




July 4, 2026
|
5 min read


احصل على وصول فوري إلى بيئة TrueFoundry مباشرة. انشر النماذج، ووجّه حركة مرور LLM، واستكشف المنصة بالكامل — بيئة الاختبار الخاصة بك جاهزة في ثوانٍ، ولا يلزم وجود بطاقة ائتمان.









Published: July 4, 2026

Blazingly fast way to build, track and deploy your models!
في عام 2026، لم يعد بإمكان الشركات تحمل تكلفة تعديل بوابة نموذج اللغة الكبير (LLM) لتصبح حلاً مؤقتًا بوابة ذكاء اصطناعي. سيصبح الذكاء الاصطناعي أكثر اندماجًا في سير العمل الموجهة للعملاء، مما يجعل طبقة البوابة المخصصة أمرًا لا غنى عنه للتطبيقات الموثوقة المدعومة بالذكاء الاصطناعي. غالبًا ما تكون البنية التحتية النموذجية للذكاء الاصطناعي في الشركات متعددة النماذج والفرق والسحابات، مما يؤدي إلى تعقيد الامتثال ومساءلة التكاليف.
تُعرّف Gartner بوابة الذكاء الاصطناعي بأنها تقنية أو منصة تعمل كوسيط بين التطبيقات وخدمات أو نماذج الذكاء الاصطناعي المختلفة. هدفها هو تبسيط وإدارة الوصول إلى قدرات الذكاء الاصطناعي، وتوفير نقطة مركزية لتمكين الأمان والحوكمة وإمكانية المراقبة لأعباء عمل الذكاء الاصطناعي. اقرأ الدليل الكامل دليل Gartner للسوق لبوابات الذكاء الاصطناعي 2025 لمعرفة المزيد.
على مدار العام الماضي، رأينا ظهور ثلاث فئات رئيسية لمعالجة مشكلة حوكمة ومرونة الذكاء الاصطناعي التوليدي:
كل فئة محسّنة لمرحلة مختلفة من تبني الذكاء الاصطناعي. تنشأ المشاكل عندما يتم تمديد الأدوات المحسّنة لمرحلة واحدة للتعامل مع مرحلة أخرى.
في هذه المدونة، نجمع كل الأبحاث التنافسية في مشهد واحد شامل، موضحين مكان كل منصة، وأين تكمن نقاط ضعفها، وما الذي يجب على الشركات أخذه في الاعتبار عند اختيار مورد يلبي متطلباتها على أفضل وجه.
1. Kong AI: بوابة API تقليدية مكيفة للذكاء الاصطناعي
Kong هي بوابة API، تُستخدم غالبًا في معماريات الخدمات المصغرة القائمة على Kubernetes. تبني Kong AI على هذا الأساس من خلال تقديم إضافات وتكاملات مصممة لتوجيه حركة المرور إلى نماذج اللغة الكبيرة.
ما الذي تبرع فيه Kong AI
أين يقصر Kong AI
مع تزايد استخدام الذكاء الاصطناعي، تصبح هذه الثغرات أكثر وضوحًا. يجب التعامل مع تحديد مصدر التكلفة، واستراتيجيات اختيار النموذج، والحوكمة الخاصة بالذكاء الاصطناعي خارج البوابة، وغالبًا ضمن كود التطبيق.
الخلاصة: Kong AI فعال كبوابة API، لكن الذكاء الاصطناعي يظل اهتمامًا ثانويًا بدلاً من كونه تجريدًا أصيلًا.
2. Portkey: بوابة نماذج اللغة الكبيرة (LLM) على مستوى التطبيق
Portkey هي بوابة ذكاء اصطناعي مصممة خصيصًا لتطبيقات نماذج اللغة الكبيرة (LLM). بدلاً من التعامل مع طلبات الذكاء الاصطناعي كاستدعاءات HTTP عامة، يقدم Portkey توجيهًا ومراقبة مدركين للمطالبات والنماذج.
ما يبرع فيه Portkey
أين يقصر Portkey
تصميم Portkey يركز عمدًا على التطبيقات، مما يفرض قيودًا على مستوى المؤسسة
مع تحول الذكاء الاصطناعي إلى قدرة داخلية مشتركة بدلاً من ميزة تطبيق واحدة، غالبًا ما تتطلب هذه القيود طبقات بنية تحتية إضافية.
الأفضل لـ: تطبيقات نماذج اللغة الكبيرة (LLM) الخاصة بفريق واحد التي تنتقل إلى مرحلة الإنتاج المبكر.
٣. LiteLLM: بوابة مفتوحة المصدر موجهة للمطورين
LiteLLM هي مفتوحة المصدر بوابة LLM التي توفر واجهة برمجية موحدة ومتوافقة مع OpenAI للوصول إلى عشرات من مزودي النماذج.
ما يميز LiteLLM
أوجه قصور LiteLLM
الأفضل لـ: LiteLLM هي نقطة دخول فعالة ولكنها تتطلب تعزيزًا كبيرًا للبيئات المنظمة أو متعددة الفرق.
اقرأ أيضًا: Portkey مقابل LiteLLM
4. AWS Bedrock: واجهات برمجة تطبيقات النماذج بدون خادم
يوفر AWS Bedrock وصولاً مُدارًا وبدون خادم إلى النماذج الأساسية من مزودين مثل Anthropic و Amazon. إنه يجرّد البنية التحتية بالكامل ويتم الفوترة بناءً على استخدام الرموز فقط.
ما يميز AWS Bedrock
المقايضات الخفية لـ AWS Bedrock
غالبًا ما تفاجئ هذه المقايضات الفرق مع انتقال أعباء العمل من التجريب إلى الاستخدام الإنتاجي المستمر.
الخلاصة: Bedrock يحقق أقصى استفادة من السرعة والبساطة، وليس كفاءة التكلفة على المدى الطويل أو التحكم.
5. AWS SageMaker: بنية تحتية مُدارة للتعلم الآلي
يوفر SageMaker مجموعة شاملة لتدريب نماذج التعلم الآلي وضبطها ونشرها. على عكس Bedrock، فإنه يعرض خيارات البنية التحتية مباشرة للمستخدمين.
ما الذي يبرع فيه AWS Sagemaker
عيوب AWS Sagemaker
الخلاصة: يوفر SageMaker التحكم ولكن على حساب البساطة التشغيلية.
6. Databricks: منصة Lakehouse للتعلم الآلي
يتعامل Databricks مع الذكاء الاصطناعي من منظور يركز على البيانات أولاً، ويدمج قدرات التعلم الآلي (ML) والذكاء الاصطناعي التوليدي (GenAI) في بنية Lakehouse الخاصة به.
ما الذي يبرع فيه Databricks
أوجه قصور Databricks
الخلاصة: تتفوق Databricks في هندسة البيانات، لا في خدمة الذكاء الاصطناعي.
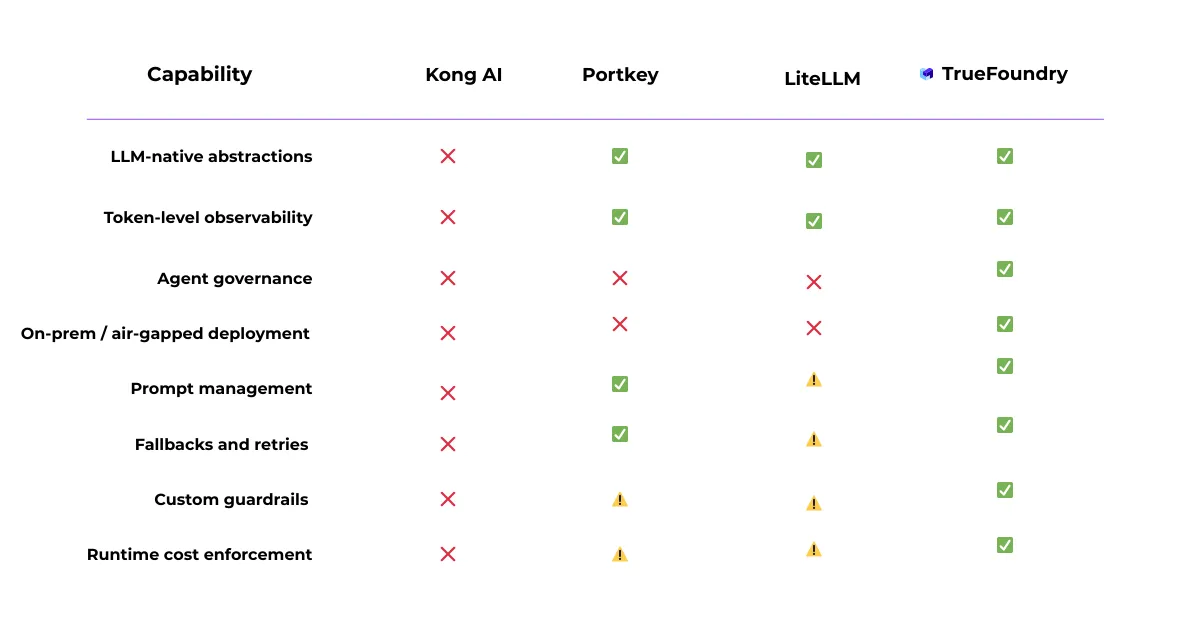
القاسم المشترك: البوابات بلا حوكمة
عبر Kong مقابل LiteLLM، Portkey، وحتى Bedrock، تظهر نفس المشكلة: فهي تدير الطلبات، لا أنظمة الذكاء الاصطناعي.
عبر البوابات والخدمات المُدارة، تظهر مشكلة متكررة: تركز معظم الأدوات على الطلبات، لا على الأنظمة.
يجيبون على أسئلة مثل:
يواجهون صعوبة في:
هذه مخاوف على مستوى البنية التحتية.
تحتل TrueFoundry طبقة مختلفة في المكدس. فبدلاً من التركيز فقط على توجيه واجهة برمجة التطبيقات (API) أو الخدمات المُدارة، فإنها تتعامل مع أعباء عمل الذكاء الاصطناعي – النماذج والوكلاء والخدمات والمهام – ككائنات بنية تحتية أساسية. وهذا يحول المسؤولية من كود التطبيق إلى المنصة نفسها.
تم بناء بوابة TrueFoundry للذكاء الاصطناعي وفقًا للمبادئ الأساسية التالية:
هذا يعني أن بوابة الذكاء الاصطناعي هي مكون من نظام أكبر، مما يسمح للمؤسسات بتوسيع نطاق حالات استخدام الذكاء الاصطناعي الخاصة بها بسلاسة.
Here's The Evaluation Framework for Proposal Template
| Criteria | What should you evaluate ? | Priority | TrueFoundry |
|---|---|---|---|
| Unified API & Routing | |||
| Unified OpenAI-compatible endpoint | Is the gateway API compatible with OpenAI's /v1/chat/completions and /v1/responses formats, allowing consistent access across different models through a standardized interface? | Must have | ✅ Supported: OpenAI-compatible endpoint across all providers. |
| Provider and model coverage | Does it support leading providers like OpenAI, Azure OpenAI, Amazon Bedrock, Anthropic, Gemini, Groq, plus self-hosted models? | Must have | ✅ Supported: 1000+ LLMs across hosted and self-hosted providers. |
| Model onboarding speed | How quickly can new models (OpenAI-compatible and non-standard APIs) be added without code changes? | Must have | ✅ Supported: config-driven onboarding within minutes. |
| Multimodal support | Does the gateway support text, vision, audio, image generation, and embeddings through a single interface? | Depends on use case | ✅ Supported: chat, embeddings, images, audio, rerank, and realtime APIs. |
| Routing, load balancing, fallback | Can requests be routed by model, provider, latency, priority, weight, region, and failure state with automatic retries? | Must have | ✅ Supported: load balancing, fallbacks, weighted and latency-based routing. |
| Model switching without code change | Is model switching supported via headers or config without changing client code? | Must have | ✅ Supported: header-based and config-based model switching. |

تصبح بوابة TrueFoundry للذكاء الاصطناعي حاسمة عندما يتجاوز استخدام الذكاء الاصطناعي التطبيقات المعزولة ويصبح قدرة مشتركة وحيوية للإنتاج. في تلك المرحلة، غالبًا ما تكون التحديات أقل حول استدعاءات النماذج الفردية وأكثر حول الاتساق التشغيلي عبر الفرق والبيئات.
إليك كيف تختلف بوابة TrueFoundry للذكاء الاصطناعي عن الحلول الأخرى:
تركز العديد من أدوات الذكاء الاصطناعي على المخاوف المتعلقة بمستوى الطلب مثل التوجيه وإعادة المحاولة والمراقبة الأساسية. وهذا عادة ما يكون كافيًا في المراحل المبكرة.
ومع ذلك، مع توسع الاستخدام، تبدأ النماذج والوكلاء في التصرف بشكل أشبه بالخدمات طويلة الأمد. تحتاج الفرق إلى ملكية أوضح، وإدارة لدورة الحياة، وحدود تشغيلية. تم تصميم TrueFoundry لإدارة أعباء عمل الذكاء الاصطناعي – النماذج والخدمات والمهام – كمكونات بنية تحتية ذات خصائص نشر وتشغيل محددة.
في العديد من المكدسات، يتم تكوين ضوابط الوصول وسياسات الاستخدام على مستوى التطبيق أو حزمة تطوير البرامج (SDK). وبمرور الوقت، قد يؤدي ذلك إلى عدم الاتساق مع تزايد عدد الخدمات.
تطبق TrueFoundry الضوابط على مستوى البيئة، حيث تفصل بين بيئات التطوير والاختبار والإنتاج افتراضيًا. تُطبق السياسات المحددة في هذه الطبقة بشكل موحد على جميع أعباء العمل المنشورة داخل البيئة، مما يقلل الاعتماد على التكوين الخاص بكل تطبيق.
غالبًا ما تزداد تكاليف الذكاء الاصطناعي بسبب التزامن أو عمليات إعادة المحاولة أو أعباء العمل الخلفية، وليس بسبب الطلبات الفردية. تعالج TrueFoundry هذا الأمر بفرض قيود على التزامن والإنتاجية واستخدام الموارد أثناء التنفيذ.
يتيح ذلك للمؤسسات إدارة البنية التحتية المشتركة بشكل أكثر قابلية للتنبؤ مع تزايد الاستخدام.
بينما تعد مقاييس مستوى الرمز المميز مفيدة، إلا أنها لا تفسر سلوك النظام في بيئة الإنتاج بشكل كامل. تربط TrueFoundry إشارات مستوى الطلب بمقاييس البنية التحتية مثل استخدام وحدة المعالجة المركزية/وحدة معالجة الرسوميات وسلوك التحجيم التلقائي، مما يساعد الفرق على فهم محركات الأداء والتكلفة في سياقها.
تعمل بعض المؤسسات في ظل قيود تتطلب شبكات خاصة، أو عمليات نشر داخلية، أو إقامة صارمة للبيانات. صُممت TrueFoundry للعمل في هذه البيئات، مما يسمح بإدارة أعباء عمل الذكاء الاصطناعي باستخدام نفس معايير البنية التحتية المطبقة في أماكن أخرى بالمؤسسة.
الخاتمة
يعكس المشهد الحالي لمنصات الذكاء الاصطناعي السرعة التي تطور بها الذكاء الاصطناعي التوليدي. تعالج العديد من الأدوات مشكلات حقيقية — مثل التوجيه، والوصول إلى النماذج، وقابلية المراقبة، أو التدريب — ولكنها تفعل ذلك من نقاط انطلاق مختلفة. ونتيجة لذلك، لا تغطي فئة واحدة بشكل طبيعي المجموعة الكاملة من المتطلبات التشغيلية التي تظهر بمجرد أن يصبح الذكاء الاصطناعي حاسمًا للإنتاج.
تقدم TrueFoundry أكبر قيمة عندما تحتاج أعباء عمل الذكاء الاصطناعي إلى التشغيل بنفس الانضباط المتبع في أنظمة الإنتاج الأخرى—عبر البيئات المختلفة، وتحت سياسات مشتركة، ومع سلوك موارد يمكن التنبؤ به.
غالبًا ما تبدأ الشركات التي تقارن بين البائعين بالبحث عن أفضل بوابة LLM، لكن الميزة التنافسية الحقيقية تكمن في مدى جودة إدارة المنصة لأنظمة الذكاء الاصطناعي على نطاق واسع. إن فهم مكانة كل منصة، ومتى تبدأ افتراضات تصميمها في الانهيار، أمر ضروري عند تقييم أفضل بوابة للذكاء الاصطناعي لعمليات النشر على مستوى المؤسسات. يعتمد الاختيار الصحيح بشكل أقل على الميزات الفردية وأكثر على كيفية توقع المؤسسة لتطور استخدامها للذكاء الاصطناعي بمرور الوقت.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.


The best AI gateway depends on the organization's specific requirements. TrueFoundry's AI Gateway stands out for enterprises needing multi-provider routing, centralized governance, cost tracking, and MCP integration in a single platform. Other strong options include LiteLLM for open-source flexibility and Kong AI Gateway for teams already invested in Kong's API management ecosystem.
An AI gateway is a middleware layer that sits between applications and LLM providers (such as OpenAI, Anthropic, or Google). Its architecture typically includes a routing engine that directs requests to the appropriate model, a policy layer for enforcing rate limits and access controls, an observability stack for logging and cost tracking, and a caching layer to reduce redundant API calls. This architecture allows organizations to manage multi-model deployments from a single control plane.
TrueFoundry differentiates itself by combining AI gateway capabilities with a full ML infrastructure platform including model serving, fine-tuning, and MCP server management in a unified solution. Its AI Gateway offers enterprise-grade features such as per-team budget controls, audit logging, model fallback routing, and native MCP support, making it particularly well-suited for organizations looking to govern and scale Claude Code and other agentic AI deployments






أحدث الأخبار والمقالات والموارد تصلك مباشرة إلى بريدك الوارد
© 2026 جميع الحقوق محفوظة.







.png)
.webp)










.webp)
