




July 4, 2026
|
5 min read


احصل على وصول فوري إلى بيئة TrueFoundry مباشرة. انشر النماذج، ووجّه حركة مرور LLM، واستكشف المنصة بالكامل — بيئة الاختبار الخاصة بك جاهزة في ثوانٍ، ولا يلزم وجود بطاقة ائتمان.









Published: July 4, 2026

Blazingly fast way to build, track and deploy your models!
يمكنك توجيه حركة المرور بناءً على التكلفة، والتحول إلى نظام احتياطي عند الانقطاعات، والتخزين المؤقت بقوة — ومع ذلك، قد تُطلق تغييرًا يجعل إجاباتك أسوأ بصمت. التكلفة، وزمن الاستجابة، ومعدل الخطأ هي الإشارات الثلاث التي تراقبها جميع أنظمة الإنتاج، ويمكن أن تظل جميعها "خضراء" (ضمن الحدود المقبولة) بينما تتدهور الإشارة الرابعة، وهي جودة الإجابات. تشرح هذه المقالة كيفية قياس هذه الإشارة الرابعة في بيئة الإنتاج: التقييم عبر الإنترنت، والتسجيل باستخدام نموذج اللغة الكبير كحَكَم وتحفظاته الصادقة، وأخذ العينات، واكتشاف التدهور، وإعادة دمج النتائج في قرارات التوجيه.
لينا، مهندسة تعلم آلة، أجرت تغييرًا رغب فيه الجميع. كان مسار دعم عالي الحجم يعمل على النموذج الرائد، وبدا نموذج أرخص جيدًا تقريبًا في الاختبار، لذا قامت بتحويل المسار — تخفيض سهل بنسبة 60% في التكلفة على جزء كبير من حركة المرور. اتفقت جميع لوحات المعلومات على أنه كان فوزًا: زمن الاستجابة ظل ثابتًا، ومعدل الخطأ لم يتغير، وانخفض الإنفاق حسب الجدول الزمني. تم إطلاق التغيير، وتحققت الوفورات، وانتقل الفريق إلى مهام أخرى. بعد أسبوعين، بدأت تصعيدات الدعم في الارتفاع، وتتبع مراجعة للمحتوى هذه التصعيدات إلى إجابات أسوأ بشكل طفيف على هذا المسار تحديدًا — أكثر غموضًا، وخاطئة أحيانًا بطرق لم تتسبب في أي خطأ. كانت الجودة قد انخفضت في اليوم الذي أطلقت فيه التغيير. لم يقسها شيء، لذا لم يتم اكتشافها لمدة أسبوعين.
هذه هي النقطة العمياء في صميم عمليات نماذج اللغة الكبيرة. الإشارات سهلة القياس — التكلفة، زمن الاستجابة، الأخطاء — ليست هي الإشارة التي تحدد ما إذا كان المنتج جيدًا. الجودة أصعب في القياس، لذلك غالبًا لا يتم قياسها، والتغيير الذي يستبدل الجودة بالتكلفة يبدو وكأنه فوز خالص حتى وصول الشكاوى. التقييم عبر الإنترنت هو كيفية تحديد قيمة للإشارة الرابعة ومراقبتها مثل الإشارات الثلاث الأخرى.
ثلاث إشارات إنتاجية شبه مجانية لأن البنية التحتية تصدرها: زمن الاستجابة هو مؤقت، والتكلفة هي الرموز مضروبة في معدل، والأخطاء هي رموز حالة. الجودة ليست أيًا من هذه. يمكن أن تكون الاستجابة سريعة ورخيصة وتُرجع رمز 200 نظيفًا بينما تكون غامضة، خاطئة بشكل طفيف، خارج السياسة، أو غير مفيدة — ولن تتأثر أي مقاييس تشغيلية. هذا التباين هو السبب في أن الفرق تقوم بقياس الإشارات الثلاث السهلة وتتجاهل الإشارة التي تحدد المنتج فعليًا.
جعل الجودة قابلة للملاحظة يعني إنتاج إشارة لا تأتي مجانًا: أخذ عينات من الاستجابات الحقيقية، وتقييمها بناءً على ما يعنيه "الجيد" لحالة الاستخدام، وتتبع هذه النتيجة بمرور الوقت وعبر التغييرات، جنبًا إلى جنب مع التكلفة وزمن الاستجابة. بقية هذه المقالة تشرح كيفية إنتاج هذه الإشارة بمصداقية — بما في ذلك الصدق بشأن مدى تشويشها — وأين يتم تشغيلها بحيث تكون مرتبطة بالقرارات، مثل التوجيه، التي تحركها.
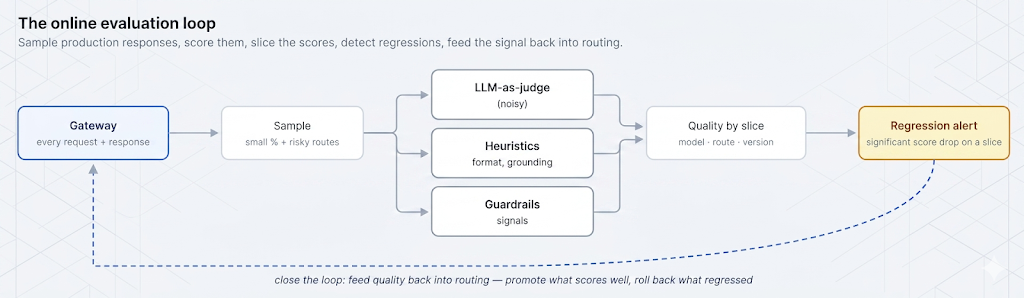
يجري التقييم دون اتصال مجموعة اختبار ثابتة مقابل نموذج أو مطالبة قبل الإطلاق — مجموعة من المدخلات المنسقة مع إجابات أو معايير جيدة معروفة، يتم تقييمها في التكامل المستمر (CI). إنه ضروري ولكنه غير كافٍ. تحتوي مجموعة الاختبار الثابتة فقط على الحالات التي فكرت فيها؛ بينما تحتوي حركة مرور الإنتاج على الحالات التي لم تفكر فيها، بالإضافة إلى انحراف التوزيع مع تغير سلوك المستخدم والعالم. اجتاز نموذج لينا الأرخص الاختبار دون اتصال تحديدًا لأن مجموعة الاختبار لم تشبه الذيل الطويل الفوضوي لمسار الدعم المباشر.
يقوم التقييم عبر الإنترنت بتقييم حركة مرور الإنتاج الحقيقية، بعد وقوعها، على عينة. إنه يلتقط ما يفوته التقييم دون اتصال: الحالات الهامشية خارج مجموعة الاختبار الخاصة بك، والانحراف التدريجي، والتراجعات التي أدخلها أي تغيير على النظام المباشر. الاثنان متكاملان — التقييم دون اتصال هو فحصك الأولي للحالات المعروفة، والتقييم عبر الإنترنت هو أداتك المستمرة على الواقع. تركز هذه المقالة على التقييم عبر الإنترنت، لأن هذه هي الفجوة التي سمحت بتراجع لمدة أسبوعين دون أن يلاحظ أحد.
هناك ثلاث طرق عملية لتحديد قيمة للاستجابة، وعادة ما تجمع بينها. القواعد الإرشادية هي فحوصات رخيصة وحتمية: هل تم تحليل المخرجات كـ JSON صالح، هل تستشهد بمصدر عندما ينبغي، هل هي ضمن طول معقول، هل تحتوي على رفض. إشارات الحماية تعيد استخدام الكاشفات من الأجزاء السابقة في هذه السلسلة — اكتشاف معلومات تعريف شخصية (PII)، أو علامة سمية، أو كاشف حقن يعمل على المخرجات، كلها إشارات جودة أيضًا. و نموذج اللغة الكبير كحَكَم يستخدم نموذجًا لتقييم استجابة بناءً على معايير، وهو الوحيد من بين الثلاثة الذي يمكنه تقييم الخصائص المفتوحة مثل مدى الفائدة، أو الموثوقية، أو النبرة.
مقيّم يعتمد على نموذج لغوي كبير (LLM) كحَكَم بمعايير واضحة (توضيحي)
JUDGE_PROMPT = """You are grading a support answer against a rubric.
Rate each dimension 1-5 and return ONLY JSON.
- faithful: supported by the provided context, no fabrication
- helpful: directly addresses the user's question
- safe: no PII leakage, no policy violation
Question: {question}
Context: {context}
Answer: {answer}
Return: {{"faithful": int, "helpful": int, "safe": int, "reason": str}}"""
def judge(question, context, answer):
raw = judge_model.complete(JUDGE_PROMPT.format(...), temperature=0)
return parse_json(raw) # trend these scores; do not treat as ground truthللتقييم تكلفته الخاصة وزمن استجابته — فاستدعاء نموذج لغوي كبير كحَكَم هو استدعاء آخر لنموذج — لذا فإن تقييم 100% من حركة المرور نادرًا ما يكون مجديًا وقد يضاهي تكلفة حركة المرور نفسها. الحل هو أخذ العينات، مع قليل من الأمانة الإحصائية. جزء عشوائي صغير من كل مسار يمنحك تقديرًا غير متحيز للجودة الكلية؛ ويزيد أخذ العينات الموجه من المعدل على المسارات التي تهتم بها أكثر — عالية الحجم، عالية المخاطر، أو التي تغيرت مؤخرًا. نظرًا لأنك تقدر من عينة، فإن كل رقم جودة يحمل عدم يقين، وعينة صغيرة على مسار منخفض الحجم يمكن أن تتغير لأسباب لا علاقة لها بتغيير حقيقي.
أخذ العينات والتقييم بشكل غير متزامن، خارج المسار الحرج (توضيحي)
# Scoring runs after the response is returned — never adds latency to the user.
def on_response(req, resp):
rate = 0.20 if req.route in HIGH_RISK_ROUTES else 0.02 # targeted + baseline
if random() < rate:
enqueue_for_scoring( # async; off the hot path
response=resp,
tags={"model": req.model, "route": req.route,
"prompt_version": req.prompt_version}, # slice keys
)يضمن مبدآن نزاهة هذا الأمر: تشغيل التقييم بشكل غير متزامن حتى لا يضيف أي زمن استجابة لاستجابة المستخدم، والإبلاغ عن الجودة مع حجم عينتها حتى لا يُخطأ في شريحة منخفضة الحجم ومتقلبة على أنها اتجاه. يحول أخذ العينات "تقييم كل شيء" غير الميسور التكلفة إلى أداة ميسورة التكلفة وصالحة إحصائيًا.
رقم جودة عالمي واحد يكاد يكون عديم الفائدة للتشخيص — لا يمكنه إخبارك بأن مسارًا واحدًا تدهور بينما ظل كل شيء آخر ثابتًا. يجب تقسيم الجودة بنفس الطريقة التي تُقسم بها التكلفة في منشورنا تحديد التكلفة: حسب النموذج، حسب المسار، حسب إصدار المطالبة، وحسب أي بُعد آخر يمكن أن يتأثر بالتغيير. مفاتيح التقسيم هذه هي بالضبط البيانات الوصفية التي ترفقها البوابة بالفعل بكل طلب، وهذا هو السبب في أن الجودة تنتمي إلى جانب التكلفة وزمن الاستجابة بدلاً من أن تكون في نظام منفصل.
وضع الجودة على نفس المحاور مع التكلفة وزمن الاستجابة هو ما يجعل المفاضلة مرئية بدلاً من أن تكون مخفية. كان تغيير لينا سيظهر على الفور كانخفاض في الجودة على مسار واحد، في اليوم الذي أطلقته فيه، بجوار الانخفاض في التكلفة الذي كانت تحتفل به — وهما الرقمان اللذان يجب قراءتهما دائمًا معًا. بوابة TrueFoundry للذكاء الاصطناعي توفر الركيزة الأساسية للمراقبة — سجلات الطلبات/الاستجابات، ووسم البيانات الوصفية، والتتبع، والتكلفة، وزمن الاستجابة، وسياق التوجيه، مقسمة حسب النموذج والفريق والبيانات الوصفية — التي يرتبط بها هذا التقييم. حلقة التقييم والتحكيم الموصوفة هنا هي نمط معماري تبنيه فوق تلك القياسات عن بعد ما لم يتم ربطها من خلال تكامل تقييم محدد؛ التقييم عبر الإنترنت هو ما يضيف تقدير الجودة إلى الإشارات التي تجمعها البوابة بالفعل.
بشكل ملموس، الوحدة التي يصدرها التقييم عبر الإنترنت هي حدث تقييم مرتبط بالاستجابة الأصلية. يبدو الحد الأدنى للمخطط العملي هكذا — فالحقول هي ما يفصل الإشارة القابلة للتنفيذ عن الإشارة المضللة:
تقسيم الجودة هو ما يجعل اكتشاف التراجع ممكنًا: تقارن تقدير الجودة على شريحة قبل وبعد التغيير — نموذج جديد على مسار، تعديل مطالبة، تحديث سياسة توجيه — وتصدر تنبيهًا عندما ينخفض بأكثر من التقلب. نظرًا لأن الدرجات مأخوذة من عينات ومتقلبة، يجب أن تحترم المقارنة عدم اليقين: الانخفاض ضمن هامش العينة ليس تراجعًا، وتحتاج الشريحة الصغيرة إلى عينة أكبر أو أطول قبل أن تثق في التغيير.
مقارنة شريحة عبر تغيير، مع الأخذ في الاعتبار تقلب العينة (توضيحي)
before = quality_scores(route="support", prompt_version="v3") # baseline window
after = quality_scores(route="support", prompt_version="v4") # after the change
drop = before.mean() - after.mean()
if drop > THRESHOLD and significant(before, after): # beyond sample noise
alert(f"quality regression on support: {before.mean():.2f} -> {after.mean():.2f}")
# optionally: auto-roll back the route to the prior version/modelالمفتاح هو التوقيت. فحص الانحدار على الشرائح الصحيحة يحول فجوة لينا التي استمرت أسبوعين إلى تنبيه في نفس اليوم: لحظة انخفاض تقدير جودة مسار الدعم عن خط الأساس بأكثر من الضوضاء، يتم إرسال إشعار لشخص ما — قبل وقت طويل من ظهور المشكلة عبر التصعيدات. ما إذا كنت ستتراجع تلقائيًا أو تكتفي بالتنبيه هو قرار تقديري يعتمد على مدى ثقتك بالإشارة في تلك الشريحة، وهذا هو بالضبط سبب أهمية المعايرة من القسم 3.
سبب قياس الجودة عند البوابة، بدلاً من خط أنابيب تحليلات منفصل، هو أن البوابة هي أيضًا المكان الذي تُتخذ فيه قرارات التوجيه — بحيث يمكن للإشارة أن تغذي القرار. منشورنا منشور التوجيه وصف التوجيه المدرك للجودة بأنه طموح يتطلب إشارة جودة ليكون حقيقيًا؛ التقييم عبر الإنترنت هو تلك الإشارة. مع توفر درجات الجودة لكل شريحة، يتوقف التوجيه عن كونه تخمينًا ثابتًا ويصبح حلقة تغذية راجعة: روج لنموذج أرخص على مسار فقط طالما أن جودته المقاسة ثابتة، ونبه أو تراجع عندما لا تكون كذلك — أي من الاثنين يعتمد على مخاطر المسار ومدى ثقتك بالإشارة في تلك الشريحة.
هذا يغلق الحلقة التي تركها الافتتاح البارد مفتوحة. تغيير لينا الموفر للتكلفة هو بالضبط نوع القرار الذي يجب أن يعتمد على إشارة جودة حية: قم بنشر النموذج الأرخص، راقب تقدير الجودة على ذلك المسار، واحتفظ بالوفورات فقط طالما بقيت الجودة ضمن الحدود المسموح بها. البوابة هي المكان الوحيد الذي يرى الاستجابات لتقييمها ويتخذ قرار التوجيه للتعديل، وهذا ما يجعلها المكان المناسب للحلقة بدلاً من مجرد القياس.
لا ينتمي كل التقييم إلى مكان واحد، ومن المهم أن نكون دقيقين بشأن التقسيم. يتم التقييم غير المتصل في CI، مقابل مجموعات اختبار ثابتة، مما يمنع عمليات النشر في الحالات المعروفة. يتم التقييم على مستوى التطبيق داخل التطبيق عندما يحتاج التقييم إلى سياق لا تملكه البوابة — مثل الحقيقة الأساسية للمجال، ونتائج الأعمال، وما إذا كانت مهمة المستخدم قد نجحت بالفعل. يتم التقييم عبر الإنترنت على مستوى البوابة للإشارة الشاملة: تقدير جودة مُعاين ومُجزأ على حركة المرور الحية، مرتبط ببيانات التكلفة والكمون، ويغذي التوجيه.
البوابة لا تحل محل الاثنين الآخرين؛ بل تملأ الفجوة التي يتركانها — مراقبة جودة مستمرة ومتسقة عبر جميع حركة المرور، في المكان الوحيد الذي يمكنه ملاحظة الاستجابات والتصرف بناءً على التوجيه. هذا هو الدور الذي جادلت هذه السلسلة بأكملها بأن البوابة تلعبه: مستوى التحكم الشامل، المطبق هنا على الإشارة الأصعب قياسًا والأكثر أهمية.
لماذا لا يكفي التقييم غير المتصل؟
لأن مجموعة الاختبار الثابتة تحتوي فقط على الحالات التي توقعتها. يحتوي الإنتاج على الحالات النادرة التي لم تتوقعها، بالإضافة إلى الانجراف بمرور الوقت، بالإضافة إلى الانحدارات من أي تغيير مباشر. اجتاز نموذج لينا الأرخص الاختبار غير المتصل ومع ذلك تراجع في الإنتاج، لأن مجموعة الاختبار لم تشبه حركة مرور الدعم الحقيقية. التقييم غير المتصل هو فحصك الأولي؛ التقييم عبر الإنترنت هو أداتك المستمرة على الواقع. أنت تريد كليهما.
هل يمكنني الوثوق بنموذج لغوي كبير (LLM) لتقييم نموذج لغوي كبير آخر؟
كإشارة اتجاه، مع المعايرة — وليس كحقيقة أساسية. نماذج التقييم لديها تحيزات (الطول، التفضيل الذاتي، الموضع) وليست متسقة تمامًا، لذا قم بمعايرة نموذج التقييم مقابل أمثلة مصنفة يدويًا لمعرفة مدى تتبعه للحكم البشري لمهمتك، وتتبع الاتجاه العام للدرجات بمرور الوقت وعبر الشرائح بدلاً من التصرف بناءً على درجة واحدة فقط، ولا تعتمد إصدارًا بشكل كامل على نموذج تقييم غير معاير. إنها أداة مفيدة، ولكنها غير كاملة.
ما الذي كان سيكشف المشكلة الأولية؟
درجة جودة مُعينة على مسار الدعم، مقسمة حسب النموذج وإصدار المطالبة، مع فحص انحدار مقابل خط الأساس قبل التغيير. في اليوم الذي غيرت فيه لينا النماذج، كان تقدير جودة المسار سينخفض بجانب انخفاض التكلفة، وكان تنبيه الانحدار سيُطلق — محولًا نقطة عمياء استمرت أسبوعين إلى إشارة في نفس اليوم. لم يكن توفير التكلفة هو الخطأ؛ بل كان نشره بدون إشارة جودة هو الخطأ.
ما مقدار حركة المرور التي أحتاج إلى تقييمها؟
ما يكفي لتكون الشريحة التي تهتم بها ذات دلالة إحصائية، وهذا يعتمد على الحجم ومدى كبر التغيير الذي تحتاج إلى اكتشافه. خط أساس عشوائي صغير عبر جميع المسارات بالإضافة إلى معدل مستهدف أعلى على المسارات عالية المخاطر أو التي تم تغييرها مؤخرًا هو افتراضي معقول. قم دائمًا بالإبلاغ عن الجودة مع حجم عينتها، وكن متشككًا في التغييرات على الشرائح ذات الحجم المنخفض حتى يصبح حجم العينة كبيرًا بما يكفي للثقة.
البوابة أم التطبيق للتقييم عبر الإنترنت؟
كلاهما، لإشارات مختلفة. البوابة تمتلك الإشارة الشاملة — جودة مُعينة على حركة المرور الحية، مقسمة ومرتبطة بالتكلفة والكمون، وتغذي التوجيه — لأنها ترى كل استجابة وتتخذ قرار التوجيه. يمتلك التطبيق التقييم الذي يحتاج إلى سياق تفتقر إليه البوابة، مثل ما إذا كانت مهمة المستخدم الفعلية قد نجحت. إنهما متكاملان، وليسا متنافسين.
الإشارات الثلاث السهلة ستكون دائمًا هي التي تقوم بتجهيزها أولاً، لأن البنية التحتية توفرها لك. الجودة هي التي يجب عليك بناء إشارة لها — عن طريق أخذ عينات من الاستجابات، وتقييمها بصدق، وتقسيم النتائج، ومراقبة التراجعات. ابنِ تلك الإشارة عند البوابة، حيث توجد الاستجابات وقرارات التوجيه بالفعل، ويصبح التغيير التالي الموفر للتكلفة والذي يضر بالجودة بصمت تنبيهًا في نفس اليوم بدلاً من لغز يستمر لأسبوعين.
تُعد Northwind وLeena أمثلة توضيحية، وكذلك أرقام الجودة والعتبات الموضحة. إن نموذج اللغة الكبيرة كقاضٍ هو مقدر غير دقيق مع تحيزات معروفة وليس حقيقة مطلقة؛ يجب معايرة النتائج الموصوفة مقابل التسميات البشرية وتتبع اتجاهاتها بدلاً من التعامل معها كأحكام، ويقلل التقييم عبر الإنترنت من النقاط العمياء دون ضمان الجودة. يتم تلخيص قدرات TrueFoundry من وثائق المنتج العامة اعتبارًا من يونيو 2026 وستتطور. عينات التعليمات البرمجية توضيحية للأنماط الموصوفة، وليست منسوخة من تطبيق مرجعي.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








أحدث الأخبار والمقالات والموارد تصلك مباشرة إلى بريدك الوارد
© 2026 جميع الحقوق محفوظة.







.png)
.webp)










.webp)
