احصل على وصول فوري إلى بيئة TrueFoundry مباشرة. انشر النماذج، ووجّه حركة مرور LLM، واستكشف المنصة بالكامل — بيئة الاختبار الخاصة بك جاهزة في ثوانٍ، ولا يلزم وجود بطاقة ائتمان.
٩.٩
قياس أداء بوابة TrueFoundry LLM: إنها فائقة السرعة ⚡
توفر بوابة TrueFoundry LLM واجهة موحدة متوافقة مع OpenAI لمختلف مقدمي نماذج اللغة الكبيرة (LLM) مثل Anthropic وOpenAI وBedrock وGemini والعديد غيرها
تتوسع بوابة TrueFoundry LLM بسلاسة لتصل إلى 350 طلبًا في الثانية (RPS) على نسخة واحدة بوحدة معالجة مركزية واحدة، مع استخدام 270 ميجابايت من الذاكرة. قارنا ذلك بمنتج بوابة آخر، LiteLLM، على إعداد مماثل، وفشل LiteLLM في التوسع لأكثر من 50 طلبًا في الثانية (RPS)
تضيف بوابة TrueFoundry LLM زمن انتقال إضافي يتراوح بين 3-5 مللي ثانية فقط، بينما يضيف LiteLLM ما بين 15-30 مللي ثانية لكل طلب.
لماذا تحتاج مؤسستك إلى بوابة LLM؟
توفر بوابة LLM واجهة موحدة لإدارة استخدام مؤسستك لـ LLM:
واجهة برمجة تطبيقات موحدة: الوصول إلى العديد من مقدمي LLM من خلال واجهة واحدة متوافقة مع OpenAI ، دون الحاجة لتغييرات في الكود
أمان مفتاح API: إدارة آمنة ومركزية لبيانات الاعتماد
الحوكمة والتحكم: تحديد الحدود، وضوابط الوصول، وتصفية المحتوى
تحديد المعدل: منع إساءة الاستخدام وضمان الاستخدام العادل
قابلية المراقبة: تتبع الاستخدام والتكاليف وزمن الانتقال والأداء
موازنة التحميل: توجيه الطلبات عبر المزودين تلقائيًا
إدارة التكاليف: مراقبة الإنفاق وتعيين تنبيهات الميزانية
سجلات التدقيق: تسجيل جميع تفاعلات نماذج اللغة الكبيرة (LLM) للامتثال
ما مدى سرعة بوابة TrueFoundry LLM؟
إعداد اختبار التحميل
لتجربة اختبار التحميل الخاصة بنا، قمنا بإعداد ونشر هذا خدمة نقطة نهاية OpenAI وهمية باستخدام TrueFoundry. ستحاكي الخدمة تنسيق طلب واستجابة OpenAI دون إنتاج رموز فعلية.
قمنا أيضًا بنشر بوابة TrueFoundry LLM وخادم وكيل LiteLLM، وكلاهما يعمل بنسخة واحدة (replica) بمعالج مركزي (CPU) واحد وذاكرة 1 جيجابايت.
أضفنا مزود OpenAI الوهمي الخاص بنا إلى كل من بوابتي TrueFoundry وLiteLLM. أثناء اختبار التحميل، أرسلنا طلبات إلى خادم OpenAI الوهمي بثلاث طرق مختلفة:
الإعداد 1: مباشرة دون استخدام أي وكيل أو بوابة
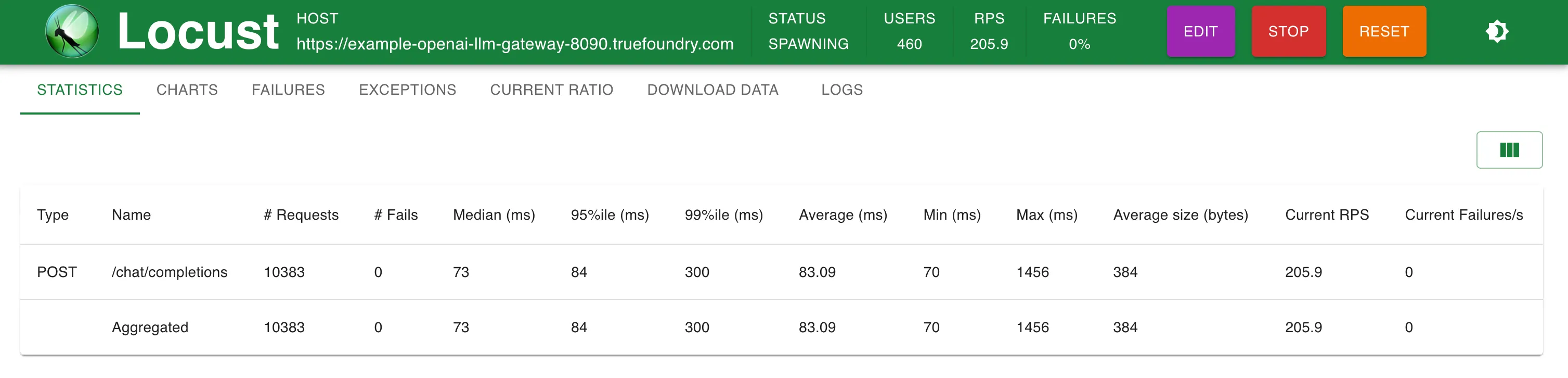
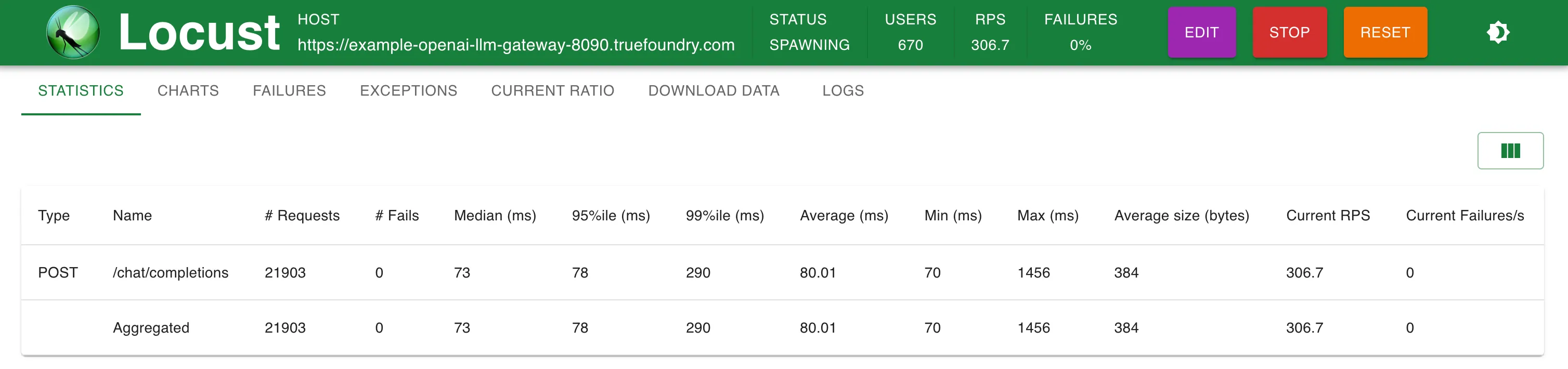
الإعداد 2: عبر بوابة TrueFoundry LLM المنشورة على وحدة معالجة مركزية واحدة وذاكرة 1 جيجابايت
الإعداد 3: عبر خادم وكيل LiteLLM المنشور على وحدة معالجة مركزية واحدة وذاكرة 1 جيجابايت
RPS
10 RPS
50 RPS
200 RPS
300 RPS
OpenAI direct (Setup 1)
73 ms
73 ms
73 ms
73 ms
TrueFoundry LLM Gateway (Setup 2)
76 ms (+3 ms)
76 ms (+3 ms)
76 ms (+3 ms)
77 ms (+4 ms)
LiteLLM Proxy (Setup 3)
88 ms (+15 ms)
99 ms (+26 ms)
Could not scale to 200 RPS
Could not scale to 300 RPS
الملاحظات
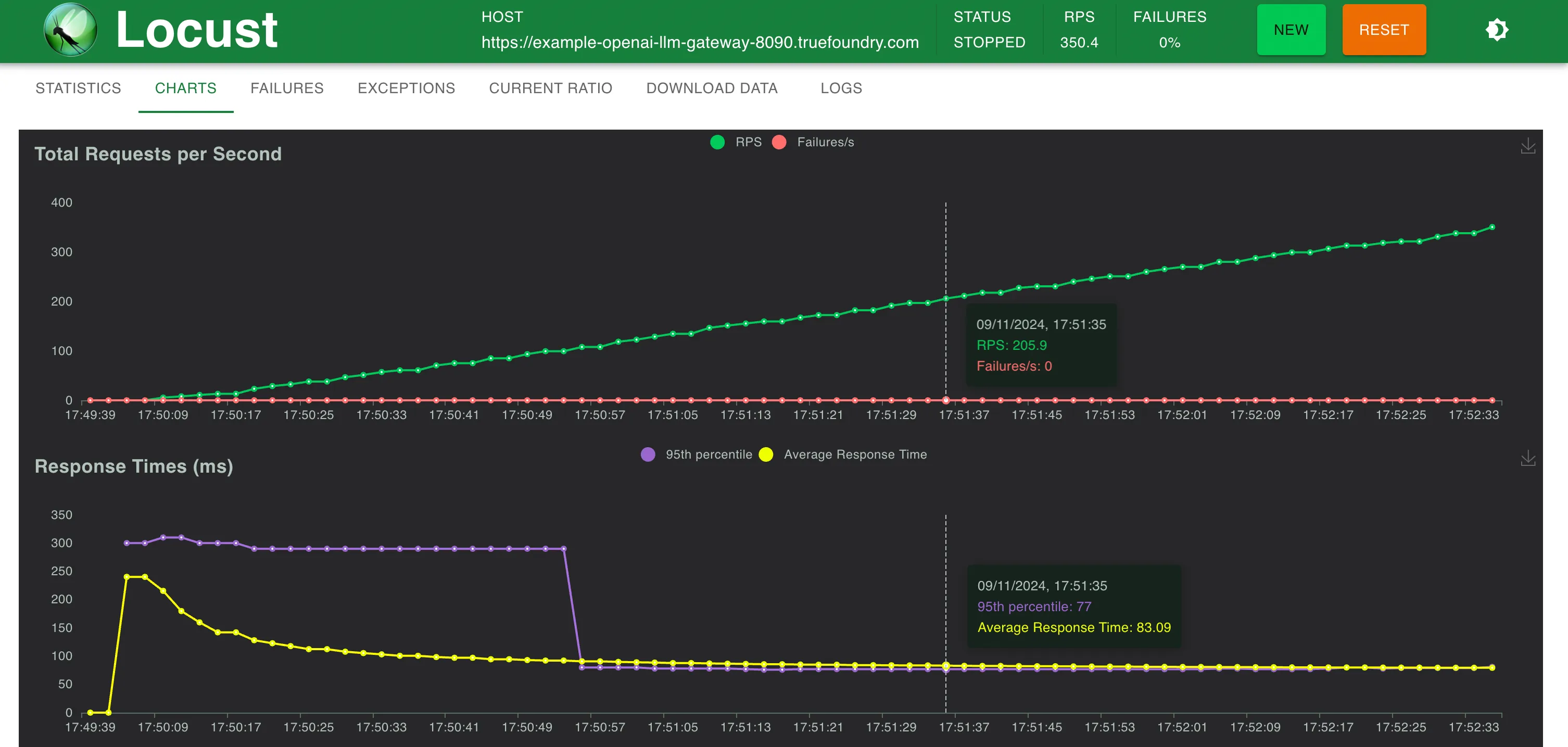
تضيف بوابة TrueFoundry 3 مللي ثانية فقط إضافية في زمن الاستجابة حتى 250 طلبًا في الثانية (RPS) و4 مللي ثانية عند أكثر من 300 طلب في الثانية.
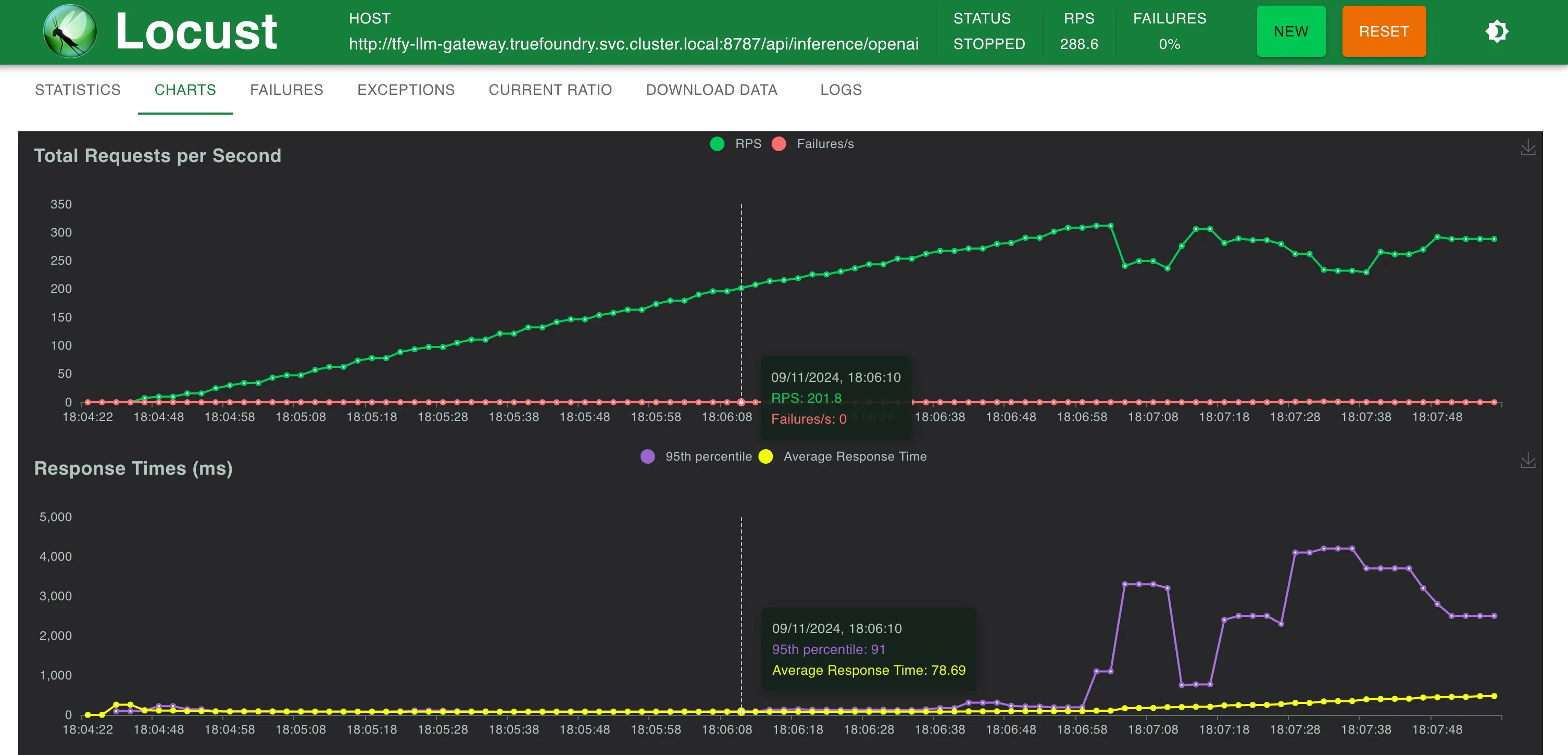
تمكنت بوابة TrueFoundry LLM من التوسع دون أي تدهور في الأداء حتى حوالي 350 طلبًا في الثانية (RPS) (جهاز بمعالج افتراضي واحد وذاكرة 1 جيجابايت) قبل أن يصل استخدام وحدة المعالجة المركزية إلى 100% وبدأت أزمنة الاستجابة تتأثر. مع المزيد من وحدات المعالجة المركزية أو المزيد من النسخ المتماثلة، يمكن لبوابة LLM أن تتوسع لتصل إلى عشرات الآلاف من الطلبات في الثانية.
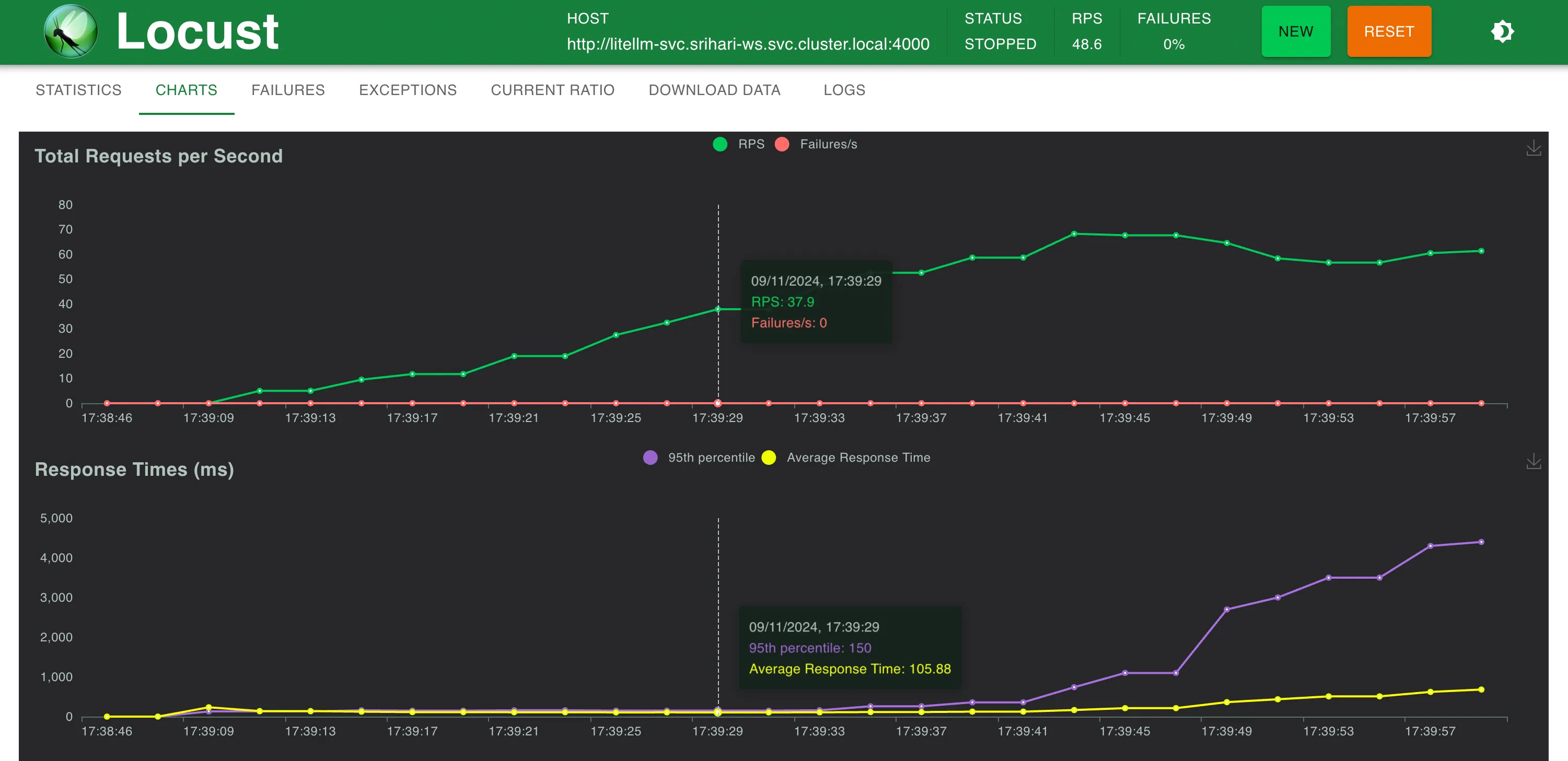
لم يتمكن LiteLLM على نفس الجهاز من التوسع إلى ما بعد 40-50 طلب في الثانية قبل الوصول إلى حد استخدام وحدة المعالجة المركزية (CPU)
المزيد من المقاييس
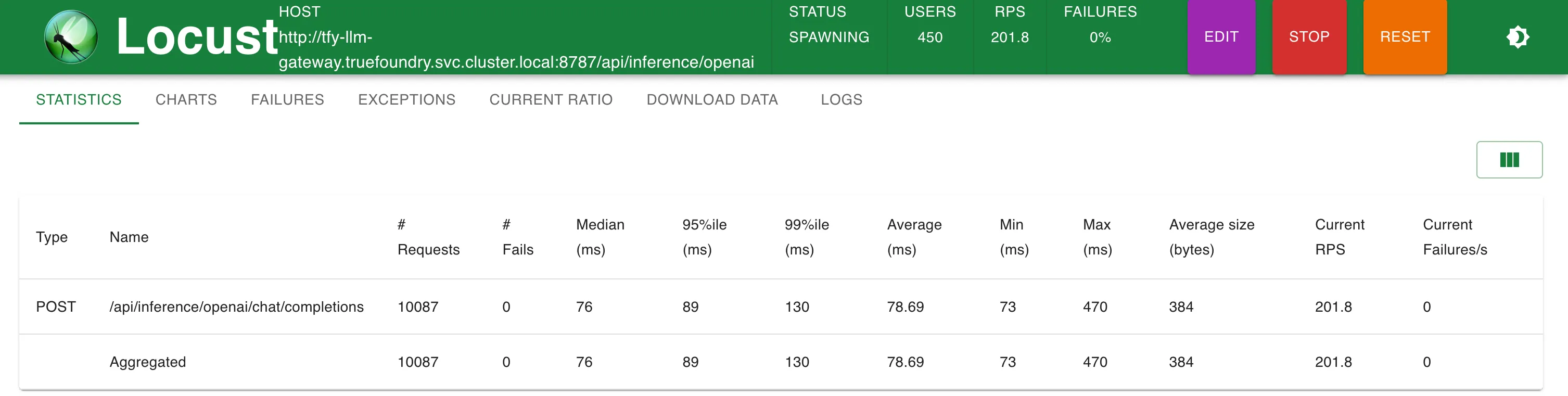
الإعداد 1: استدعاء نقطة نهاية OpenAI مباشرة
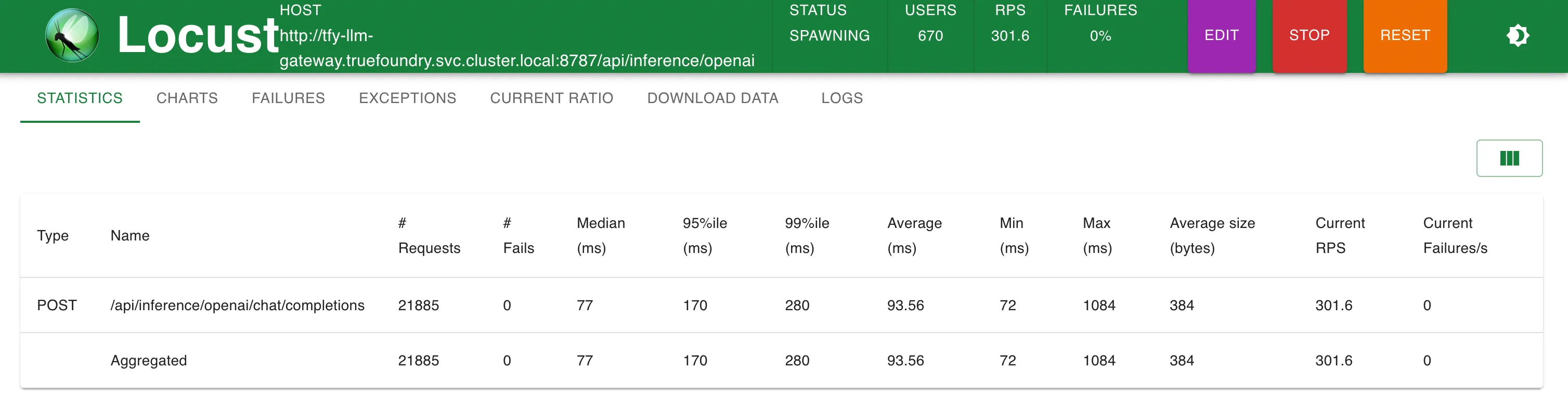
إحصائيات عند 200 طلب في الثانية
إحصائيات عند 300 طلب في الثانية
وقت الاستجابة مقابل طلب في الثانية
الإعداد 2: بوابة TrueFoundry LLM
إحصائيات عند 200 طلب في الثانية
إحصائيات عند 300 طلب في الثانية
وقت الاستجابة مقابل طلب في الثانية
الإعداد 3: LiteLLM
إحصائيات عند حوالي 58 طلب في الثانية
أوقات الاستجابة مقابل طلب في الثانية
ميزات السرعة لبوابة LLM
حمل إضافي شبه معدوم: زمن انتقال إضافي يتراوح بين 3-5 مللي ثانية فقط
الواجهة الخلفية المحسّنة: مبني باستخدام إطار عمل Node.js عالي الأداء
التخزين المؤقت للتكوين: تُخزّن الإعدادات في الذاكرة للوصول السريع
التوجيه الذكي: أدنى عبء معالجة
جاهز للحافة: انشر بالقرب من تطبيقاتك
سعة عالية: A t2.2xlarge مثيل AWS (43 دولارًا شهريًا عند الطلب الفوري) يمكن للجهاز التوسع حتى حوالي 3000 طلب في الثانية دون أي مشاكل.
النشر على الحافة لبوابة TrueFoundry LLM
المزودون المدعومون
فيما يلي قائمة شاملة بمزودي LLM المشهورين التي تدعمها بوابة TrueFoundry LLM:
Provider
Streaming Supported
GCP
✅
AWS
✅
Azure OpenAI
✅
Self Hosted Models on TrueFoundry
✅
OpenAI
✅
Cohere
✅
AI21
✅
Anthropic
✅
Anyscale
✅
Together AI
✅
DeepInfra
✅
Ollama
✅
Palm
✅
Perplexity AI
✅
Mistral AI
✅
Groq
✅
Nomic
✅
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.







































.png)
.webp)










.webp)
