




November 5, 2025
|
5 min read


احصل على وصول فوري إلى بيئة TrueFoundry مباشرة. انشر النماذج، ووجّه حركة مرور LLM، واستكشف المنصة بالكامل — بيئة الاختبار الخاصة بك جاهزة في ثوانٍ، ولا يلزم وجود بطاقة ائتمان.









Published: July 4, 2026

Blazingly fast way to build, track and deploy your models!
Cognita is a versatile open-source RAG framework designed to enable Data Science, Machine Learning, and Platform Engineering leaders to build and deploy scalable RAG applications. It features a fully modular, user-friendly, and adaptable architecture, ensuring complete security and compliance. It also ships with a UI that makes it easier to try out different RAG configurations and see the results in real-time.
In an era where customer experience defines business success, the ability to provide immediate and precise support is crucial. TrueFoundry's Cognita framework enables the development of sophisticated real-time AI applications tailored for customer support. By leveraging the modular and open-source nature of Cognita, businesses can enhance their support systems to deliver superior customer service.
Present customer support systems have substantial problems in delivering customers' high expectations for prompt and accurate responses. Conventional support approaches fail to handle vast amounts of requests, ensure consistency in responses, and provide 24/7 availability. These difficulties lead to higher operating expenses, lower customer satisfaction, and inefficiencies, which can deter business growth.
In a traditional manual customer support system, human agents are responsible for addressing each customer inquiry individually. This labor-intensive process involves agents navigating through extensive knowledge bases, documentation, and past query records to find accurate and relevant information. The variability in human performance can lead to inconsistencies in responses, with the quality of support depending heavily on the agent's expertise and experience. Furthermore, maintaining a 24/7 support system requires a significant workforce, necessitating shift rotations and leading to increased operational costs. During peak query times, the manual approach often results in backlogs, prolonged response times, and customer dissatisfaction.
This automated pipeline not only significantly reduces response times but also ensures that each customer interaction is handled with consistent accuracy and reliability. Cognita's scalability enables the system to handle high numbers of requests at once, making it a practical choice for enterprises facing growth or shifting support demands. Furthermore, this automation relieves human agents of mundane questions, allowing them to concentrate on more complicated issues, thus increasing the overall efficiency and efficacy of the support operation.
Transitioning to an automated system powered by TrueFoundry's Cognita framework enables the integration of advanced AI components to automate customer query handling. Specifically, the use of data loaders and parsers ensures that a comprehensive and structured dataset is readily available for the system to learn from. By implementing embedders, textual data is converted into high-dimensional vectors, facilitating efficient and accurate similarity searches. The vector databases support rapid retrieval of this embedded information, ensuring real-time performance. When a query is received, the query controller orchestrates the process, utilizing rerankers to evaluate and prioritize the most relevant responses.
Implementing Cognita for customer support can address these challenges by:
You can use Cognita locally or with/without using any Truefoundry components. However, using Truefoundry components makes it easier to test different models and deploy the system in a scalable way. Cognita allows you to host multiple RAG systems using one app. Hence, we will be using TrueFoundry components to create a small-scale support bot for just the MacBook Pro initially and then add a few more products and support for different languages to scale it.
Once you've set up a cluster, added a Storage Integration, and created an ML Repo and Workspace, you are all set to begin deploying a Cognita-based RAG application using TrueFoundry. More information on this one-time setup can be found here. Once done:
+ New Deployment button on the top-right and select Application Catalogue. Select your workspace and the RAG Application.By default, the release branch is used for deployment (You will find this option in Show Advance fields). You can change the branch name and git repository if required.
Make sure to re-select the main branch, as the SHA commit does not get updated automatically.
Submit, and your application will be deployed.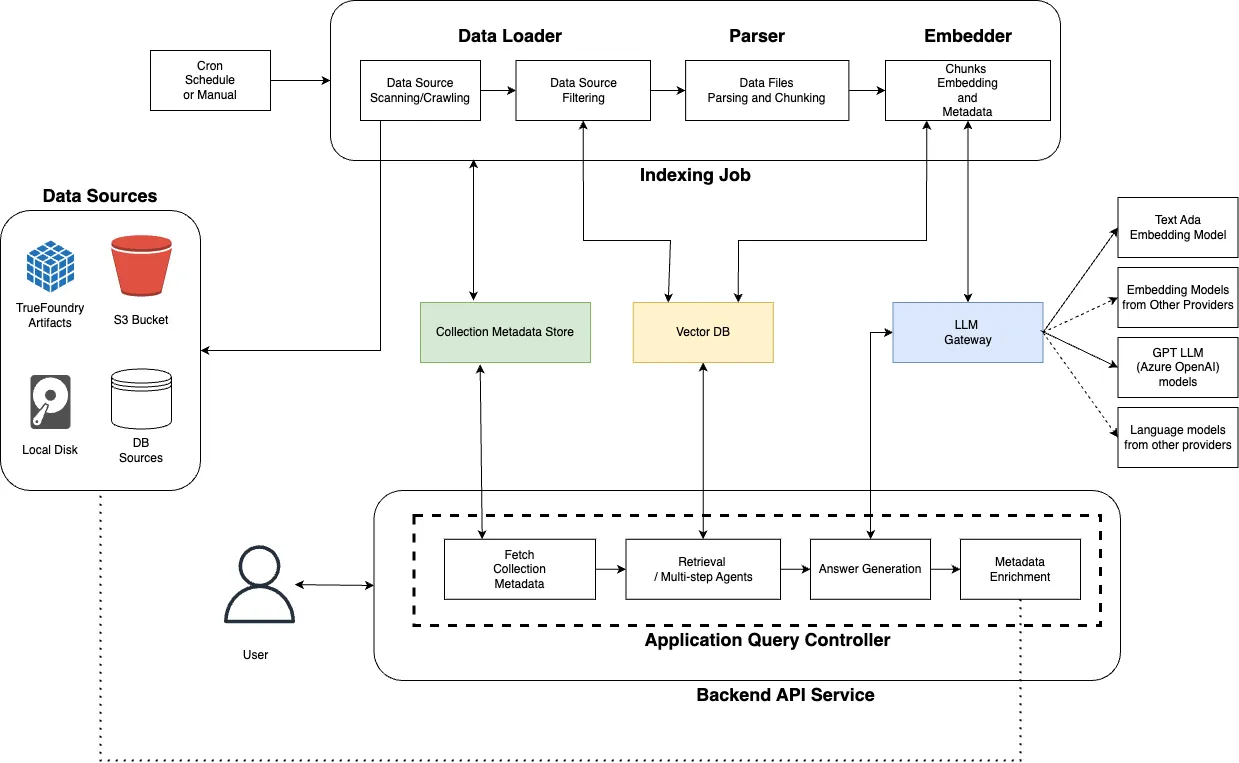
Overall, the architecture of Cognita is composed of several entities. We will be delving into each of them through the implementation steps below.
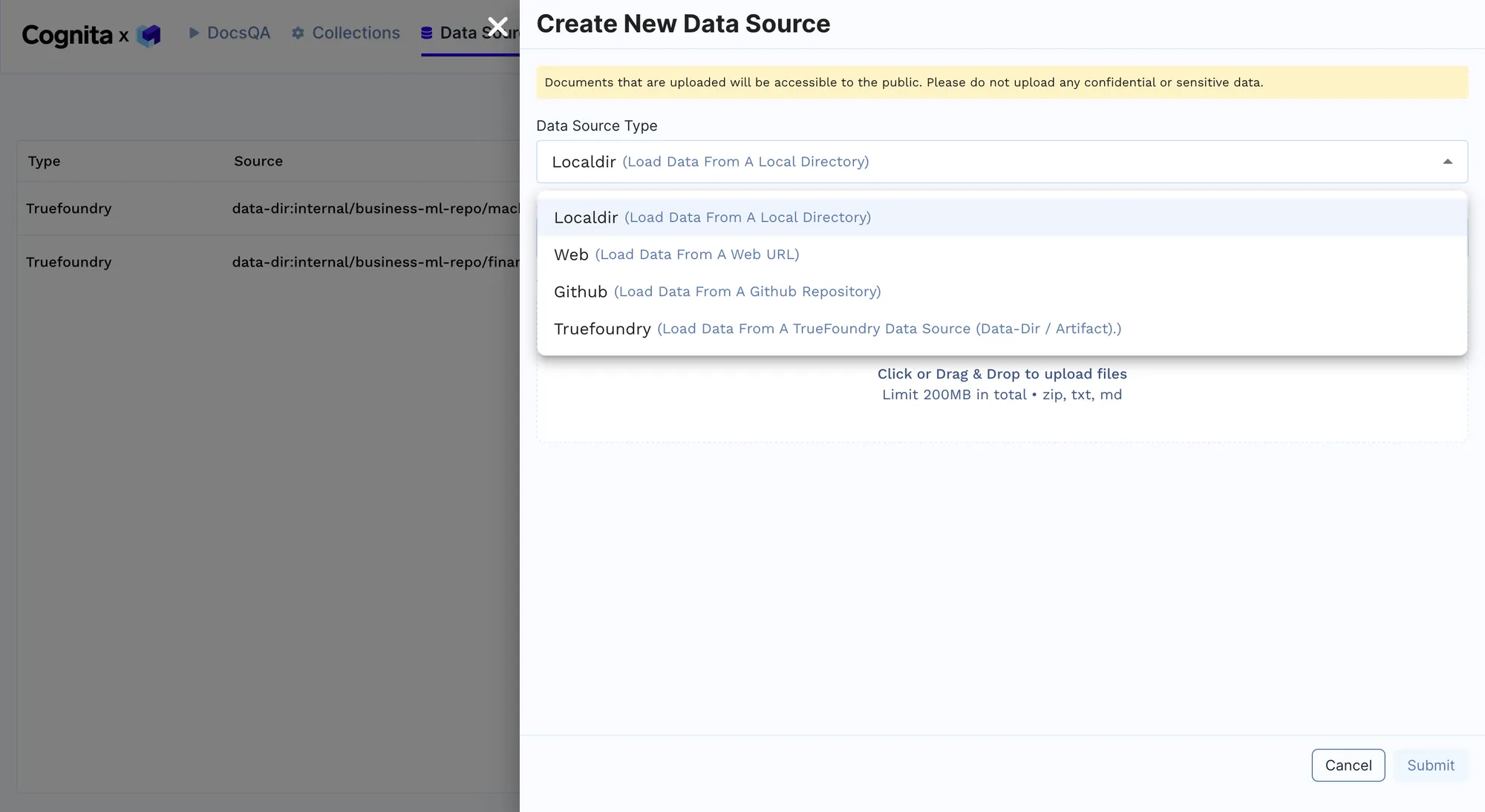
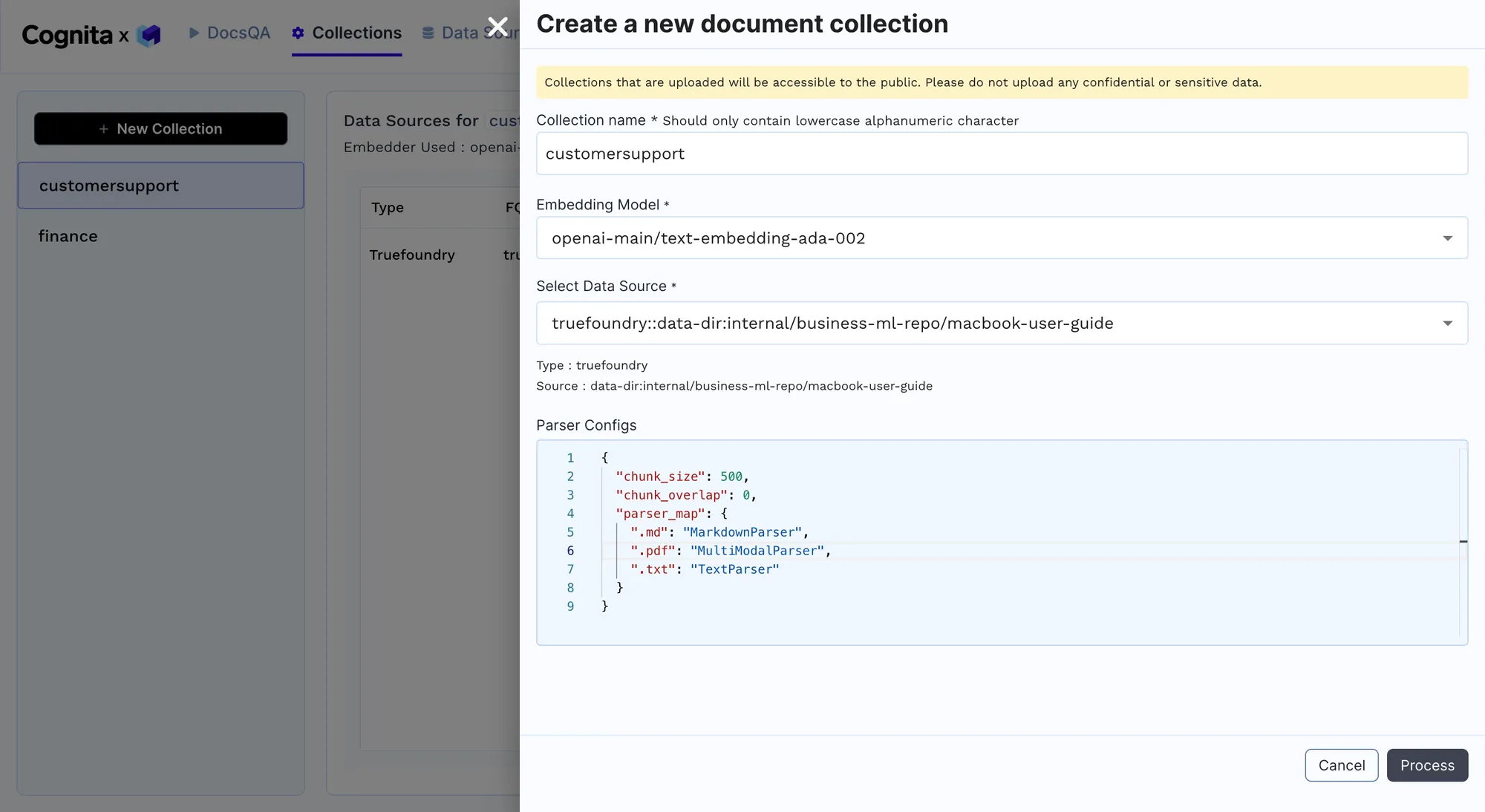
Suppose you want to scale the RAG application. In that case, we can do this by adding different data sources to allow it to cater to various customer queries and be an all-inclusive solution. We add other documents, including support documents for different MacBooks, iPads, iPhones, AirPods, and watchOS, by adding a new data source and linking it to the collection. The RAG now acts as a comprehensive AI customer support agent for a broad suite of Apple products. Some documents are also in different languages to further scale it by adding multi-language support.
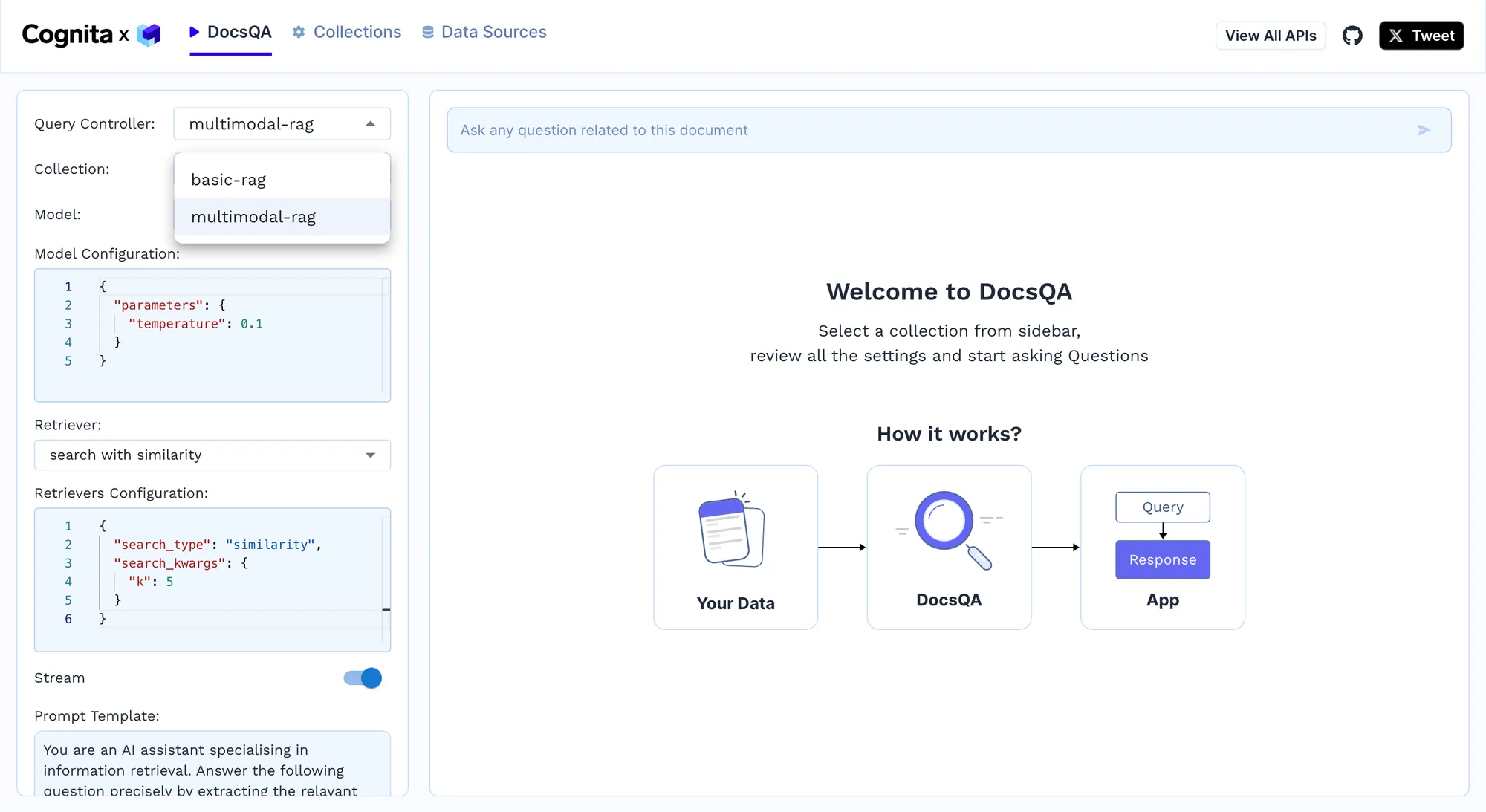
We will now test the model by giving it a complex query, and the results are shown below.
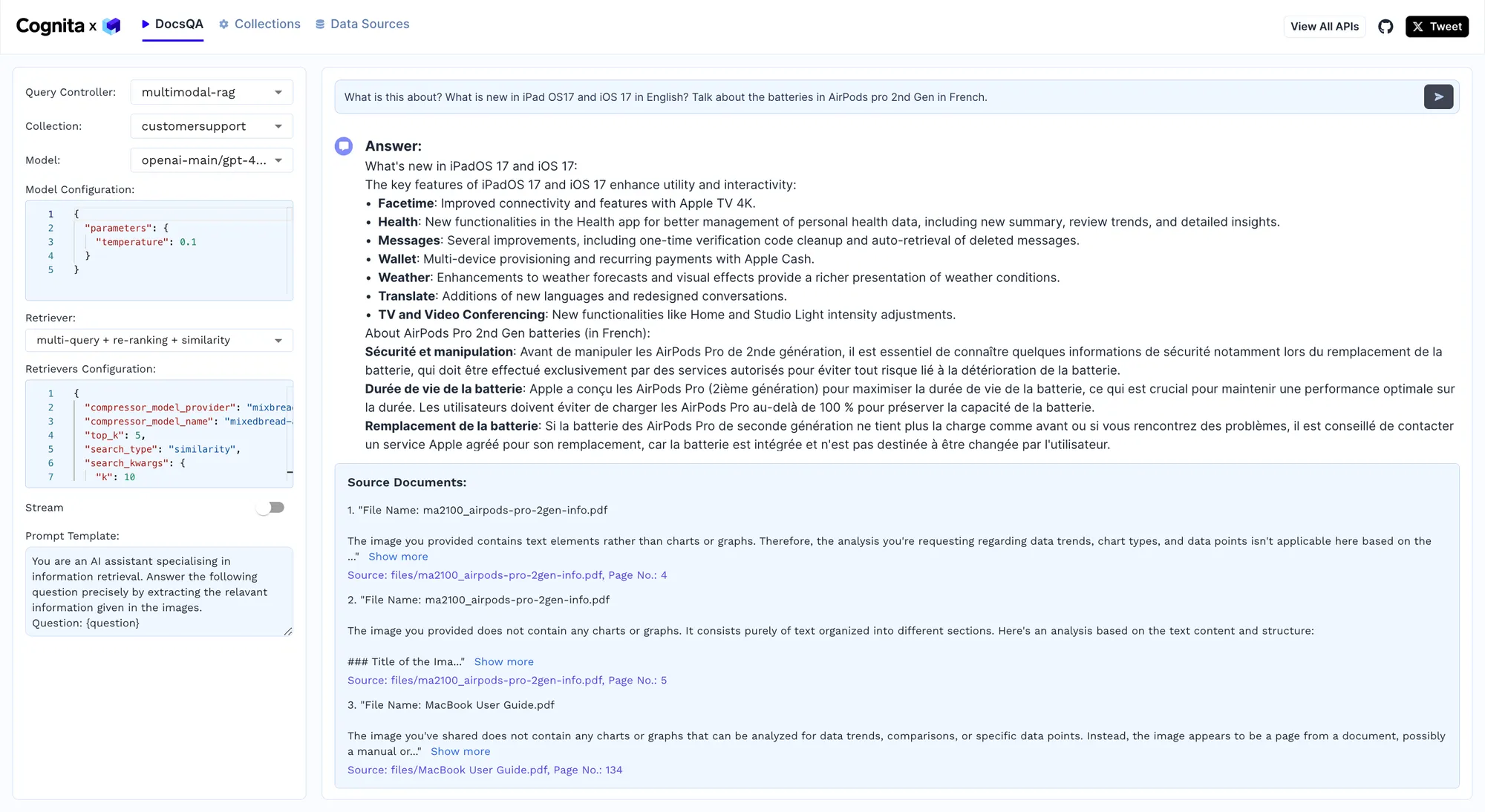
في اختبار لإطار عمل Cognita، نجح النموذج في الإجابة على الاستعلام، "ما الجديد في iPadOS 17 و iOS 17 باللغة الإنجليزية؟ تحدث عن بطاريات AirPods Pro الجيل الثاني باللغة الفرنسية،" مما يدل على قدرته على التعامل مع الأسئلة المعقدة ومتعددة اللغات. استخدم النموذج تكوين multimodal-rag لمعالجة وتجميع المعلومات من وثائق مختلفة، مقدمًا قائمة مفصلة بالميزات الجديدة في iPadOS 17 و iOS 17، مثل تحسينات قدرات FaceTime والتحسينات في تطبيق الصحة. بالإضافة إلى ذلك، قدم معلومات دقيقة حول بطاريات AirPods Pro الجيل الثاني باللغة الفرنسية، متناولًا جوانب السلامة وعمر البطارية وإجراءات الاستبدال. يؤكد هذا الاختبار قدرة Cognita على دمج نماذج معالجة اللغة الطبيعية (NLP) والرؤية المتقدمة، مما يضمن استجابات دقيقة وذات صلة بالسياق بلغات متعددة، وبالتالي يعزز عمليات دعم العملاء باسترجاع المعلومات عالية الجودة في الوقت الفعلي.
توفر البنية المعيارية لـ Cognita وقدرات الذكاء الاصطناعي المتقدمة حلاً قويًا لتعزيز دعم العملاء. فهي تتعامل بكفاءة مع الاستفسارات المعقدة، وتعالج أنواع البيانات المتنوعة، وتقدم استجابات دقيقة وفي الوقت الفعلي. من خلال دمج ميزات مثل الدعم متعدد اللغات والتحليلات التنبؤية، تعمل Cognita على تحسين رضا العملاء والكفاءة التشغيلية بشكل كبير، مما يجعلها أداة لا تقدر بثمن لأنظمة الدعم الحديثة.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








أحدث الأخبار والمقالات والموارد تصلك مباشرة إلى بريدك الوارد
© 2026 جميع الحقوق محفوظة.











.png)
.webp)










.webp)
