احصل على وصول فوري إلى بيئة TrueFoundry مباشرة. انشر النماذج، ووجّه حركة مرور LLM، واستكشف المنصة بالكامل — بيئة الاختبار الخاصة بك جاهزة في ثوانٍ، ولا يلزم وجود بطاقة ائتمان.
٩.٩
كيفية التفكير في بنية بوابة الذكاء الاصطناعي ضمن مكدس الذكاء الاصطناعي التوليدي
في أنظمة الذكاء الاصطناعي التوليدي الحديثة، تعمل بوابة الذكاء الاصطناعي بمثابة طبقة الوكيل الحاسمة بين التطبيقات ومقدمي نماذج اللغة الكبيرة (LLM). تلعب دورًا محوريًا في إدارة الموثوقية، وإمكانية المراقبة، والتحكم في الوصول، وكفاءة التكلفة لكل طلب يتدفق إلى بيئة الإنتاج.
نظرًا لأن البوابة تقع في المسار الحرج لحركة مرور الإنتاج، يجب تصميمها مع مراعاة المبادئ الأساسية التالية:
أولويات معمارية رئيسية:
التوافرية العالية: يجب ألا تصبح البوابة نقطة فشل واحدة. حتى في مواجهة مشكلات التبعية (مثل انقطاع قواعد البيانات أو قوائم الانتظار)، يجب أن تستمر في خدمة حركة المرور بسلاسة.
زمن الاستجابة المنخفض: نظرًا لأنها تقع في مسار كل طلب استدلال، يجب أن تضيف البوابة حدًا أدنى من الحمل الإضافي لضمان تجربة مستخدم سريعة الاستجابة.
الإنتاجية العالية وقابلية التوسع: يجب أن يتوسع النظام خطيًا مع الحمل وأن يكون قادرًا على التعامل مع آلاف الطلبات المتزامنة مع استخدام فعال للموارد.
لا توجد تبعيات خارجية في المسار الساخن: يجب نقل أي عمليات تعتمد على الشبكة أو القرص إلى أنظمة غير متزامنة لمنع اختناقات الأداء.
اتخاذ القرار في الذاكرة: يجب إجراء جميع الفحوصات الحيوية مثل تحديد المعدل وموازنة التحميل والمصادقة والتفويض في الذاكرة لتحقيق أقصى سرعة وموثوقية.
فصل مستوى التحكم ومستوى الوكيل: يجب فصل تغييرات التكوين وإدارة النظام عن توجيه حركة المرور الحية، مما يتيح عمليات نشر عالمية مع عزل الأخطاء الإقليمي.
معمارية بوابة الذكاء الاصطناعي من TrueFoundry
بوابة TrueFoundry للذكاء الاصطناعي تجسد جميع مبادئ التصميم المذكورة أعلاه، وهي مصممة خصيصًا لزمن انتقال منخفض وموثوقية عالية وقابلية توسع سلسة.
معمارية بوابة TrueFoundry
الخصائص الرئيسية لمعمارية بوابة الذكاء الاصطناعي
مبني على إطار عمل Hono: تستفيد البوابة من Hono، وهو إطار عمل بسيط وفائق السرعة مُحسّن لبيئات الحافة. وهذا يضمن الحد الأدنى من النفقات العامة لوقت التشغيل ومعالجة سريعة للغاية للطلبات.
لا توجد مكالمات خارجية في مسار الطلب: بمجرد وصول الطلب إلى البوابة، فإنه لا يؤدي إلى أي مكالمات خارجية (ما لم يتم تمكين التخزين المؤقت الدلالي). يتم التعامل مع جميع منطق التشغيل داخليًا، مما يقلل المخاطر ويعزز الموثوقية.
التنفيذ في الذاكرة: تُتخذ جميع قرارات المصادقة والتفويض وتحديد المعدل وموازنة التحميل باستخدام تكوينات الذاكرة، مما يضمن أوقات استجابة في جزء من الألف من الثانية.
التسجيل غير المتزامن: يتم دفع السجلات ومقاييس الطلبات إلى قائمة انتظار رسائل بشكل غير متزامن، مما يضمن أن مراقبة البيانات لا تعيق أو تبطئ مسار الطلب.
سلوك آمن ضد الأعطال: حتى لو كانت قائمة انتظار التسجيل الخارجية معطلة، فإن البوابة لن تفشل أي طلبات. يضمن ذلك استمرارية التشغيل والمرونة في ظل حالات فشل النظام الجزئية.
قابل للتوسع أفقيًا: البوابة تعتمد على وحدة المعالجة المركزية (CPU) وعديمة الحالة، مما يسهل توسيع نطاقها. تعمل بكفاءة عالية في ظل التزامن العالي واستخدام منخفض للذاكرة.
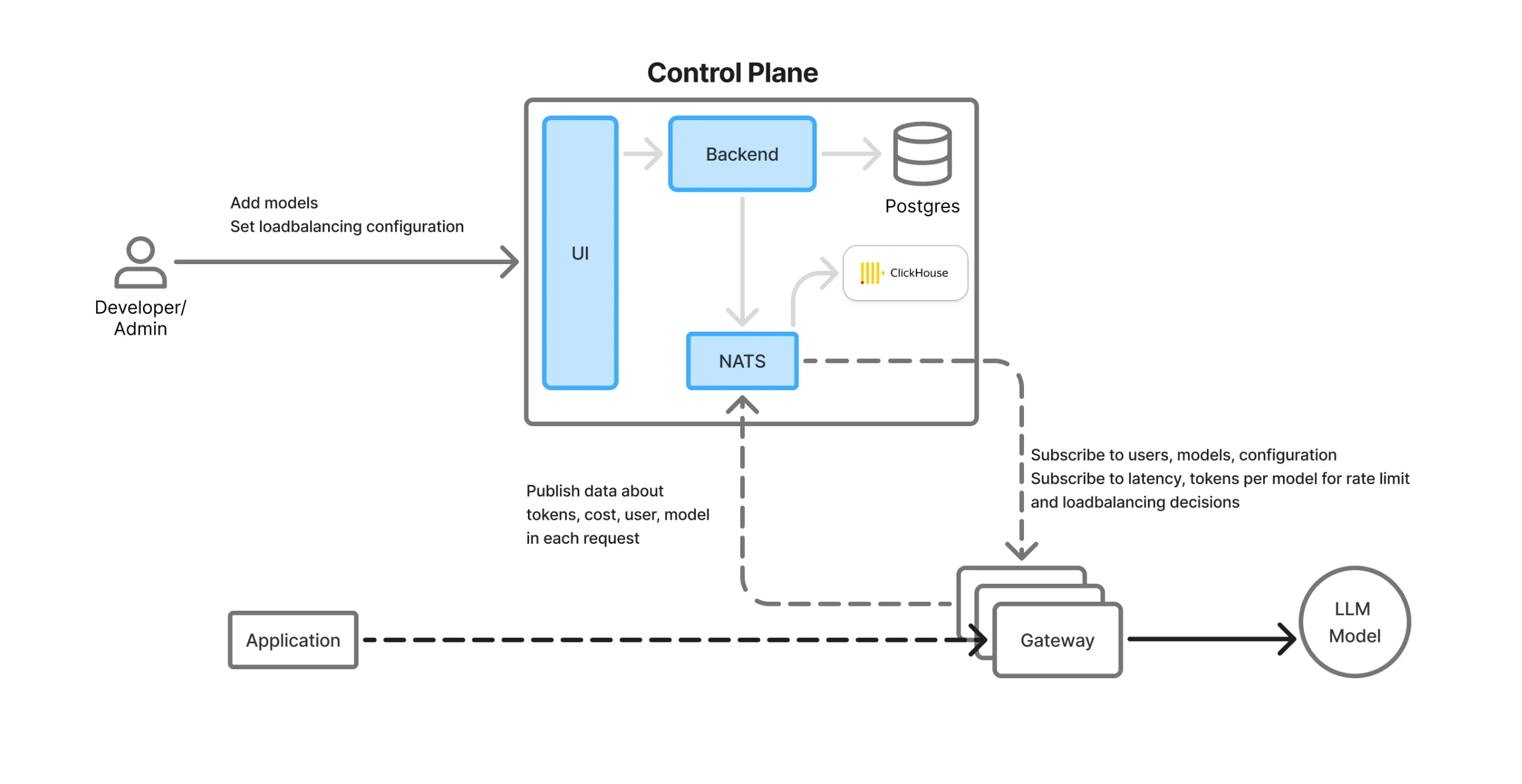
مستوى التحكم وتدفق البيانات
تفصل TrueFoundry مستوى التحكم (الإدارة) عن مستوى البيانات (توجيه حركة المرور في الوقت الفعلي) لتحقيق قابلية التوسع والمرونة.
نظرة عامة على مكونات بوابة الذكاء الاصطناعي:
واجهة المستخدم: واجهة ويب مع بيئة تجريبية لنموذج اللغة الكبير (LLM)، ولوحات معلومات للمراقبة، ولوحات إعدادات للنماذج والفرق وحدود المعدل وما إلى ذلك.
قاعدة بيانات Postgres: تخزن بيانات التكوين الدائمة (المستخدمين، الفرق، المفاتيح، النماذج، الحسابات الافتراضية، إلخ.)
ClickHouse: قاعدة بيانات عمودية عالية الأداء تُستخدم لتخزين السجلات والمقاييس وتحليلات الاستخدام.
NATS Queue: يعمل كناقل مزامنة في الوقت الفعلي بين مستوى التحكم ووحدات البوابة الموزعة. يتم دفع جميع تحديثات التكوين/الحالة عبر NATS وتكون متاحة فورًا في جميع المناطق.
خدمة الواجهة الخلفية: تنسق مزامنة التكوين وتحديثات قاعدة البيانات واستيعاب التحليلات.
وحدات البوابة: وكلاء خفيفو الوزن، عديمو الحالة، داخل المنطقة، يتعاملون مع حركة مرور LLM الفعلية. يستهلكون رسائل NATS وينفذون جميع المنطق في الذاكرة، بدون أي تبعيات خارجية.
Key Metrics for Evaluating Gateway
Criteria
What should you evaluate ?
Priority
TrueFoundry
Latency
Adds <10ms p95 overhead for time-to-first-token?
Must Have
✅ Supported
Data Residency
Keeps logs within your region (EU/US)?
Depends on use case
✅ Supported
Latency-Based Routing
Automatically reroutes based on real-time latency/failures?
Must Have
✅ Supported
Key Rotation & Revocation
Rotate or revoke keys without downtime?
Must Have
✅ Supported
Key Rotation & Revocation
Rotate or revoke keys without downtime?
Must Have
✅ Supported
Key Rotation & Revocation
Rotate or revoke keys without downtime?
Must Have
✅ Supported
Key Rotation & Revocation
Rotate or revoke keys without downtime?
Must Have
✅ Supported
Key Rotation & Revocation
Rotate or revoke keys without downtime?
Must Have
✅ Supported
Evaluating an AI Gateway?
A practical guide used by platform & infra teams
معايير الأداء لبوابة TrueFoundry للذكاء الاصطناعي
تم اختبار أداء بوابة TrueFoundry بدقة تحت أحمال شبيهة بالإنتاج:
250 طلبًا في الثانية على معالج مركزي واحد / 1 جيجابايت من ذاكرة الوصول العشوائي مع إضافة 3 مللي ثانية من زمن الاستجابة الإضافي.
تتوسع بكفاءة حتى 350 طلبًا في الثانية لكل وحدة قبل الوصول إلى تشبع وحدة المعالجة المركزية، وبعد ذلك يمكنك إضافة نسخ متماثلة.
تدعم عشرات الآلاف من الطلبات في الثانية مع التوسع الأفقي عبر المناطق.
لا يوجد زمن استجابة إضافي حتى مع وجود قواعد متعددة لتحديد المعدل والمصادقة وموازنة التحميل.
لماذا هذا مهم
إذا كنت تدير أعباء عمل الذكاء الاصطناعي التوليدي على نطاق واسع، أو تخطط لدمج نماذج لغوية كبيرة متعددة (مثل OpenAI، Claude، المصادر المفتوحة، إلخ.)، فإن البوابة تصبح أساس بنيتك التحتية.
قم بكل هذا دون التأثير على زمن الاستجابة أو الموثوقية.
احجز عرضًا توضيحيًا الآن إذا كنت ترغب في البدء باستخدام بوابة الذكاء الاصطناعي.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.




































.png)
.webp)










.webp)
