




July 4, 2026
|
5 min read


احصل على وصول فوري إلى بيئة TrueFoundry مباشرة. انشر النماذج، ووجّه حركة مرور LLM، واستكشف المنصة بالكامل — بيئة الاختبار الخاصة بك جاهزة في ثوانٍ، ولا يلزم وجود بطاقة ائتمان.









Published: July 4, 2026

Blazingly fast way to build, track and deploy your models!
تجاوزت نماذج اللغة الكبيرة (LLMs) مجرد كونها روبوتات دردشة تجريبية وعروضًا توضيحية عامة؛ فقد أصبحت الآن تدعم سير العمليات الحيوية داخل المؤسسات. من أتمتة البحث عن المعرفة الداخلية إلى إنشاء التقارير، وتعزيز دعم العملاء، وضمان الامتثال، تعيد نماذج LLM تشكيل طريقة عمل الشركات الحديثة. لكن نشر نماذج LLM في بيئات المؤسسات ليس بالبساطة التي يتصورها البعض عند ربطها بواجهة برمجة تطبيقات (API). فهو يتطلب حوكمة، وقابلية للمراقبة، وضمانات للخصوصية، وبنية تحتية مصممة خصيصًا. يستكشف هذا الدليل المشهد المتطور لـ LLMs المؤسسية، ويغطي التحديات الرئيسية، ونماذج النشر، وأفضل ممارسات المراقبة، وكيف تمكّن المنصات مثل TrueFoundry التبني الآمن والقابل للتطوير لـ LLMs عبر مختلف الصناعات.
أثارت الضجة حول نماذج LLM موجة من التبني، لكن بالنسبة للمؤسسات، التحدي الحقيقي ليس في توليد استجابات مبهرة. بل في نشر هذه النماذج بذكاء ومسؤولية. نموذج LLM المؤسسي الحقيقي ليس مجرد ChatGPT بغلاف تجاري. إنه نظام يستند إلى بياناتك الخاصة، ومُحسّن لسير عملك، ويتم نشره مع مراعاة متطلبات الامتثال والتكلفة والتحكم الخاصة بك.
تُدرّب معظم نماذج LLM العامة على بيانات الإنترنت المفتوحة. وهذا يجعلها قوية في الاستدلال اللغوي العام، لكنها غير موثوقة عند تطبيقها على سياقات خاصة بالشركة، خاصة حيث تكون الدقة والتتبع والأمان أمورًا حاسمة. على سبيل المثال، لا يمكن لشركة خدمات مالية أن تتحمل حقائق مختلقة، أو إخلاء مسؤولية غامض، أو استجابات غير متوقعة. ما يحتاجونه هو نموذج يدرك المجال، وقابل للتدقيق، ويمكن نشره خلف جدران الحماية. غالبًا ما يُقترن هذا بتقنية التوليد المعزز بالاسترجاع (RAG) حتى يتمكن من الاستدلال على المستندات الداخلية، وليس فقط ما تم تدريبه عليه مسبقًا.
تتطور نماذج LLM المؤسسية لتصبح مساعدين داخليين. تستخدمها الفرق القانونية لصياغة العقود، وفرق الموارد البشرية للإجابة على استفسارات الموظفين، والمطورون لتسريع كتابة الأكواد، وفرق الدعم لتلخيص وحل المشكلات بشكل أسرع. لكن هذه النتائج لا يمكن تحقيقها إلا إذا كانت نماذج LLM مدمجة جيدًا، وتتم مراقبتها في بيئة الإنتاج، ومتوافقة مع حدود بيانات المؤسسة.
يشير هذا التحول أيضًا إلى تطور فلسفي. نحن ننتقل من التعامل مع نماذج LLM كصناديق سوداء سحرية إلى اعتبارها أنظمة ذكاء اصطناعي معيارية، حيث يكتسب التنسيق، والتأسيس، وقابلية المراقبة، وحلقات التغذية الراجعة أهمية لا تقل عن أهمية النموذج الأساسي نفسه.
التطبيق الناجح لـ نماذج LLM في المؤسسات لا يقتصر على قدرة الذكاء الاصطناعي. بل يتعلق بالرافعة التجارية. وهذا يتطلب التفكير أبعد بكثير من النموذج إلى البنية، والبنية التحتية، والثقة التنظيمية التي يعتمد عليها.
بينما الإمكانات الكامنة في نماذج LLM المؤسسية هائلة، فإن نشرها في بيئة عمل حقيقية يأتي مع تحديات حرجة يجب على المؤسسات معالجتها منذ اليوم الأول.
خصوصية البيانات وأمنها: غالبًا ما تعمل نماذج LLM المؤسسية على بيانات داخلية حساسة، مثل العقود، وسجلات العملاء، والتعليمات البرمجية المصدرية، والبيانات المالية. وهذا يثير مخاوف جدية بشأن تسرب البيانات، والوصول غير المصرح به، وعدم الامتثال التنظيمي. بدون ضوابط وصول صارمة، وتشفير، وتنقية للمدخلات (prompts)، يمكن لمخرجات نماذج LLM أن تكشف عن معلومات سرية عن غير قصد.
الهلوسة والموثوقية: تميل نماذج LLM إلى توليد إجابات واثقة ولكنها غير صحيحة، وهو ما يُعرف بالهلوسة. في بيئة المؤسسات، يمكن أن يؤدي ذلك إلى أخطاء تشغيلية، ومخاطر قانونية، وفقدان الثقة. وهذا يجعل ترسيخ النموذج في المستندات الداخلية عبر مسارات RAG أمرًا ضروريًا لضمان الدقة الواقعية.
حقن الأوامر والمدخلات العدائية: يجب على المؤسسات الحماية من الأوامر الخبيثة أو التلاعبية التي تتجاوز المرشحات أو تستخرج بيانات غير مقصودة. بدون التحقق المناسب من المدخلات والضوابط الوقائية، قد تصبح النماذج وسيلة للهندسة الاجتماعية أو تسرب البيانات.
التكلفة والنفقات العامة للبنية التحتية: يتكبد تشغيل النماذج الكبيرة على وحدات معالجة الرسوميات (GPUs) على نطاق واسع تكاليف استدلال عالية. وهنا تبرز أهمية استراتيجية استدلال نماذج اللغة الكبيرة (LLM) ، لأن حجم النموذج، والتجميع (batching)، واختيارات الأجهزة تحدد بشكل مباشر زمن الاستجابة وكفاءة التكلفة للمؤسسة. تحتاج المؤسسات إلى إدارة زمن الاستجابة، والإنتاجية، والتوسع مع الحفاظ على نفقات السحابة تحت السيطرة. ويعد اختيار حجم النموذج المناسب وتحسين التجميع والتخزين المؤقت (caching) والتكميم (quantization) أمرًا بالغ الأهمية.
المراقبة والتحكم في الإصدارات: على عكس البرامج التقليدية، يمكن أن يتغير سلوك نماذج اللغة الكبيرة (LLM) بشكل طفيف بمرور الوقت. تحتاج المؤسسات إلى أدوات لتتبع المطالبات (prompts)، والمخرجات، وجودة الاستجابة، واتجاهات الاستخدام. يمكن أن يؤدي نقص المراقبة إلى سوء استخدام النموذج، أو ضعف الأداء، أو عدم الوفاء باتفاقيات مستوى الخدمة (SLAs).
تعقيد التقييم: تقييم نماذج اللغة الكبيرة (LLMs) ليس بالأمر الهين. يتطلب ذلك معايير مخصصة، وحلقات تغذية راجعة، ومقاييس خاصة بالمهام مثل الصلة، والاتساق، والدقة الواقعية.
يتطلب كل من هذه التحديات نهجًا منظمًا للتخفيف من المخاطر وتمكين التوسع. بدون ذلك، تظل مبادرات نماذج اللغة الكبيرة عالقة في وضع النموذج الأولي، ولا تصل أبدًا إلى النضج المؤسسي الحقيقي.
تتجاوز المؤسسات في مختلف الصناعات مرحلة التجريب وتبدأ في نشر نماذج اللغة الكبيرة (LLMs) في بيئات الإنتاج. تركز عمليات النشر هذه على حالات الاستخدام الداخلية عالية التأثير التي يمكن أن تحقق عائدًا استثماريًا قابلاً للقياس مع تقليل المخاطر.
استرجاع المعرفة والبحث الداخلي
أحد أكثر التطبيقات شيوعًا هو البحث المؤسسي. من خلال الجمع بين نماذج اللغة الكبيرة (LLMs) وأنظمة الاسترجاع مثل قواعد بيانات المتجهات، تمكّن الشركات الموظفين من الاستعلام عن الوثائق الداخلية باستخدام اللغة الطبيعية. وهذا يحسن الوصول إلى المعرفة لفرق الموارد البشرية، والشؤون القانونية، والامتثال، وتكنولوجيا المعلومات.
أتمتة دعم العملاء
تقوم المؤسسات بدمج نماذج اللغة الكبيرة (LLMs) في سير عمل دعم العملاء. تساعد النماذج في تلخيص التذاكر، وإنشاء رسائل البريد الإلكتروني، وتوجيه النوايا. عند إقرانها ببيانات الدعم التاريخية، يمكن لنماذج اللغة الكبيرة أن تقلل بشكل كبير من أوقات الاستجابة وتحسن رضا العملاء.
تلخيص وتصنيف المستندات
تُستخدم نماذج اللغة الكبيرة (LLMs) لتحليل وتلخيص التقارير الطويلة أو العقود أو النصوص. تستفيد المؤسسات في القطاعات القانونية والمالية والرعاية الصحية من المعالجة الآلية للمستندات، مما يقلل من وقت المراجعة اليدوية ويسرع عملية اتخاذ القرار.
إنتاجية المطورين
تنشر الفرق التقنية نماذج لغة كبيرة (LLMs) تركز على التعليمات البرمجية لتسريع تطوير البرمجيات. تقترح المساعدات البرمجية الداخلية (copilots) مقتطفات التعليمات البرمجية، وتحدد الأخطاء، وتنشئ وثائق بناءً على المستودعات الداخلية. وهذا يعزز سرعة الهندسة دون المساس بالأمان.
المساعدات المتخصصة حسب المجال
تقوم بعض المؤسسات ببناء مساعدات قائمة على نماذج اللغة الكبيرة (LLMs) ومصممة خصيصًا لسير عمل محددة. على سبيل المثال، تستخدم شركات التأمين نماذج مدربة على بيانات المطالبات للإشارة إلى الحالات الشاذة أو ملء النماذج مسبقًا. تستخدم شركات الاستشارات نماذج اللغة الكبيرة لإعداد ملخصات بحثية تستند إلى قواعد بياناتها الخاصة.
تشمل الأمثلة الواقعية استخدام VMware الداخلي لـ StarCoder في الهندسة، ومساحة عمل LLM للمؤسسات التابعة للجيش الأمريكي للوصول إلى الوثائق، ومنصة Glean للبحث المؤسسي المدعومة بالذكاء الاصطناعي.
ما يجمع عمليات النشر الناجحة ليس النموذج فحسب، بل التكامل مع البيانات والأدوات وممارسات الحوكمة الداخلية. هذه ليست حلولاً جاهزة. إنها أنظمة مخصصة مصممة خصيصًا لتحقيق تأثير مؤسسي.
أحد أهم القرارات المعمارية لأي مبادرة لنماذج اللغة الكبيرة (LLM) في المؤسسات هو مكان نشر النموذج. يقدم كل من النشر المحلي والسحابي مزايا مميزة، اعتمادًا على أولويات المنظمة وقيودها وبيئتها التنظيمية.
النشر المحلي
غالبًا ما تختار المؤسسات ذات الحوكمة الصارمة للبيانات، مثل تلك العاملة في قطاعات الرعاية الصحية أو المالية أو الحكومية، عمليات النشر المحلية. تضمن هذه العمليات التحكم الكامل في البيانات الحساسة، مما يتيح الامتثال للسياسات الداخلية واللوائح الخارجية. كما تقلل الإعدادات المحلية الاعتماد على البنية التحتية للجهات الخارجية وتسمح بضبط الأداء على مستوى الأجهزة. ومع ذلك، تتطلب استثمارًا كبيرًا في وحدات معالجة الرسوميات (GPUs) وخبرة DevOps وصيانة مستمرة. تصبح تحديثات النماذج وتصحيح الأخطاء والتوسع مسؤوليات داخلية، مما قد يبطئ الابتكار إذا لم تتوفر الموارد الكافية.
النشر السحابي
نماذج اللغة الكبيرة (LLMs) المستندة إلى السحابة أسرع في التبني وأسهل في التوسع. يقدم مزودون مثل OpenAI وAWS Bedrock وGoogle Cloud وAzure واجهات برمجة تطبيقات مُدارة (APIs) مع وصول فوري إلى أحدث النماذج. تقلل هذه الخدمات العبء التشغيلي وتسرع وقت تحقيق القيمة، خاصة خلال التجارب الأولية. لكنها تأتي مع مخاوف تتعلق بخصوصية البيانات، والارتباط بمزود معين، والتكاليف المتكررة. بالنسبة للعديد من المؤسسات، يعد إرسال البيانات الخاصة إلى نقاط نهاية خارجية أمرًا غير مقبول ما لم يتم فرض تشفير صارم وإخفاء هوية وسياسات وصول.
الحلول الهجينة وحلول الشبكة الافتراضية الخاصة (VPC)
يتجه الاتجاه المتزايد نحو النشر الهجين، حيث يتم تشغيل الاستدلال في بيئة سحابة خاصة افتراضية (VPC). يوازن هذا بين مرونة السحابة وأمان البنية التحتية المعزولة. تدعم منصات مثل TrueFoundry وHugging Face الاستضافة الخاصة للنماذج مفتوحة المصدر ضمن بيئات تتحكم فيها المؤسسات، مما يوفر أفضل ما في العالمين.
اختيار نموذج النشر الصحيح ليس مجرد قرار تقني. إنه يؤثر بشكل مباشر على الامتثال والأداء والتكاليف طويلة الأجل. يجب على المؤسسات تقييم حالات استخدامها، وتحمل المخاطر، ونضج البنية التحتية قبل الالتزام بمسار معين.
تختلف مراقبة نماذج اللغة الكبيرة (LLMs) في بيئات المؤسسات اختلافًا جوهريًا عن مراقبة نماذج التعلم الآلي التقليدية. نماذج اللغة الكبيرة احتمالية، وغير حتمية، وحساسة للغاية للسياق. بدون إمكانية ملاحظة مناسبة، يمكن أن ينحرف سلوكها بصمت، أو تولد مخرجات غير صحيحة، أو تُدخل مخاطر، دون أي إشارة إلى فشل في النظام.
تتبع المطالبات وتحديد الإصدارات: يجب على المؤسسات تتبع كل تفاعل بين المستخدمين ونموذج اللغة الكبيرة (LLM)، بما في ذلك بنية المطالبة الدقيقة، ورسالة النظام، ونافذة السياق. تبدأ إمكانية الملاحظة بالتتبع الكامل. يسمح تسجيل قوالب المطالبات، وإصدارات النماذج، وإعدادات درجة الحرارة، وأزواج المدخلات والمخرجات للفرق بإعادة إنتاج النتائج وتحليلها لاحقًا.
تقييم المخرجات والأساس المنطقي: تعد مراقبة الدقة الواقعية ومدى ملاءمة استجابات نماذج اللغة الكبيرة (LLM) أمرًا بالغ الأهمية. يجب على المؤسسات تطبيق فحوصات تلقائية للهلوسات، مثل التحقق من صحة المخرجات مقابل المستندات الداخلية المعروفة أو فرض الاستشهاد بالمصادر باستخدام مسارات RAG. يضيف تقييم المخرجات باستخدام معايير تسجيل مثل الفائدة والصحة والاكتمال هيكلاً للمراقبة.
زمن الاستجابة واستخدام الرموز (Tokens): بينما يتم التعامل مع مقاييس البنية التحتية في مكان آخر، تتضمن إمكانية الملاحظة على مستوى نماذج اللغة الكبيرة (LLM) تتبع حجم إدخال الرموز، وطول المخرجات، وإجمالي استهلاك الرموز. تؤثر هذه المقاييس بشكل مباشر على وقت الاستجابة والتكلفة. قد تشير الزيادات المفاجئة في الرموز إلى مشكلات في هندسة المطالبات أو سوء استخدام.
اكتشاف المخرجات الضارة أو غير الآمنة: قد تولد نماذج اللغة الكبيرة (LLMs) لغة متحيزة أو مسيئة أو غير متوافقة إذا فشلت الضوابط الوقائية. يجب على الشركات مراقبة المخرجات بحثًا عن المصطلحات الحساسة أو انتهاكات النبرة أو تسرب البيانات باستخدام مطابقات الأنماط أو المصنفات. يمكن لاختبار الفرق الحمراء والاختبار العدائي الكشف عن النقاط العمياء.
دمج حلقة التغذية الراجعة: ملاحظات المستخدمين حاسمة. يجب على الشركات التقاط التصحيحات، وإشارات عدم الرضا، والتقييمات. تُستخدم هذه الإشارات في تحسين المطالبات، وتحديثات RAG، وضبط النماذج.
بدون قابلية مراقبة مستهدفة، تتصرف نماذج اللغة الكبيرة كصناديق سوداء. ومع المراقبة المناسبة، تصبح أنظمة شفافة يمكن للشركات الوثوق بها وتدقيقها وتحسينها باستمرار.
صُممت TrueFoundry خصيصًا لمساعدة الشركات على نشر تطبيقات نماذج اللغة الكبيرة وإدارتها وتوسيع نطاقها بالتحكم والأمان والأداء الذي تتطلبه بيئات الإنتاج. على عكس منصات الذكاء الاصطناعي العامة، تركز TrueFoundry على بنية تحتية للذكاء الاصطناعي معيارية وجاهزة للإنتاج تتناسب مع بيئة المؤسسة السحابية أو المحلية أو الهجينة.
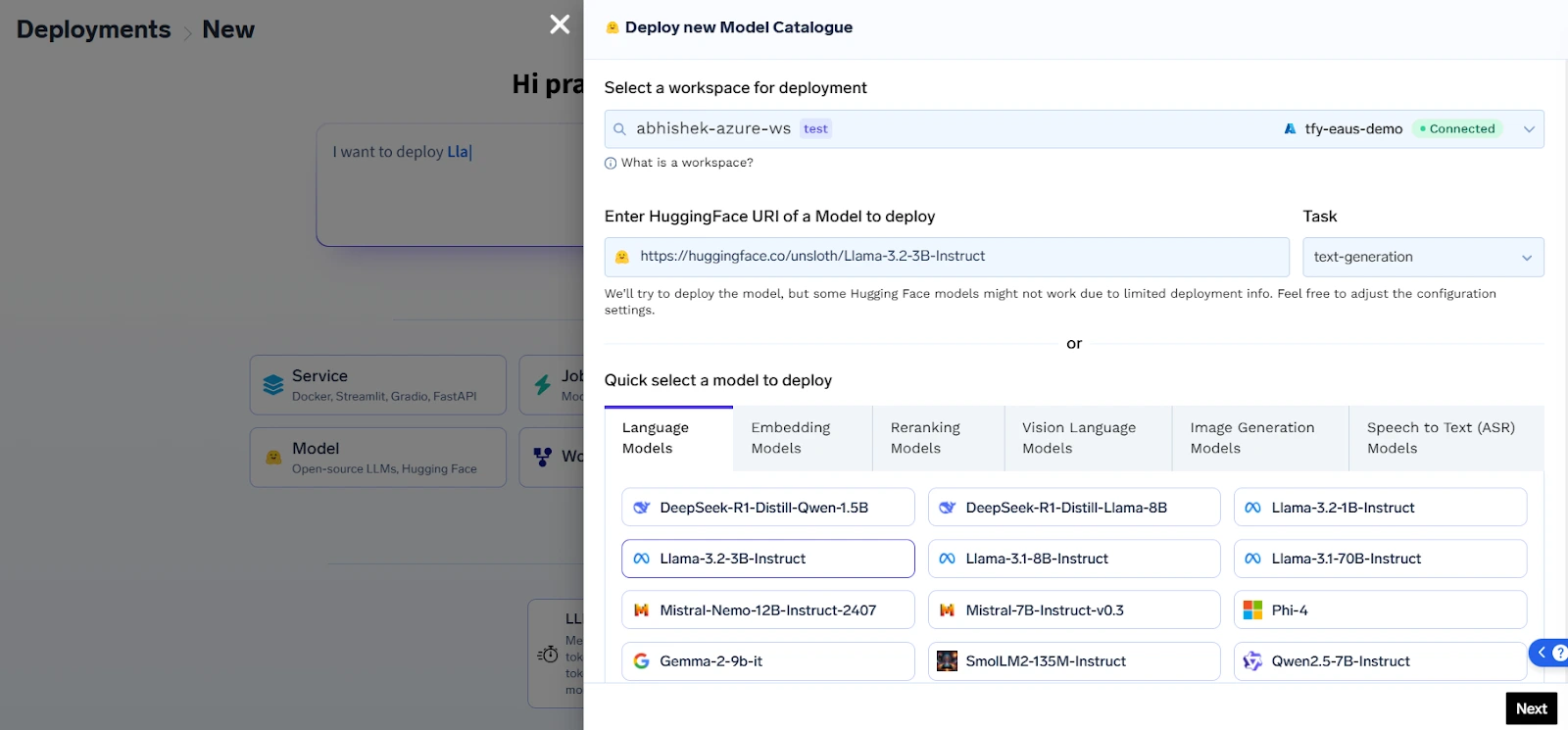
في صميم ما تقدمه، توجد طبقة بنية تحتية للذكاء الاصطناعي متوافقة مع Kubernetes تمكن الفرق من نشر نماذج اللغة الكبيرة المملوكة والمفتوحة المصدر مثل LLaMA وMistral وFalcon وGPT-J مع تحكم كامل في الاستضافة والشبكات والأمان. يضمن هذا بقاء بيانات المؤسسة الحساسة ضمن حدود المنظمة، سواء تم نشرها في سحابة خاصة أو مركز بيانات محلي.
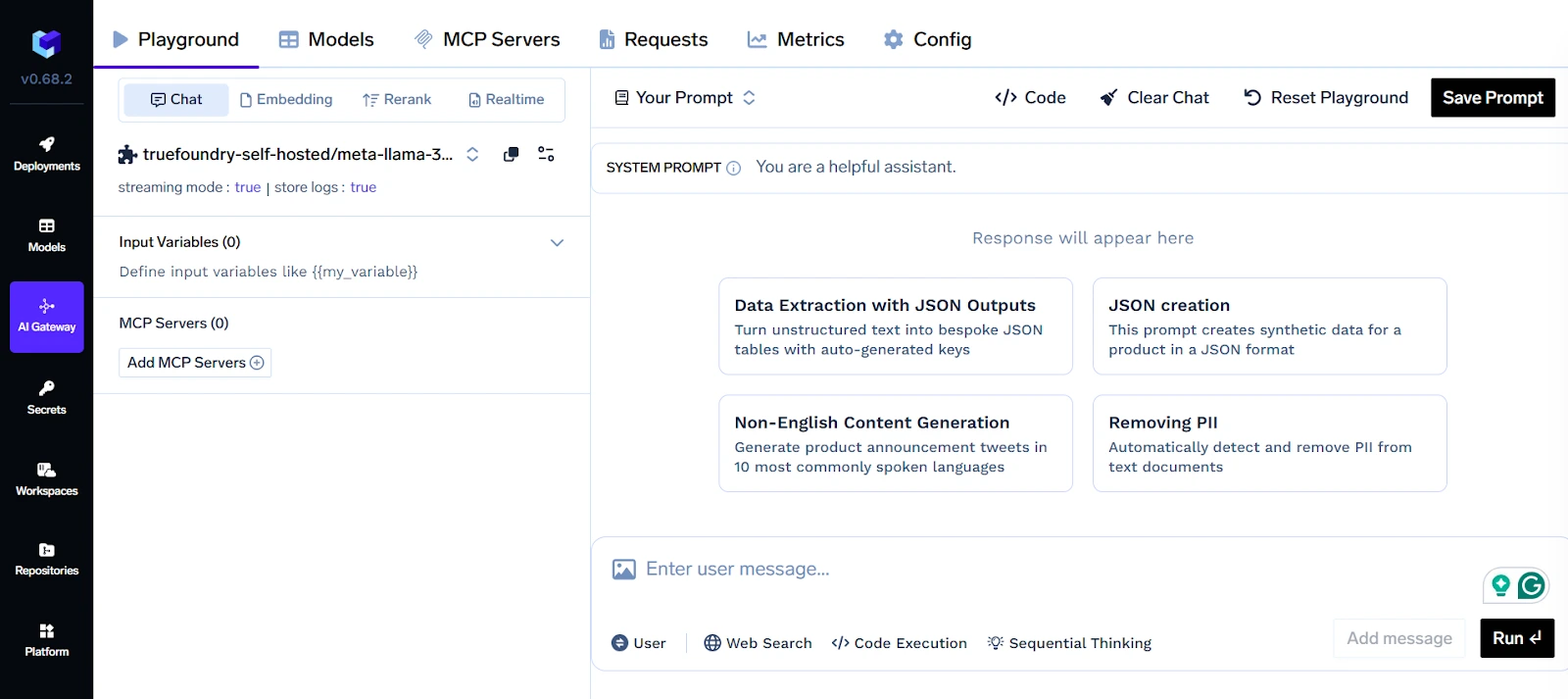
بالنسبة للمؤسسات التي تستخدم عدة مزودي نماذج لغة كبيرة (مثل OpenAI، Anthropic، Cohere)، تقدم TrueFoundry بوابة موحدة لـ LLM. تتيح طبقة التجريد هذه للفرق التبديل بين المزودين أو توجيه حركة المرور بذكاء بناءً على التكلفة أو زمن الاستجابة أو احتياجات الامتثال. كما تدعم استراتيجيات التراجع والنماذج المتعددة، وهي ضرورية للموثوقية في بيئات الإنتاج.
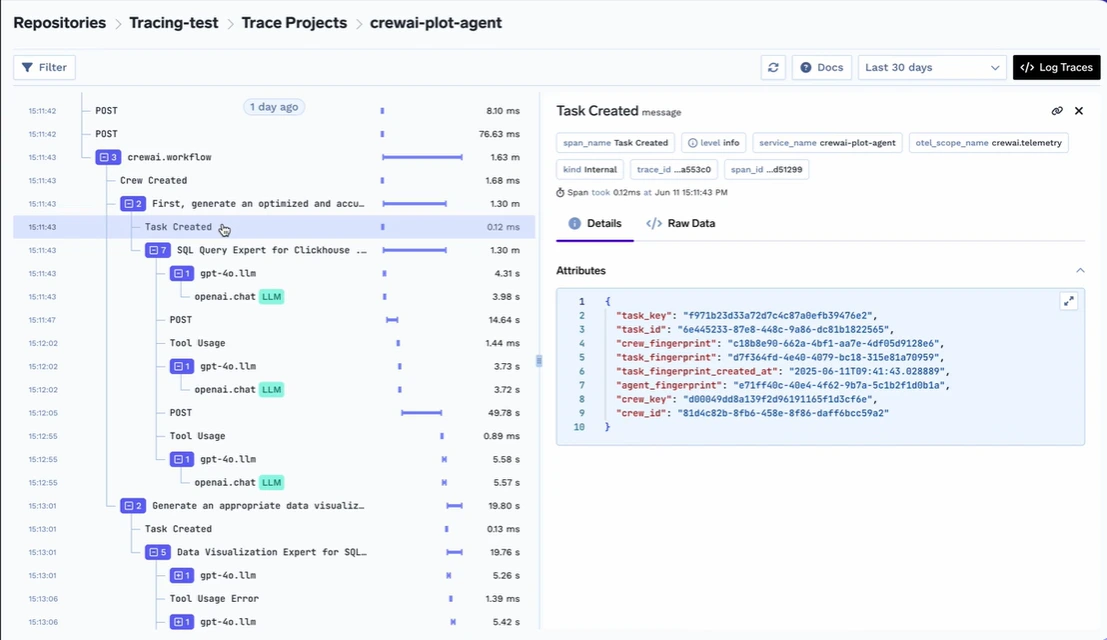
لضمان الثقة وقابلية المراقبة، توفر TrueFoundry مراقبة وتحليلات عميقة على مستوى المطالبة والاستجابة، تعمل كطبقة أساسية جنبًا إلى جنب مع أدوات مراقبة نماذج اللغة الكبيرة. يمكن للمؤسسات تتبع المطالبات المستخدمة، وكيف تتصرف النماذج بمرور الوقت، ومقدار زمن الاستجابة أو التكلفة المرتبطة بكل طلب. هذا أمر بالغ الأهمية لتصحيح الأخطاء، وتدقيقات الامتثال، وتحسين الأداء.
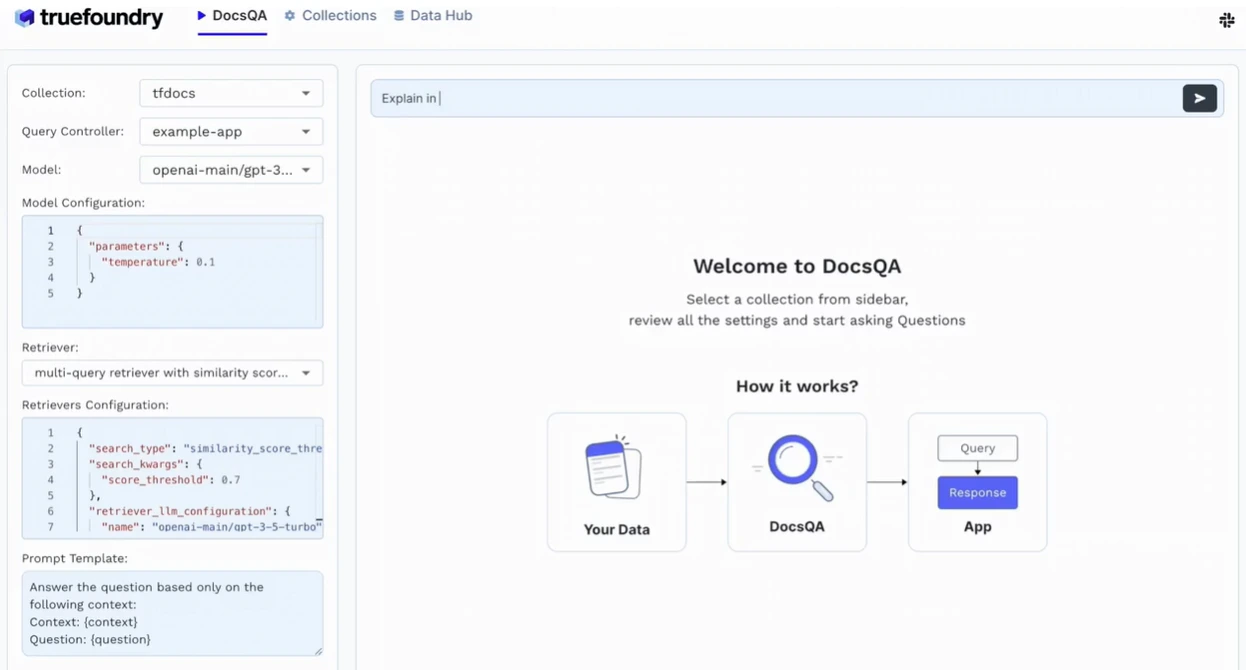
تدعم TrueFoundry أيضًا RAG (التوليد المعزز بالاسترجاع) جاهزًا للاستخدام، مما يسمح للمؤسسات بتأسيس استجابات نماذج اللغة الكبيرة على معرفتها الداخلية. تتكامل مع مخازن المتجهات الشائعة مثل Weaviate وPinecone وQdrant، مما يتيح استجابات دقيقة وواعية بالسياق دون إعادة تدريب النماذج الأساسية.
يمكن للمؤسسات أيضًا الاستفادة من تحديد إصدار المطالبات، وتتبع استخدام الرموز، وخطوط أنابيب الضبط الدقيق مع بيئات معزولة آمنة. تضمن ضوابط الوصول، وإدارة مفاتيح API، وسجلات التدقيق أمانًا وحوكمة على مستوى المؤسسات. تتيح TrueFoundry شفافية التكلفة والتحكم من خلال الفوترة الدقيقة، وتحديد معدل الاستخدام، وحصص الاستخدام، مما يمنح فرق الهندسة والمالية رؤية كاملة لاستخدام نماذج اللغة الكبيرة على نطاق واسع.
مع TrueFoundry، لا تكتفي المؤسسات بنشر نماذج اللغة الكبيرة فحسب؛ بل تقوم بتشغيلها عمليًا. تسد المنصة الفجوة بين التجريب والإنتاج، مما يجعل من الممكن بناء تطبيقات مدعومة بنماذج اللغة الكبيرة موثوقة ومتوافقة وقابلة للتطوير.
مع نضوج تبني المؤسسات لنماذج اللغة الكبيرة، يتحول التركيز من الوصول إلى التحسين والتنسيق والتوسع. أحد أهم الاتجاهات هو صعود النماذج مفتوحة المصدر الصغيرة والفعالة. تُظهر نماذج مثل Mistral وPhi-3 وDBRX أن الحجم لم يعد المؤشر الوحيد للجودة. تقوم المؤسسات بشكل متزايد بضبط هذه النماذج الأصغر لتلبية الاحتياجات الخاصة بالمهام مع تقليل التكلفة وزمن الاستجابة.
اتجاه آخر ناشئ هو التحول نحو الأنظمة الوكيلة (agentic systems)، حيث لا تكتفي نماذج اللغة الكبيرة بالاستجابة للمطالبات فحسب، بل تعمل كوكلاء مستقلين يخططون ويستدلون وينفذون المهام عبر أنظمة متعددة. يسمح هذا بسير عمل مؤسسي أكثر تعقيدًا مثل الإعداد، ومعالجة المستندات متعددة الخطوات، والتحليل الآلي.
نشهد أيضًا تكاملاً عميقًا مع رسوم المعرفة وقواعد بيانات المؤسسات. بدلاً من الاعتماد فقط على التضمينات ومخازن المتجهات، تقوم المؤسسات بربط نماذج اللغة الكبيرة بمصادر المعرفة المنظمة لتوفير مخرجات أكثر رسوخًا وقابلية للتدقيق والتتبع.
أخيرًا، ستصبح أدوات الحوكمة والامتثال غير قابلة للتفاوض. مع تزايد سير العمليات الحيوية للأعمال عبر نماذج اللغة الكبيرة، ستطالب المؤسسات بتحكم صارم في المطالبات والمخرجات وأذونات المستخدمين.
تشير هذه الاتجاهات إلى مستقبل تصبح فيه نماذج اللغة الكبيرة بنية تحتية أساسية—آمنة، قابلة للتركيب، ومدمجة بعمق في عمليات المؤسسات.
لم تعد نماذج اللغة الكبيرة للمؤسسات تجريبية؛ بل أصبحت بسرعة جزءًا أساسيًا من البنية التحتية للأعمال الحديثة. لكن تحقيق إمكاناتها الكاملة يتطلب أكثر من مجرد الوصول إلى نماذج قوية. يتطلب الأمر البنية الصحيحة، واستراتيجية النشر، وأنظمة المراقبة، وأطر الحوكمة. باستخدام منصات مثل TrueFoundry، يمكن للمؤسسات تجاوز النماذج الأولية وبناء تطبيقات LLM آمنة وقابلة للتطوير وموجهة نحو تحقيق عائد الاستثمار. ومع تطور هذا النظام البيئي، سيكون الفائزون هم أولئك الذين يتعاملون مع نماذج اللغة الكبيرة ليس كأدوات سحرية، بل كأنظمة مُدارة ومدمجة بعمق، ومراقبة باستمرار، ومتوافقة مع نتائج الأعمال.
نموذج اللغة الكبير للمؤسسات هو نموذج لغوي كبير مُحسّن لبيئات الشركات، يولي الأولوية لأمن البيانات وقابلية التوسع والتكامل مع الأنظمة الداخلية. على عكس النماذج العامة، تم تصميم نموذج اللغة الكبير للمؤسسات للعمل ضمن السحابة الخاصة للشركة أو البنية التحتية المحلية، مما يضمن حماية البيانات الحساسة. تُستخدم هذه النماذج عادةً لتشغيل أدوات متخصصة مثل قواعد المعرفة الداخلية وسير العمل الآلي.
لبناء نموذج لغة كبير للمؤسسات، يجب على المنظمات تجاوز مجرد استدعاءات واجهة برمجة التطبيقات البسيطة وإنشاء مسار عمل بجودة إنتاجية. يتضمن ذلك إعداد بنية تحتية قوية لاستضافة النماذج، وتطبيق التوليد المعزز بالاسترجاع (RAG) لترسيخ النموذج في البيانات الخاصة، وإنشاء بوابة ذكاء اصطناعي للإدارة المركزية. تعمل TrueFoundry على تبسيط هذه العملية من خلال توفير أدوات MLOps اللازمة لنشر وتوسيع نطاق هذه النماذج مع الحفاظ على الحوكمة الكاملة.
تشمل حالات الاستخدام الشائعة لنماذج اللغة الكبيرة للمؤسسات بناء محركات بحث قائمة على RAG للمستندات الخاصة، وأتمتة تحليل العقود المعقدة، ونشر وكلاء الذكاء الاصطناعي للدعم الفني. من خلال الاستفادة من نماذج اللغة الكبيرة في المؤسسات، يمكن للشركات تقليل وقت المعالجة اليدوية بشكل كبير مع زيادة دقة استرجاع المعلومات الداخلية.
غالبًا ما تفشل المعايير القياسية في تلبية متطلبات بيئة الإنتاج. بالنسبة لنموذج اللغة الكبير للمؤسسات، تشمل المعايير الحاسمة زمن استجابة الاستدلال، وكفاءة تكلفة الرمز المميز، ومقاييس "الدقة" في مسارات RAG لضمان عدم حدوث هلوسات. تتيح مراقبة هذه المعايير للفرق تقييم ما إذا كان نموذج معين يلبي معايير الأداء والموثوقية المطلوبة للتطبيقات الموجهة للعملاء أو الحيوية للمهام.
يتطلب اختيار نموذج اللغة الكبير المناسب للمؤسسات تحقيق التوازن بين أداء النموذج ومتطلبات سيادة البيانات. تستخدم العديد من المؤسسات مزيجًا من النماذج الاحتكارية للتفكير المعقد والنماذج مفتوحة المصدر للمهام ذات الحجم الكبير والحساسة للخصوصية. تتيح لك منصة مرنة مثل TrueFoundry تجنب الارتباط بمورد واحد من خلال توفير واجهة موحدة للتبديل بين النماذج المختلفة بناءً على احتياجات التكلفة والأمان المحددة لكل مشروع.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








أحدث الأخبار والمقالات والموارد تصلك مباشرة إلى بريدك الوارد
© 2026 جميع الحقوق محفوظة.







.png)
.webp)










.webp)
