Create a virtual model
Open Virtual Models in AI Gateway
From the TrueFoundry dashboard, go to AI Gateway → Models → Virtual Model.
Virtual models live inside Virtual Model Provider Groups. You can add models to an existing group or create a new group when you start.
Create or select a provider group and set access controls
Give the group a unique name (3–64 characters, alphanumeric and hyphens, cannot start with a number). Configure collaborators: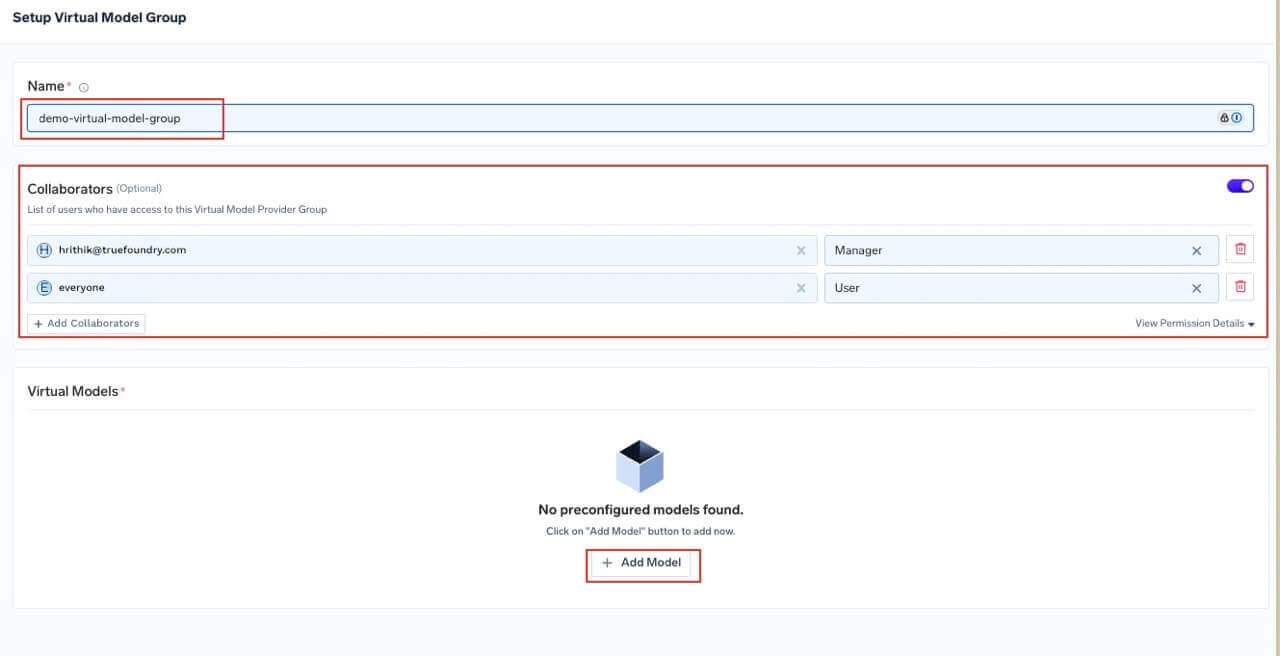
- User — May call the virtual models in this group for inference.
- Manager — May change virtual model configuration.
Define the virtual model, strategy, and targets
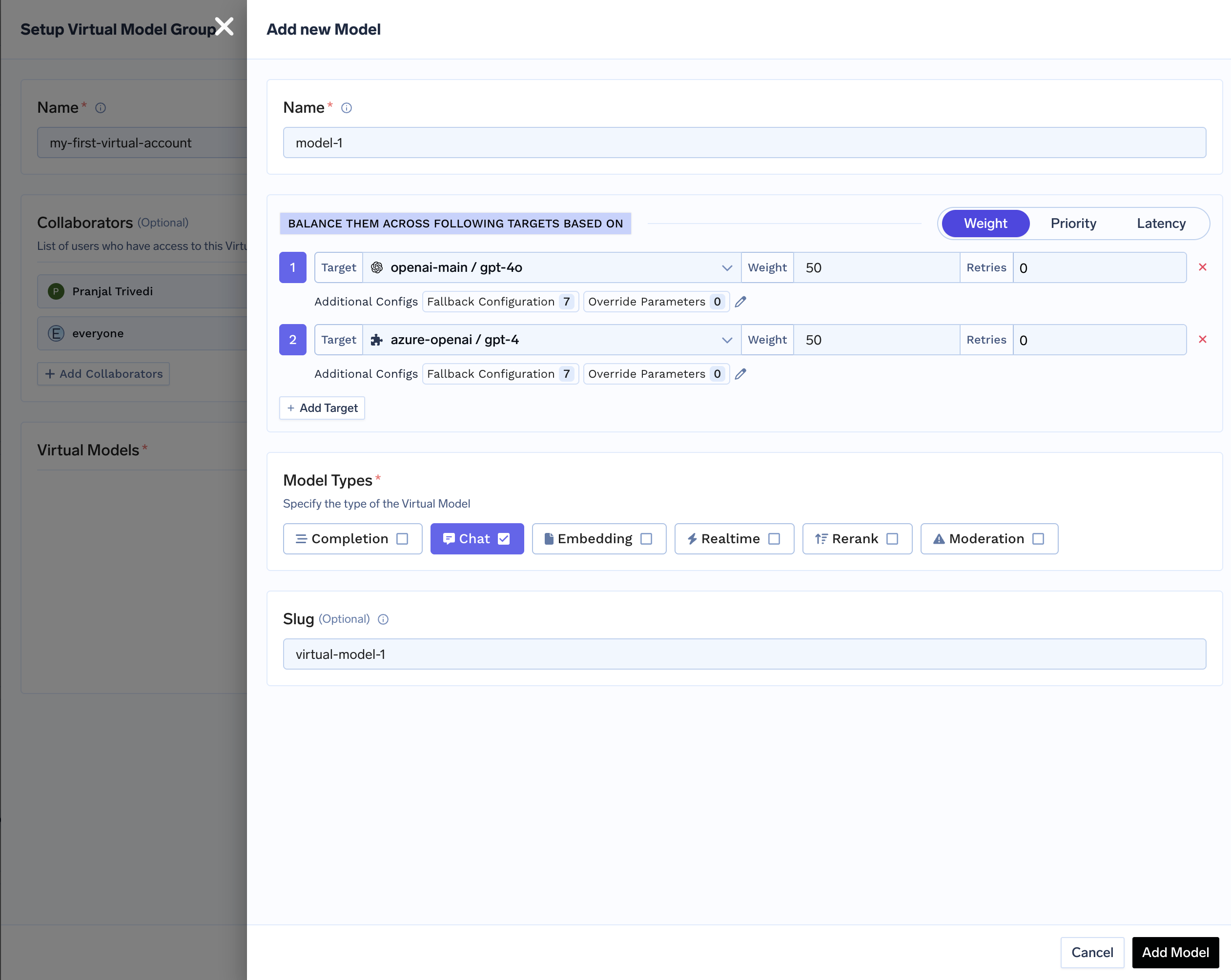
For each virtual model in the group, set: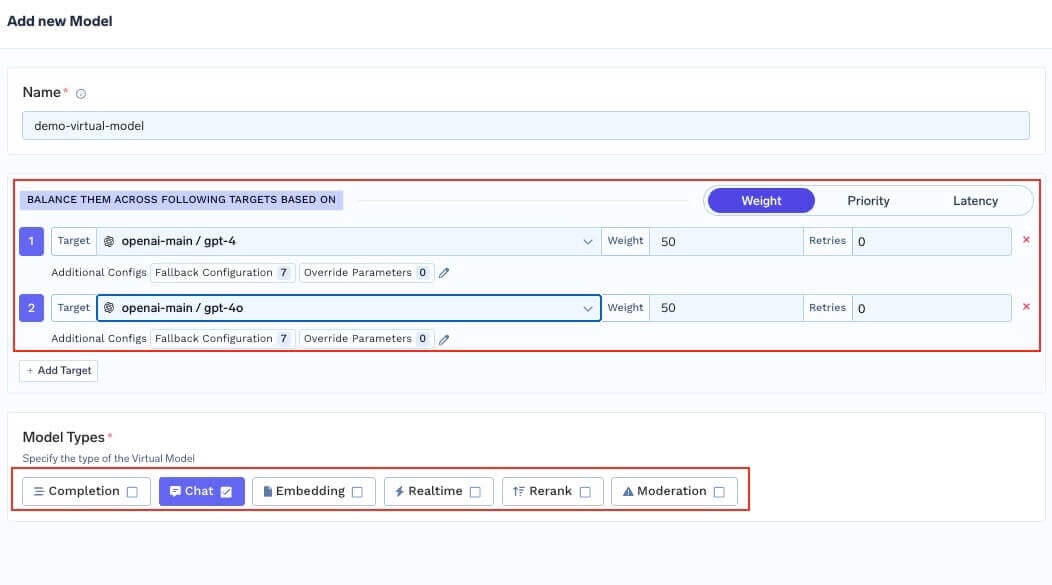
-
Name — Identifier used in the full path
group-name/virtual-model-name(for examplegpt-4-production). - Model types — Operation kinds this virtual model supports — chat, completion, embedding, rerank, moderation, and the audio types (text to speech, audio transcription, audio translation). All targets must support the operation you invoke.
-
Routing strategy — Choose one of three strategies:
For how each strategy works, see the overview.
Strategy When to use Weight-based Canaries, fixed capacity splits, A/B allocation. Assign weights that sum to 100. Latency-based Automatic performance chasing. No weights needed — the gateway picks the fastest. Priority-based Primary + backup topologies. Assign priority numbers (0 = highest). -
Target models — For each target, configure:
Field Description Target A real model from the catalog (not another virtual model). Weight Traffic share (weight-based only). Weights across targets should sum to 100. Priority Priority level (priority-based only). Lower number = higher priority. Retry config Attempts, delay (ms), and status codes that trigger retries. Defaults: 2 attempts, 100 ms delay, retry on 429,500,502,503.SLA cutoff Priority-based only. Per-target latency thresholds ( time_per_output_token_ms,time_to_first_token_ms); a target is marked unhealthy when either configured metric is breached over a 3-minute rolling window. See SLA cutoff.Fallback status codes HTTP codes that cause fallback to another target. Defaults: 401,403,404,429,500,502,503.Fallback candidate Whether this target may receive traffic when another target fails. Default: true.Override parameters Per-target request parameters like temperature,max_tokens, orprompt_version_fqnfor model-specific prompts.Header overrides Inject or remove HTTP headers for this target only. Use setto add/overwrite headers andremoveto strip them. See header overrides.prompt_version_fqnoverride does not apply when using agents with MCP/tools; it is supported for standard chat completion requests. - Slug (optional) — Short global alias for this virtual model. See Slugs.
Configure the slug in the Virtual Model Provider Group settings. Slugs must be unique across all virtual models in the tenant.
Common patterns
The following YAML sketches show therouting_config shape used inside a virtual model. In the dashboard, the same fields are set in the UI.
Priority chain — fail over when rate limited
Priority chain — fail over when rate limited
Canary rollout with weights
Canary rollout with weights
On-prem primary with cloud fallback
On-prem primary with cloud fallback
Audio (STT) failover across providers
Audio (STT) failover across providers
Route speech-to-text traffic to a primary provider and fall back to a second provider on failure. Set the virtual model’s Model types to Call the virtual model from your application the same way you’d call any STT model — pass the virtual model’s full path as
audio_transcription so it can be called on POST /audio/transcriptions. The same shape works for text_to_speech and audio_translation — just swap the targets and model type.model:Latency race with limited retries per target
Latency race with limited retries per target
Different prompt versions per provider
Different prompt versions per provider
Sticky routing for multi-turn conversations
Sticky routing for multi-turn conversations
Region-based routing using SaaS gateway metadata
Region-based routing using SaaS gateway metadata
Route to region-specific model deployments based on which SaaS gateway handled the request. The gateway automatically adds US gateway traffic goes to the Azure US deployment, EU traffic to Azure EU, and everything else falls back to OpenAI. See Metadata Keys for all available region and zone values.
tfy_gateway_region and tfy_gateway_zone to request metadata — no client changes needed.Per-target header overrides
Per-target header overrides
Inject or remove headers on specific targets — useful when one provider needs extra headers the others don’t.
Metadata filtering with enterprise tier routing
Metadata filtering with enterprise tier routing
Route enterprise-tier traffic to a dedicated deployment while standard traffic uses a shared pool.Requests with
x-tfy-metadata: {"tier":"enterprise"} go exclusively to the dedicated Azure deployment. All other requests are split 60/40 between OpenAI and the shared Azure deployment.Priority chain with SLA cutoff and retries
Priority chain with SLA cutoff and retries
Full configuration using priority-based routing with SLA thresholds, custom retries, and controlled fallback eligibility.
Environment- or segment-specific routing
Use different virtual model names per environment or segment (for examplebooking-app/gpt-prod vs booking-app/gpt-dev) and have your client pass the appropriate model. You can still send metadata and headers for observability, rate limits, and other gateway features; routing for a given virtual model name is always defined on that virtual model.
Use a virtual model from your application
Once created, use the full pathvirtual-model-group-name/virtual-model-name as the model value in API requests — it works like any other model in the gateway.
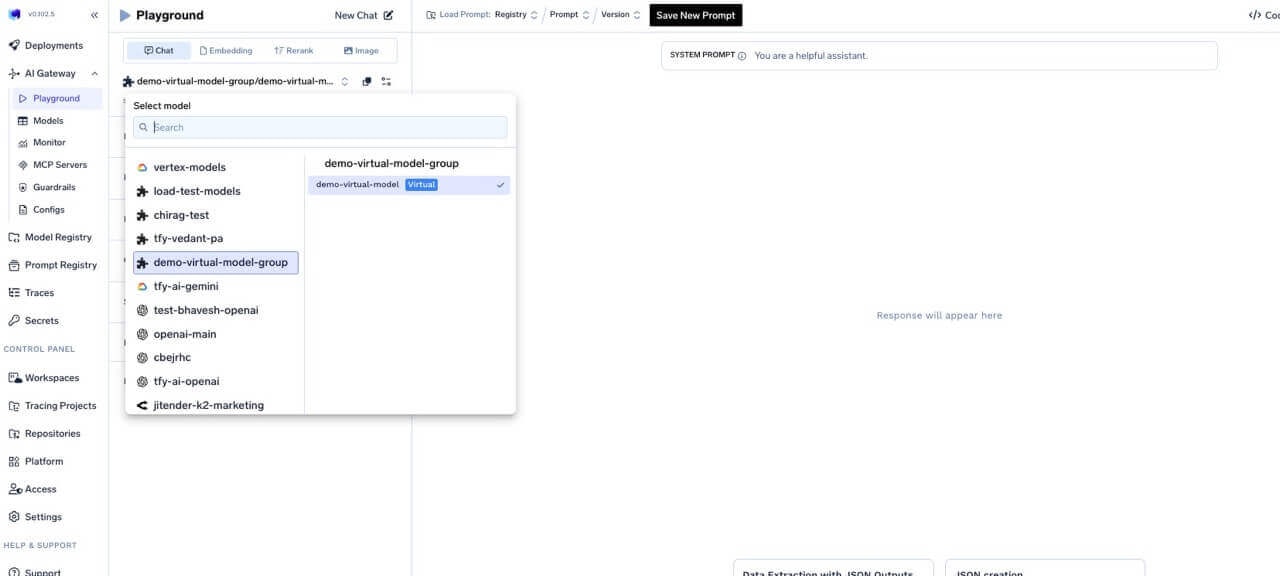
Try in the Playground
- Click Try in playground on the virtual model row after creation, or
- Open the Playground and pick the virtual model from the model dropdown.
Virtual model slugs
Slugs are optional short names that refer to a single virtual model. They are unique across the tenant. You can use either the slug or the fullgroup/model path in requests.
my-first-virtual-account/model-1 with slug virtual-model-1, both bodies are valid: