




July 4, 2026
|
5 min read


احصل على وصول فوري إلى بيئة TrueFoundry مباشرة. انشر النماذج، ووجّه حركة مرور LLM، واستكشف المنصة بالكامل — بيئة الاختبار الخاصة بك جاهزة في ثوانٍ، ولا يلزم وجود بطاقة ائتمان.









Published: July 4, 2026

Blazingly fast way to build, track and deploy your models!
لا يوجد نموذج واحد يتفوق في كل مهمة. يتعامل GPT-4o مع الاستدلال المعقد بشكل جيد، بينما غالبًا ما تتعامل نماذج اللغة الأصغر مع التصنيف والتوجيه والاستخراج بتكلفة أقل. توجيه كل طلب إلى النموذج الأكثر تكلفة يؤدي إلى إنفاق غير ضروري ويضعف تخصيص الموارد عبر فرق الذكاء الاصطناعي للإنتاج.
يعمل تنسيق النماذج المتعددة على تفعيل هذا التمييز. بدلاً من ربط كل عبء عمل بمزود واحد، يقوم بتوجيه الطلبات عبر نماذج مختلفة بناءً على نوع المهمة والتكلفة وزمن الاستجابة ومتطلبات الجودة. بالنسبة لفرق الإنتاج، لم يعد هذا تحسينًا ضيقًا. بل أصبح الطبقة التشغيلية للذكاء الاصطناعي في المؤسسات.
تدير الشركات الآن تطبيقات الذكاء الاصطناعي عبر OpenAI وAnthropic وGoogle وAzure وAWS Bedrock والنماذج المستضافة ذاتيًا. لقد تحول تنسيق نماذج اللغة الكبيرة المتعددة (LLM) من نمط توجيه مفيد إلى متطلب أساسي للبنية التحتية. يشرح هذا الدليل كيفية عمله، وما لا يمكنه حله بمفرده، وكيف تضيف TrueFoundry الحوكمة عبر طبقة بوابة المؤسسة.
تنسيق النماذج المتعددة هو ممارسة ربط تطبيق أو وكيل ذكاء اصطناعي واحد أو سير عمل بنماذج ذكاء اصطناعي متعددة. ثم تقوم طبقة التنسيق بتوجيه كل طلب إلى النموذج الذي يناسب المهمة المحددة أو هدف التكلفة أو متطلب زمن الاستجابة أو عتبة الجودة.
يشمل المصطلح كلاً من التوجيه الثابت والديناميكي. يقوم التوجيه الثابت بتعيين مهام مختلفة لنماذج محددة مسبقًا. يمكن أن تذهب الملخصات إلى نموذج فعال من حيث التكلفة، ويمكن أن تذهب إكمال التعليمات البرمجية إلى نموذج برمجي، ويمكن أن يذهب البحث المتعمق إلى نموذج استدلال أقوى.
التوجيه الديناميكي يقوم بتقييم مدخلات المستخدم في وقت التشغيل. يمكن لمحرك التنسيق فحص التعقيد، وصحة المزود، وزمن الاستجابة، والتكلفة، وسياسات التوجيه المتاحة قبل الإرسال. تستخدم معظم الأنظمة الواقعية كلا النهجين لتحقيق التوازن بين السرعة والجودة والمرونة والتكلفة.
في كلتا الحالتين، يقع المنسق المركزي بين التطبيق والنماذج الأساسية. يقوم بتجريد واجهات برمجة التطبيقات الخاصة بالمزودين، ويتعامل مع التوجيه، ويوحد الاستجابات، ويدير تجاوز الفشل. يحتوي تطبيقك على نقطة دخول واحدة، بينما تدير البوابة اختيار النموذج وسلوك المزود.
أصبح تنسيق النماذج المتعددة ضروريًا لأن أعباء عمل الذكاء الاصطناعي تختلف الآن بشكل حاد من حيث التكلفة والمخاطر والتعقيد وزمن الاستجابة. لا يحتاج روبوت الدردشة الذي يجيب على استفسارات العملاء البسيطة إلى نفس النموذج الذي يحتاجه وكيل يتعامل مع قرارات منظمة أو توليد تعليمات برمجية معقدة.
تعمل النماذج الرائدة على تحسين جودة الاستدلال واتساعه. تعمل نماذج اللغة الأصغر على تحسين السرعة والتكلفة في المهام المحددة جيدًا. ربط كل عبء عمل بمستوى واحد يترك قيمة حقيقية غير محققة على كلا الطرفين.
توجيه كل حركة المرور إلى نماذج اللغة الكبيرة الرائدة افتراضيًا يعني دفع مبالغ زائدة على حصة كبيرة من الطلبات. يمكن لنموذج أصغر الإجابة على العديد من المطالبات الروتينية بنفس الدقة وبأوقات استجابة أسرع. العكس يخلق مشكلة مختلفة، لأن التوحيد على نموذج أرخص يمكن أن يتسبب في عودة مطالبات صعبة حقًا باستجابات سطحية أو غير صحيحة.
إذا سبق لك أن شاهدت رسمًا بيانيًا للإنفاق يرتفع بدون محرك واضح، فإن السبب غالبًا ما يكون بسيطًا. نموذج افتراضي واحد، وقاعدة توجيه واحدة، ولا توجد طريقة لإرسال العمل الأسهل إلى مكان أرخص. تنسيق النماذج المتعددة هو الحل الهيكلي لأنه يطابق كل مهمة محددة بالنموذج الصحيح.
يعاني مزودو واجهات برمجة تطبيقات نماذج اللغة الكبيرة (LLM) من انقطاعات، وحدود للمعدل، وتدهور في الأداء يؤثر بشكل مباشر على تطبيقات الإنتاج. تستشهد وثائق بوابة TrueFoundry الخاصة بصفحات حالة OpenAI وAnthropic من فبراير حتى مايو 2025، مما يظهر حوادث متكررة على مدى أربعة أشهر.
هذه ليست حالة استثنائية. بل هي بيئة التشغيل لأنظمة الذكاء الاصطناعي التوليدية في الإنتاج.
يوجه تنسيق النماذج المتعددة مع تجاوز الفشل التلقائي أعباء عمل الإنتاج إلى مزود متاح عندما تتدهور نقطة النهاية الأساسية. يظل التطبيق متاحًا دون الحاجة إلى تدخل بشري أو تغييرات عاجلة من مهندس المناوبة. النمط هو نفسه لأي تبعية حرجة: التكرار، فحوصات السلامة، والعودة التلقائية.
لا يمكن للشركات الخاضعة للتنظيم إرسال كل طلب إلى كل نموذج. تتضمن بعض أعباء العمل بيانات حساسة، أو معلومات حساسة، أو سجلات عملاء، أو قيود بيانات إقليمية. في هذه الحالات، يجب أن تأخذ قرارات التوجيه في الاعتبار قواعد السياسة، وليس فقط التكلفة أو زمن الاستجابة.
يمكن لطبقة التحكم المحكومة توجيه الطلبات بناءً على البيانات الوصفية، أو الموقع الجغرافي، أو الفريق، أو البيئة، أو فئة البيانات. هذا مهم عندما تحتاج البيانات الخارجية، أو مجموعات البيانات الخاصة، أو سير العمل المقيدة إلى البقاء ضمن الحدود المعتمدة.
في حالة TrueFoundry، يمكنك إرفاق قواعد metadata_match بهدف بحيث لا يستقبل حركة المرور إلا عندما تتطابق البيانات الوصفية للطلب (أو وسم tfy_gateway_region الخاص بالبوابة) مع قيمة مهيأة، مع هدف شامل لأي منطقة غير معينة بشكل صريح.
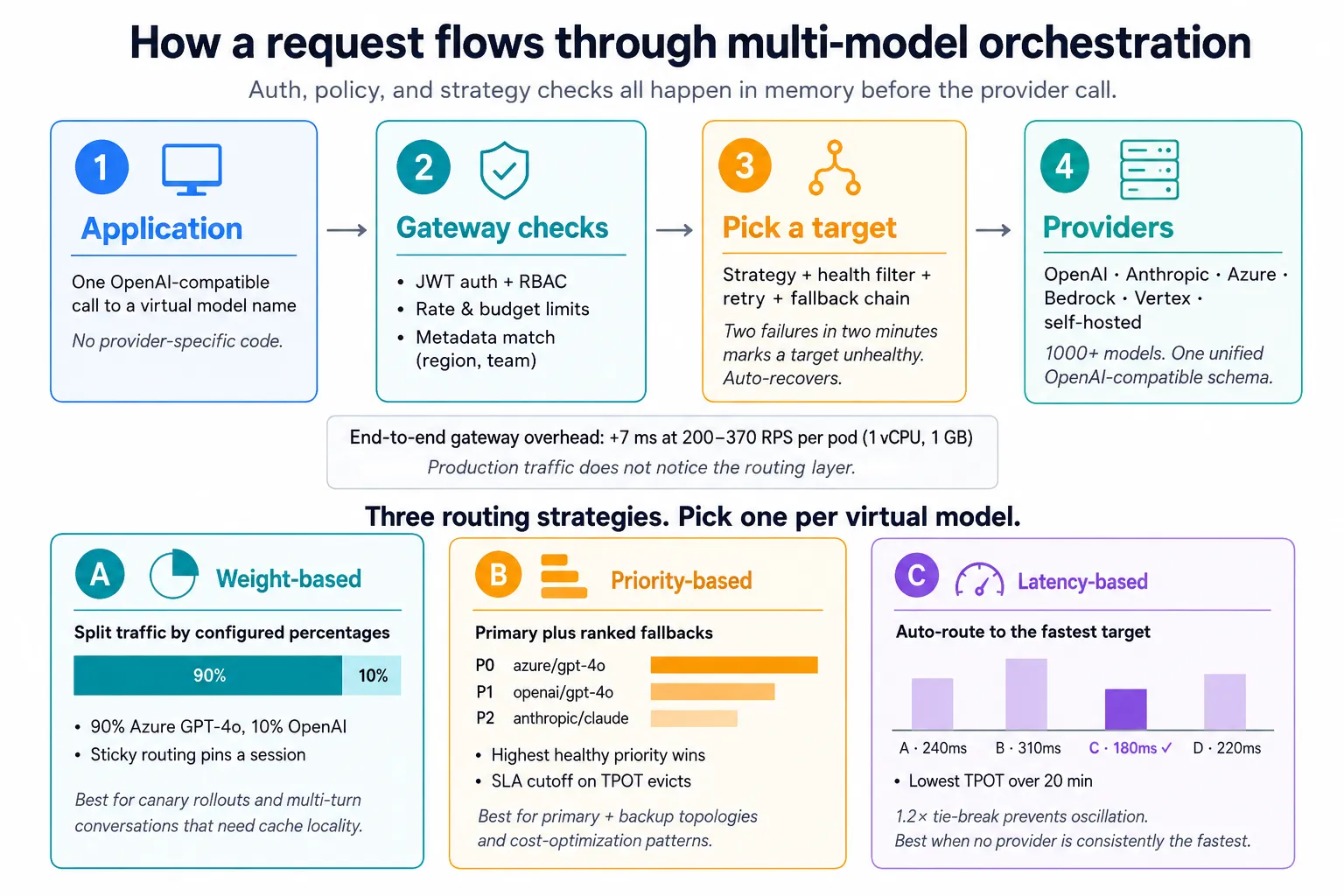
يعتمد تنسيق النماذج المتعددة عادةً على أربعة مكونات أساسية: طبقة واجهة برمجة تطبيقات موحدة، منطق التوجيه، سلاسل تجاوز الفشل، وتطبيع الاستجابة. معًا، تساعد الفرق على استخدام مزودين متعددين دون ترميز كل عملية تكامل بشكل ثابت داخل رمز التطبيق.
يستخدم كل مزود تنسيقات طلبات مختلفة، وأسماء معلمات، ورموز خطأ، وهياكل استجابة. يقوم إطار عمل تنسيق الذكاء الاصطناعي بتطبيع هذه الاختلافات خلف واجهة برمجة تطبيقات واحدة. وهذا يمنح التطبيقات واجهة متسقة عبر النماذج المستضافة، ومفتوحة المصدر، والمستضافة ذاتيًا.
بوابة LLM الخاصة بـ TrueFoundry LLM Gateway تعرض مخططًا متوافقًا مع OpenAI عبر أكثر من 1000 نموذج. يتيح ذلك للفرق إضافة أو تبديل المزودين دون تغيير كل خدمة تابعة. كما يبسط هندسة الأوامر، والاختبار، وإدارة النشر عبر الفرق.
تعمل طبقة واجهة برمجة التطبيقات الموحدة هذه أيضًا على تحسين سهولة الاستخدام للمطورين وفرق المنصات. إنها تبسط هندسة الأوامر، واختبار التكامل، وإدارة النشر عبر التطبيقات المختلفة. بدلاً من بناء منطق منفصل خاص بالمزودين عبر الخدمات، تستخدم الفرق نقطة دخول واحدة متسقة للوصول إلى النماذج.
هنا يكتسب تنسيق النماذج المتعددة اسمه. تدعم النماذج الافتراضية لـ TrueFoundry ثلاث استراتيجيات توجيه، وتختار واحدة لكل نموذج افتراضي:
في TrueFoundry، يبدو تكوين النموذج الافتراضي النموذجي الأساسي مع الاحتياطي كما يلي:
routing_config:
type: priority-based-routing
load_balance_targets:
- target: azure/gpt-4o
priority: 0
retry_config:
attempts: 3
delay: 200
on_status_codes: ["429", "500", "503"]
fallback_status_codes: ["429", "500", "502", "503"]
- target: openai/gpt-4o
priority: 1
retry_config:
attempts: 2
delay: 100
- target: anthropic/claude-sonnet
priority: 2
fallback_candidate: false
في هذا التكوين، تنتقل الطلبات أولاً إلى azure/gpt-4o. وفقًا لكتلة retry_config الخاصة به، تعيد البوابة المحاولة حتى 3 مرات مع تأخير 200 مللي ثانية عند أخطاء تجاوز الحد الأقصى للمعدل قبل الانتقال إلى openai/gpt-4o. يعمل هدف Anthropic فقط عندما يكون الهدف الصحي ذو الأولوية القصوى، ولا يعمل أبدًا كخيار احتياطي للهدفين الآخرين.
كل هذا موجود في الذاكرة.
لا توجد استدعاءات خارجية في مسار الطلب.
تدعم أنماط التوجيه هذه تطبيقات متنوعة، بما في ذلك خدمة العملاء، ودعم العملاء، وحل النزاعات، ومساعدي البرمجة، وسير عمل الامتثال، والمساعدين الداخليين للمؤسسات.
تحدد سلاسل تجاوز الفشل قائمة مزودين مرتبة حسب الأولوية لكل قاعدة توجيه. عندما يُرجع المزود الأساسي رمز حالة احتياطيًا (الافتراضيات في TrueFoundry: 401، 403، 404، 429، 500، 502، 503)، تحاول البوابة الهدف المؤهل التالي بدلاً من تمرير الخطأ إلى التطبيق.
هذا النمط مفيد بشكل خاص لسير العمل المعقدة والوكلاء المستقلين. عندما يعتمد الوكيل على استدعاءات نماذج متعددة، يمكن أن يؤدي فشل مزود واحد إلى تعطيل سير العمل. يحمي تجاوز الفشل التلقائي التجربة دون الحاجة إلى تدخل بشري.
توجد أيضًا منطق إعادة المحاولة على نفس الهدف قبل تفعيل أي خيار احتياطي. الإعدادات الافتراضية للبوابة هي محاولتان مع تأخير 100 مللي ثانية عند الأخطاء 429، 500، 502، 503. يمكن لكل هدف تجاوز هذه الإعدادات الافتراضية داخل كتلة retry_config الخاصة به. في ملف YAML أعلاه، يتجاوز azure/gpt-4o هذه الإعدادات الافتراضية إلى 3 محاولات عند 200 مللي ثانية، بينما يضبط openai/gpt-4o صراحةً على محاولتين عند 100 مللي ثانية (مطابقًا للإعدادات الافتراضية). لا يحتوي anthropic/claude-sonnet على كتلة retry_config، لذا فهو يرث الإعدادات الافتراضية. وتتتبع البوابة حالات الفشل باستمرار. إذا تعرض هدف لفشلين أو أكثر خلال نافذة متجددة مدتها دقيقتان، يتم وضع علامة عليه بأنه غير صحي ويتم تخطيه حتى تزول الأخطاء، مع استعادة تلقائية. لا يوجد تدخل بشري، ولا تعديلات يدوية على التكوين عند انتهاء الانقطاع.
تُرجع النماذج المختلفة استجابات بأشكال مختلفة، مع بيانات وصفية مختلفة، وأسباب انتهاء، وتنسيقات عدد الرموز. تعمل طبقة التنسيق على توحيد كل ذلك. يقرأ الكود الخاص بك نفس بنية الاستجابة سواء ذهب الطلب إلى OpenAI أو Anthropic أو Llama مستضاف ذاتيًا.
لأغراض التصحيح، تُرجع TrueFoundry الهدف الفعلي الذي خدم الطلب في رأس استجابة x-tfy-resolved-model، بحيث يمكنك تتبع النموذج الذي أنتج أي مخرج معين حتى عندما يغطي اسم النموذج الافتراضي عشرة أهداف محتملة. هذه الرؤية مهمة عندما تحقق في تراجع في الجودة وتحتاج إلى معرفة ما إذا كان تكوين التوجيه الثابت الخاص بك أبقى المستخدم على نفس المزود أو انتقل إلى مزود آخر في منتصف الجلسة.
تخلق أوركسترا النماذج المتعددة قيمة عندما تربط الفرق قرارات التوجيه بالنتائج التجارية. الهدف ليس استخدام المزيد من النماذج. الهدف هو تطبيق النموذج الصحيح على كل طلب مع تحسين التكلفة والجودة والتوافر والامتثال والحوكمة.
على سبيل المثال، يمكن لسير عمل الدعم توجيه استفسارات العملاء الروتينية إلى نموذج أصغر. ويمكنه إرسال نزاعات الفواتير المعقدة أو حالات الدعم الفني إلى نموذج أقوى. هذا يحسن التحكم في التكلفة دون إضعاف جودة الإجابة.
في حالة استخدام أخرى، يمكن لمساعد البحث في المؤسسة استخدام نموذج واحد لفهم اللغة الطبيعية، وآخر لاسترجاع البيانات، وآخر لتوليد اللغة الطبيعية. يقرر منطق التنسيق أي نموذج أو وكيل يساهم في الإجابة النهائية.
تمنح هذه البنية المؤسسات ميزة تنافسية لأن اختيار النموذج يصبح عمليًا. يمكن للفرق تعديل قواعد التوجيه، واختبار المزودين، وتقليل التكاليف، وتحسين جودة الاستجابة دون إعادة بناء كل تطبيق ذكاء اصطناعي.
التوجيه وحده لا يمثل حوكمة.
تبني العديد من الفرق أجهزة التوجيه الخاصة بها، وتتقن حسابات موازنة التحميل، ومع ذلك تجد نفسها أمام أربع مشكلات لم تخطط لها.
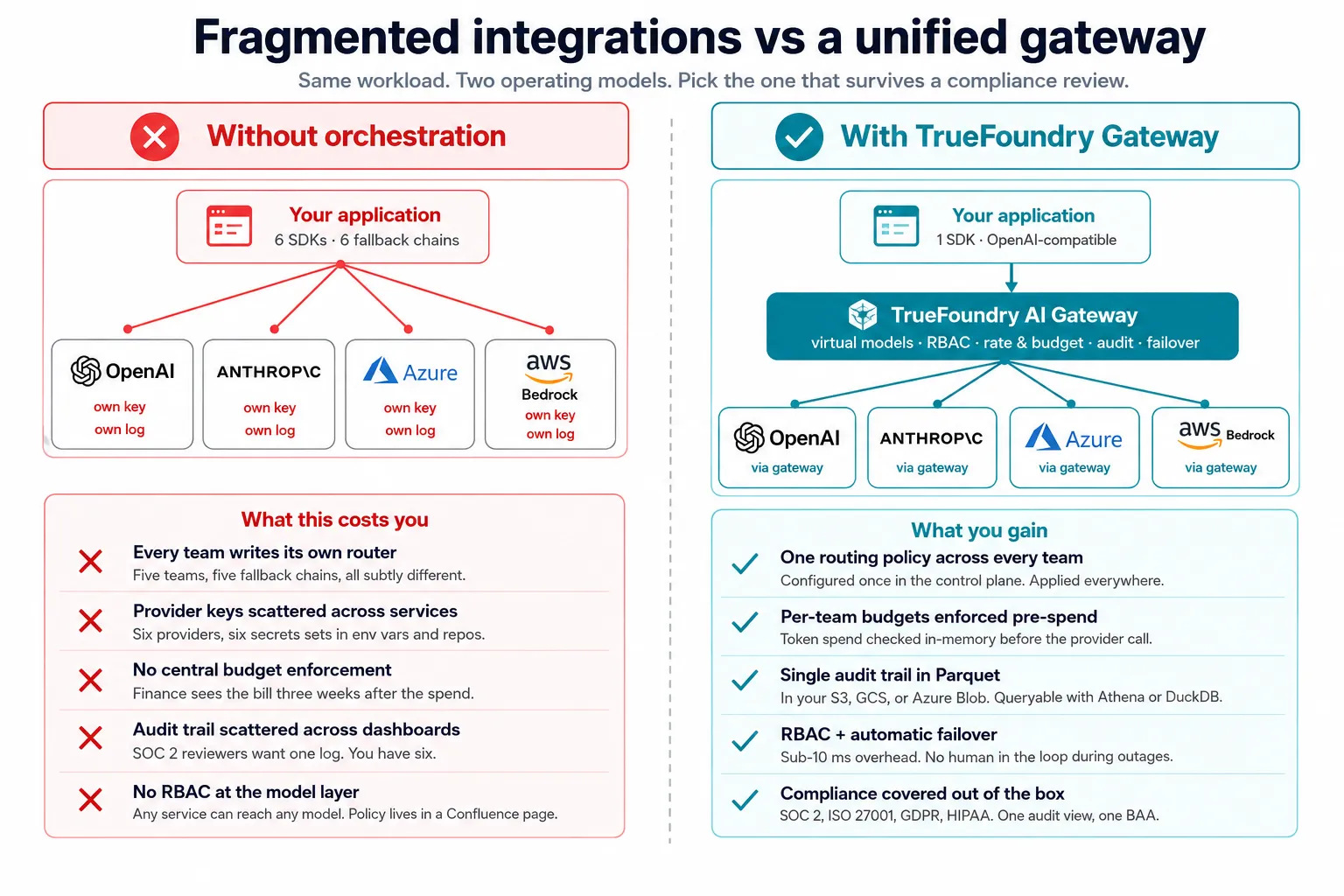
التوجيه لكل تطبيق يعني أن كل فريق يكتب نسخته الخاصة من نفس المنطق. خمسة فرق، خمس سلاسل احتياطية مختلفة بشكل طفيف، خمس مجموعات من مفاتيح المزودين تطفو في متغيرات البيئة. يتفاقم هذا التناقض على نطاق المؤسسة ويحول "لدينا تنسيق متعدد النماذج" إلى "كل فريق لديه تنسيق متعدد النماذج".
لا يفرض أي إطار عمل للتوجيه حدود ميزانية لكل فريق قبل تنفيذ الطلبات. يتراكم إنفاق الرموز عبر كل مزود موجه. وبحلول الوقت الذي تسأل فيه الإدارة المالية عن سبب تضاعف فاتورة OpenAI ثلاث مرات، تكون محادثة الميزانية قد جرت بالفعل، متأخرة بثلاثة أسابيع.
يخلق التوجيه متعدد المزودين مشكلة تدقيق متعددة المزودين. سجلات في لوحة تحكم OpenAI، سجلات في وحدة تحكم Anthropic، سجلات في بوابة Azure. لا يربط أي منها معًا في مسار تدقيق موحد ومنسوب للمستخدم الذي SOC 2 و HIPAA ترغب المراجعات في رؤيته بالفعل.
التوفر ليس هو نفسه التحكم في الوصول. يعني تجاوز الفشل أن أي مزود سليم يمكنه تلبية طلب. بدون التحكم في الوصول المستند إلى الدور (RBAC) عند البوابة، قد يصبح أي مزود سليم متاحًا أيضًا للمهندسين أو وكلاء الذكاء الاصطناعي الذين لا ينبغي لهم الوصول إليه. إذا كان يجب ألا يصل طلب تسويقي أبدًا إلى نموذج معتمد فقط لسير العمل السريري، فيجب أن تكون السياسة موجودة عند البوابة، وليس في صفحة Confluence.
هنا تصبح هندسة السياق وإدارة الحالة أيضًا من الشواغل التشغيلية. قد يسترد النظام معلومات ذات صلة من مصادر البيانات، وأنظمة قواعد المعرفة، وقواعد بيانات المتجهات، ومصادر البيانات الخارجية. بدون طبقة تحكم محوكمة، يمكن للنظام بأكمله أن يكشف عن معلومات أو يوجه الطلبات بشكل غير صحيح.
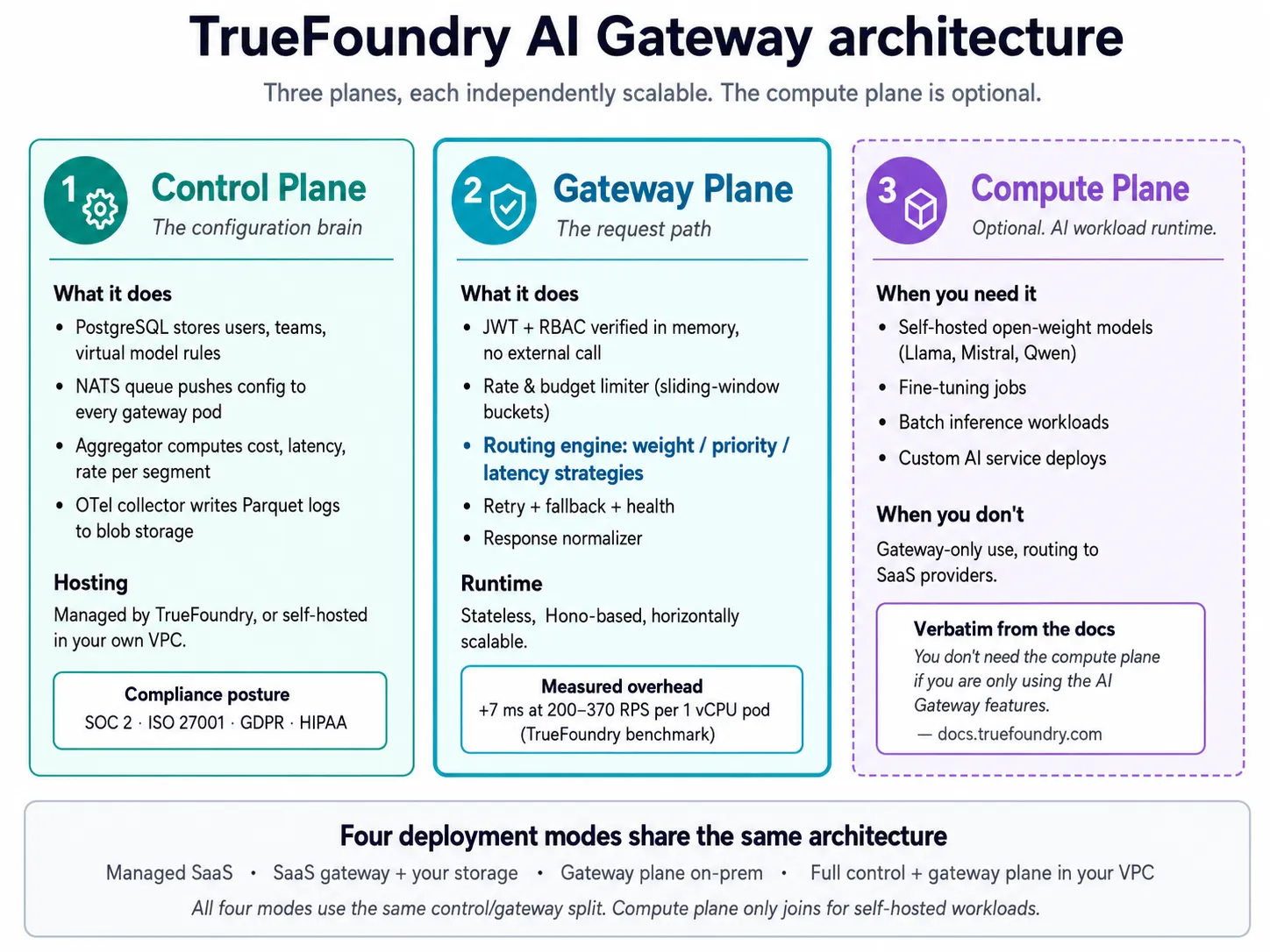
بوابة TrueFoundry لـ LLM Gateway توفر تنسيقًا متعدد النماذج كطبقة توجيه مدارة بواسطة مستوى التحكم يمكن تشغيلها كخدمة SaaS مدارة، أو هجينة، أو بالكامل داخل شبكة VPC الخاصة بك. أربع خصائص مهمة لعمليات النشر في بيئة الإنتاج.
تضيف بوابة الذكاء الاصطناعي (AI Gateway) حوكمة أوسع، وتحديدًا للمعدل، وميزانيات، وضوابط حماية، وإمكانية مراقبة عبر أعباء عمل الذكاء الاصطناعي الإنتاجية. الـ MCP Gateway تحكم الوصول إلى الأدوات، والمصادقة، ورؤية خادم MCP للتطبيقات المدعومة بالنماذج. الـ بوابة الوكيل تتحكم في الوكلاء المستقلين، والوكلاء المتخصصين، وسير العمل المعقدة التي يمكن فيها لوكيل ذكاء اصطناعي واحد إجراء استدعاءات متعددة للنماذج أو الأدوات.
احجز عرضًا توضيحيًا لترى كيف تدير TrueFoundry توجيه النماذج المتعددة، والوكلاء، وأدوات MCP، ومسارات التدقيق داخل شبكتك الافتراضية الخاصة (VPC).
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.


Multi-model orchestration is the architectural pattern of connecting an application to multiple AI models and dynamically routing each request to the model best suited for it, based on factors like task type, latency, cost, or provider availability. The orchestration layer abstracts the underlying providers behind a single API, handles failover when a model is unavailable, and normalizes responses so applications don’t need provider-specific code. In production, it’s how teams keep AI features running through provider outages and keep costs predictable as usage grows.
Multi LLM orchestration is the same pattern applied specifically to large language models. An orchestration layer sits between applications and several LLM providers (OpenAI, Anthropic, Google, Bedrock, self-hosted), routes each request to the appropriate model, manages failover and retries, and gives the application a consistent interface no matter which provider serves the response. The term is often used interchangeably with multi-model orchestration when the underlying models are all LLMs rather than a mix of model types.
The purpose is to match every workload to the right model on three axes: capability, cost, and reliability. Frontier models cost more but handle hard tasks better. Smaller models are cheap and fast for routine work. Multi-model orchestration routes intelligently between them, fails over when providers degrade, and gives operations teams one place to enforce cost, rate, and access policies. It’s the difference between running AI as a collection of provider integrations and running AI as a governed platform.
The orchestration layer normalizes them. Each provider has its own response shape, token count format, error codes, and finish reason conventions. The gateway translates everything into a single, consistent format (typically the OpenAI-compatible schema) before returning to the application. Provider-specific handling stays inside the gateway, not in the application code. In TrueFoundry’s case, the resolved target model is also returned in the x-tfy-resolved-model response header so you can trace which provider served any given request.
In a system like TrueFoundry’s gateway, you define a virtual model that points to a list of real targets and choose a routing strategy: weight-based (split traffic by percentages), priority-based (primary plus ranked fallbacks), or latency-based (pick the fastest healthy target automatically). You can layer in retry policies, fallback status codes, SLA cutoffs on time-per-output-token, sticky routing for multi-turn sessions, and metadata-based filters per target. Rules live in the gateway config and apply to every team that uses the virtual model name, with updates propagating in seconds.






أحدث الأخبار والمقالات والموارد تصلك مباشرة إلى بريدك الوارد
© 2026 جميع الحقوق محفوظة.







.png)
.webp)










.webp)
