













.png)
July 17, 2026
|
5 min read

Published: March 13, 2026

Blazingly fast way to build, track and deploy your models!
We have moved past the "check out this cool demo" phase of Voice AI. Enterprises aren't just building cute Alexa skills anymore. They are deploying complex, multi-modal systems designed to handle millions of sensitive customer interactions—from banking wire transfers to healthcare triage.
But here is the uncomfortable truth about moving Voice AI from prototype to production: it is incredibly fragile.
Unlike text-based chatbots, where a failure is just a bad text response, a failure in Voice AI is visceral. It’s dead air. It’s a robotic voice stuttering. It’s a customer yelling "agent!" repeatedly because the latency on the RAG lookup took 400ms too long and the ASR cut them off.
When you are orchestrating a sprawling stack involving Automatic Speech Recognition (ASR), complex intent classification, agentic Retrieval-Augmented Generation (RAG), and realistic Text-to-Speech (TTS), standard application monitoring tools (APMs) are woefully inadequate. They tell you that something broke, but rarely why.
This post will walk through a realistic, large-scale enterprise use case to demonstrate why specialized observability is non-negotiable, and how platforms like TrueFoundry are emerging as the control plane for these complex systems.
To understand the observability challenge, we first need to look at the "beast" we are trying to tame. A modern, conversational voice agent isn't a single model; it's a relay race of highly specialized components, often distributed across different infrastructure.
If any single handoff in this relay race fumbles, the entire user experience crashes.
Let’s imagine Apex Financial, a large bank deploying a voice assistant to handle mid-tier transactions like checking balances across varying asset classes and initiating international transfers.
The Scale: 50,000 concurrent calls during peak hours.
The Stakes: High. Misinterpreting "fifty" as "sixty" during a transfer is catastrophic.
The Stack:
A customer, "Sarah," calls in. She has a slight background noise and says, "I need to send 5k to my brother in London from my savings."
Here is what that workflow looks like, and where things usually go wrong.
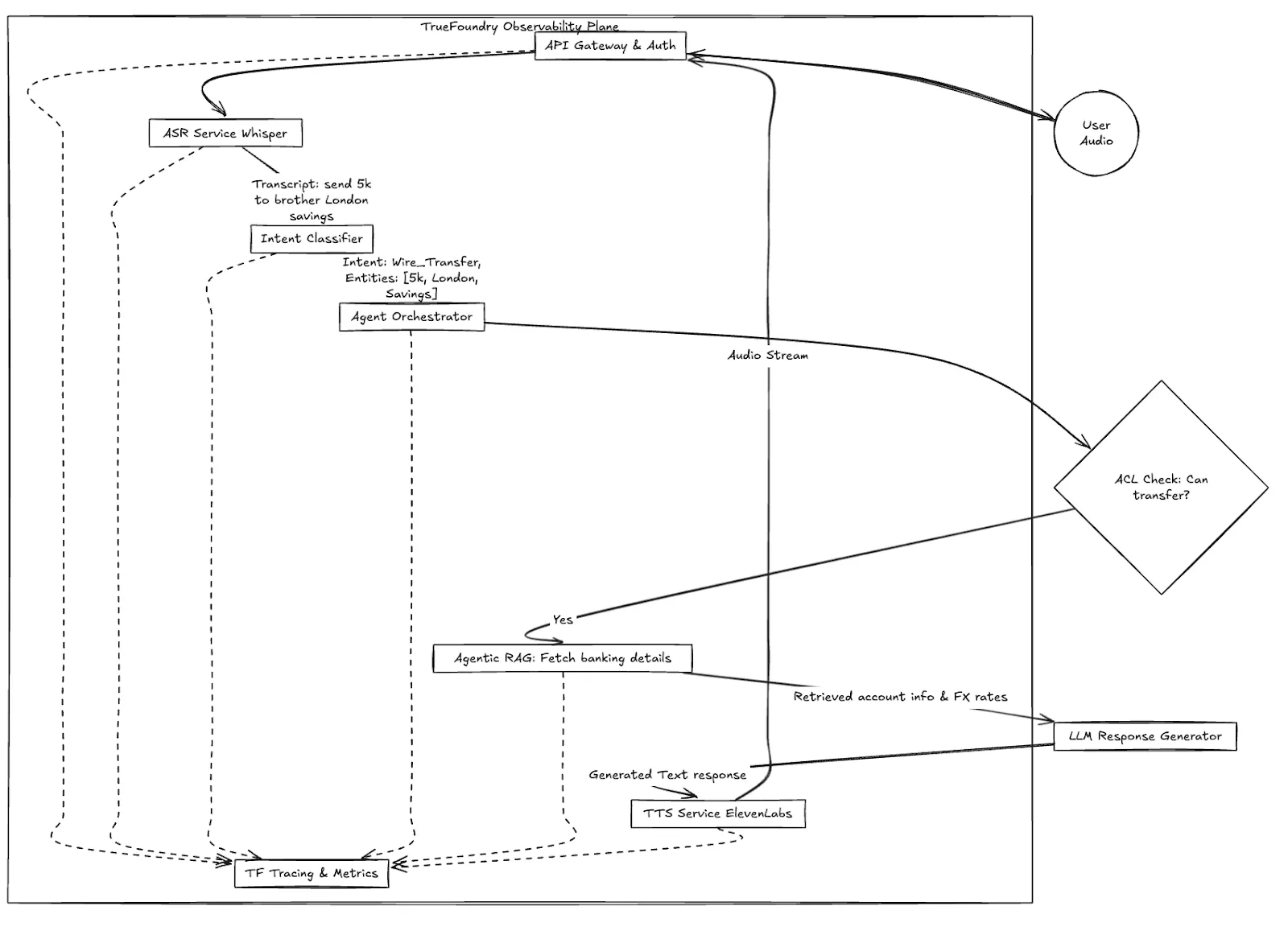
Fig 1: High-level Workflow of Apex Financial's Voice Transaction, showing the critical role of the Observability Plane.
In a standard setup, if Sarah's call fails, the engineering team gets a ticket saying "Voice bot hung up."
They check Datadog or Prometheus. The CPU is fine. Memory is fine. The Kubernetes pods are up. What happened?
Without specialized Voice AI observability, debugging this is like solving a labyrinth mystery without forensic tools.
In a distributed Voice AI system, latency is cumulative. A 200ms delay in ASR plus a 400ms delay in RAG equals a failed customer experience. You need tracing that understands audio frames, not just HTTP requests.
This is where platforms like TrueFoundry are becoming essential. TrueFoundry isn't just another monitoring dashboard; it's an AI/ML infrastructure and observability platform built specifically for the complexities of GenAI stacks, including voice.
TrueFoundry treats the entire chain—from the first audio packet to the final TTS stream—as an observable flow.
Here is how it addresses the critical enterprise needs that generic tools miss:
Standard tracing shows you service-to-service hop times. TrueFoundry's specialized tracing allows you to visualize the latency budget of a conversation in real-time.
You can see that for Sarah’s call, ASR took 350ms (acceptable), but the Agentic RAG step took 2.1 seconds (unacceptable). You can immediately drill down into the RAG step: Was it the vector DB retrieval? Was it the reranking model?
You stop guessing and start fixing the bottleneck.
When your Voice AI uses an agent to make decisions (like checking if Sarah has sufficient funds before asking for the destination), you need to audit the agent's "thought process."
TrueFoundry provides observability into the agent's intermediate steps. You aren't just seeing the input and output; you are seeing the tools the agent selected, the queries it ran against the vector database, and the raw context it retrieved. If the bot gives a wrong answer, you can see exactly which piece of stale data it retrieved from the RAG system that caused the hallucination.
In banking, "who can do what" is paramount. You cannot have your marketing voice bot accidentally accessing the transaction agent.
TrueFoundry provides robust Access Control Lists (ACL) governing which models and agents can interact. Furthermore, as multi-agent systems grow, TrueFoundry is adopting standards like the Model Context Protocol (MCP) to ensure authenticated, secure communication between different AI agents within your ecosystem.
Observability here isn't just performance; it's security auditing. You need a log that proves why Agent A was denied access to Data Source B during a live call.
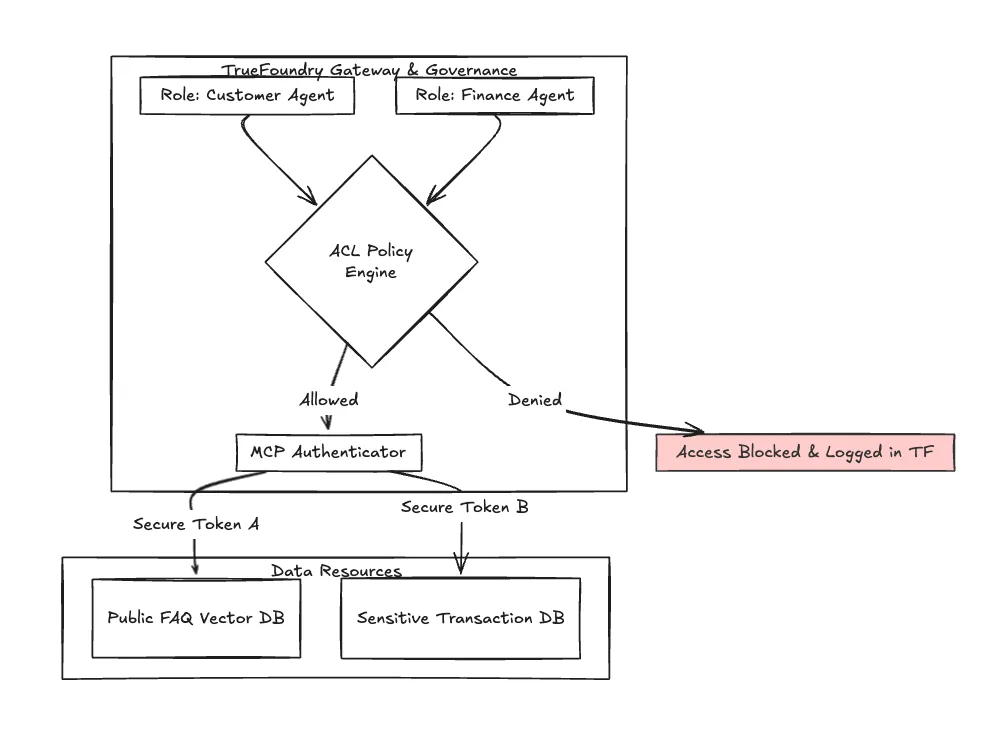
Fig 2: Simplified view of ACL and MCP auth flow managed within the TrueFoundry ecosystem, ensuring isolation of sensitive voice agents.
To summarize the difference between standard monitoring and what is required for enterprise voice AI:
Table 1: Comparison of Standard APM vs. TrueFoundry Voice AI Observability depths.
For Apex Financial, deploying TrueFoundry meant the difference between rolling back their voice assistant program and scaling it. They moved from a Mean Time To Detection (MTTD) of hours to minutes. They could proactively identify that a specific RAG embedding model was causing latency spikes during high-volume periods before customers started hanging up.
When building enterprise Voice AI, the models you choose—Whisper, ElevenLabs, GPT-4o—are just the engine. Observability is the avionics system. You shouldn't attempt to fly a jet with just a speedometer; don't try to run an enterprise voice stack without deep, specialized observability.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








The latest news, articles, and resources sent to your inbox

.webp)

.webp)
.webp)



.webp)
.webp)
.webp)






