




July 4, 2026
|
5 min read


احصل على وصول فوري إلى بيئة TrueFoundry مباشرة. انشر النماذج، ووجّه حركة مرور LLM، واستكشف المنصة بالكامل — بيئة الاختبار الخاصة بك جاهزة في ثوانٍ، ولا يلزم وجود بطاقة ائتمان.









Published: July 4, 2026

Blazingly fast way to build, track and deploy your models!
في المؤسسات التي تعتمد على الذكاء الاصطناعي اليوم، تُعد التدابير القوية لـ سلامة الذكاء الاصطناعي و امتثال نماذج اللغة الكبيرة (LLM) أمرًا بالغ الأهمية. مع دمج الشركات لنماذج اللغة الكبيرة (LLMs) القوية في سير العمل التجاري، تحتاج إلى آليات لإبقاء هذه النماذج "على المسار الصحيح" وفقًا لقواعد المؤسسة. تؤدي حواجز حماية الذكاء الاصطناعي هذا الدور – على غرار حواجز الطرق – من خلال ضمان أن كل تفاعل للذكاء الاصطناعي يعكس معايير الشركة وسياساتها وقيمها. تعمل حواجز الحماية عن طريق الفحص التلقائي أو تحويل مطالبات واستجابات نماذج اللغة الكبيرة (LLM) لفرض سياسات الأمان والخصوصية والمحتوى. بوابة الذكاء الاصطناعي من TrueFoundry تدمج حواجز الحماية هذه في صميم مسار عمل الذكاء الاصطناعي، مما يضمن صحة الطلبات والاستجابات لضمان السلامة والجودة والامتثال. تقدم هذه المقالة نظرة عامة تقنية على حواجز حماية الذكاء الاصطناعي في سياق بوابة الذكاء الاصطناعي. نحدد ماهية حواجز الحماية، ونشرح كيفية عملها، ونسلط الضوء على مكوناتها الأساسية، ونصف كيف يمكن للمؤسسات تطبيقها.
حواجز حماية الذكاء الاصطناعي هي ضوابط وفلاتر قائمة على القواعد توضع حول أنظمة الذكاء الاصطناعي التوليدية لفرض سياسات المؤسسة. تساعد حواجز الحماية على ضمان أن أداة الذكاء الاصطناعي "تعمل بما يتماشى مع المعايير والسياسات والقيم التنظيمية". عمليًا، هذا يعني أن حواجز الحماية قد تخفي أو تزيل البيانات الحساسة (لخصوصية البيانات)، أو تحظر الموضوعات غير المسموح بها (لامتثال المحتوى)، أو تتحقق من صحة تنسيقات المخرجات (لضمان الجودة).
في بوابة الذكاء الاصطناعي (مثل TrueFoundry)، تُطبق حواجز الحماية في نقطتين: قبل إرسال الطلب إلى نموذج لغة كبير (LLM) (حواجز حماية الإدخال) وبعد إرجاع الاستجابة (ضوابط المخرجات). من خلال اعتراض كلا طرفي تفاعل نموذج اللغة الكبير (LLM)، تضمن الضوابط أن كل مطالبة ورد يلتزم بقواعد المؤسسة.
أمثلة على ضوابط الذكاء الاصطناعي أثناء العمل:
باختصار، حواجز حماية الذكاء الاصطناعي هي التطبيق التقني لسياسات حوكمة الذكاء الاصطناعي، للتأكد من أن "كل طلب واستجابة يفي بمعايير المؤسسة للأمان والجودة والامتثال".
Key Metrics for Evaluating Gateway
| Criteria | What should you evaluate ? | Priority | TrueFoundry |
|---|---|---|---|
| Latency | Adds <10ms p95 overhead for time-to-first-token? | Must Have | ✅ Supported |
| Data Residency | Keeps logs within your region (EU/US)? | Depends on use case | ✅ Supported |
| Latency-Based Routing | Automatically reroutes based on real-time latency/failures? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |

بوابة TrueFoundry للذكاء الاصطناعي تفرض حواجز حماية على كل من المدخلات والمخرجات لكل استدعاء لنموذج اللغة الكبير (LLM). تعمل حواجز حماية المدخلات قبل وصول المطالبة إلى النموذج، وتؤدي مهام مثل إخفاء البيانات الشخصية أو تصفية المحتوى المحظور. تعمل حواجز حماية المخرجات بعد استجابة النموذج، للتدقيق في المحتوى غير الآمن أو غير المسموح به (وتصحيحه اختياريًا).
يمكن لكل قاعدة من قواعد حواجز الحماية أن تعمل في وضعين: التحقق (حظر) أو التعديل (تعديل). في وضع التحقق، يؤدي أي انتهاك يتم اكتشافه إلى حظر الطلب أو الاستجابة مع ظهور خطأ، مما يفرض الامتثال بشكل صارم. في وضع التعديل، تقوم حاجز الحماية تلقائيًا بتغيير المحتوى لإزالة المشكلة أو تحويلها (على سبيل المثال، إخفاء رقم هاتف أو استبدال كلمة محظورة). يضمن هذا النهج ذو المرحلتين (المدخلات/المخرجات) والوضعَين (التحقق/التعديل) عدم تسرب أي بيانات حساسة أو غير متوافقة عبر النظام.
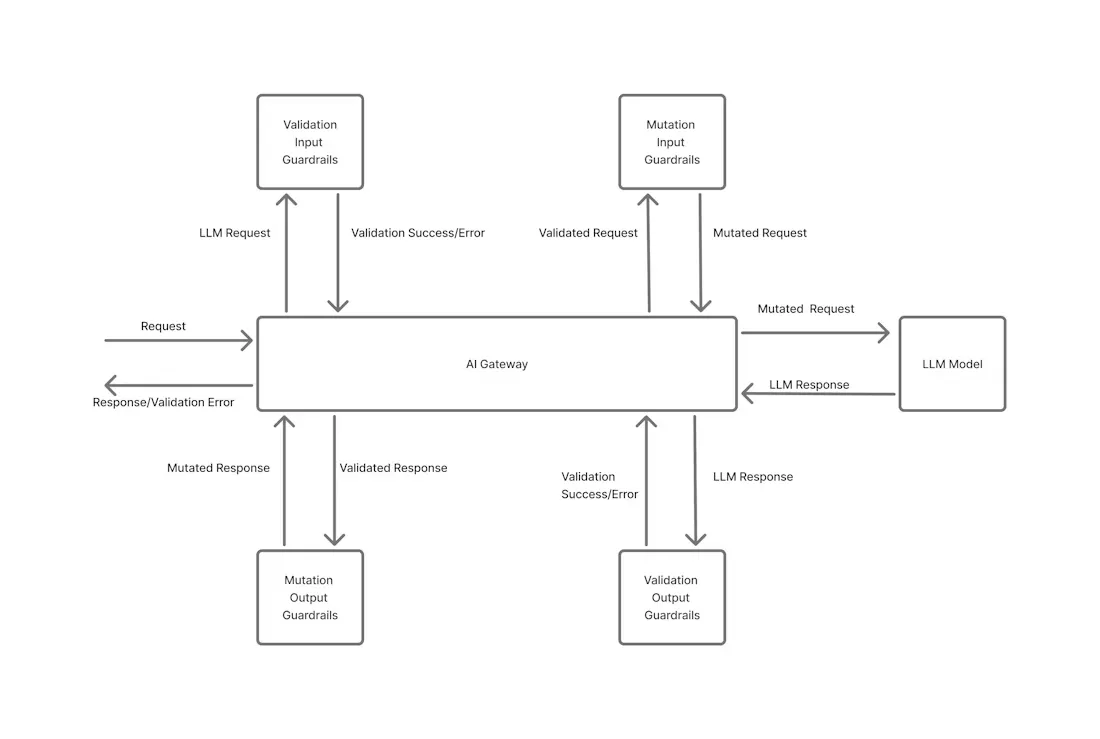
يوضح الرسم البياني أعلاه كيف تمر كل رسالة عبر مرشحات المدخلات قبل الوصول إلى النموذج وعبر مرشحات المخرجات بعد الاستجابة، مما يوفر شبكة أمان على جانبي تفاعل الذكاء الاصطناعي.
بوابة TrueFoundry للذكاء الاصطناعي يوفر طبقة تحكم موحدة حيث يمكن للمؤسسات تحديد ودمج وإدارة ضوابط الحماية عبر جميع تفاعلات نماذج اللغة الكبيرة (LLM) — دون تعديل منطق التطبيق. يمكن تكوين ضوابط الحماية بشكل تصريحي عبر YAML أو واجهات برمجة التطبيقات (APIs) أو وحدة تحكم TrueFoundry، مما يسمح للفرق بتطبيق سياسات متسقة عبر العديد من مزودي الذكاء الاصطناعي (مثل OpenAI، Anthropic، أو Azure OpenAI).
بشكل عام، يتم دمج ضوابط الحماية عند طبقة البوابة، حيث تعترض حركة المرور بين التطبيقات ونماذج اللغة الكبيرة الأساسية.
تضمن هذه البنية سلامة الذكاء الاصطناعي والامتثال مع الحفاظ على كمون منخفض من خلال التنفيذ المتوازي والتخزين المؤقت لنتائج الضوابط.
يمكن للمطورين وفرق المنصات تكوين الضوابط على نطاقات متنوعة:
ضوابط شاملة: سياسات على مستوى المؤسسة تنطبق على جميع النماذج ونقاط النهاية (مثل، إخفاء معلومات التعريف الشخصية أو المواضيع غير المسموح بها).
ضوابط على مستوى النموذج: تكوينات محددة لكل مزود نموذج لغوي كبير (على سبيل المثال، استخدام كشف معلومات التعريف الشخصية من Azure مع GPT-4 ولكن استخدام إشراف OpenAI لـ Claude).
ضوابط على مستوى المسار: تحكم دقيق في مسارات واجهة برمجة التطبيقات—مما يسمح لنقاط نهاية مختلفة بفرض قواعد تحقق أو امتثال مختلفة.
قد يبدو مثال بسيط للتكوين كما يلي:

With TrueFoundry’s AI Gateway, organizations can integrate guardrails as a native part of their AI infrastructure, ensuring robust AI safety, data protection, and regulatory alignment—all while maintaining high performance and flexibility.
Without guardrails, enterprise LLM deployments face serious risks. Generative AI models can produce unpredictable or unsafe outputs that expose organizations to legal, reputational, and operational harm. For example, an unfiltered AI chatbot might inadvertently reveal personal user information or use profanity or biased language, eroding customer trust and potentially violating regulations like GDPR or HIPAA. In sensitive domains (e.g. healthcare or finance), even a single hallucinated answer could have disastrous consequences. Lack of real-time checks also means issues are detected only after deployment – for instance, by unhappy users or audit reviews – which is far costlier than catching them early.
In practice, the absence of guardrails leads to security breaches (data leaks), compliance violations (illegal advice or misinformation), brand damage (offensive or inconsistent responses), and unpredictable application behavior. In short, without guardrails to enforce AI safety and compliance, enterprises run the risk of costly mistakes and loss of control over their AI systems.
Effective AI guardrails combine several technical elements to cover different risk areas. A robust system typically includes:
(1) Rule Engine – an ordered set of policy rules that match on user, model, or context, ensuring only the first applicable rule fires
(2) PII & Data Filters – built-in or external detectors that recognize and redact personal and sensitive information (emails, SSNs, credit cards, etc.) in both inputs and outputs
(3) Content Classifiers – semantic filters that check for disallowed topics (medical advice, hate speech, profanity, etc.) or hallucinations against a taxonomy of risks
(4) Custom Keyword Filters – company-specific word or phrase blocklists that can transform or block particular terms in real-time and,
(5) Transformation Actions – the ability to either reject content (validate) or automatically sanitize it (mutate) based on policy.
In TrueFoundry’s platform, these components are implemented as “guardrail integrations” (for example, linking to OpenAI’s moderation API) which the Gateway invokes as needed. Each time a rule is applied, the system logs the event (what was checked, and how it was handled) for auditing and analysis. Combined, these features create a comprehensive safety framework: inputs are pre-scrubbed before they ever reach the LLM, and outputs are checked before they reach the user. In McKinsey’s terms, an effective guardrail system includes “checkers” to flag issues and “correctors” to fix them – exactly the role played by TrueFoundry’s input/output filters and transformation logic.
It is important to distinguish guardrails from governance. AI governance refers to the high-level frameworks, policies, roles, and oversight procedures that define what is acceptable and why – for example, an enterprise’s data privacy policy or AI ethics guidelines. Governance ensures that AI initiatives have clear accountability and align with legal and ethical standards. Guardrails, by contrast, are the technical enforcement mechanisms that implement those policies in real time on each AI request. In other words, governance sets the rules of the road, and guardrails are the barriers and sensors that keep the AI vehicle from veering off course. Having governance without guardrails means policies exist only on paper; having guardrails without governance means there is no clear guidance on what to enforce. In practice, effective AI risk management uses both: strategic governance defines the goals (e.g. “never reveal PII”, “no medical advice”), and guardrails (in the AI Gateway) automatically enforce those rules on every LLM interaction. As one analyst notes, organizations need both AI governance and technical guardrails working together to safely scale AI.
TrueFoundry’s AI Gateway makes it practical to deploy guardrails across an organization. Typically, administrators begin by creating a Guardrails Group in the Gateway UI – a container with defined managers and users – to hold policy integrations. Within that group, they add specific guardrail integrations (for example, OpenAI’s Moderation API for content filtering) by filling in the provider’s configuration form.
Once integrations are defined, teams can immediately test them using TrueFoundry’s Playground. For instance, one can apply an input guardrail and submit an unsafe prompt; the Playground will demonstrate that the guardrail blocks or sanitizes the content as expected.
In production code, developers can enforce guardrails per request by adding the X-TFY-GUARDRAILS header with the chosen rule set. This lets applications dynamically specify which filters to apply on a call-by-call basis.
For enterprise-wide policy, TrueFoundry supports gateway-level guardrail configurations: an administrator creates a YAML config in the AI Gateway’s Config tab specifying rules with when conditions and listing the input_guardrails and output_guardrails to apply. Only the first matching rule is used per request.
Defining guardrails at the gateway level is best for organization-wide enforcement, so that every AI request is automatically checked according to the company’s compliance standards. In this way, the AI Gateway centralizes guardrail management and auditing, eliminating the need to instrument each application separately.
The guardrails landscape is evolving rapidly alongside AI capabilities and regulations. Researchers advocate multi-layer guardrail architectures: for example, a primary input/output “gatekeeper” layer could be complemented by a knowledge-grounding layer that uses retrieval-augmented checks to verify factual accuracy. Organizations are also experimenting with intelligent guardrails – using AI agents to continuously monitor and correct model outputs in real time. On the tooling front, a growing ecosystem of open-source frameworks is emerging. NVIDIA’s NeMo Guardrails toolkit, LangChain’s Guardrails library, and others provide programmable rule engines for LLMs. Cloud providers likewise offer built-in moderation and safety filters for their AI services. Meanwhile, stricter regulations (such as the EU’s proposed AI Act) will drive demand for turnkey guardrail solutions that can demonstrate LLM compliance in real time. Overall, we can expect guardrails to become even more integrated into the AI development lifecycle – incorporating advanced NLP detectors, context-aware policies, and verifiable audit logs – to keep enterprise AI deployments both powerful and safe.
AI guardrails are essential for turning advanced LLMs from unpredictable experiments into reliable, compliant enterprise tools. By sandwiching every AI request between input and output checks, TrueFoundry’s AI Gateway enables organizations to enforce data privacy, content standards, and regulatory requirements automatically. The key is combining flexible, policy-driven filters (for PII masking, topic moderation, etc.) with real-time enforcement (validate or mutate actions) and thorough logging. For CTOs and AI architects, building in guardrails means unlocking generative AI’s potential without sacrificing trust or safety. In the enterprise context, robust guardrails at the gateway level are the backbone of responsible AI – they let businesses innovate confidently with LLMs, knowing that every response has been vetted against their security, quality, and compliance rules.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








أحدث الأخبار والمقالات والموارد تصلك مباشرة إلى بريدك الوارد
© 2026 جميع الحقوق محفوظة.







.png)
.webp)










.webp)
