثوث قبل الالتزام بالبث. هذا هو نفس التوتر الذي أثارته مناقشة البث في منشورات هندسة السياق والمعلومات الشخصية من الاتجاه الآخر: البث يقايض قابلية الاسترداد والتحكم اللاحق بزمن الاستجابة. تعامل مع تجاوز الفشل في البث كقرار متعمد لكل مسار، وليس إعدادًا عامًا — فالإجابة الصحيحة لوكيل دفعات داخلي تختلف عن الإجابة الصحيحة لدردشة موجهة للعملاء. ولأن هذا الاختيار خاص بالمسار، فإنه ينتمي إلى حيث توجد سياسات المسار الأخرى: نوع التكوين الخاص بالمسار بوابة الذكاء الاصطناعي من TrueFoundry يركز، بحيث يمكن لمسار الدردشة ومسار الدفعات اتخاذ خيارات تخزين مؤقت متعارضة ضمن تكوين واحد.
هل هو احتياطي عبر المزودين أم ضمن المزود؟
كلاهما، بالترتيب. الاحتياطي ضمن المزود (منطقة/نشر بديل) غير مكلف ويتعامل مع المشكلات المحلية، ولكنه يتشارك نطاق فشل، لذا فإن حادثًا على مستوى المزود يعطل الطبقة بأكملها. الاحتياطي عبر المزودين يوفر نطاقات فشل مستقلة وهو ما ينقذك في انقطاع مثل الافتتاحية الباردة — على حساب تباين أكبر في المخرجات، نظرًا لأنك تقدم الخدمة الآن من نموذج مختلف. عادةً ما تحاول السلسلة القوية نشرًا بديلاً أولاً، ثم تنتقل إلى بائع مختلف.
ألن يؤدي التحول إلى نموذج آخر إلى تغيير مخرجاتي؟
نعم — هذه هي المقايضة المذكورة في القسم 4. تجاوز الفشل يضمن التوفر على حساب الدقة، لأن النموذج الاحتياطي ينسق ويرفض ويستدل بشكل مختلف. تحقق من مخرجات الاحتياطي مقابل نفس مخطط النموذج الأساسي، خاصة للاستجابات المهيكلة، واجعل المطالبات قابلة للنقل حتى لا يبدأ الاحتياطي من مطالبة تم ضبطها فقط للنموذج الأساسي.
كم عدد المحاولات التي يجب أن أقوم بتكوينها؟
قليل — عادة اثنان أو ثلاثة — مع تراجع أسي، وتذبذب، واحترام رأس "Retry-After". المزيد من المحاولات ضد مزود معطل بالفعل يؤخر فقط الاحتياطي الذي كان سينجح، ويضيف حملاً في اللحظة التي يعاني فيها المزود. الهدف هو تجاوز عطل قصير، ثم التسليم، وليس ضرب نقطة نهاية ميتة.
هل يجب أن أتحوط لكل طلب؟
لا. التحوط لكل شيء يضاعف تكلفة المزود والحمل. قم بتفعيل التحوط فقط بعد تأخير مضبوط بالقرب من p95 الخاص بك بحيث يستهدف الذيل البطيء، وفقط في المسارات التي يكون فيها زمن الاستجابة للذيل مهمًا بالفعل. بالنسبة للمكالمات غير المتكررة، كن حذرًا — فالتحوط يمكن أن يكرر الآثار الجانبية.
هل يجب أن يكون هذا في التطبيق أم في البوابة؟
البوابة. فهي ترى كل مزود ومفتاح، وتوحد واجهة برمجة التطبيقات بحيث يمكن أن يكون هدف الاحتياطي بائعًا مختلفًا دون تغييرات في التطبيق، ويمكنها تطبيق سياسة متسقة واحدة لإعادة المحاولة/الاحتياطي/قاطع الدائرة عبر جميع الخدمات. تتشتت تطبيقات كل خدمة وتكرر نفس المنطق. تتتبع البوابة أيضًا أحداث تجاوز الفشل، بحيث يكون "لقد تحولنا إلى الاحتياطي لأن الأساسي كان مفتوحًا" مرئيًا بدلاً من استنتاجه — وهو ما يرتبط بعمل التكلفة والمراقبة في وقت سابق من هذه السلسلة.
لم يكن انقطاع ناديا بحاجة إلى مزود أفضل؛ بل كان بحاجة إلى مزود ثانٍ وسياسة لاستخدامه. الموثوقية لحركة مرور نماذج اللغة الكبيرة هي نفس الانضباط لأي تبعية أخرى — محاولات إعادة تحترم الخادم، واحتياطيات عبر نطاقات فشل مستقلة، وقواطع دوائر تفشل بسرعة — تُطبق على الطبقة التي ترى كل مزود في وقت واحد.
بوابة الذكاء الاصطناعي من TrueFoundry هي لوحة تحكم على مستوى المؤسسات تقع بين تطبيقاتك وأكثر من 1600 نموذج — عبر OpenAI، وAnthropic، وGoogle، وAWS Bedrock، وAzure OpenAI، ونماذجك المستضافة ذاتيًا — خلف واجهة برمجة تطبيقات واحدة متوافقة مع OpenAI. إنها تحول أنماط الموثوقية في هذا المنشور إلى تكوين بدلاً من كود خاص بكل خدمة: سلاسل الاحتياطي، وموازنة التحميل الموزونة والقائمة على زمن الاستجابة، وإعادة المحاولات، والتوجيه المدرك للحالة الصحية، وكلها تُعرف مرة واحدة وتُطبق على كل طلب.
نظرًا لأن البوابة تحتفظ بالمفاتيح، وتوحّد كل مزود، وتسجل تكلفة كل طلب، وزمن الاستجابة، والأخطاء، وبيانات تتبع الفشل الاحتياطي، فهي المكان الطبيعي لجعل تجاوز الفشل تلقائيًا وقابلاً للمراقبة. يتم نشرها كخدمة (SaaS)، في شبكتك الافتراضية الخاصة (VPC)، أو في الموقع (on-prem)، أو في بيئة معزولة (air-gapped)، مع صلاحيات التحكم بالوصول المستندة إلى الأدوار (RBAC)، والميزانيات، وحدود المعدل، وآليات الحماية المضمنة، وتتوافق مع معايير SOC 2 و HIPAA و ITAR — وهي معترف بها في دليل السوق للبوابات الذكاء الاصطناعي من Gartner. يمكنك استكشاف ميزات الموثوقية في مستندات موازنة التحميل والفشل الاحتياطي أو اطلع على نظرة عامة على بوابة الذكاء الاصطناعي.
Northwind و Nadia هما مثالان توضيحيان. تصنيف أنماط الفشل وأنماط إعادة المحاولة، والفشل الاحتياطي، وموازنة التحميل، وقاطع الدائرة هي هندسة موثوقية قياسية مطبقة على حركة مرور نماذج اللغة الكبيرة (LLM). الأرقام المحددة — محاولتان إلى ثلاث محاولات، التحوط بالقرب من p95 — هي نقاط بداية تمثيلية، وليست إعدادات عالمية؛ قم بضبطها لتناسب حركة المرور الخاصة بك، وأهداف مستوى الخدمة (SLOs)، وحدود المزود. تأتي سعة حدود المعدل من مجمعات حصص مستقلة (مزودين أو مشاريع أو حسابات منفصلة)، وليس من مفاتيح إضافية تحت منظمة واحدة.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








أحدث الأخبار والمقالات والموارد تصلك مباشرة إلى بريدك الوارد
© 2026 جميع الحقوق محفوظة.









.png)
.webp)










.webp)
