
A TrueFoundry anuncia a aquisição da Seldon AI, expandindo sua Plataforma de Controle para IA Empresarial. Comunicado oficial completo →

Obtenha acesso instantâneo a um ambiente TrueFoundry ao vivo. Implante modelos, direcione o tráfego de LLM e explore a plataforma completa — seu sandbox estará pronto em segundos, sem necessidade de cartão de crédito.










Solução de IA para avaliar e melhorar as habilidades de leitura de crianças em comunidades carentes
A Wadhwani AI é uma organização sem fins lucrativos que trabalha em diversas soluções de IA prontas para uso voltadas a populações carentes em países em desenvolvimento.
Por meio do projeto Vachan Samiksha, a equipe está desenvolvendo uma solução de IA personalizada que professores na Índia rural podem usar para avaliar a fluência de leitura dos alunos e desenvolver um plano de contingência personalizado para melhorar as habilidades de leitura de cada aluno.
A equipe havia implantado a solução em escolas primárias para conduzir pilotos. No entanto, a equipe enfrentava os seguintes problemas, que precisavam ser resolvidos antes de o escopo do projeto ser expandido para mais escolas e alunos:
A equipe da TrueFoundry fez parceria com a equipe para resolver esses problemas. Usando a plataforma TrueFoundry, a equipe conseguiu:
A Wadhwani AI foi fundada por Romesh e Sunil Wadhwani (parte da lista Times100 AI) para aproveitar a IA na resolução de problemas enfrentados por comunidades carentes em nações em desenvolvimento. Eles firmam parcerias com órgãos governamentais e organizações sem fins lucrativos globais em todo o mundo para entregar valor por meio da solução. Como entidade sem fins lucrativos, a Wadhwani AI usa inteligência artificial para resolver problemas sociais nas áreas de agricultura, educação e saúde, entre outras. Alguns de seus projetos incluem:
A Wadhwani AI também trabalha com organizações parceiras para avaliar sua prontidão para IA, ou seja, sua capacidade de criar e usar soluções de IA de forma eficaz e sustentável. O trabalho da Wadhwani AI tem como objetivo usar a IA para o bem e melhorar a vida de bilhões de pessoas em países em desenvolvimento.
As habilidades de leitura são fundamentais para a base educacional de qualquer criança. Infelizmente, muitos alunos das regiões rurais e carentes da Índia e de outras nações em desenvolvimento não possuem essas habilidades. Para resolver esse problema em um nível fundamental, a equipe da Wadhwani AI desenvolveu uma ferramenta de Fluência de Leitura Oral baseada em IA chamada Vachan Samiksha.
A ferramenta usa IA para analisar o desempenho de leitura de cada criança. No momento, ela é voltada principalmente para regiões rurais e semiurbanas do país e está sendo usada em diferentes faixas etárias. Para tornar a solução generalizável para a maior parte do país, a equipe construiu um modelo inclusivo de sotaques para avaliar idiomas regionais e o inglês. A avaliação manual dessas habilidades tem seus vieses e é muitas vezes imprecisa.
A solução é entregue aos usuários (professores das escolas-alvo) por meio de um aplicativo que invoca o modelo implantado na nuvem. O aluno é levado a ler um parágrafo, que é gravado pela aplicação e enviado para a nuvem. Na nuvem, o modelo avalia a precisão de leitura, a velocidade, a compreensão e outros atrasos de aprendizagem complexos que poderiam passar despercebidos em uma avaliação normal. Além de avaliar essas habilidades, a aplicação também cria um plano de aprendizagem personalizado para cada aluno, a fim de facilitar seu aprendizado, e também gera relatórios demográficos para ações em nível macro pelas autoridades governamentais. A equipe havia implantado o modelo para o piloto com o serviço gerenciado de ML do provedor de nuvem
Quando começamos nossa colaboração com a equipe da Vachan Samiksha dentro da Wadhwani AI, a equipe vinha aproveitando a stack nativa de MLOps de seu provedor de nuvem para implantar o modelo em seu piloto com o Departamento de Educação de Gujarat.
A configuração de infraestrutura deles era a seguinte:

A equipe enfrentou desafios com essa configuração ao tentar conduzir o primeiro piloto, o que a motivou a experimentar outras soluções:
Esperava-se que o piloto rodasse em uma escala enorme (~6 milhões de alunos em um mês). No entanto, a equipe não tinha confiança de que o serviço gerenciado de ML conseguiria suportar essa escala porque:
Durante o piloto, a equipe enfrentou problemas com a velocidade de escalonamento, e alguns pods não subiram como esperado. No entanto, para resolver o problema, a equipe contatava os representantes do provedor de nuvem, que então contatavam a equipe técnica. Isso gerava um atraso no sistema e causava atraso no piloto.
Quando o tráfego de requisições aumentava durante o piloto, os pods precisavam escalar horizontalmente (subir novos nodes que pudessem retirar e processar parte das requisições da fila). Esse processo levava cerca de 9-10 minutos para cada novo pod que era criado, resultando em respostas atrasadas e em uma experiência ruim para o usuário final.
As instâncias de GPU são muito caras devido à escassez global de chips. Some a isso o markup de 20-40% para instâncias de ML que o provedor de nuvem aplica. Isso tornava o custo das instâncias muito alto e inviável para a equipe na escala em que queriam rodar o projeto.
Quando conhecemos a equipe da Vachan Samiksha, eles estavam no período entre o primeiro piloto e o segundo. O piloto estava a menos de uma semana de distância e tínhamos de:

Durante o período anterior ao piloto:
Nossa equipe ajudou a equipe da Wadhwani AI a instalar a plataforma em seu próprio Kubernetes puro. O control plane e o cluster de workload foram ambos instalados em sua própria infraestrutura. Todos os dados, os elementos de UI para interagir com a plataforma e os processos de workload para treinar/implantar os modelos permaneceram dentro de sua própria VPC. A plataforma também cumpriu todas as regras e práticas de segurança da empresa.
Ajudamos a equipe a entender como os diferentes componentes interagem durante o processo de treinamento e onboarding. Nós os guiamos sobre como configurar recursos, configurar o autoscaling e implantar o modelo.
A equipe da Wadhwani AI conseguiu migrar a aplicação por conta própria com ajuda mínima da equipe da TrueFoundry. Isso foi feito em uma chamada de 1 hora com a equipe.
Depois que a aplicação foi implantada, a equipe começou a testar carga de nível de produção nela. A equipe escalou de forma independente a aplicação para mais de 100 nodes por meio de um simples argumento na UI da TrueFoundry, o que é 5X a maior escala que conseguiam atingir anteriormente. Eles também tentaram fazer o benchmark da velocidade de escalonamento de nodes, que foi muito (3-4X) mais rápida do que a fornecida pelo serviço anterior.
Com os testes de carga concluídos, a equipe implantou a aplicação do piloto e se preparou para lançá-la na segunda fase do piloto, que foi disponibilizada para 1.000 escolas, 9.000 professores e mais de 200 mil alunos.
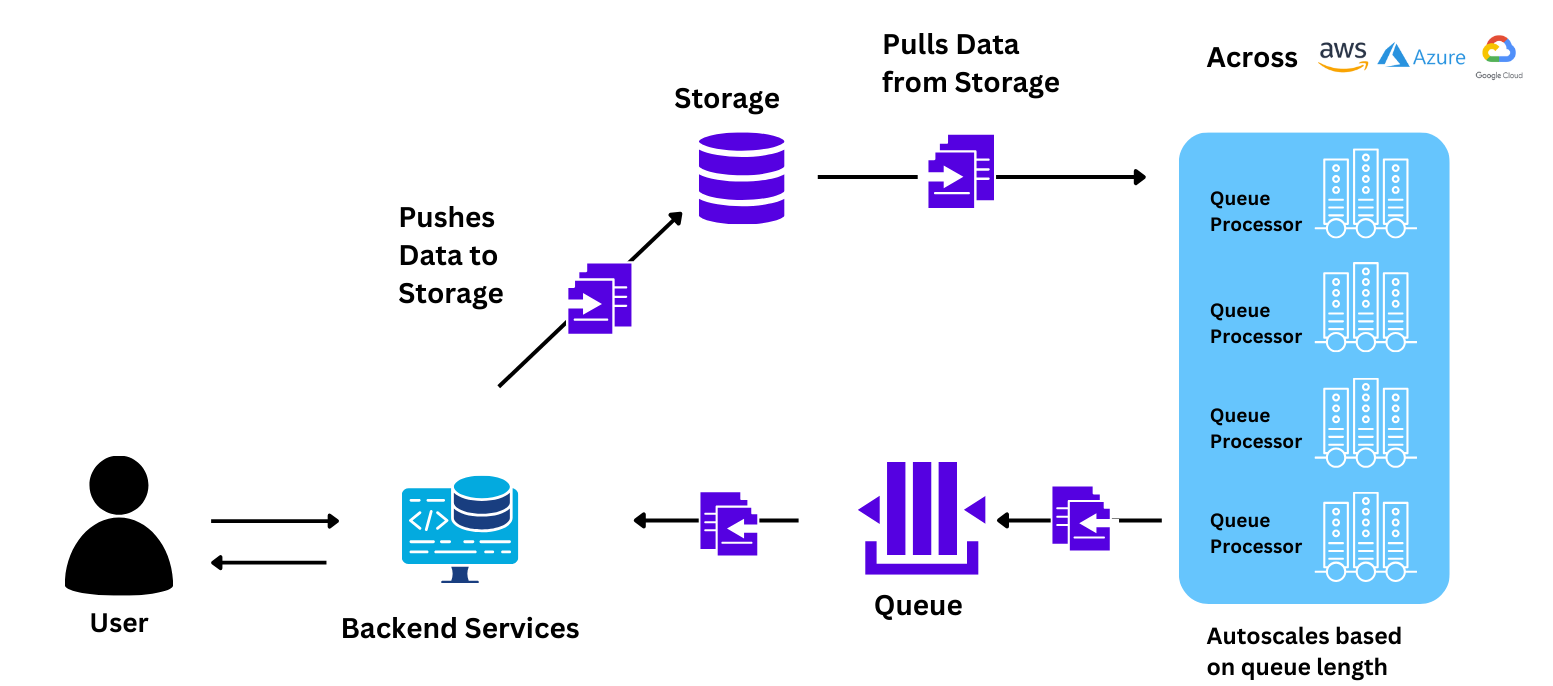
Com um esforço mínimo de menos de 10 horas, a equipe da Wadhwani AI conseguiu obter uma melhora significativa em velocidade, controle e custos. Algumas das principais mudanças que obtiveram foram:
Os cientistas de dados e engenheiros de machine learning conseguiram configurar vários elementos que antes eram difíceis de fazer pelo console do provedor de nuvem ou para os quais tinham de depender da equipe de engenharia:
Com base no comprimento da fila e aumentando o número máximo de réplicas/nodes para 70, em vez do limite anterior de 20
Como a maior parte do tráfego do piloto chegava durante o horário escolar, quando os professores interagiam com os alunos, havia poucas requisições, se é que havia, durante a noite. A equipe conseguiu configurar uma agenda de escalonamento com a qual os pods reduziam ao mínimo durante as horas de baixo movimento (noite). Isso economizou cerca de 15-20% do custo do piloto.
A equipe podia monitorar facilmente o tráfego, a utilização de recursos e as respostas diretamente pela UI da TrueFoundry. Eles também recebiam sugestões pela plataforma sempre que havia um superprovisionamento ou subprovisionamento de recursos
Para testar o escalonamento com a TrueFoundry, a equipe enviou uma rajada de 88 requisições à aplicação e fez o benchmark do desempenho do serviço gerenciado de ML do provedor de nuvem vs. a TrueFoundry. Todas as configurações do sistema foram mantidas iguais, como a lógica de escalonamento (com base no comprimento da fila de backlog, o número inicial de nodes, o tipo de instância etc.)
Percebemos que a TrueFoundry conseguia escalar 78% mais rápido do que o serviço gerenciado de ML, o que dava ao usuário respostas muito mais rápidas. O tempo de ponta a ponta para responder à consulta foi 40% menor com a TrueFoundry.
O custo que a equipe estava tendo com o piloto foi reduzido em cerca de 50% ao migrar para a TrueFoundry; isso foi viabilizado pelos seguintes fatores contribuintes:
Enquanto o serviço gerenciado de ML era limitado pela disponibilidade de instâncias de GPU na mesma região do provedor de nuvem, a TrueFoundry pode adicionar worker nodes ao sistema que podem estar em qualquer região ou provedor de nuvem.
Isso significa que:
A TrueFoundry oferece integração fluida com qualquer ferramenta que a equipe queira usar. Com o provedor de nuvem, isso era limitado pelas escolhas de design feitas pelo provedor e por suas integrações nativas. Por exemplo, a equipe queria usar o NATS para publicar mensagens, o que o serviço nativo do provedor de nuvem não oferecia no momento. A TrueFoundry tornou trivial para a equipe da Wadhwani AI fazer esse tipo de escolha.







As últimas notícias, artigos e recursos enviados para sua caixa de entrada
© 2026 Todos os direitos reservados.



