




November 5, 2025
|
5 min read


احصل على وصول فوري إلى بيئة TrueFoundry مباشرة. انشر النماذج، ووجّه حركة مرور LLM، واستكشف المنصة بالكامل — بيئة الاختبار الخاصة بك جاهزة في ثوانٍ، ولا يلزم وجود بطاقة ائتمان.









Published: July 4, 2026
Blazingly fast way to build, track and deploy your models!
لا نبالغ إذا قلنا إن كل عمل تجاري يحتاج إلى التعامل مع المزيد من حركة المرور، ومعالجة المزيد من البيانات، ودعم المزيد من العملاء مع نموه. غالبًا ما يحتاجون إلى توسيع نطاق بنيتهم التحتية لمواكبة المتطلبات المتزايدة. ينطبق هذا أيضًا إذا كان عملك موسميًا. تخيل موقعًا للتجارة الإلكترونية يشهد الكثير من حركة المرور خلال العطلات، مثل الجمعة السوداء أو سايبر مونداي. قد تزداد حركة مرور الموقع بشكل كبير خلال هذه الأوقات المزدحمة. قد يواجه الموقع مشاكل في تأخر تحميل الصفحات ويزعج المستخدمين إذا لم يتمكن من التعامل مع الطلب المتزايد. ونتيجة لذلك، قد تخسر الشركة مبيعات وتتدهور سمعتها.
إحدى طرق معالجة هذه المشكلة هي زيادة عدد الخوادم يدويًا في البنية التحتية للتعامل مع حركة المرور المتزايدة. ومع ذلك، فإن التوسع والتقليص اليدوي يمكن أن يستغرق وقتًا طويلاً، ويكون عرضة للأخطاء، ويصعب إدارته. هنا يأتي دور التحجيم التلقائي للمجموعات. يقوم التحجيم التلقائي للمجموعات بضبط عدد الخوادم في البنية التحتية تلقائيًا بناءً على شروط معينة، مثل استخدام وحدة المعالجة المركزية، أو استخدام الذاكرة، أو الطلبات الواردة. هذا يعني أن البنية التحتية يمكنها التوسع أو التقليص بناءً على الطلب الحالي دون تدخل يدوي.
ستستكشف هذه المدونة ما هو التحجيم التلقائي للمجموعات، ولماذا هو ضروري، وكيف يمكن تنفيذه في مختلف موفري الخدمات السحابية.
لكي تعمل مجموعتنا بشكل صحيح على جميع موفري الخدمات السحابية الرئيسيين، يجب علينا تكييف طريقة تحجيم عقد المجموعة.
💡
على AWS، نستخدم Karpenter، الذي، بأقل قدر من التكوين، يمكنه اختيار العقدة الأقل تكلفة والأكثر كفاءة لطلبات الـ pod الواردة.
💡
على GCP، نعتمد على GKE Autopilot، الذي يوفر لنا مجموعة مُدارة قادرة على التوسع والتقليص حسب الطلبات.
💡
لا توجد حلول مخصصة على Azure، ونستخدم Kubernetes cluster-autoscaler، وهو أقل تحسينًا من Karpenter ويتطلب تكوينًا أكثر من Autopilot.
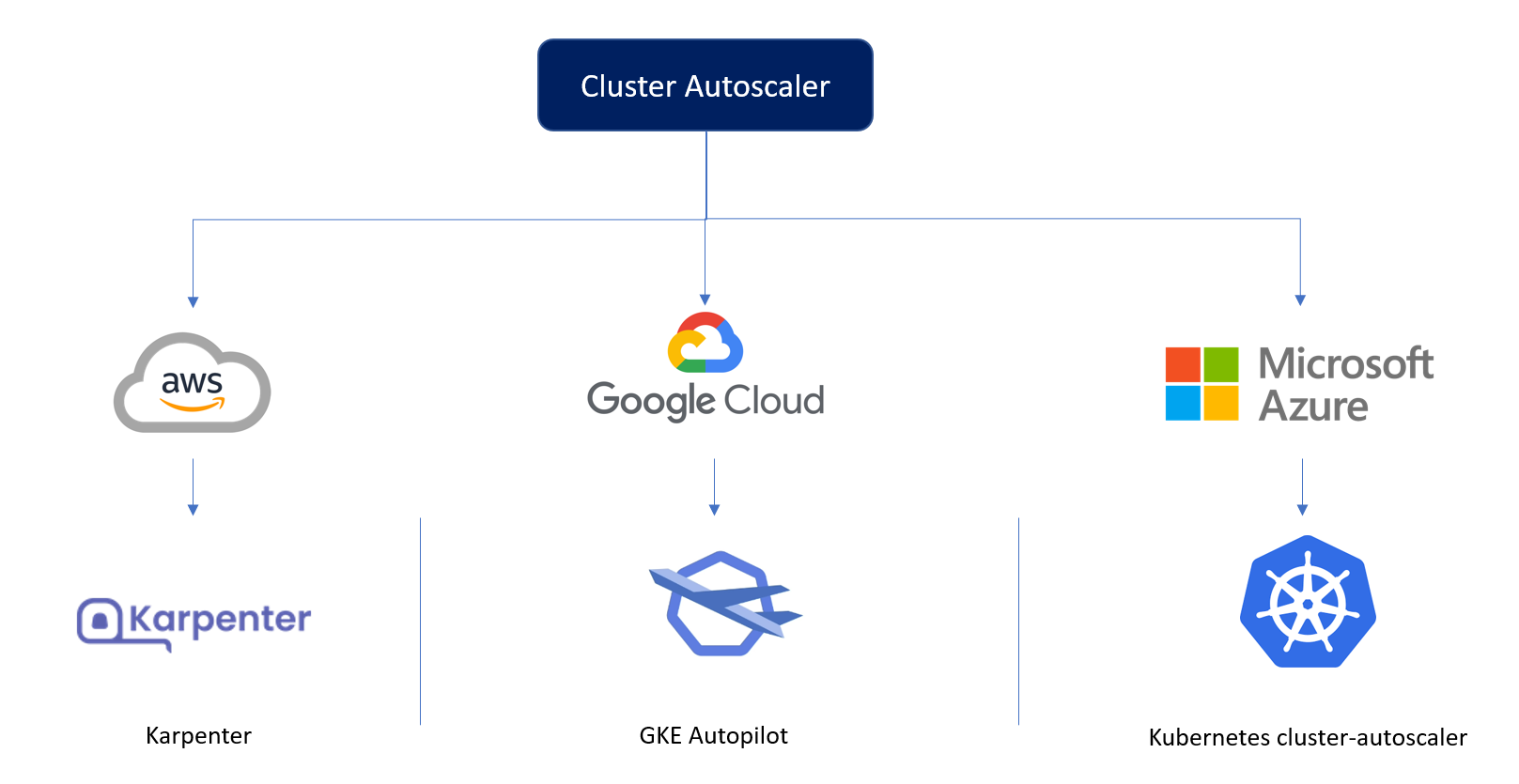
يراقب Karpenter طلبات الموارد الإجمالية للـ pods غير المجدولة ويتخذ قرارات لإطلاق وإنهاء العقد لتقليل زمن استجابة الجدولة وتكاليف البنية التحتية.
ولكن للأسف، يعمل Karpenter فقط على AWS.
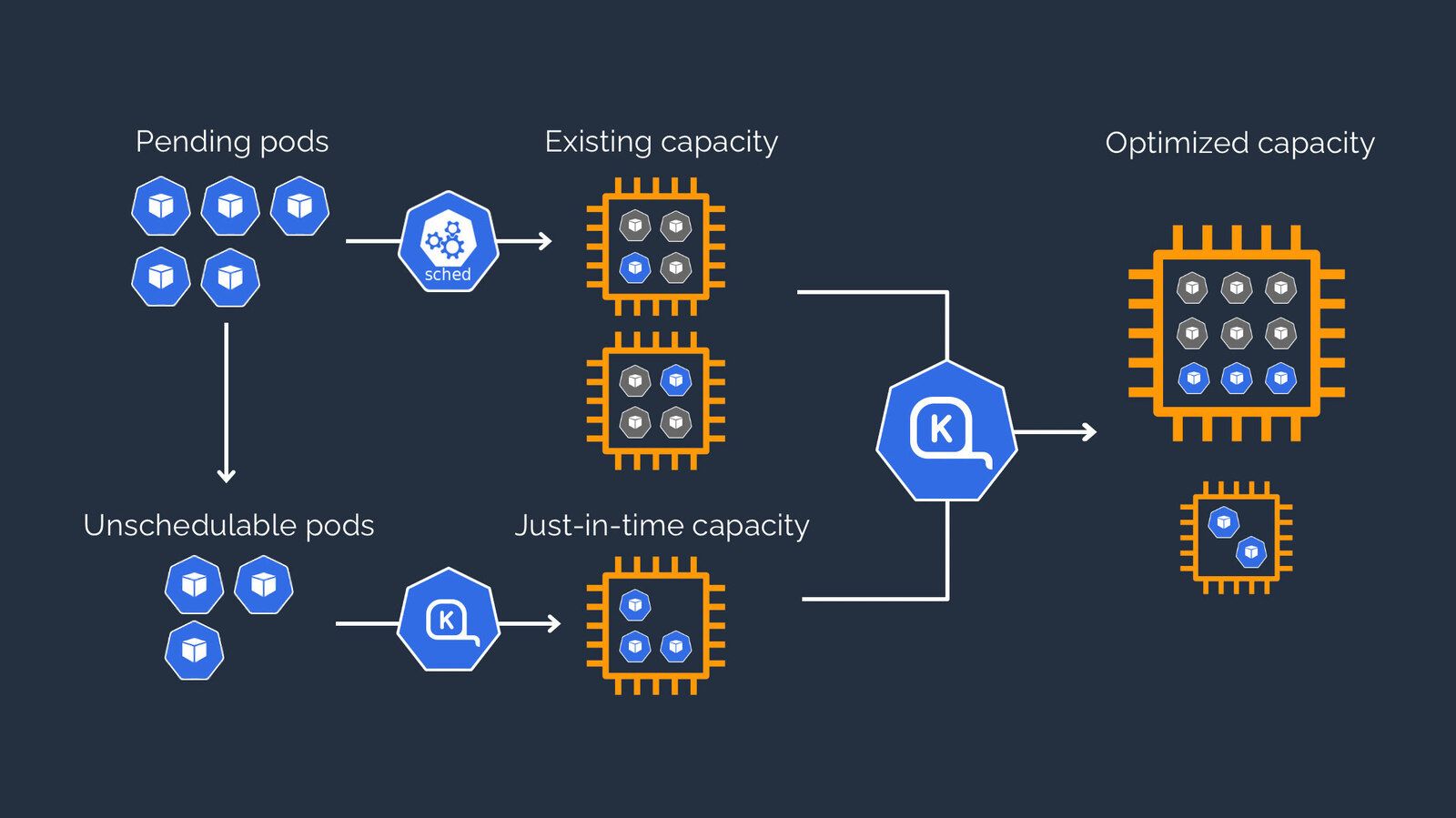
Autopilot هي خدمة مُدارة تستخدم خوارزميات التعلم الآلي لتحديد العدد الأمثل للعُقد للمجموعة بناءً على عبء العمل الحالي. كما توفر ميزات مثل الترقيات والتصحيحات التلقائية، مما يسهل الحفاظ على تحديث المجموعة وتأمينها.
بالإضافة إلى التحجيم التلقائي، يوفر Cluster Autopilot أيضًا مزايا أخرى، مثل تحسين استخدام الموارد وتوفير التكاليف عن طريق تجنب الإفراط في توفير الموارد. كما يوفر نهجًا أقل تدخلاً في إدارة المجموعات، حيث تتولى الخدمة جميع عمليات التحجيم التلقائي.
لا يوجد عرض مُدار على سحابة Azure مثل GKE Autopilot أو نهج مخصص للتحجيم التلقائي مثل Karpenter؛ لذلك، نعتمد على أداة التحجيم التلقائي للمجموعات (cluster-autoscaler).
أداة التحجيم التلقائي لمجموعات Kubernetes (Kubernetes Cluster Autoscaler) هي أداة مفتوحة المصدر تتيح التحجيم التلقائي لمجموعات Kubernetes. تعمل كـ "بود" (وحدة) داخل المجموعة وتراقب استخدام موارد المجموعة، وتعدل عدد العُقد الضرورية لتلبية احتياجات التطبيقات التي تعمل بداخلها. يساعد هذا في تحسين استخدام الموارد وتقليل التكاليف عن طريق تجنب الإفراط في توفير الموارد عندما يكون الطلب منخفضًا. تتطلب أداة التحجيم التلقائي للمجموعات تكوينًا يدويًا لمجموعات العُقد وأنواعها.
تغطي هذه المدونة تفاصيل حول التحجيم التلقائي في Kubernetes.
TrueFoundry هي منصة كخدمة (PaaS) لنشر التعلم الآلي (ML) فوق Kubernetes لتسريع سير عمل المطورين مع منحهم مرونة كاملة في اختبار ونشر النماذج، مع ضمان الأمان والتحكم الكامل لفريق البنية التحتية. من خلال منصتنا، نمكّن فرق التعلم الآلي من نشر ومراقبة النماذج في 15 دقيقة بموثوقية 100% وقابلية للتوسع، والقدرة على التراجع في ثوانٍ - مما يسمح لهم بتوفير التكلفة وإطلاق النماذج إلى الإنتاج بشكل أسرع، مما يتيح تحقيق قيمة تجارية حقيقية.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








أحدث الأخبار والمقالات والموارد تصلك مباشرة إلى بريدك الوارد
© 2026 جميع الحقوق محفوظة.











.png)
.webp)










.webp)
