














July 18, 2026
|
5 min read

Published: May 29, 2026

Blazingly fast way to build, track and deploy your models!
Once upon a time – roughly six months ago in startup years – there was Jason, a brilliant ML engineer at a rapidly growing fintech company. Jason was the resident "AI Whisperer." When the product team needed their new LLM-powered chatbot to sound more empathetic but less hallucination-prone about interest rates, they called Jason.
Jason’s toolkit was vast: state-of-the-art vector databases, highly optimized Kubernetes clusters, and sophisticated CI/CD pipelines. But the heart of the operation, the actual prompts driving these multi-million dollar features, lived in a precarious ecosystem.
Some prompts were hardcoded into Python f-strings, buried deep within conditional logic like ancient artifacts. Others existed in a 40-page shared Google Doc titled "FINAL_PROMPTS_v3_REAL_FINAL(2).docx," maintained by three different product managers. The newest experimental prompts were currently slacked to Jason by the CEO at 11:30 PM.
When a customer complained that the chatbot had confusingly offered them a mortgage in Klingon, Jason didn’t debug code. Jason went on an archeological dig through Slack history and git commits to find out which version of the "empathy prompt" was running in production and who changed it last.
Jason wasn’t doing engineering anymore. Jason was doing digital janitorial work. The team had built a Ferrari engine but was steering it with loose bits of string.
The pain behind the above story is actually acute and universal. Moving generative AI from a hackathon prototype to a reliable production system reveals a critical missing piece in the traditional MLOps stack.
In the early days, treating prompts as code seemed logical. You version them in Git, you deploy them with the application. But as teams scale, this model collapses. Prompts are not traditional code; they are configuration, business logic, and user interface all rolled into one natural language package.
When prompts are tightly coupled with codebases, several critical issues emerge:
To cross the chasm from prototype to production, we must stop treating prompts as "magic strings" scattered throughout our infrastructure. We need to treat them as first-class citizens.
Before implementing a structured approach, the workflow often looks like a tangled web of miscommunication and manual effort.
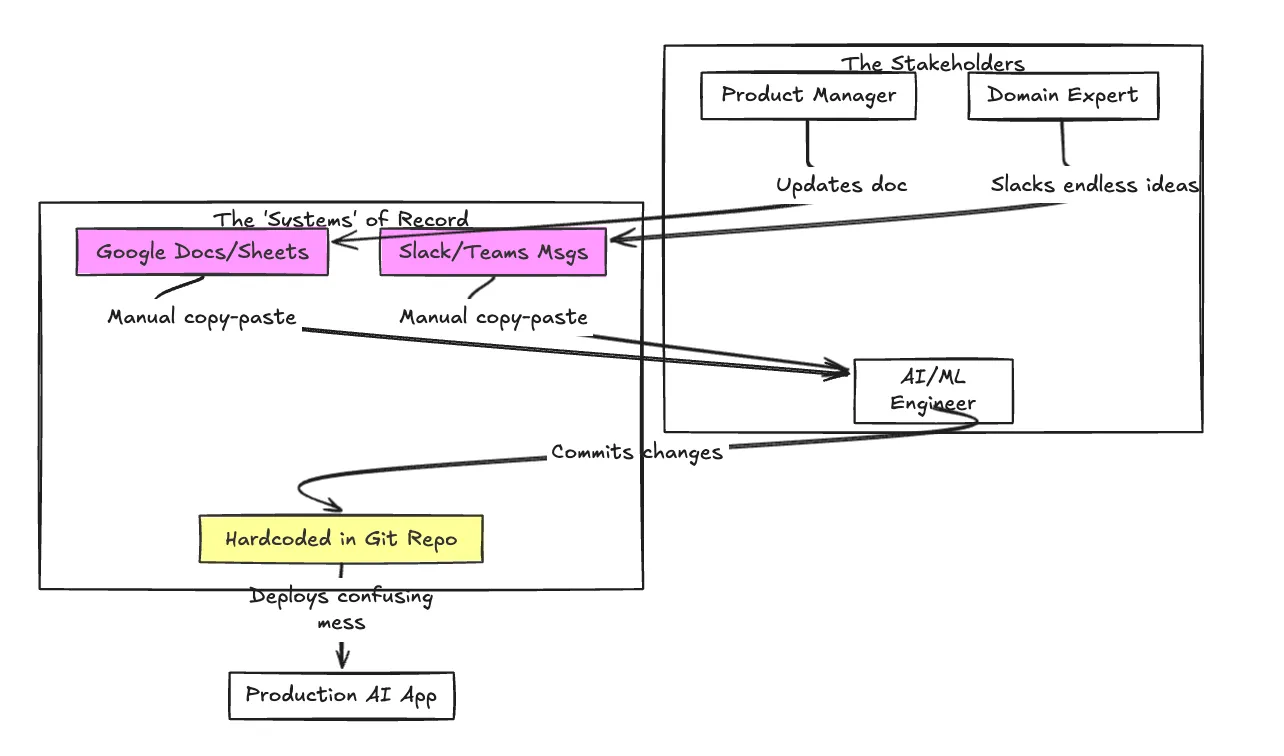
This is where a dedicated Prompt Management System becomes essential. It is the bridge between the experimental art of prompt engineering and the rigorous discipline of production software engineering.
TrueFoundry acts as this central control system. It is designed to decouple prompt management from application logic, allowing teams to collaborate, version, evaluate, and deploy prompts with the same rigor they apply to traditional code, but with interfaces designed for the specific needs of LLM workflows.
TrueFoundry transforms prompt management from an ad-hoc task into a structured, auditable infrastructure layer.
TrueFoundry provides a centralized prompt registry. No more hunting through Google Docs or codebases. Every prompt, for every use case, resides in one secure, accessible location.
This is the most significant shift for velocity. In TrueFoundry, your application code doesn't contain the prompt text. Instead, it contains a lightweight SDK call that fetches the active version of the desired prompt.
This means a Product Manager can iterate on a prompt, test it within TrueFoundry’s playground, and "promote" it to production without an engineer ever needing to touch the application code or trigger a redeployment.
With TrueFoundry, the chaos transforms into a streamlined lifecycle. Stakeholders collaborate in the hub, versions are tracked rigorously, and applications consume prompts reliably via API, with rate limiting in AI gateway ensuring stable production behavior under heavy usage.
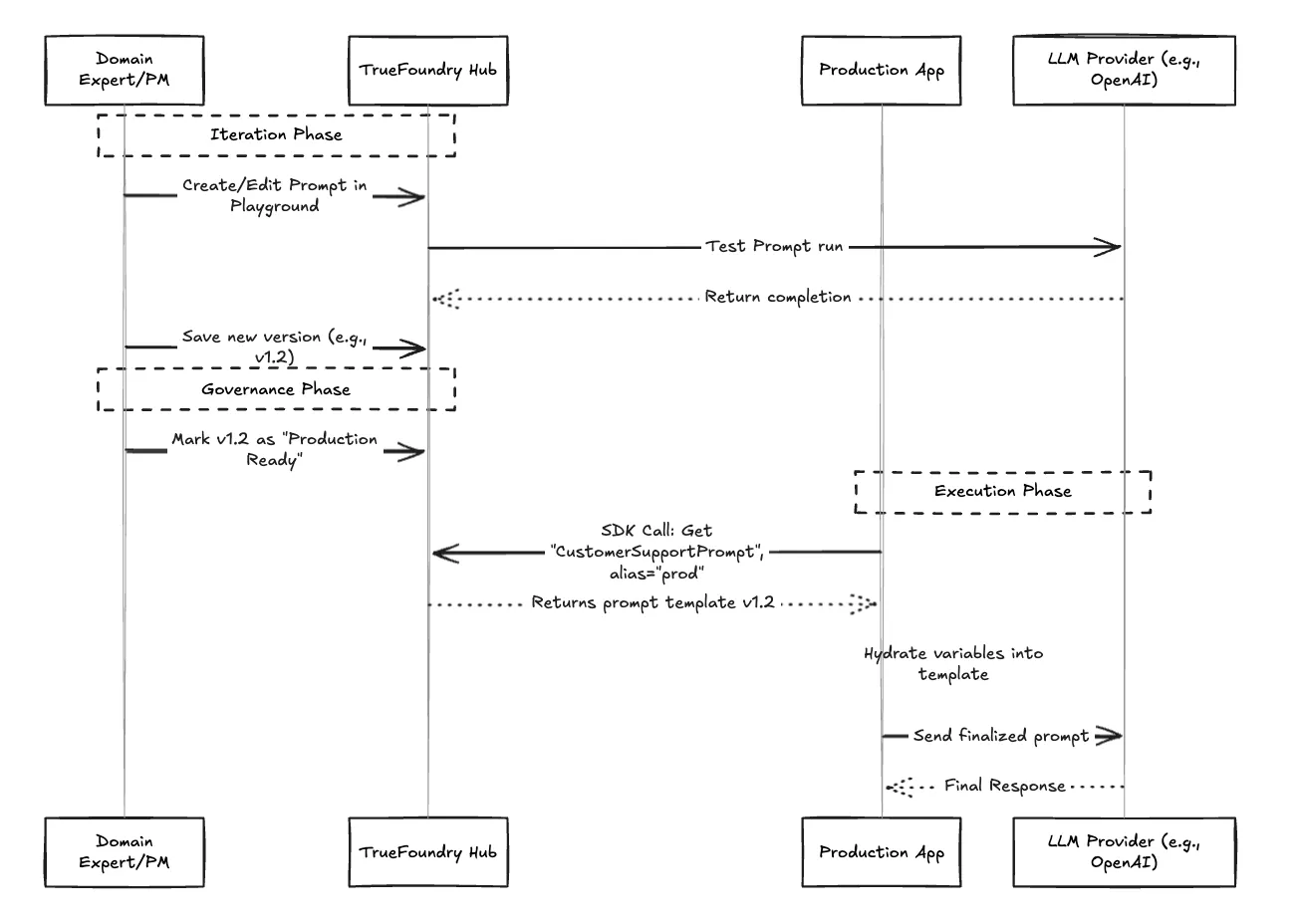
Managing the prompt text is only half the battle. How do you know if version 2.0 is actually better than version 1.5? TrueFoundry integrates evaluation alongside management. Before promoting a prompt to production, you can run it against golden datasets to ensure accuracy, tone, and safety haven't regressed.
For more information, please visit https://www.truefoundry.com/docs/ai-gateway/prompt-management
Returning to our story, Jason implemented TrueFoundry. The Google Docs were archived. The hardcoded strings were replaced with SDK calls.
Now, when the CEO wants to change the chatbot's tone, they log into TrueFoundry, draft a new version, test it against a few examples, and tag Jason for review. Jason can see the exact diff, run an evaluation set against it, and approve it for deployment in minutes—all without writing a single line of Python.
The shift to production AI requires recognizing that prompts are a new class of software artifact. They need their own dedicated infrastructure. TrueFoundry provides the tooling to turn the art of prompt engineering into a manageable, scalable engineering discipline, ensuring your generative AI applications are as robust as the rest of your stack.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








The latest news, articles, and resources sent to your inbox
.png)

.webp)

.webp)
.webp)



.webp)
.webp)
.webp)





