




July 4, 2026
|
5 min read


احصل على وصول فوري إلى بيئة TrueFoundry مباشرة. انشر النماذج، ووجّه حركة مرور LLM، واستكشف المنصة بالكامل — بيئة الاختبار الخاصة بك جاهزة في ثوانٍ، ولا يلزم وجود بطاقة ائتمان.









Published: July 4, 2026

Blazingly fast way to build, track and deploy your models!
Large Language Models (LLMs) have taken the AI world by storm—but they’re just the beginning. The real magic happens when LLMs evolve into agents: intelligent, goal-driven systems that can reason, make decisions, and take actions autonomously. LLM agents are transforming how we build AI products, enabling everything from automated research assistants to complex multi-step task solvers. In this ultimate guide, we’ll break down what LLM agents are, how they work, different types, real-world use cases, and the challenges they face. Whether you're a developer, founder, or AI enthusiast—this guide will give you a crystal-clear understanding of the future of intelligent agents.
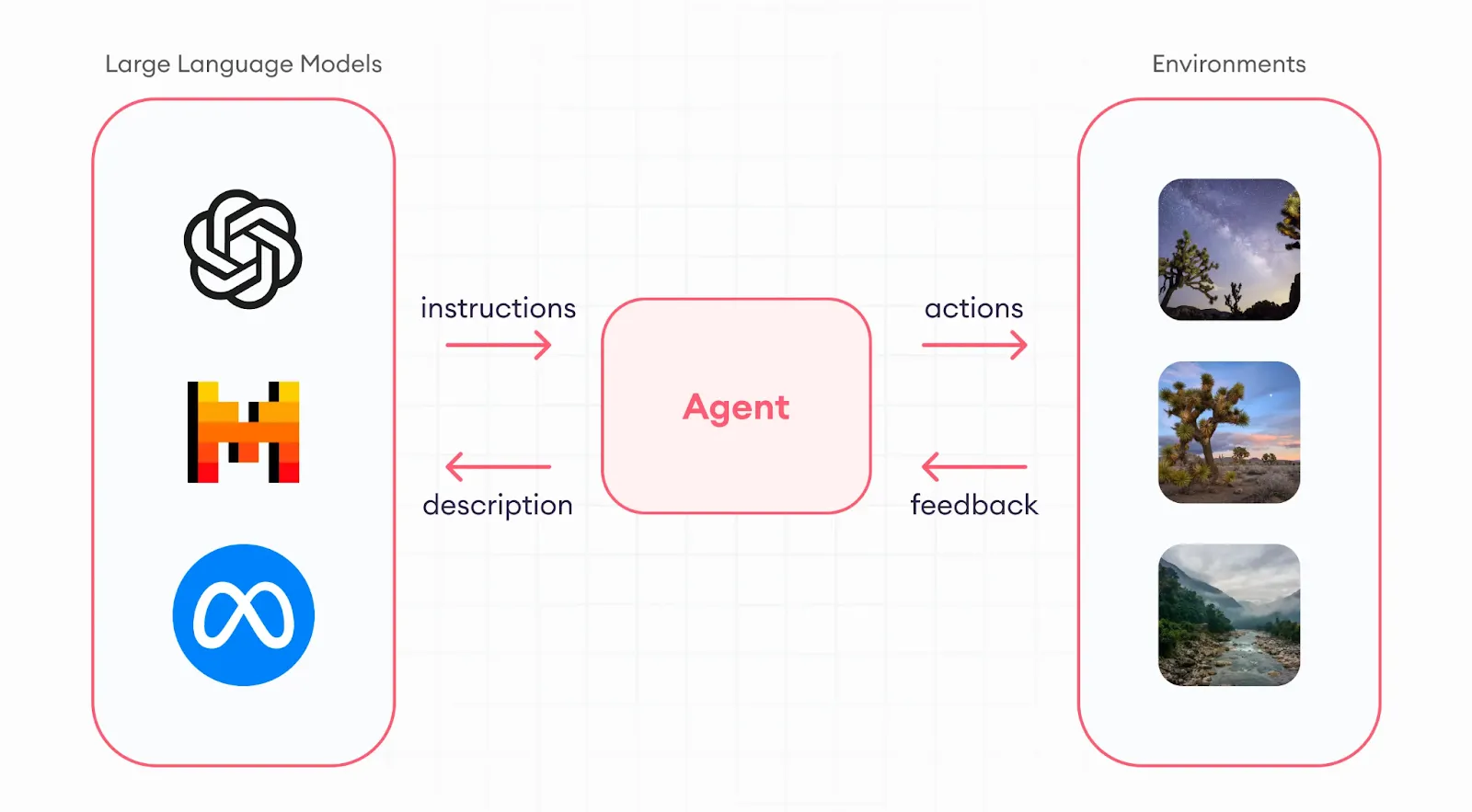
LLM agents are intelligent systems built on top of Large Language Models, designed not just to respond to prompts—but to take action. They can plan, reason, use tools, maintain memory, and operate autonomously to complete multi-step tasks. In simple terms, they transform passive LLMs into goal-oriented AI entities.
While a standard LLM like GPT-4 or Claude responds to a single prompt in isolation, an LLM agent has an objective and a looping process: it evaluates the task, decides what to do next, executes actions (like calling a tool or searching a database), observes the result, and continues until the goal is achieved.
This is possible because agents add multiple layers around the base language model:
LLM agents operate by layering structure, memory, and decision-making capabilities on top of a foundational Large Language Model. At a high level, an LLM agent follows a sense-think-act loop—observing its environment or inputs, reasoning about the next step, and executing actions toward a defined goal.
The workflow typically begins with a user query or task. Instead of responding immediately like a traditional LLM, the agent breaks down the task, determines if external tools are needed, decides what actions to take, and continues interacting with the environment until the objective is met. Each of these steps depends on repeated LLM inferencing, where the model evaluates intermediate context before deciding the next action.
Key Steps in an LLM Agent’s Workflow:
Task Initialization
The agent receives input or is assigned a goal—such as “generate a competitor report” or “book a meeting based on email context.”
Planning
It uses the LLM to generate a plan, often by thinking through the steps in natural language or selecting from predefined options.
Tool Selection and Invocation
If tools are available—like search engines, APIs, code interpreters, or databases—the agent decides which one to use and forms structured calls to access them.
Observation and Feedback Loop
Once a tool returns a result, the agent evaluates the output. It decides whether the information is sufficient, if further action is needed, or if the task is complete.
Memory (Optional)
In more advanced setups, the agent maintains short-term or long-term memory to track previous interactions, store knowledge, or build user profiles.
Iteration Until Goal Completion
This loop continues—plan, act, observe—until the agent achieves its intended result or reaches a termination condition.
As LLM agents continue to evolve, they’re being designed in a variety of forms based on complexity, autonomy, and purpose. While all agents are built on the foundation of a large language model, the way they plan, interact with tools, and handle tasks varies significantly. Broadly, LLM agents can be grouped into several types:
Task-Specific Agents
These agents are built to perform well-defined, narrow tasks. They follow pre-set workflows or logic but still benefit from the flexibility of an LLM to handle edge cases or ambiguity. For example:
They are often used in production because they are easier to test, validate, and control.
Autonomous Agents
These agents operate with minimal human intervention and can decide how to approach a task. Given a broad objective like “research market trends and write a report,” the agent will plan the process, gather data, analyze it, and generate a report—all on its own.
Autonomous agents typically include memory, recursive loops, and even self-correction mechanisms. AutoGPT and BabyAGI are examples of open-source projects that demonstrate this kind of agent behavior.
Tool-Using Agents
This category includes agents that rely heavily on external tools, APIs, and environments to complete their objectives. They may not be fully autonomous, but they excel at calling functions, fetching data, or running scripts when needed.
These agents use strategies like ReAct (Reasoning + Acting) or OpenAI’s function calling to decide:
They’re ideal for enterprise scenarios where the agent needs to integrate with CRMs, databases, or internal APIs.
Multi-Agent Systems
Instead of one agent doing everything, multiple agents with specialized roles collaborate to achieve a complex task. For example, one agent could gather research, another could verify data, and a third could summarize insights. They communicate, pass context, and resolve conflicts when needed.
Frameworks like CrewAI and MetaGPT enable such multi-agent coordination.
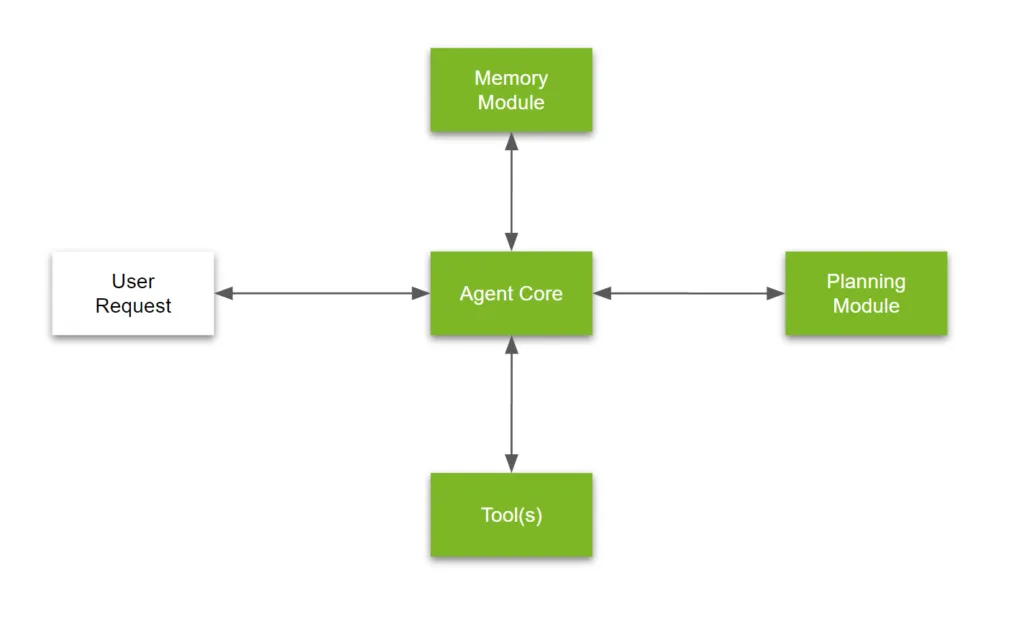
An LLM agent is not a single model or script—it’s a modular system designed to think, remember, interact, and act autonomously. This architecture is typically made up of four core components: the agent core, memory module, tools, and planning module. These parts work together to transform a raw language model into a capable, goal-driven agent.
1. Agent Core
At the center of the agent is the language model itself—often a foundation model like GPT-4, Claude, LLaMA 2, or Mistral. This component is responsible for understanding inputs, generating responses, and reasoning through tasks.
While powerful, the model on its own is reactive. It needs supporting logic to become proactive. The agent core acts as the “brain”, interpreting prompts and instructions, but it depends on the other modules to carry out actions, remember the context, and solve complex problems.
2. Memory Module
Memory allows the agent to retain information across steps, interactions, or sessions. This makes the agent more adaptive and personalized over time.
This module may be implemented using a vector database, a document store, or even structured key-value storage depending on the agent's needs.
3. Tools
The tools layer is what gives agents real-world utility. It allows the agent to go beyond language generation and actually take action.
Tools can include:
When the agent identifies a gap in its own knowledge or capabilities, it can call a tool, process the result, and continue with the task. This gives LLM agents a plugin-like extensibility that scales to enterprise use cases.
4. Planning Module
This is where the agent becomes goal-oriented. The planning module enables it to break down complex tasks, decide the order of operations, and loop through actions intelligently.
It handles:
Without planning, agents are just one-shot responders. With it, they can navigate uncertainty, iterate, and self-correct.
One of the most critical capabilities that separates LLM agents from standard language models is their ability to leverage tools. This allows agents to interact with the real world—fetching up-to-date information, performing calculations, accessing databases, or triggering actions. Without tools, agents are limited to their pre-trained knowledge and remain purely reactive. With tools, they become interactive, task-completing systems.
At a high level, tool usage in LLM agents follows a simple cycle:
Tool Abstraction and Invocation
Tools are typically exposed to the agent as function signatures or tool schemas. These can be custom-defined or registered via a framework like LangChain, OpenAI’s Function Calling, ReAct, or AgentOps. The agent doesn't execute code directly—instead, it generates a structured function call (like a JSON object), which is handled by an execution layer in the backend.
For example, consider a weather-checking tool:
{
"tool": "get_weather",
"inputs": {
"location": "New York City"
}
}
The agent determines that weather information is needed, constructs this tool invocation, and then the backend executes the function (an API call in this case). The result is fed back to the agent core, which continues reasoning.
When and Why Tools Are Used
LLM agents invoke tools when:
Tools are the agent’s bridge to external systems. They expand the agent’s capability from a “smart text generator” to an "مساعد يتخذ الإجراءات".
استراتيجية استخدام الأدوات: ReAct والتخطيط
تستخدم معظم الوكلاء الحديثين نموذج ReAct (الاستدلال + الفعل). يستدل الوكيل على ما يجب فعله بعد ذلك، ويختار أداة، ويراقب المخرجات، ويستمر حتى إنجاز المهمة. تسمح هذه الحلقة المحكمة بحل المشكلات متعدد الخطوات، والتحقق، والتصحيح.
في الأنظمة الأكثر تقدمًا، تحدد وحدات التخطيط الأداة التي يجب استخدامها في كل خطوة من سير العمل—مثل شجرة القرار، التي يتم بناؤها ديناميكيًا بناءً على سياق المهمة.
يمثل وكلاء نماذج اللغة الكبيرة (LLM) قفزة كبيرة في كيفية تطبيق الذكاء الاصطناعي عبر مهام العالم الحقيقي. من خلال الجمع بين قوة الاستدلال لنماذج اللغة الكبيرة مع الذاكرة والتخطيط واستخدام الأدوات، يتحول الوكلاء من كونهم مساعدين ثابتين إلى متعاونين مستقلين. يفتح هذا التحول المعماري مجموعة من الفوائد الملموسة عبر المجالات التقنية والتجارية على حد سواء.
الاستقلالية والاستدلال متعدد الخطوات
على عكس نماذج اللغة الكبيرة التقليدية التي تستجيب لمطالبات فردية، يمكن للوكلاء إدارة سير العمل المعقدة عن طريق تقسيم المهام، واستدعاء الأدوات، والتكرار حتى إنجاز المهمة. هذه الاستقلالية تجعلهم مناسبين لتنفيذ عمليات الأعمال متعددة الخطوات—مثل تحليل مجموعة بيانات، وتلخيص الرؤى، وإنشاء عرض تقديمي، وإرسال النتائج عبر البريد الإلكتروني—كل ذلك دون تدخل بشري.
التفاعل في الوقت الفعلي مع الأنظمة
من خلال دمج الأدوات، يمكن للوكلاء جلب البيانات الحية، والتفاعل مع واجهات برمجة التطبيقات (APIs)، وحتى معالجة الملفات أو قواعد البيانات. هذه القدرة على الوصول إلى معلومات محدثة تزيل قيود المعرفة الثابتة المتأصلة في النماذج المدربة مسبقًا. بالنسبة للشركات، هذا يعني أن الوكلاء يمكنهم التفاعل مع أنظمة إدارة علاقات العملاء (CRMs)، وأنظمة التحليلات، والتقويمات، والأدوات الداخلية—مما يجعلها مفيدة تشغيليًا فور استخدامها.
الوعي بالسياق والتخصيص
تمنح وحدات الذاكرة الوكلاء القدرة على الحفاظ على السياق عبر التفاعلات. يتيح لهم ذلك تذكر تفضيلات المستخدم، وتتبع الخطوات السابقة، وتخصيص المخرجات. بمرور الوقت، يمكن للوكلاء تكييف نبرتهم ومحتواهم وتوصياتهم بناءً على سلوك المستخدم المتعلم—مما يوفر تجربة أقرب إلى البشر.
قابلية التوسع عبر حالات الاستخدام
وكلاء نماذج اللغة الكبيرة (LLM) قابلة للتركيب بدرجة عالية. يمكن إعادة استخدام نفس جوهر الوكيل عبر الأقسام (مثل المبيعات والتسويق والمالية) عن طريق تغيير الأدوات ومنطق التخطيط المحيط به. هذه النمطية تسرع وقت تحقيق القيمة وتقلل من جهود التطوير الزائدة.
زيادة الكفاءة وتوفير التكاليف
من خلال أتمتة المهام المتكررة أو التحليلية، يحرر الوكلاء القدرات البشرية. يمكن للفرق التركيز على الاستراتيجيات وصنع القرار ذات القيمة الأعلى، بينما يتولى الوكلاء المهام التشغيلية—مما يؤدي إلى تحسينات قابلة للقياس في الإنتاجية والتكاليف التشغيلية.
Here's The Evaluation Framework for Proposal Template
| Criteria | What should you evaluate ? | Priority | TrueFoundry |
|---|---|---|---|
| Unified API & Routing | |||
| Unified OpenAI-compatible endpoint | Is the gateway API compatible with OpenAI's /v1/chat/completions and /v1/responses formats, allowing consistent access across different models through a standardized interface? | Must have | ✅ Supported: OpenAI-compatible endpoint across all providers. |
| Provider and model coverage | Does it support leading providers like OpenAI, Azure OpenAI, Amazon Bedrock, Anthropic, Gemini, Groq, plus self-hosted models? | Must have | ✅ Supported: 1000+ LLMs across hosted and self-hosted providers. |
| Model onboarding speed | How quickly can new models (OpenAI-compatible and non-standard APIs) be added without code changes? | Must have | ✅ Supported: config-driven onboarding within minutes. |
| Multimodal support | Does the gateway support text, vision, audio, image generation, and embeddings through a single interface? | Depends on use case | ✅ Supported: chat, embeddings, images, audio, rerank, and realtime APIs. |
| Routing, load balancing, fallback | Can requests be routed by model, provider, latency, priority, weight, region, and failure state with automatic retries? | Must have | ✅ Supported: load balancing, fallbacks, weighted and latency-based routing. |
| Model switching without code change | Is model switching supported via headers or config without changing client code? | Must have | ✅ Supported: header-based and config-based model switching. |

وكلاء نماذج اللغة الكبيرة (LLM) هي أنظمة قوية، لكن تعقيدها يقدم العديد من التحديات الهندسية والتشغيلية. من دقة القرار إلى موثوقية النظام، يتطلب بناء وكلاء قويين وجاهزين للإنتاج أكثر من مجرد توصيل نموذج لغة كبير (LLM) بحلقة مطالبة. فيما يلي بعض التحديات الأكثر شيوعًا—بالإضافة إلى أمثلة بسيطة لتوضيح تأثيرها.
ال هلوسة وأخطاء القرار
لا تزال نماذج اللغات الكبيرة (LLMs) قادرة على توليد معلومات واثقة ولكنها غير صحيحة أو مضللة — وهي ظاهرة تُعرف بالهلوسة. في مسار عمل الوكيل (agent pipeline)، يمكن أن يتسبب هذا في تتابع من الإجراءات الخاطئة.
سوء استخدام الأدوات وفشل الاستدعاء
يجب على الوكلاء استدعاء واجهات برمجة التطبيقات (APIs) أو الأدوات بشكل صحيح باستخدام مدخلات منظمة. ومع ذلك، فإن توليد التنسيق الصحيح أو التعامل مع الحالات الهامشية ديناميكيًا عرضة للأخطاء.
زمن الاستجابة والتكاليف الإضافية
يؤدي الاستدلال متعدد الخطوات وتسلسل الأدوات إلى ارتفاع زمن الاستجابة وتكاليف رموز النموذج، خاصة إذا تم استخدام نماذج كبيرة لكل خطوة.
تعقيد الذاكرة
تعد إدارة ما يجب تذكره، وما يجب نسيانه، وكيفية استرجاع الذاكرة ذات الصلة بكفاءة تحديًا مستمرًا.
الأمن والخصوصية والضوابط الوقائية
غالبًا ما تتعامل الوكلاء مع أنظمة وبيانات حساسة. بدون ضوابط وقائية، يمكنهم كشف المنطق الداخلي أو تسريب بيانات خاصة في الردود.
تصحيح الأخطاء وقابلية المراقبة
الوكلاء ليسوا حتميين. بدون الأدوات المناسبة، من الصعب تتبع سبب فشل الوكيل أو كيف اتخذ قرارًا.
لم تعد وكلاء نماذج اللغات الكبيرة (LLM) مجرد مفاهيم نظرية — بل يتم تطبيقها بالفعل في مختلف الصناعات لأداء مهام مستقلة، وأتمتة سير العمل، والتفاعل مع المستخدمين بذكاء. دعنا نلقي نظرة على بعض الأمثلة العملية التي توضح كيفية عمل وكلاء نماذج اللغات الكبيرة في بيئات حقيقية.
AutoGPT و BabyAGI
أظهرت هذه المشاريع مفتوحة المصدر فكرة الوكلاء المستقلين القادرين على تنفيذ المهام دون إشراف بشري. عند إعطائه هدفًا عالي المستوى مثل "تحليل المنافسين وتوليد استراتيجية"، سيقوم AutoGPT بتخطيط الخطوات، والبحث في الويب، وكتابة الملخصات، وتقييم النتائج، وتعديل خطته بشكل متكرر. وبينما لا تزال هذه الوكلاء تجريبية وتتطلب ضوابط وقائية، فقد أثارت اهتمامًا كبيرًا في حلقات تنفيذ المهام المستقلة.
وكلاء LangChain
يوفر LangChain إطار عمل لبناء الوكلاء باستخدام مكونات معيارية مثل قوالب الأوامر، وواجهات الأدوات، والذاكرة، والمخططين. على سبيل المثال، يمكن لوكيل الإجابة على استفسارات معقدة حول مجموعة من ملفات PDF عن طريق استرجاع المستندات ذات الصلة، وتلخيص المحتوى، وتوليف إجابة. يسهل LangChain إنشاء كل من الوكلاء المخصصين لمهام محددة والوكلاء الذين يستخدمون الأدوات عن طريق تحديد سير العمل ودمج واجهات برمجة التطبيقات، مع فهم LangChain مقابل LangGraph يساعد الفرق على تحديد متى يكون التنسيق القائم على الرسوم البيانية أفضل لتنفيذ الوكيل متعدد الخطوات.
وكلاء استدعاء الوظائف من OpenAI
تتيح ميزة استدعاء الدوال من OpenAI إنشاء وكلاء منظمين يستخدمون الأدوات. يحدد المطورون الأدوات كأنماط JSON، ويختار النموذج متى وكيف يستدعيها. من الأمثلة العملية على ذلك وكيل خدمة العملاء الذي، عند التعرف على النية، يقوم تلقائيًا بجلب حالة الطلب، أو تحديث معلومات التسليم، أو تقديم تذكرة دعم—دون الحاجة إلى هندسة يدوية لواجهة برمجة التطبيقات (API).
CrewAI و MetaGPT
تقدم هذه الأطر عملًا تعاونيًا متعدد الوكلاء، حيث يتم تعيين أدوار محددة للوكلاء—مثل المطور أو المراجع أو المخطط الاستراتيجي—ويتواصلون مع بعضهم البعض لحل المهام المعقدة. على سبيل المثال، في MetaGPT، يقوم وكيل مدير المشروع بإنشاء المتطلبات، ويكتب وكيل المطور الكود، ويتحقق وكيل الاختبار من صحته—مما يعكس بفعالية سير عمل فريق برمجي حقيقي.
تعمل معظم وكلاء نماذج اللغة الكبيرة (LLM) بشكل ممتاز في بيئة الاختبار (sandbox)—ولكنها تنهار بسرعة في البيئات الحقيقية. فهي تهلوس، وتفشل في استدعاء الأدوات، وتعاني من مشكلات زمن الاستجابة (latency)، وتقدم رؤية محدودة عند حدوث أي عطل. بناء وكيل ذكي أمر سهل. لكن جعله موثوقًا وقابلًا للتطوير وآمنًا في بيئة الإنتاج هو الجزء الصعب.
هنا يأتي دور TrueFoundry. فهي تقدم منصة شاملة لعمليات نماذج اللغة الكبيرة (LLMOps) مصممة لتحويل النماذج الأولية الواعدة إلى أنظمة وكلاء على مستوى المؤسسات تتسم بالسرعة، وقابلية المراقبة، والامتثال، ومصممة للتوسع.
تتيح TrueFoundry للفرق نشر الوكلاء المبنيين باستخدام LangChain أو AutoGen أو CrewAI أو البنى المخصصة—دون القلق بشأن تعقيد البنية التحتية. سواء كانت حالة استخدام لوكيل واحد أو مسار عمل متعدد الوكلاء، توفر TrueFoundry العمود الفقري للتنسيق لإدارة سير العمل عبر البيئات السحابية أو المحلية.
لتشغيل تفاعلات الوكلاء في الوقت الفعلي، توفر المنصة خدمة نماذج محسّنة باستخدام خلفيات عالية الأداء مثل vLLM و SGLang. وبالاقتران مع التحجيم التلقائي وتوفير الموارد الذكي، يمكن للوكلاء الاستجابة بشكل أسرع مع الحفاظ على تكاليف الاستدلال تحت السيطرة.
يستفيد الوكلاء الذين يستدعون أدوات خارجية أو واجهات برمجة تطبيقات (APIs) تابعة لجهات خارجية من بوابة API الموحدة لـ TrueFoundry. فهي توفر:
تعيد وكلاء نماذج اللغة الكبيرة (LLM) تشكيل طريقة تفاعلنا مع الذكاء الاصطناعي—من روبوتات الدردشة التفاعلية إلى الأنظمة المستقلة القادرة على الاستدلال والتخطيط والتصرف. تتطور بنيتها، المدعومة بنماذج اللغة والأدوات والذاكرة والتنسيق، بسرعة لدعم مهام أكثر تعقيدًا وواقعية. وبينما الإمكانيات هائلة، فإن نشر الوكلاء في بيئة الإنتاج يتطلب أكثر من مجرد مطالبات ذكية—فهو يتطلب بنية تحتية قابلة للتطوير، وقابلية للمراقبة، وتصميم نظام دقيق.
تنشر الشركات وكلاء نماذج اللغة الكبيرة (LLM) لأتمتة سير العمل المعقدة والمتعددة الخطوات التي تتطلب اتخاذ قرارات ديناميكية. تستخدم هذه الأنظمة نماذج اللغة للاستدلال لحل المشكلات وتنفيذ الإجراءات باستخدام أدوات خارجية. إنها توفر قدرات تنفيذ مستقلة لا يمكن لروبوتات الدردشة التقليدية والثابتة تحقيقها في بيئات الإنتاج القابلة للتطوير.
غالبًا ما تواجه وكلاء نماذج اللغة الكبيرة (LLM) صعوبة في حلقات الاستدلال، أو أخطاء الأدوات، أو هلوسات البيانات عند العمل في بيئات غير مقيدة. تحدث هذه الإخفاقات عادةً عندما يفتقر الوكيل إلى تعليمات واضحة أو يواجه استجابات غير متوقعة من واجهة برمجة التطبيقات (API). يساعد تطبيق المراقبة العميقة الفرق على تتبع خطوات الوكيل وإصلاح هذه الأعطال المنطقية لضمان موثوقية الإنتاج.
تعتمد موثوقية وكلاء نماذج اللغة الكبيرة (LLM) على تعقيد المهمة وقدرات النموذج الأساسي. بينما يعد استرجاع البيانات البسيط موثوقًا به للغاية، يتطلب الاستدلال المعقد أطر تقييم صارمة. تتيح المراقبة على مستوى المنصة للفرق قياس معدلات النجاح هذه والتكرار على مطالبات الوكيل بشكل منهجي لتحسين دقة الاستدلال.
يشير وكيل نماذج اللغة الكبيرة (LLM) على وجه التحديد إلى نظام مستقل يستخدم نموذج لغة كبير كمحرك استدلال أساسي له. بينما "وكيل الذكاء الاصطناعي" هو فئة أوسع تشمل خوارزميات متنوعة، تتفوق الإصدارات المستندة إلى نماذج اللغة الكبيرة (LLM) في فهم اللغة الطبيعية وتخطيط المهام المعقدة. إنها تحول التعليمات النصية إلى خطوات قابلة للتنفيذ عبر أدوات برمجية متكاملة.
بينما العديد من الأنظمة الحديثة هي وكلاء نماذج لغة كبيرة (LLM)، يستخدم بعض وكلاء الذكاء الاصطناعي التعلم المعزز التقليدي أو المنطق القائم على قواعد ثابتة. ومع ذلك، فإن دمج نماذج اللغة الكبيرة (LLM) يسمح للوكلاء بالتعامل مع معلومات أكثر تنوعًا وغير منظمة بكثير. تدعم منصات المؤسسات مثل TrueFoundry البنى الهجينة، مما يمنح الفرق المرونة لاختيار الذكاء الأمثل لسير العمل المحدد وعالي المخاطر.
يركز وكلاء MCP على ربط نماذج اللغة الكبيرة (LLM) بأدوات أو بيانات خارجية عبر بروتوكول سياق النموذج (Model Context Protocol)، يعملون كوسطاء متحكم بهم. من ناحية أخرى، يعمل وكلاء نماذج اللغة الكبيرة (LLM) بشكل مستقل، يتخذون القرارات، وينفذون المهام، أو يتفاعلون مع أدوات متعددة دون تعليمات بشرية مباشرة، مستفيدين من الاستدلال وتنسيق سير العمل.
تشمل المخاطر توليد مخرجات غير دقيقة أو متحيزة، تسريب معلومات حساسة، اتخاذ قرارات مستقلة تنتهك السياسات، أو إساءة استخدام الأدوات المتكاملة. بدون إشراف مناسب، يمكن لوكلاء نماذج اللغة الكبيرة (LLM) نشر الأخطاء، إنشاء مسؤوليات قانونية، أو المساس بالأمن، مما يجعل آليات الحوكمة والمراقبة والسلامة ضرورية في عمليات النشر على مستوى المؤسسات.
عندما يُتركون دون إشراف، يواصل وكلاء نماذج اللغة الكبيرة (LLM) تنفيذ المهام المخصصة ضمن قيودهم المبرمجة. قد يقومون بتكرار سير العمل، أو الاستعلام عن الأدوات المتصلة، أو تحسين المخرجات بشكل مستقل. ومع ذلك، بدون إشراف بشري أو ضوابط، يمكنهم الانحراف عن الأهداف المقصودة، توليد نتائج غير متسقة أو غير آمنة، والفشل في اكتشاف تغييرات السياق.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








أحدث الأخبار والمقالات والموارد تصلك مباشرة إلى بريدك الوارد
© 2026 جميع الحقوق محفوظة.







.png)
.webp)










.webp)
