




July 4, 2026
|
5 min read


احصل على وصول فوري إلى بيئة TrueFoundry مباشرة. انشر النماذج، ووجّه حركة مرور LLM، واستكشف المنصة بالكامل — بيئة الاختبار الخاصة بك جاهزة في ثوانٍ، ولا يلزم وجود بطاقة ائتمان.









Published: July 4, 2026

Blazingly fast way to build, track and deploy your models!
تجاوزت نماذج اللغة الكبيرة عتبة مهمة. فما بدأ كتجارب معزولة ومشاريع تجريبية تطور الآن إلى أعباء عمل إنتاجية مدمجة عبر أنظمة المؤسسات. ويعتمد دعم العملاء، والبحث عن المعرفة الداخلية، وتطوير البرمجيات، والتحليلات، والوكلاء المستقلون بشكل متزايد على نماذج اللغة الكبيرة كعناصر بناء أساسية بدلاً من كونها تحسينات اختيارية.
كشف هذا التحول عن فئة جديدة من تحديات البنية التحتية. تتصرف أعباء عمل نماذج اللغة الكبيرة بشكل مختلف تمامًا عن خدمات التطبيقات التقليدية. تتصاعد التكاليف مع الرموز (tokens) بدلاً من الطلبات، ويختلف زمن الاستجابة بشكل كبير بين المزودين والمناطق، وغالبًا ما تكون أوضاع الفشل - مثل انتهاء المهلة، أو الهلوسة، أو الاستجابات الجزئية - غامضة. ومع اعتماد المؤسسات لعدة نماذج من مزودين مختلفين، تتفاقم هذه المشكلات بسرعة.
بالنسبة لمعظم المؤسسات، تم بناء عمليات دمج نماذج اللغة الكبيرة المبكرة باستخدام استدعاءات API مباشرة ومنطق على مستوى التطبيق. هذا النهج لا يصمد عند التوسع. تواجه الفرق بسرعة تكاليف استدلال غير متوقعة، ورؤية محدودة للاستخدام، والارتباط بمزود معين، ومخاوف متزايدة بشأن الحوكمة. يصبح تحسين أعباء عمل نماذج اللغة الكبيرة أكثر صعوبة عندما يطبق كل تطبيق توجيهه الخاص، وإعادة المحاولات، وضوابط التكلفة، والتسجيل.
مع توسع اعتماد الذكاء الاصطناعي أفقيًا عبر الفرق وعموديًا عبر البيئات، يتحول تحسين أعباء عمل نماذج اللغة الكبيرة من مشكلة تطبيق إلى مشكلة بنية تحتية. تحتاج المؤسسات إلى طبقة مركزية يمكنها مراقبة، والتحكم في، وتحسين كيفية استخدام النماذج بشكل متسق وعلى نطاق واسع. وقد دفع هذا الاحتياج إلى ظهور بوابات الذكاء الاصطناعي كمكون أساسي للبنية التحتية الحديثة للذكاء الاصطناعي.
يختلف تحسين أعباء عمل نماذج اللغة الكبيرة اختلافًا جوهريًا عن تحسين الحوسبة التقليدية أو الخدمات المصغرة. التحديات نظامية وليست محلية.
أولاً، ديناميكيات التكلفة غير خطية. يمكن أن يؤدي تغيير بسيط في بنية المطالبة، أو منطق إعادة المحاولة، أو حجم السياق إلى زيادة كبيرة في استهلاك الرموز والإنفاق. بدون رؤية مركزية وحل منظم لـ تتبع تكاليف نماذج اللغة الكبيرة، غالبًا ما تمر هذه التغييرات دون أن يلاحظها أحد حتى ترتفع التكاليف بشكل حاد. تفتقر الضوابط على مستوى التطبيق إلى السياق العالمي المطلوب لفرض الميزانيات أو مقارنة الكفاءة عبر الفرق وحالات الاستخدام.
ثانيًا، تقلب الأداء متأصل. يصبح هذا أكثر وضوحًا خلال استدلال نماذج اللغة الكبيرة، حيث يختلف الكمون والإنتاجية باختلاف النماذج والمزودين والمناطق، ويتذبذبان بناءً على الحمل والتوافر. إن ترميز مزود أو نموذج واحد بشكل ثابت في التطبيق يخلق هشاشة. وعندما تحدث انقطاعات أو قيود على المعدل، تضطر الفرق إلى إصلاحات تفاعلية بدلاً من التحسين الاستباقي.
ثالثًا، اعتماد نماذج متعددة يُدخل تعقيدًا تشغيليًا. تستخدم الشركات بشكل متزايد مزيجًا من النماذج المتميزة لسير العمل الحرج ونماذج أقل تكلفة للمهام ذات الحجم الكبير أو غير الحرجة. تتطلب إدارة هذا المزيج بكفاءة قرارات توجيه توازن بين التكلفة والجودة والكمون، وهي قرارات لا ينبغي أن تكون جزءًا من رمز التطبيق.
أخيرًا، الحوكمة وضغوط الامتثال تستمر في الازدياد. يجب على المؤسسات فرض ضوابط الوصول، ومراقبة الاستخدام، والاحتفاظ بسجلات التدقيق، وضمان إقامة البيانات عبر المناطق. تمتد هذه المتطلبات لتشمل كل عبء عمل للذكاء الاصطناعي ولا يمكن معالجتها بفعالية على أساس كل تطبيق على حدة.
مجتمعة، توضح هذه العوامل أن تحسين أعباء عمل نماذج اللغة الكبيرة لا يمكن حله بشكل مجزأ. يتطلب طبقة تحكم مركزية تتمتع برؤية شاملة لجميع حركة مرور الذكاء الاصطناعي وصلاحية فرض السياسات بشكل متسق.
تعالج بوابات الذكاء الاصطناعي هذا التحدي من خلال العمل كـ مستوى التحكم لأعباء عمل نماذج اللغة الكبيرة. تقع بوابة الذكاء الاصطناعي بين التطبيقات ومزودي النماذج، وتقوم بمركزة كيفية توجيه طلبات نماذج اللغة الكبيرة ومراقبتها وحوكمتها وتحسينها.
على عكس بوابات API التقليدية، تم تصميم بوابات الذكاء الاصطناعي خصيصًا لخصائص أعباء عمل نماذج اللغة الكبيرة. إنها تفهم السلوك الخاص بالنموذج، والتسعير القائم على الرموز، ومقايضات الكمون، والحاجة إلى قابلية مراقبة دقيقة. وهذا يسمح بتطبيق استراتيجيات التحسين مرة واحدة على مستوى البنية التحتية وتطبيقها بشكل موحد عبر جميع التطبيقات.
على مستوى عالٍ، تمكّن بوابات الذكاء الاصطناعي تحسين أعباء عمل نماذج اللغة الكبيرة من خلال:
يفصل هذا النهج المعماري منطق التطبيق عن إدارة النماذج. يركز المطورون على بناء ميزات مدعومة بالذكاء الاصطناعي، بينما تحتفظ فرق المنصة بالتحكم في الأداء والتكلفة والمخاطر.
مع توسع الشركات في استخدامها لنماذج اللغة الكبيرة (LLMs)، يصبح هذا الفصل حاسمًا. فبدونه، تكون جهود التحسين مجزأة وتفاعلية ويصعب الحفاظ عليها. وبوجوده، تكتسب المؤسسات طريقة متسقة وقابلة للقياس والتكرار لتشغيل أعباء عمل نماذج اللغة الكبيرة بكفاءة، بغض النظر عن عدد النماذج أو الفرق أو التطبيقات المعنية.
مع نضوج المؤسسات في استخدامها لنماذج اللغة الكبيرة (LLMs)، أصبحت استراتيجيات التحسين أكثر منهجية وتعتمد على البنية التحتية. وبحلول عام 2026، تظهر عدة أنماط كممارسات قياسية بين الشركات التي تشغل أعباء عمل نماذج اللغة الكبيرة على نطاق واسع.
بدلاً من التعامل مع اختيار النموذج كخيار ثابت، تتبنى الشركات التنسيق المدرك للتكلفة. في هذا النموذج، توازن بوابات الذكاء الاصطناعي ديناميكيًا بين التكلفة والجودة وزمن الاستجابة بناءً على سياق كل طلب.
على سبيل المثال:
يتيح هذا النهج للمؤسسات تحسين الإنفاق دون المساس بتجربة المستخدم. ومع مرور الوقت، فإنه يخلق أيضًا حلقة تغذية راجعة حيث تُستخدم بيانات الاستخدام الحقيقية لاتخاذ قرارات تنسيق أفضل.
تعيد المتطلبات التنظيمية والواقع الجيوسياسي تشكيل كيفية نشر أنظمة الذكاء الاصطناعي. تعمل الشركات بشكل متزايد على تشغيل مكدسات ذكاء اصطناعي مقسمة جغرافيًا، حيث يتم عزل أعباء عمل نماذج اللغة الكبيرة حسب المنطقة لتلبية متطلبات إقامة البيانات والسيادة والامتثال.
عمليًا، هذا يعني:
تلعب بوابات الذكاء الاصطناعي دورًا محوريًا في فرض هذه القيود مع الاستمرار في توفير نموذج تشغيل موحد عبر المناطق.
مع تزايد استخدام نماذج اللغة الكبيرة (LLM)، تتجه المؤسسات بعيدًا عن إرسال سياقات كبيرة بشكل متكرر إلى النماذج. وبدلاً من ذلك، تتبنى أنظمة الذكاء الاصطناعي المعتمدة على الأدوات، حيث تقوم النماذج باسترداد المعلومات عند الطلب عبر واجهات تحكم.
هذا التحول:
تتوسط بوابات الذكاء الاصطناعي بشكل متزايد ليس فقط استدعاءات النماذج، بل أيضًا تنفيذ الأدوات وواجهات برمجة التطبيقات (API)، مما يضمن أن أنظمة الذكاء الاصطناعي تتفاعل مع بيانات المؤسسة بطريقة محكمة وقابلة للتدقيق.
يؤدي صعود الوكلاء المستقلين وشبه المستقلين إلى ظهور تحديات تحسين جديدة. غالبًا ما يقوم الوكلاء بإجراء استدعاءات متعددة للنماذج، واستدعاء الأدوات، وتنفيذ مهام سير عمل طويلة الأمد.
تعمل المؤسسات الرائدة على توسيع استراتيجيات التحسين لتشمل طبقة الوكيل من خلال:
تتطور بوابات الذكاء الاصطناعي لدعم هذا التحول، وتعمل كطبقة وساطة لكل من استدلال النموذج وتنفيذ الوكيل.
Key Metrics for Evaluating Gateway
| Criteria | What should you evaluate ? | Priority | TrueFoundry |
|---|---|---|---|
| Latency | Adds <10ms p95 overhead for time-to-first-token? | Must Have | ✅ Supported |
| Data Residency | Keeps logs within your region (EU/US)? | Depends on use case | ✅ Supported |
| Latency-Based Routing | Automatically reroutes based on real-time latency/failures? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |

اختيار بوابة الذكاء الاصطناعي ليس قرارًا يتعلق بالأدوات، بل هو التزام بـ البنية التحتية. بالنسبة لمعظم الشركات، ستقع هذه الطبقة في المسار الحرج لكل تطبيق مدعوم بنماذج اللغة الكبيرة (LLM)، مما يجعل من الصعب التراجع عن خيارات تصميمها لاحقًا. ونتيجة لذلك، يجب أن يركز التقييم بشكل أقل على الميزات السطحية وأكثر على الملاءمة المعمارية، والنضج التشغيلي، والمرونة طويلة الأمد.
فيما يلي إطار عمل عملي يمكن للمديرين التنفيذيين التقنيين استخدامه لتقييم بوابات الذكاء الاصطناعي تحديدًا من منظور تحسين أعباء عمل نماذج اللغة الكبيرة (LLM).
يجب أن تتيح بوابة الذكاء الاصطناعي الرائدة الاستخدام الحقيقي للنماذج المتعددة دون إجبار التطبيقات على التغيير عند تغيير النماذج أو المزودين.
أسئلة رئيسية يجب طرحها:
إذا تسرب اختيار النموذج إلى منطق التطبيق، فسيكون التحسين بطيئًا وهشًا.
تحسين نماذج اللغة الكبيرة (LLM) مستحيل بدون رؤية التكلفة. يجب أن توفر البوابات رؤى وتطبيقًا على المستوى الذي تُتخذ فيه القرارات.
ابحث عن:
البوابة التي تبلغ عن الاستخدام الإجمالي فقط غير كافية للتحسين الحقيقي.
بما أن البوابة تقع في المسار الحرج، فإن خصائص الأداء مهمة.
قيّم:
حتى تدهور الأداء البسيط يمكن أن يتفاقم عند التوسع.
يعتمد التحسين على حلقات التغذية الراجعة. يجب أن تعمل البوابة كنظام السجل الأساسي لنشاط نماذج اللغة الكبيرة (LLM).
قيّم ما إذا كانت البوابة توفر:
إذا بدت قابلية المراقبة مضافة بشكل غير متكامل، فسيكون التحسين تفاعليًا بدلاً من أن يكون منهجيًا.
يجب أن يتعايش التحسين مع ضوابط المخاطر المؤسسية.
تشمل الاعتبارات الرئيسية:
البوابة التي تتطلب مفاضلات بين التحسين والامتثال لن تتوسع في البيئات المنظمة.
أخيرًا، قيّم كيف تتناسب البوابة مع بنيتك التحتية الحالية ونموذج التشغيل الخاص بك.
ضع في اعتبارك:
كلما اندمجت البوابة بإحكام أكبر مع مكدس منصتك، كان تشغيلها أسهل على المدى الطويل.
بنية TrueFoundry قائمة على فرضية واضحة: تحسين أحمال عمل نماذج اللغة الكبيرة (LLM) هو شاغل يتعلق بالبنية التحتية، وليس مسؤولية التطبيق. ونتيجة لذلك، تم تصميم بوابة الذكاء الاصطناعي الخاصة بها كمستوى تحكم من الدرجة الأولى يقع في قلب مكدس الذكاء الاصطناعي للمؤسسات.
في نشر TrueFoundry، لا تتفاعل التطبيقات والوكلاء أبدًا بشكل مباشر مع موفري النماذج. بدلاً من ذلك، تتدفق جميع حركة مرور نماذج اللغة الكبيرة (LLM) عبر الـ بوابة الذكاء الاصطناعي، والتي تعمل كواجهة واحدة ومستقرة للاستدلال والتوجيه والمراقبة والحوكمة.
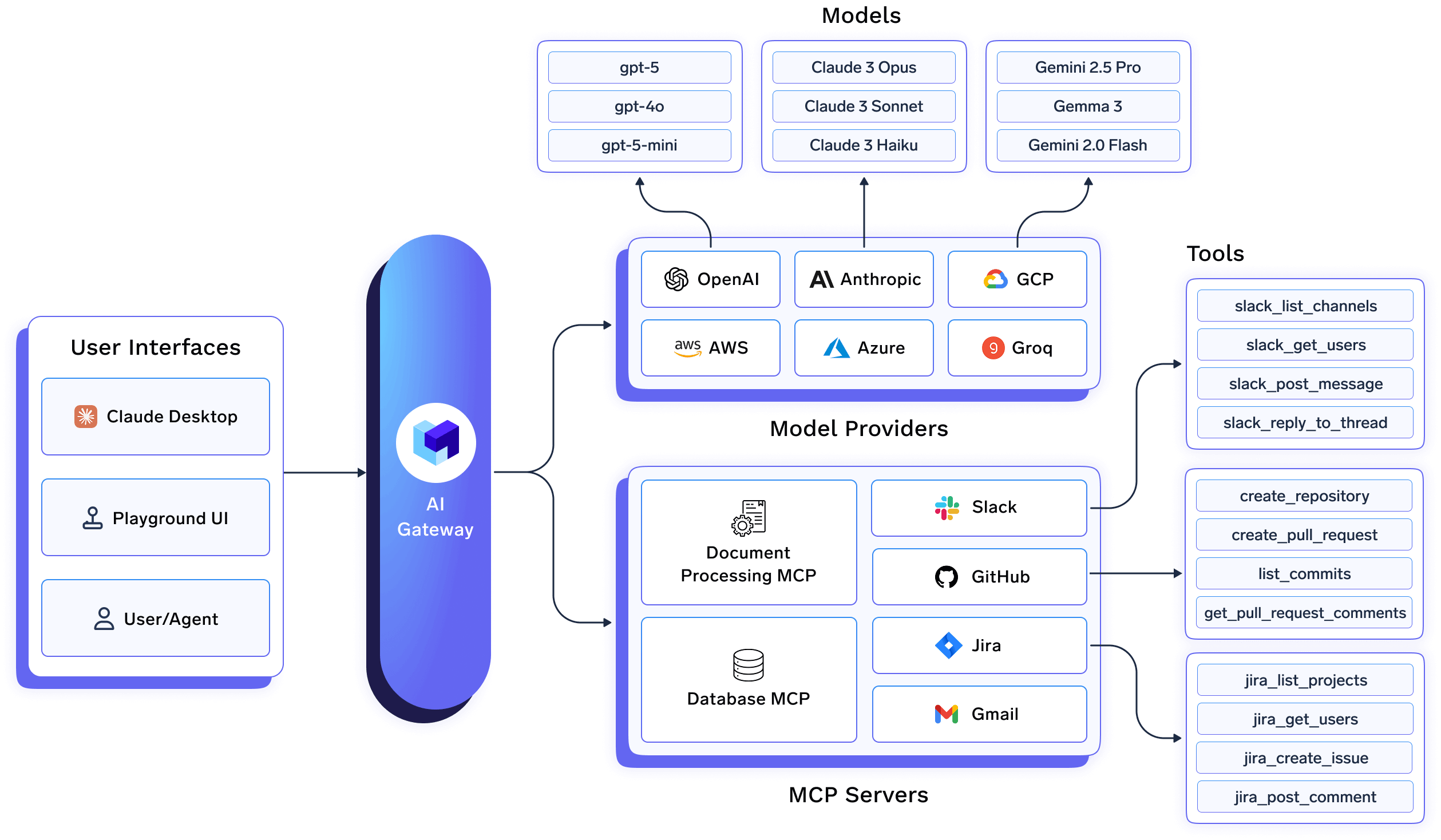
على المستوى المعماري، هذا يعني:
يزيل هذا التصميم المخاوف الخاصة بالنموذج من كود التطبيق ويسمح لاستراتيجيات التحسين بالتطور بشكل مستقل.
تتيح بوابة الذكاء الاصطناعي من TrueFoundry التشغيل الحقيقي متعدد النماذج عن طريق تجريد واجهات برمجة التطبيقات الخاصة بالمزودين خلف عقد واحد. تُعالج قرارات التوجيه، مثل أي نموذج يجب استخدامه، ومتى يتم الرجوع إلى نموذج احتياطي، أو كيفية الموازنة بين التكلفة وزمن الاستجابة، مركزيًا عند البوابة.
عمليًا، يتيح هذا لفرق المنصة ما يلي:
نظرًا لأن التوجيه يتم التعامل معه عند البوابة، يمكن معالجة التغييرات في التسعير أو الأداء أو توفر المزود على الفور، بدلاً من طلب تغييرات على مستوى التطبيق.
أحد المبادئ الأساسية لهندسة TrueFoundry هو أن بوابة الذكاء الاصطناعي تعمل كـ نظام السجل لجميع أنشطة نماذج اللغة الكبيرة. يتم التقاط كل طلب يمر عبر البوابة ببيانات وصفية مفصلة، بما في ذلك اختيار النموذج، واستخدام الرموز، وزمن الاستجابة، وسياق الطلب.
على عكس العديد من المنصات التي تقوم بمركزة هذه البيانات في أنظمة يديرها البائعون، يضمن تصميم TrueFoundry ما يلي:
يتجنب هذا النهج مشكلة "الصندوق الأسود" ويمكّن المؤسسات من بناء حلقات تغذية راجعة للتحسين طويلة الأجل باستخدام بياناتها الخاصة.
TrueFoundry’s بوابة الذكاء الاصطناعي تدمج ضوابط التكلفة والحوكمة مباشرة في مسار الطلب. فبدلاً من الاعتماد على تقارير الفواتير اللاحقة أو الأدوات الخارجية، يتم التحسين والتطبيق في الوقت الفعلي.
تشمل القدرات المعمارية الرئيسية ما يلي:
نظرًا لأن هذه الضوابط مركزية، فإن كل تطبيق مدعوم بنماذج اللغة الكبيرة (LLM) يرثها تلقائيًا. وهذا يجعل من الممكن توسيع نطاق استخدام الذكاء الاصطناعي عبر الفرق دون تكرار منطق الحوكمة.
بوابة الذكاء الاصطناعي من TrueFoundry مصممة ليتم نشرها حيث توجد بيانات المؤسسة بالفعل. يمكن تشغيلها في شبكات VPCs الخاصة، أو البيئات المحلية، أو مناطق السحابة الخاضعة للتحكم، مما يمكّن المؤسسات من تلبية متطلبات توطين البيانات والامتثال التنظيمي الصارمة.
من الناحية المعمارية، يدعم هذا ما يلي:
يتوافق هذا التصميم مع المؤسسات العاملة عبر ولايات قضائية متعددة، حيث يجب التحكم في حركة البيانات بإحكام.
تتوافق بنية TrueFoundry التي تركز على البوابة أيضًا مع التحول نحو أنظمة الذكاء الاصطناعي القائمة على الوكلاء. فمع تزايد قيام الوكلاء بتنسيق مهام سير العمل متعددة الخطوات واستدعاء الأدوات أو واجهات برمجة التطبيقات (APIs)، تصبح البوابة نقطة التنفيذ الطبيعية.
ضمن هذا النموذج، يمكن لبوابة الذكاء الاصطناعي أن:
هذا يضع البوابة ليس فقط كطبقة استدلال، بل كمستوى تحكم تنفيذي أوسع للأنظمة الذكية.
السمة المميزة لنهج TrueFoundry هي أن يتم تطبيق التحسين والحوكمة والمراقبة مرة واحدة على مستوى البنية التحتية وإعادة استخدامها في كل مكان. يقلل هذا من التعقيد التشغيلي، ويحسن الاتساق، ويسمح للمؤسسات بتوسيع نطاق أعباء عمل نماذج اللغة الكبيرة (LLM) دون فقدان السيطرة.
الخلاصة الأوسع هي أن بوابة الذكاء الاصطناعي من TrueFoundry لا يتم وضعها كإضافة، بل كـ بنية تحتية أساسية للذكاء الاصطناعي. من خلال التعامل مع البوابة كطبقة معمارية طويلة الأمد، تتوافق TrueFoundry مع كيفية تفكير الشركات بالفعل في الأنظمة الحيوية مثل بوابات واجهات برمجة التطبيقات ومنصات البيانات وتنسيق الحوسبة.
مع تزايد تبني نماذج اللغة الكبيرة (LLM)، لم يعد التحسين مسألة ضبط للمطالبات أو اختيار للنماذج—بل هو قرار يتعلق بالبنية التحتية. يتطلب تقلب التكاليف وتغير الأداء ومتطلبات الحوكمة طبقة تحكم مركزية يمكنها العمل عبر النماذج والفرق والتطبيقات.
برزت بوابات الذكاء الاصطناعي كطبقة التحكم هذه. من خلال دمج التوجيه والمراقبة وضوابط التكلفة وتطبيق السياسات، تحول تحسين نماذج اللغة الكبيرة (LLM) إلى قدرة منهجية بدلاً من أن يكون عبئًا تشغيليًا مستمرًا.
منصات مثل TrueFoundry تعكس هذا التحول من خلال التعامل مع بوابة الذكاء الاصطناعي كجزء أساسي من البنية التحتية للذكاء الاصطناعي للمؤسسات. بالنسبة للقادة التقنيين، الرسالة واضحة: يعتمد التوسع المستدام لنماذج اللغة الكبيرة (LLM) بشكل أقل على اختيار النموذج الصحيح، وبشكل أكبر على بناء الأساس الصحيح لتشغيلها.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








أحدث الأخبار والمقالات والموارد تصلك مباشرة إلى بريدك الوارد
© 2026 جميع الحقوق محفوظة.







.png)
.webp)










.webp)
