








November 5, 2025
|
5 min read


احصل على وصول فوري إلى بيئة TrueFoundry مباشرة. انشر النماذج، ووجّه حركة مرور LLM، واستكشف المنصة بالكامل — بيئة الاختبار الخاصة بك جاهزة في ثوانٍ، ولا يلزم وجود بطاقة ائتمان.









Published: July 4, 2026

Blazingly fast way to build, track and deploy your models!
في هذه المدونة، سنقدم لك تدريب نماذج التعلم الآلي على منصة TrueFoundry. سنتناول كيفية تشغيل مهام التدريب على TrueFoundry. سنرى أيضًا كيف يمكنك إجراء ضبط المعلمات الفائقة (hyperparameter tuning) بسهولة لنماذج التعلم الآلي الخاصة بك، وتشغيل مهامك على وحدات معالجة الرسوميات (GPUs).
لنبدأ أولاً ببيان مشكلة، على سبيل المثال، نريد أن نرى كيف سيتطور مرض السكري لدى المريض بناءً على ميزات مختلفة مثل العمر، مؤشر كتلة الجسم (BMI)، ضغط الدم، إلخ. في هذه المدونة، سنقوم بتدريب مجموعة بيانات السكري نموذج التعلم الآلي في scikit-learn.
بالحديث عن تدريب نماذج التعلم الآلي، هناك عدة طرق للقيام بذلك مثل التدريب محليًا على جهازك، التدريب في Jupyter Notebooks، إلخ. ومع ذلك، قد تتطلب عملية التدريب موارد أكثر مما هو متاح على جهاز محلي.
هنا تتيح لك وظائف TrueFoundry نشر رمز التدريب ليتم تشغيله على جهاز بعيد، ويمكنك تتبع السجلات والمقاييس.
ملاحظة: بينما نستخدم مجموعة بيانات السكري هذه، فإن التعليمات المذكورة في هذه المدونة تنطبق أيضًا على نماذج التعلم الآلي / التعلم العميق الأخرى.
توفر الوظائف طريقة لتشغيل مهام دفعية قصيرة الأجل، متوازية، أو متسلسلة داخل المجموعة (cluster). تم تصميم الوظائف لتكتمل، بدلاً من أن تكون خدمات طويلة الأمد أو تطبيقات تعمل باستمرار. بمجرد اكتمال الوظيفة، يتم تحرير موارد الحوسبة والذاكرة، وبالتالي لا نتحمل أي تكلفة إضافية.
كما ذكرنا سابقًا، سنستخدم مجموعة بيانات مرض السكري في scikit-learn. تحتوي مجموعة البيانات على 442 عينة (مريضًا) و10 ميزات، وجميعها رقمية. تمثل هذه الميزات عوامل مختلفة يمكن أن تؤثر على تطور مرض السكري لدى المرضى. المتغير المستهدف هو أيضًا رقمي ويمثل مقياسًا كميًا لتطور المرض بعد عام واحد من خط الأساس لكل مريض.
قبل أن ننتقل إلى تدريب نماذج التعلم الآلي، دعنا نراجع تعليمات الإعداد:
انتقل إلى لوحة تحكم TrueFoundry وأنشئ حسابًا. بمجرد تسجيل الدخول، سيُطلب منك إنشاء مساحة عمل. ستقوم بنشر مهامك في مساحة العمل هذه.

بمجرد إنشاء مساحة العمل الخاصة بك، انتقل وأنشئ مستودع تعلم آلي (ML Repository) من لوحة التحكم.
مستودع التعلم الآلي (ML Repository) هو مجموعة من التشغيلات والنماذج والمخرجات التي تمثل مشروع تعلم آلي. يمكنك التفكير فيه كمستودع Git، باستثناء أنه يضم المخرجات والنماذج والبيانات الوصفية. يمكن تكوين جميع ضوابط الوصول على مستوى مستودع التعلم الآلي.
بمجرد إنشاء مستودع التعلم الآلي، انتقل إلى مساحات العمل وقم بتحرير مساحة عملك وفعّل 'صلاحية الوصول إلى مستودع التعلم الآلي'. انقر على 'إضافة صلاحية الوصول إلى مستودع التعلم الآلي' لإضافة مستودع التعلم الآلي الخاص بك إلى مساحة العمل هذه. سيمنح هذا المهمة التي تعمل في مساحة العمل صلاحية الكتابة والقراءة من مستودع التعلم الآلي.
pip install servicefoundry
--host: أدخل عنوان URL الخاص بلوحة تحكم TrueFoundry هنا
sfy login --host <YOUR-HOST-URL-HERE>
بمجرد الانتهاء من تعليمات الإعداد المذكورة أعلاه، يمكننا الانتقال إلى قسم التنفيذ.
هيكل الدليل
في هذه المدونة، سنتبع هيكل الدليل التالي حيث:
❯ tree
.
├── deploy.py
├── requirements.txt
└── train.py
الآن دعنا نستعرض كود تدريب نموذج السكري:
خطوات تدريب النموذج
from sklearn.metrics import accuracy_score
from sklearn.datasets import load_diabetes
from sklearn.model_selection import train_test_split
from sklearn.compose import TransformedTargetRegressor
from sklearn.preprocessing import QuantileTransformer
from sklearn.svm import SVR
X, y = load_diabetes(as_frame=True, return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
regressor = SVR(kernel=kernel)
model = TransformedTargetRegressor(
regressor=regressor,
transformer=QuantileTransformer(n_quantiles=n_quantiles, output_distribution="normal"),
)
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy:.2f}")
الكود الكامل لتدريب النموذج
from sklearn.metrics import accuracy_score
from sklearn.datasets import load_diabetes
from sklearn.model_selection import train_test_split
from sklearn.compose import TransformedTargetRegressor
from sklearn.preprocessing import QuantileTransformer
from sklearn.svm import SVR
def train(kernel: str, n_quantiles: int):
# تحميل مجموعة البيانات وإنشاء مجموعات التدريب والاختبار
X, y = load_diabetes(as_frame=True, return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# تهيئة النموذج
regressor = SVR(kernel=kernel)
model = TransformedTargetRegressor(
regressor=regressor,
transformer=QuantileTransformer(n_quantiles=n_quantiles, output_distribution="normal"),
)
# تدريب واختبار النموذج
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy:.2f}"
return regressor, model, X_test, y_test
بما أننا رأينا الآن الكود لتدريب نموذج تعلم آلة، يمكننا المضي قدمًا والتعرف على كيفية حفظ (أو تسجيل) هذه النماذج للاستخدام المستقبلي.
يتكون النموذج من ملف النموذج وبعض البيانات الوصفية. يمكن أن يحتوي كل نموذج على إصدارات متعددة. يمكننا تلقائيًا تسلسل كائنات النموذج وحفظها وتحديد إصداراتها باستخدام save_model_metadata الطريقة والخطوات التالية للقيام بذلك:
خطوات تسجيل النموذج
import mlfoundry
run = mlfoundry.get_client().create_run(ml_repo=ml_repo, run_name="SVR-with-QT")
يمثل "التشغيل" (Run) تجربة واحدة، والتي في سياق التعلم الآلي هي نموذج محدد واحد (مثل الانحدار اللوجستي)، مع مجموعة ثابتة من المعلمات الفائقة (hyper-parameters). يتم تسجيل المقاييس والمعلمات (التفاصيل أدناه) كلها ضمن تشغيل محدد.
run.log_params(regressor.get_params())
run.log_metrics({"score": model.score(X_test, y_test)})
model_version = run.log_model(name="diabetes-regression", model=model, framework="sklearn")
print("model_version =", model_version.version, "model_fqn =", model_version.model_fqn)
يولد كل نموذج مسجل إصدارًا جديدًا مرتبطًا بـ الاسم ومرتبط بالتشغيل الحالي. يمكن تسجيل إصدارات متعددة من النموذج كإصدارات منفصلة تحت نفس اسم.
الكود الكامل لتسجيل النموذج
import mlfoundry
def save_model_metadata(regressor, model, X_test, y_test, ml_repo):
# إنشاء تشغيل في مستودع التعلم الآلي (ml_repo) الخاص بـ truefoundry
run = mlfoundry.get_client().create_run(ml_repo=ml_repo, run_name="SVR-with-QT")
# تسجيل المعلمات الفائقة (hyperparameters) للنموذج
run.log_params(regressor.get_params())
# تسجيل مقاييس النموذج
run.log_metrics({"score": model.score(X_test, y_test)})
# تسجيل النموذج
model_version = run.log_model(name="diabetes-regression", model=model, framework="sklearn")
print("model_version =", model_version.version, "model_fqn =", model_version.model_fqn)
بعد أن رأينا عملية تدريب النموذج وتسجيله، يمكننا تجميع ذلك في ملف واحد train.py ملف. المحتويات النهائية للـ train.py يجب أن تبدو كالتالي:
train.py
# استيرادات ضرورية لكلا الدالتين
def train(kernel, n_quantiles):
...
def save_model_metadata(regressor, model, X_test, y_test, ml_repo):
...
regressor, model, X_test, y_test = train(kernel="linear", n_quantiles=100)
save_model_metadata(regressor, model, X_test, y_test, ml_repo="YOUR ML REPO NAME")
بهذا يكتمل كود تدريب النموذج وتسجيله. الآن، يجب علينا نشر كود تدريب النموذج كوظيفة. الـ deploy.py يحتوي على كود نشر كود تدريب النموذج المذكور أعلاه كما هو موضح أدناه:
deploy.py
from servicefoundry import Build, Job, PythonBuild, LocalSource
# تحديد مواصفات الوظيفة
job = Job(
name="diabetes-train-job",
image=Build(
train.py و "YOUR WORKSPACE FQN HERE" باسم FQN لمساحة العمل الخاصة بك في deploy.py ملف.
في الـ train.py ملف، تحتاج إلى تمرير اسم مستودع ML الذي أنشأته إلى save_model_metadata() الدالة. في الـ deploy.py ملف، تحتاج إلى تمرير FQN لمساحة العمل التي أنشأتها إلى job.deploy() الدالة. الآن نفّذ الأمر التالي لنشر المهمة:
python deploy.py
بعد نشر مهمة التدريب، انتقل إلى القسم الفرعي "Jobs" ضمن قسم "Deployments"، يجب أن يبدو مشابهاً لهذا:
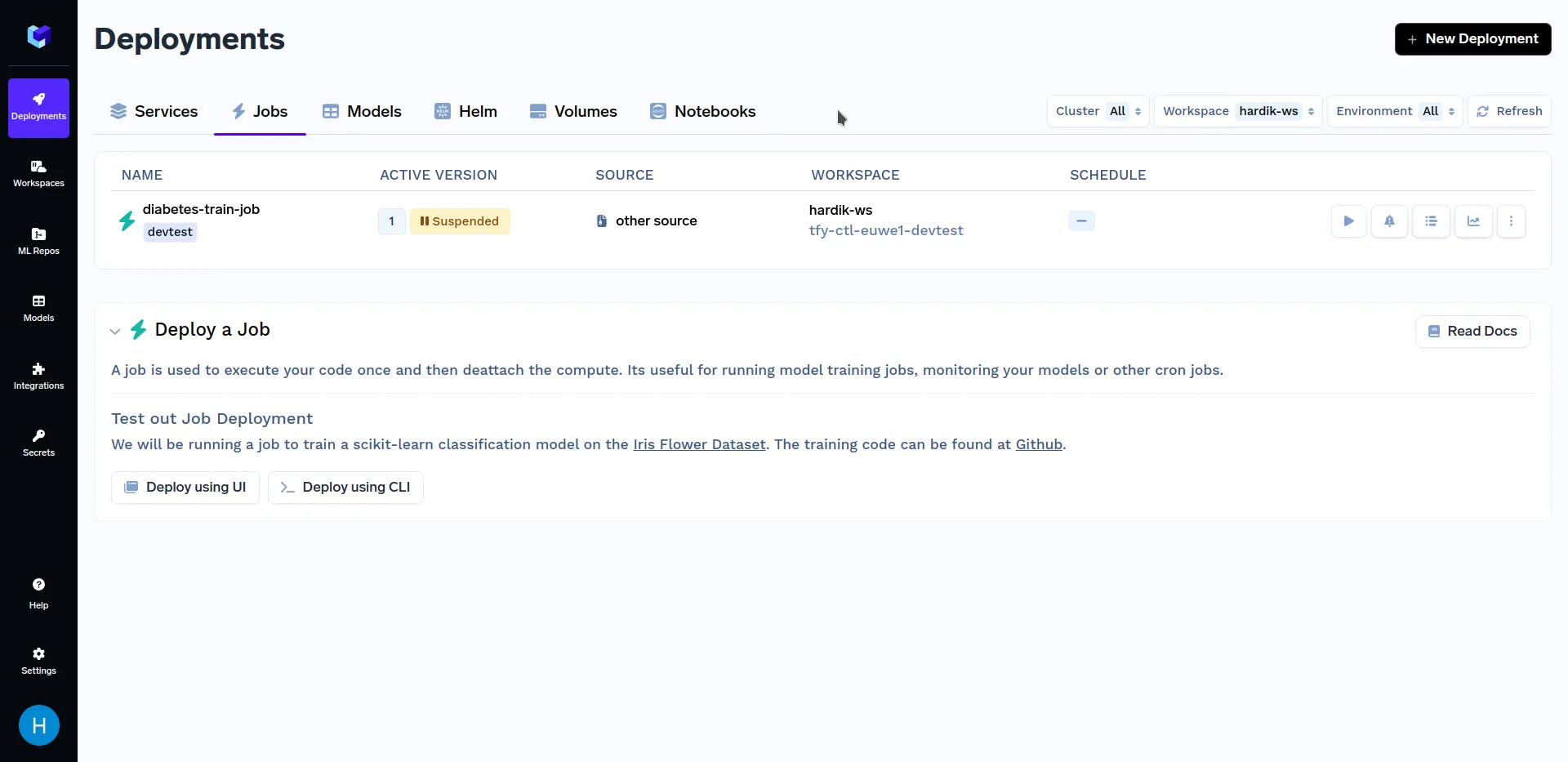
الآن بعد أن انتهينا من نشر مهمتنا، سنرغب في تشغيلها. يمكنك القيام بذلك باستخدام إما Python SDK أو لوحة تحكم TrueFoundry. أولاً، سنتحدث عن تشغيل المهام من لوحة تحكم TrueFoundry. لمعرفة الطرق الأخرى لتشغيل المهام، راجع قسم تشغيل المهام من Python SDK .
بعد أن يتم نشر مهمة التدريب المذكورة أعلاه، انتقل إلى القسم الفرعي "Jobs" ضمن قسم "Deployments"، ثم انقر على "diabetes-train-job"، وانقر على "Run Job" لتكوين المهمة قبل تشغيلها. يجب أن تبدو مشابهة لهذا:
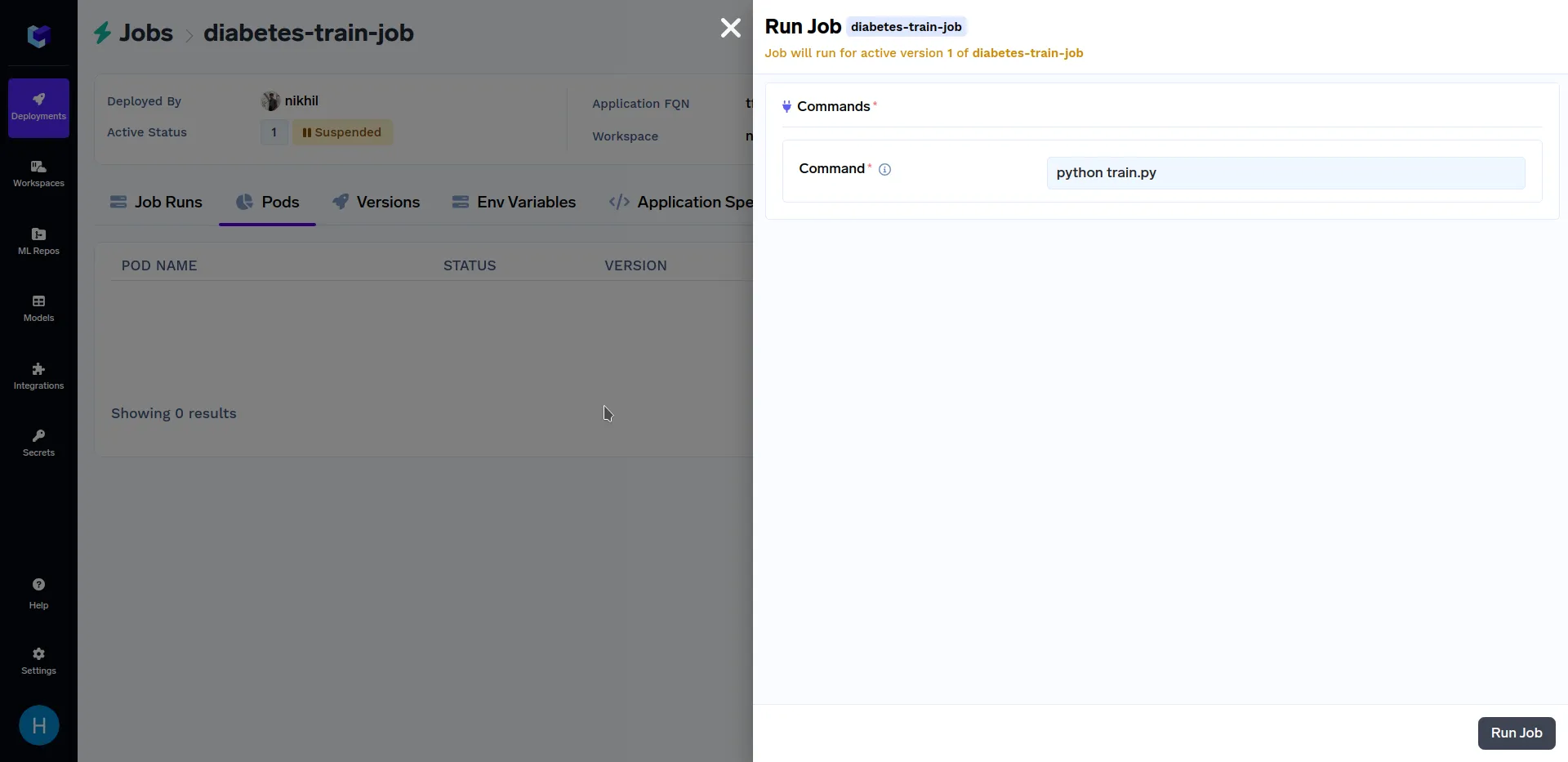
عند هذه الشاشة، انقر على "Run Job" في الزاوية السفلية اليمنى لتشغيل هذه المهمة. بعد أن ينتهي تشغيلمهمة التدريب، انتقل إلى القسم الفرعي "Jobs" ضمن قسم "Deployments"، وانقر على "diabetes-train-job"، يجب أن تبدو مشابهة لهذا:
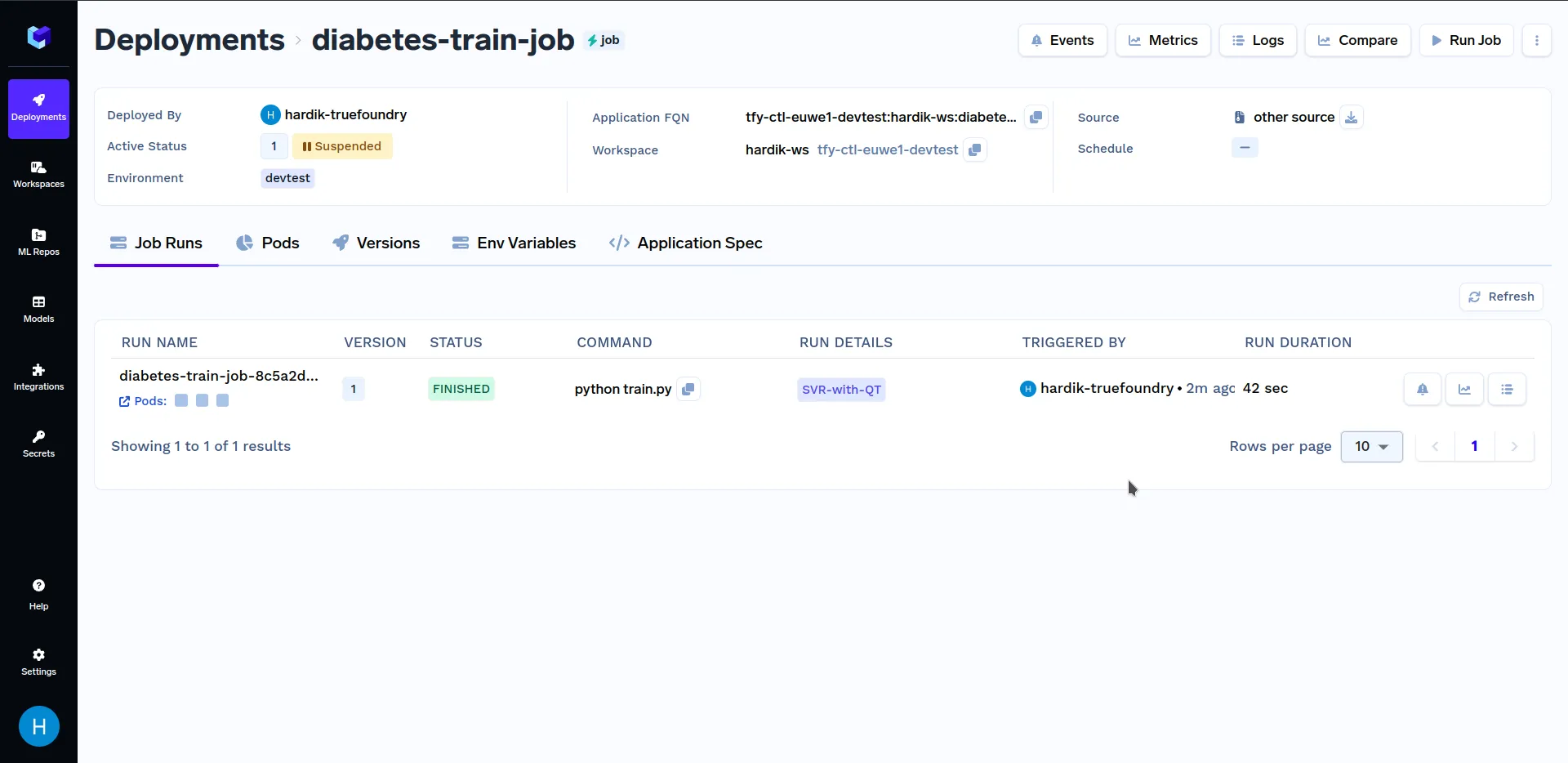
ضمن "Run Details"، انقر على SVR-with-QT لمشاهدة المقاييس الرئيسية والمعاملات الفائقة التي تم تسجيلها في train.py ملف. يجب أن يبدو مشابهًا لهذا:
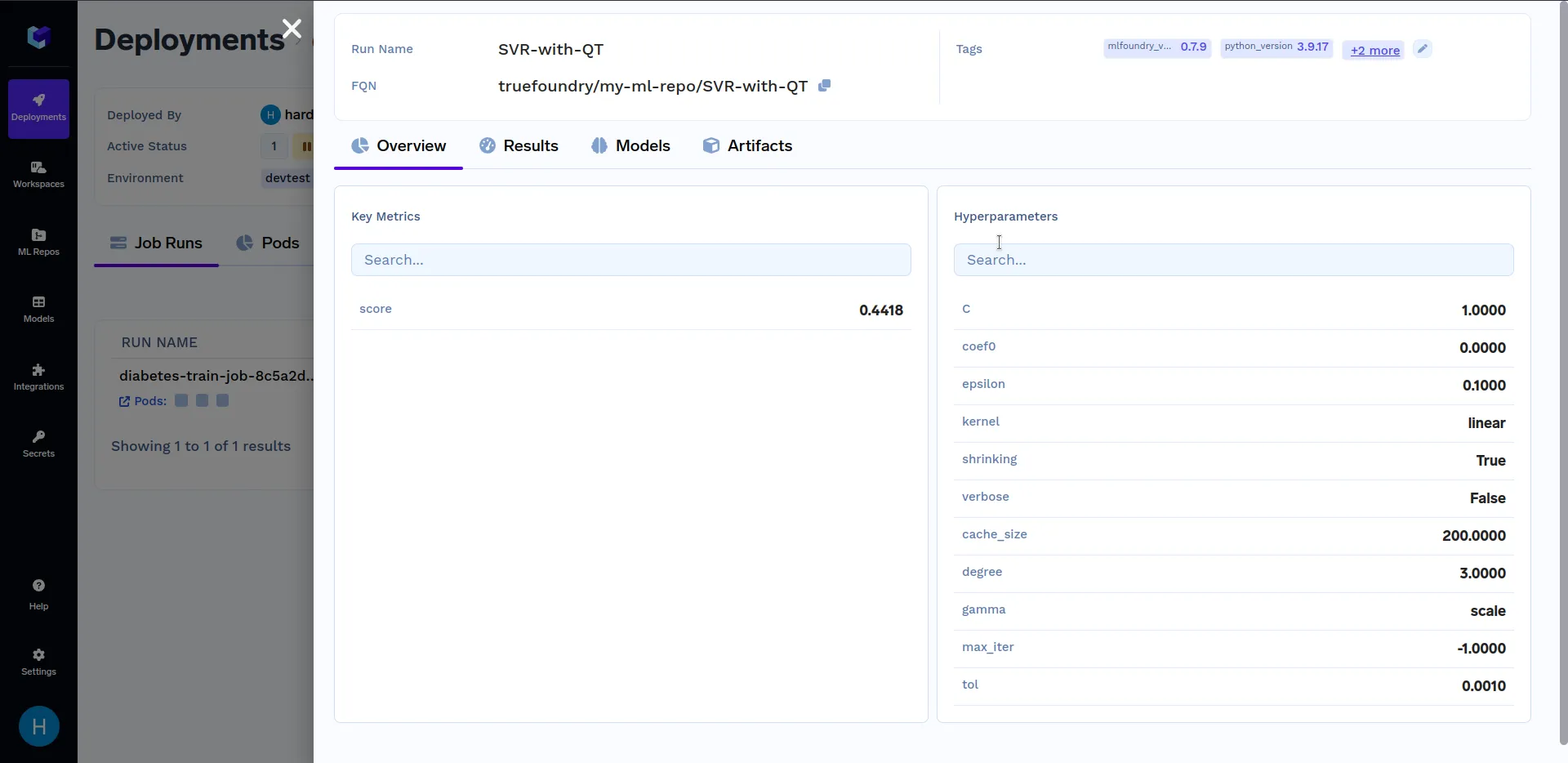
تخيل أن لديك مهام معالجة بيانات واسعة النطاق أو مهام معالجة دفعية حيث يعد تشغيل مهمة واحدة بتكوينات مختلفة أمرًا ضروريًا ليس فقط لتبسيط سير عملك ولكن أيضًا لضمان الاتساق في تنفيذ المهام. في مثل هذه الحالات، ستكون المهمة ذات المعلمات (Parameterized job) مفيدة للغاية.
المهمة ذات المعلمات (Parameterized Job) هي نوع من المهام التي تتيح لك إنشاء عدة نُسخ (pods) بمعلمات أو مدخلات مختلفة. الهدف الأساسي للمهمة ذات المعلمات هو توفير المرونة في تنفيذ المهام عن طريق تخصيص سلوكها لسيناريوهات مختلفة.
على سبيل المثال، مهمة بأمر مثل python main.py --n_quantiles {{n_quantiles}} هي مهمة ذات معلمات حيث تأخذ n_quantiles كمدخل قبل التشغيل. يمكننا تبسيط المهمة المنشورة أعلاه باستخدام المعلمات.
لتحليل وسائط سطر الأوامر، سنستخدم argparse الوحدة. يوضح الكود التالي الكود المحدث لـ train.py و deploy.py ملفات، حيث تكون القيم الافتراضية لـ kernel و n_quantiles هي خطي و 100 على التوالي:
train.py
import os, argparse
def train(kernel, n_quantiles):
...
def log_model(regressor, model, X_test, y_test, ml_repo):
...
parser = argparse.ArgumentParser()
parser.add_argument("--kernel", default="linear", type=str)
parser.add_argument("--n_quantiles", default=100, type=int)
args = parser.parse_args()
regressor, model, X_test, y_test = train(kernel=args.kernel, n_quantiles=args.n_quantiles)
log_model(regressor, model, X_test, y_test, ml_repo=os.environ.get("ML_REPO_NAME"))
deploy.py
import argparse
from servicefoundry import Build, Job, PythonBuild, Param, LocalSource
parser = argparse.ArgumentParser()
parser.add_argument("--workspace_fqn", type=str, required=True)
parser.add_argument("--ml_repo", type=str, required=True)
args = parser.parse_args()
cmd = "python train.py --kernel {{kernel}} --n_quantiles {{n_quantiles}}"
# تحديد مواصفات المهمة
# يتغير الأمر فقط في خاصية 'image'
job = Job(
...
image=Build(build_spec=PythonBuild(command=cmd, ...), ...),
params=[
Param(name="n_quantiles", default='100'),
Param(name="kernel", default='linear', description="نواة SVM"),
],
env={ "ML_REPO_NAME": args.ml_repo }
)
deployment = job.deploy(workspace_fqn=args.workspace_fqn)
ملاحظة: تأكد من استبدال "YOUR ML REPO NAME" باسم مستودع ML الخاص بك و"YOUR WORKSPACE FQN HERE" بمعرف FQN لمساحة العمل الخاصة بك في الأمر أدناه.
الآن قم بتنفيذ الأمر التالي لنشر المهمة ذات المعلمات:
python deploy.py --workspace_fqn "YOUR WORKSPACE FQN HERE" --ml_repo "YOUR ML REPO NAME"
بدلاً من ذلك، يمكنك التنفيذ مباشرة من مستودع GitHub الخاص بنا.
git clone https://github.com/truefoundry/truefoundry-examples.git
cd training-job-example
python deploy.py --workspace_fqn "YOUR WORKSPACE FQN HERE" --ml_repo "YOUR ML REPO NAME"
سيتم إنشاء الإصدار 2 من المهمة بعد اكتمال النشر. بعد أن يتم الانتهاء من نشر مهمة التدريب، الانتهاء من النشر، الخطوة التالية هي تشغيل هذه المهمة.
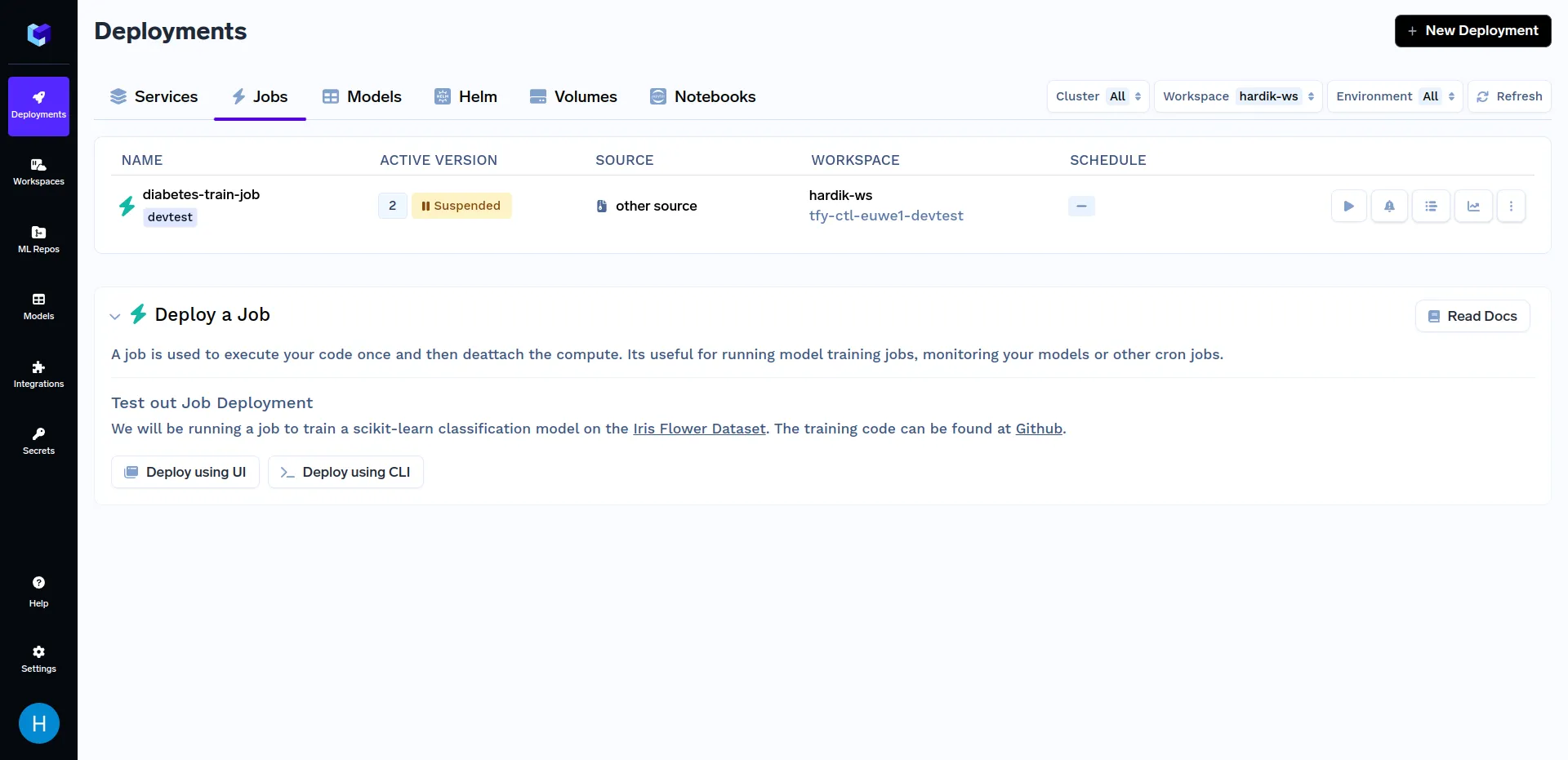
انقر على "diabetes-train-job"، وانقر على "Run Job" لتكوين المهمة قبل تشغيلها. يمكنك الآن تغيير n_quantiles و kernel المعلمات. يجب أن تبدو مشابهة لهذا:
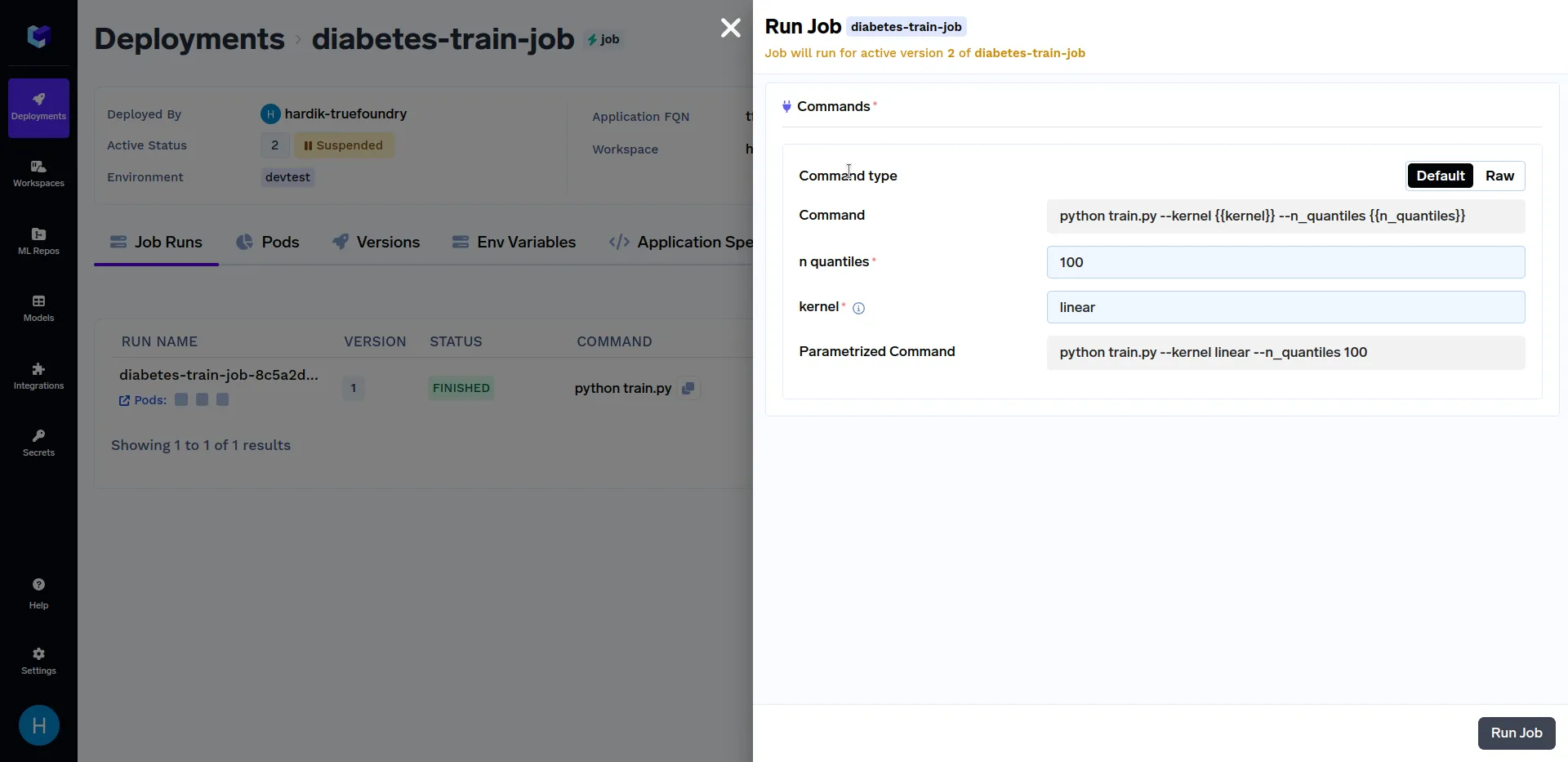
جرب تشغيل المهام بقيم مختلفة لـ النواة معامل مثل خطي، سيجمويد، بولي و RBF. وبالمثل، يمكنك استخدام قيم مختلفة لمعاملات n_quantiles مثل 50، 80، 100، إلخ. يجب أن تبدو عمليات تشغيل المهام المختلفة مشابهة لهذا:
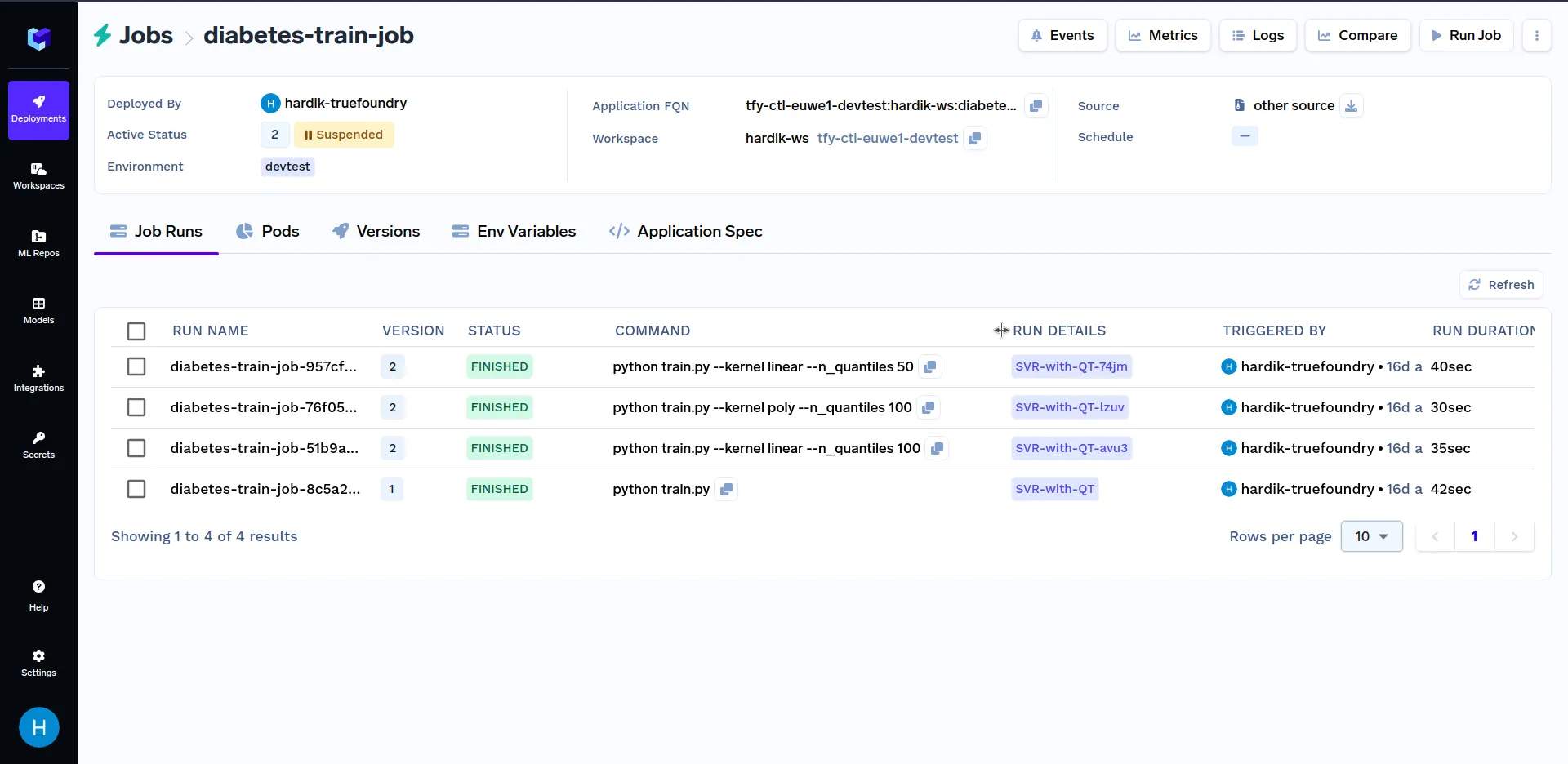
يمكنك مقارنة مقاييس عمليات تشغيل المهام المختلفة في لوحة التحكم بالنقر على زر المقارنة في الجزء العلوي الأيمن من لوحة التحكم كما هو موضح أدناه:
يمكنك قراءة المزيد حول نشر المهام ذات المعلمات هنا:
حتى الآن، لم نرَ سوى تشغيل المهام من TrueFoundry Dashboard. الآن قد لا يكون تشغيل مهمة دائمًا مرغوبًا به عبر واجهة المستخدم، لذلك سنتناول الآن كيفية تشغيل مهمة برمجيًا عبر Python SDK.
يمكنك تشغيل مهمتك برمجيًا باستخدام trigger_job الدالة كما هو موضح أدناه:
from servicefoundry import Job, trigger_job
# تكوين نشر مهمة
job = Job(...)
# نشر مهمة
job_deployment = job.deploy(workspace_fqn="YOUR WORKSPACE FQN")
# تشغيل/تنفيذ مهمة
trigger_job(
application_fqn=job_deployment.application_fqn,
params={"n_quantiles":"80"}
)
من الممكن أيضًا الحصول على الـ application_fqn بسهولة من لوحة التحكم بالانتقال إلى عمليات النشر --> المهام --> ابحث عن اسم مهمتك في مساحة العمل الخاصة بك (هنا diabetes-train-job).
فيما يلي مثال آخر لتشغيل مهمة برمجيًا. أولاً، استبدل YOUR_APPLICATION_FQN بـ Application FQN لـ المهمة المنشورة أعلاه في الكود الموضح أدناه. الـ Application FQN لتطبيق ما مُبرز أدناه:
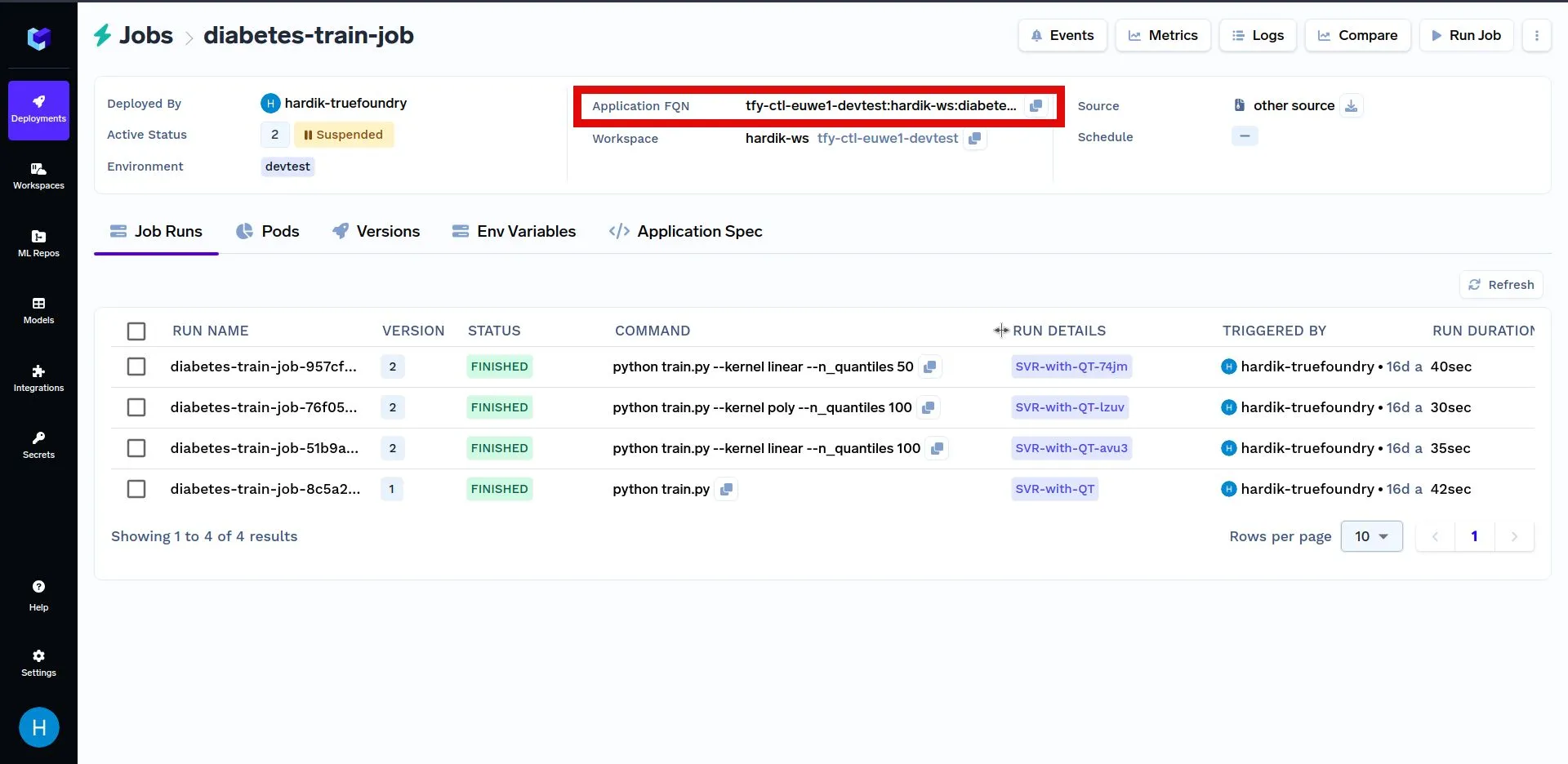
في الكود الموضح أدناه، نختار قيمة عشوائية لمعاملات النموذج ونقوم بتشغيل مهمة باستخدام تلك المعاملات. بعد ذلك، نبحث في سجلات تشغيل المهام للعثور على التشغيل الذي حقق أقصى نتيجة. يشير تشغيل المهمة الذي حقق أقصى نتيجة إلى اختيار أكثر مثالية لمعاملات النموذج.
import random
import mlfoundry as mlf
from servicefoundry import trigger_job
# ابحث عن المهمة المنشورة، واستبدلها بالاسم المؤهل بالكامل (FQN) لتطبيق مهمتك
application_fqn = "YOUR_APPLICATION_FQN"
# توليد المعلمات عشوائياً
n_quantiles = random.randint(50, 100)
kernel_values = ['linear', 'sigmoid', 'poly', 'rbf']
kernel = kernel_values[random.randrange(0, len(kernel_values))]
# تشغيل/تنفيذ مهمة
triggered_job = trigger_job(
application_fqn=application_fqn,
params={
"n_quantiles": str(n_quantiles),
"kernel": kernel
}
)
print(f'تم تشغيل المهمة بقيم n_quantiles={n_quantiles} و kernel={kernel} والاسم هو', triggered_job.jobRunName)
client = mlf.get_client()
ml_repo_name = "YOUR ML REPO NAME HERE"
runs = client.search_runs(ml_repo=ml_repo_name)
max_score = 0
for run in runs:
metrics = run.get_metrics()
print(f'All Metrics for run with name as {run.run_name}":', metrics)
if 'score' in metrics:
max_score = max(max_score, metrics['score'][0].value)
print("Model Max Score: ", max_score)
ملاحظة: تأكد من استبدال "YOUR ML REPO NAME HERE" باسم مستودع ML الخاص بك و "YOUR WORKSPACE FQN HERE" بمعرف FQN لمساحة العمل الخاصة بك في الأمر أدناه.
يمكنك قراءة المزيد حول تشغيل المهام هنا:
يمكنك مقارنة مقاييس عمليات تشغيل المهام المختلفة برمجيًا باستخدام mlfoundry.search_runs الدالة كما هو موضح في الكود التالي:
import mlfoundry as mlf
client = mlf.get_client()
ml_repo_name = "YOUR-ML-REPO-NAME"
# تعيد جميع عمليات التشغيل
runs = client.search_runs(ml_repo=ml_repo_name)
# ابحث عن التشغيلات التي سجلت مقياس دقة أكبر من 0.7
filter_string = "metrics.score > 0.7"
runs = client.search_runs(ml_repo=ml_repo_name, filter_string=filter_string)
يمكنك قراءة المزيد عن search_runs الدالة هنا:
تخيل التعامل مع نماذج واسعة النطاق تحتوي على ملايين أو مليارات المعلمات. سيكون تدريب مثل هذه النماذج باستخدام وحدات المعالجة المركزية التقليدية مستهلكًا جدًا للوقت وقد يكون غير ممكن حتى بسبب قيود الذاكرة.
على سبيل المثال، يستغرق تدريب نموذج شبكة عصبية تلافيفية (CNN) يعتمد على مجموعة بيانات CIFAR-10 في بيئة وحدة معالجة مركزية (CPU) مع 10 حقب 36 دقيقة و 31 ثانية، ولكن نفس النموذج عند تدريبه في بيئة وحدة معالجة رسوميات (GPU) (NVIDIA K80) استغرق 4 دقائق و 6 ثوانٍ فقط. هذا يمثل تحسنًا بمقدار 9 أضعاف (راجع هنا)
تلعب وحدات معالجة الرسوميات (GPUs) دورًا حيويًا في تدريب النماذج واسعة النطاق. فهي توفر النطاق الترددي للذاكرة الضروري وقدرات المعالجة المتوازية للتعامل مع أحجام النماذج الكبيرة والبنى المعقدة بكفاءة. الآن سنتناول كيفية استخدام وحدة معالجة الرسوميات (GPU) في مهمة.
يتطلب استخدام وحدة معالجة الرسوميات (GPU) في المثال أعلاه تعديلات طفيفة في كيفية تهيئة المهمة في ملف deploy.py . يوضح الكود أدناه التكوين المحدث لـ المهمة لاستخدام وحدة معالجة الرسوميات (GPU) وتخصيص موارد مخصصة لوحدة المعالجة المركزية (CPU) والذاكرة:
deploy.py
from servicefoundry import Job, NodeSelector, GPUType, Resources
job = Job(
resources=Resources(
# تكوين وحدة معالجة الرسوميات
gpu_count=1,
node=NodeSelector(gpu_type=GPUType.T4)
# (اختياري) تكوين موارد وحدة المعالجة المركزية والذاكرة
cpu_request=0.2,
cpu_limit=0.5,
memory_request=128,
memory_limit=512,
),
...
)
ملاحظة: يظل باقي الكود دون تغيير
حتى الآن، رأينا العديد من خيارات نشر المهام مثل صورة, معلمات، و البيئة. هناك عدة طرق لتخصيص مهمتك باستخدام خيارات متقدمة. بعضها كالتالي:
بعد أن ناقشنا المهام التي يمكن تشغيلها يدويًا إما عبر لوحة تحكم TrueFoundry أو حزمة تطوير Python (SDK). ولكن ماذا لو أردنا تشغيل مهمة بجدول زمني (مثل مهمة cron)؟
تقوم مهمة cron بتشغيل المهمة المحددة بجدول زمني متكرر. يمكن أن يكون هذا مفيدًا لإعادة تدريب نموذج بشكل دوري، وإنشاء تقارير، وغير ذلك. يمكننا تنفيذ مثل هذه المهام عن طريق تغيير نوع المشغل كالتالي:
from servicefoundry import Job, Schedule
job = Job(
trigger=Schedule(
schedule="0 8 1 * *",
concurrency_policy="Forbid" # القيم المحتملة: ["Forbid","Allow", "Replace"]
),
concurrency_limit=3,
...
)
بالنسبة لمهام cron، من الممكن ألا تكون الجولة السابقة للمهمة قد اكتملت بينما حان الوقت بالفعل لتشغيل المهمة مرة أخرى بسبب الوقت المجدول. في مثل هذه الحالات، يمكننا تحديد سياسة التزامن كما يلي:
منع: هذا هو الافتراضي. لا تسمح بتشغيلات متزامنة.السماح: السماح للمهام بالتشغيل بشكل متزامن. اختياريًا، يمكن تغيير الحد الأقصى لعدد المهام التي تعمل بشكل متزامن عن طريق تعيين concurrency_limit إلى القيمة المطلوبة. استبدال: استبدال المهمة الحالية بالمهمة الجديدة.التزامن لا ينطبق على المهام التي يتم تشغيلها يدويًا. في هذه الحالة، يتم دائمًا إنشاء تشغيل مهمة جديد.
يمكن أن تكون حالة المهمة من 3 أنواع وهي مكتملة، مُنهَاة، و فاشلة. يمكن تكوين المهمة لإعادة المحاولة عدة مرات عند الفشل.
يتم وضع علامة على المهمة كـ فاشلة إذا لم تكتمل بنجاح حتى بعد العدد المحدد من مرات إعادة المحاولة. مرات إعادة المحاولة يمكن تهيئتها لمهمة بهذا الشكل:
from servicefoundry import Job
job = Job(
retries=6, # الافتراضي = 1
...
)
في بعض حالات الاستخدام، قد تحتاج إلى تحديد أقصى مدة زمنية ترغب أن تستمر المهمة في التنفيذ خلالها.
باستخدام timeout، يمكنك تحديد (بالثواني) أقصى مدة زمنية لتشغيل المهمة، سواء فشلت أم لا. سيكون لهذا الأولوية على retries حد. افتراضيًا، يتم تعيين هذا على 1000 ثانية.
على سبيل المثال، إذا قمت بتعيين الـمحاولات إلى 6 و مهلة بمقدار 480 ثانية، ستتوقف المهمة بعد 480 ثانية بغض النظر عن عدد مرات محاولتها للتشغيل.
from servicefoundry import Job
job = Job(
timeout=480,
...
)
بالإضافة إلى خيارات نشر المهام التي نوقشت في هذه المدونة، توجد خيارات أخرى لن نتناولها هنا، مثل:
.... والمزيد. يمكنك الرجوع إلى الوثائق المذكورة أدناه لمعرفة إجابات الأسئلة المذكورة أعلاه :)
مستودعنا العام truefoundry-examples يحتوي على الكود المصدري لوظائف هذه المدونة ويتضمن أيضًا عدة أمثلة منها الضبط الدقيق لنماذج اللغة الكبيرة (LLM)، البدء باستخدام الدفاتر، أمثلة شاملة مما يوفر نظرة أوسع على الميزات التي تقدمها منصة TrueFoundry.
باختصار، توفر وظيفة TrueFoundry إطار عمل قويًا لإدارة وتنفيذ مهام التدريب بطريقة قابلة للتوسع، ومتحملة للأخطاء، وفعالة من حيث الموارد.
إنها تمكنك من توزيع والتحكم في تنفيذ أعباء عمل تعلم الآلة، ومراقبة تقدمها، وضمان تدريب نماذجك بفعالية وموثوقية، وهذا يجعلها مثالية لتنفيذ المهام لمرة واحدة أو عند الطلب.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








أحدث الأخبار والمقالات والموارد تصلك مباشرة إلى بريدك الوارد
© 2026 جميع الحقوق محفوظة.











.png)
.webp)










.webp)
