احصل على وصول فوري إلى بيئة TrueFoundry مباشرة. انشر النماذج، ووجّه حركة مرور LLM، واستكشف المنصة بالكامل — بيئة الاختبار الخاصة بك جاهزة في ثوانٍ، ولا يلزم وجود بطاقة ائتمان.
٩.٩
سلسلة مسرّعات TrueFoundry: مسرّع معالجة المستندات الذكية
أليست تقنية التعرف الضوئي على الحروف (OCR) ومعالجة المستندات مشكلة تم حلها؟
بينما يعتقد الكثيرون أن تقنيات التعرف الضوئي على الحروف (OCR) ومعالجة المستندات قد تم حلها، يكلف إدخال البيانات اليدوي الشركات الأمريكية حوالي 15000 إلى 30000 دولار لكل موظف سنويًا. المصدر: لا يزال الاستنزاف التشغيلي والوقتي الناتج عن المعالجة اليدوية للمستندات كبيرًا للأسباب التالية:
التعرف الضوئي على الحروف التقليدي (OCR): هش وضعيف الأداء
تُظهر طرق التعرف الضوئي على الحروف التقليدية (الرؤية الحاسوبية + القواعد + معالجة اللغة الطبيعية) قدرة منخفضة على التكيف مع تنسيقات وتخطيطات الكتابة المختلفة، وغالبًا ما تفشل في مراعاة السياق ومتطلبات تنسيق البيانات.
قدرة منخفضة على التكيف: حتى أفضل أنظمة التعرف الضوئي على الحروف التقليدية تصل إلى حد أقصى من الدقة يتراوح بين 85-90% للمستندات المعقدة، بينما ينخفض محتوى الكتابة اليدوية إلى معدل دقة لا يتجاوز 64%. Sالمصدر
جودة الصورة الرديئة أو الإضاءة: 300 نقطة في البوصة (DPI) هو الحد الأدنى القياسي للحصول على أفضل نتائج التعرف الضوئي على الحروف (OCR)
الضوضاء
الانحراف والاتجاه
الاعتماد على القالب والتخطيط: مضبوط بدقة للعمل على قالب معين، ويتطلب مسارات معالجة لاحقة مخصصة أو تغييرًا في القالب لكل نوع مستند جديد/تحديث قالب. على سبيل المثال، تنسيق فاتورة جديد من مورد، أو عمود متحرك قليلاً في تقرير
عمى السياق: يفشل التعرف الضوئي على الحروف على مستوى الأحرف في التمييز بين الأحرف المتشابهة، مما يؤدي إلى فقدان فهم السياق على مستوى المستند بأكمله. على سبيل المثال، قد تُقرأ "50mg Metformin" على أنها "5Omg Metformin" وهو أمر غير صحيح لأي مهمة طبية لاحقة.
OCR/LLM Accuracy by Document Type
Document Type
Traditional OCR
SmolDocling (2B)
Qwen-VL-Max (18B)
GPT-4o
Gemini 2.5 Pro
Claude 3.7 Sonnet
Human Baseline
Clean Printed Text
97–98%
92–95%
97–98%
99–99.5%
99–99.5%
99–99.5%
99.8%
Tables & Forms
80–85%
83–87%
91–94%
96–98%
95–97%
95–97%
98–99%
Handwriting (Print)
70–80%
65–75%
80–85%
86–90%
88–92%
89–93%
96–98%
Handwriting (Cursive)
50–70%
60–70%
75–80%
82–90%
80–89%
81–90%
95–97%
Low-Quality Scans
60–75%
80–85%
90–93%
93–96%
92–95%
93–95%
95–97%
Mathematical Notation
70–80%
75–80%
88–93%
92–96%
94–97%
94–96%
97–99%
التعرف الضوئي على الحروف القائم على نماذج اللغة الكبيرة (LLM): غير متوقع ومكلف
أنظمة التعرف الضوئي على الحروف (OCR) القائمة على نماذج اللغة الكبيرة (LLM) تحل بعض التحديات في الطرق التقليدية، لكنها تقدم تعقيدات جديدة:
لم تُحل مشكلة النصوص المكتوبة بخط اليد: على الرغم من أن GPT-4V و Claude 3.5 Sonnet حققا دقة تتراوح بين 82-90% في النصوص المكتوبة بخط اليد، وهو تحسن كبير، إلا أن هذا لا يزال أقل من العتبات الحرجة للأعمال. على سبيل المثال، في مجال الرعاية الصحية، يمكن أن يكون معدل خطأ يتراوح بين 10-18% في الوصفات الطبية المكتوبة بخط اليد مهددًا للحياة حرفيًا.
صعوبة التوسع:
باهظة التكلفة بشكل مفرط: للمؤسسات التي تعالج ملايين المستندات سنويًا.
استجابات أبطأ:
صعوبة الحفاظ على اتفاقيات مستوى الخدمة (SLAs) في الأنظمة المستضافة ذاتيًا
فترات التوقف وارتفاعات زمن الاستجابة مع مزودي الخدمات الخارجيين
مخرجات غير متسقة:
هلوسات - على سبيل المثال، قيمة ملفقة بالكامل لبند في وثيقة قانونية
صعوبة الامتثال للمخرجات المنظمة
نفس المطالبة، استجابات مختلفة
في صناعات مثل الخدمات المالية والرعاية الصحية، التي تعالج ملايين المستندات الحيوية سنويًا، يعد النظام الذي يمكنه التوسع بشكل موثوق وإنتاج مخرجات عالية الجودة بتكلفة منخفضة أمرًا ضروريًا.
ما مدى جودة خط أنابيب معالجة المستندات لديك؟ (مقاييس عملية)
Operational Metrics & World-Class Benchmarks
Metric
Definition (Short)
World-Class Benchmark
Straight-Through Processing (STP)
% of documents processed end-to-end without human touch
85–95% for structured documents
Field Extraction Accuracy
Correctness of extracted key fields (names, amounts, dates)
99%+ for critical fields
Time to Value
Time from document receipt to structured data availability
<2 min (simple docs), <10 min (complex forms)
Human Edit Rate
% of data requiring manual correction
<5% while maintaining 99%+ accuracy
Processing Cost per Document
Total cost (compute, labor, infra) per processed page
$0.02–$0.15 per page (depending on complexity)
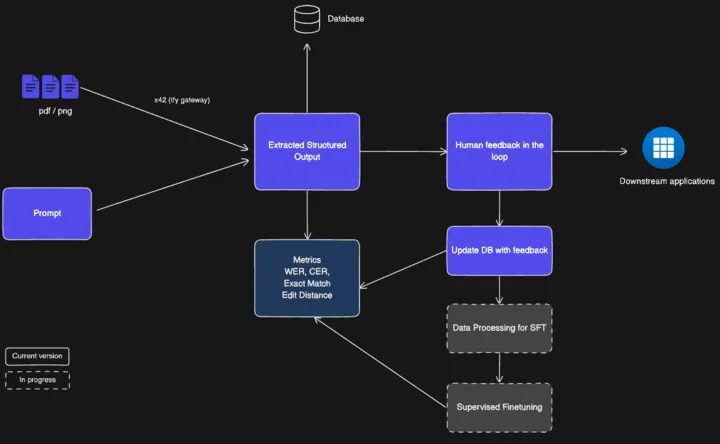
نقدم مسرّع معالجة المستندات الذكي من TrueFoundry
تعد معالجة المستندات الذكية (IDP) من TrueFoundry مسرّعًا قائمًا على الذكاء الاصطناعي التوليدي يجمع بين الممارسات الجاهزة للإنتاج ومسار عمل OCR عالي الدقة وقابل للتخصيص بدرجة كبيرة لبناء ونشر سير عمل معالجة المستندات الشاملة.
كيف يعمل: تشغيل تطبيقاتك ببيانات منظمة في دقائق!
يقوم المسرّع باستيعاب ملفات PDF أو الصور أو الفاكسات الخاصة بك وينظفها: إزالة الضوضاء، وتصحيح الانحراف، وتحسين الدقة. بحيث تبدأ النماذج من صورة واضحة. ثم يصنف كل مستند (فاتورة، وصفة طبية، ملاحظة مكتوبة بخط اليد) ويرفق المخطط الصحيح والمطالبات وقواعد المجال. يستخرج نموذج الاستخراج الحقول المنظمة ودرجات الثقة؛ وتقوم محرك القواعد بالتحقق منها وإثرائها بالفحوصات وعمليات البحث. يتم توجيه العناصر إلى مراجع عبر واجهة مستخدم بسيطة، وتعود كل تصحيح لتحسين النظام باستمرار.
مكونات قابلة للتخصيص ومعيارية
يتكون المسرّع من مكونات معيارية قابلة للتوصيل يمكنها معًا بناء نموذج أولي في اليوم الأول أو تطبيق جاهز للإنتاج على نطاق واسع.
المكونات الأساسية
دعم النماذج المتعددة (مفتوحة المصدر ومغلقة المصدر)
التدخل البشري في العملية (HITL) والملاحظات
بنية تحتية مدمجة للضبط الدقيق
المراقبة وإمكانية الملاحظة
تكامل قاعدة المعرفة (RAG + الرسم البياني المعرفي)
المكونات المتقدمة
التصنيف الآلي والتوجيه
التعرف الضوئي على الحروف (OCR) المدرك للمناطق ومربعات التحديد
الاكتشاف التلقائي للمخطط (بدون تدريب مسبق)
التحقق والمعالجة اللاحقة
الامتثال وقابلية التدقيق
تم التحقق من تصميمنا عبر العديد من تطبيقات المؤسسات
مصمم للاختيار والتحكم
المسرّع لا يعتمد على نموذج معين، سواء كان مفتوح المصدر أو مغلق المصدر، ويمكنه التوجيه عبر مزودين مختلفين لتحقيق أفضل سعر/أداء ولتجاوز الأعطال. يبقى الخبراء على اطلاع دائم من خلال واجهة مستخدم للمراجعة مُعدّة خصيصًا للمجال، وتصبح تعديلاتهم بيانات تدريب.
جاهز للعمل من اليوم الأول.
تحصل على إمكانية مراقبة فورية (زمن الاستجابة، الإنتاجية، التكلفة لكل مستند) بالإضافة إلى مؤشرات الأداء الرئيسية للأعمال — STP، دقة الحقول، ومعدل التعديل. يضمن التحقق والإثراء تطبيق القواعد عبر الحقول وتوحيد التنسيقات قبل وصول البيانات إلى التطبيقات النهائية.
قابل للتكيف، خاصة لحالات الاستخدام المعقدة للمؤسسات
يتعامل اكتشاف المخطط والتعرف الضوئي على الحروف (OCR) المدرك للمنطقة وترسيخ قاعدة المعرفة مع التخطيطات المعقدة؛ وتحفظ سجلات التدقيق كل إجراء ونتيجة وتجاوز للبيئات الخاضعة للتنظيم.
كيف نضمن قابلية هذا النظام للتوسع؟
بنيتنا المعمارية هي مخطط مستقل عن السحابة وقائم على الخدمات المصغرة، مصمم لموثوقية وقابلية توسع وكفاءة تكلفة على مستوى المؤسسات. من خلال فصل المكونات الأساسية باستخدام قوائم انتظار الرسائل غير المتزامنة، يتعامل النظام مع أعباء العمل المتقلبة وأعطال المكونات دون فقدان للبيانات، مما يتجنب الارتباط بمورد واحد.
طبقة الاستيعاب
بوابة LLM عديمة الحالة: نقطة دخول واحدة (للمصادقة/تحديد المعدل) تضع كل مستند في قائمة انتظار لموضوع رسالة.
التخزين المؤقت الدائم: تُكتب التحميلات الخام إلى تخزين الكائنات لإعادة التشغيل والتدقيق والاستعادة.
مسار المعالجة
عزل الخدمات: وحدات عمل منفصلة للتصنيف والاستخراج والتحقق؛ يمكن تحديث وتوسيع نطاق كل منها بشكل مستقل.
التوسع التلقائي المستقل: تتوسع المستخرجات كثيفة الاستخدام لوحدة المعالجة المركزية/وحدة معالجة الرسوميات خلال فترات الذروة دون التأثير على المراحل الأقل كثافة.
مهام متكررة النتائج: مهام قابلة لإعادة التشغيل مع إزالة التكرار تضمن إعادة المحاولة الآمنة ومخرجات مرة واحدة بالضبط.
إدارة البيانات والحالة
تخزين محمول: حاويات متوافقة مع S3 تحتفظ بالمستندات والمخرجات مع التحكم في الإصدارات.
العمود الفقري العلائقي: قاعدة بيانات متوافقة مع PostgreSQL تتتبع البيانات الوصفية وحالة سير العمل وقوائم انتظار HITL.
عقود المخطط: واجهات واضحة بين الخدمات تمكن من إجراء تغييرات آمنة ومتوافقة مع الإصدارات السابقة.
طبقة التغذية الراجعة وعمليات تعلم الآلة (MLOps)
حلقة بشرية: يتم التقاط التصحيحات التي تم التحقق منها مع إثبات المصدر لبيانات التدريب.
حلقة مغلقة: تدفع مسارات إعادة التدريب/التقييم/النشر الآلية نماذج أفضل إلى الإنتاج.
إصدارات مُحكمة: يحافظ سجل النماذج وفحوصات A/B وعمليات التراجع على سلامة التحسينات وقابليتها للتدقيق.
الخلاصة
تقنية التعرف الضوئي على الحروف (OCR) الحديثة لم تُحل بعد، خاصة عندما تكون الدقة والنطاق والتكلفة عوامل مهمة. يقدم مسرّع معالجة المستندات الذكية (IDP) من TrueFoundry نهجًا عمليًا وجاهزًا للإنتاج، يتميز باستخراج متعدد النماذج، والتحقق الآلي، ودور بشري في الحلقة يعزز النظام باستمرار. والنتيجة هي معالجة أسرع ومباشرة، ودقة أعلى على مستوى الحقول في المستندات التي تدير أعمالك بالفعل، ومنصة يمكن لفرقك تشغيلها، وليست مجرد عرض توضيحي للإعجاب به.
يساعدك هذا المسرّع على معالجة المزيد من المستندات بكفاءة وفعالية من حيث التكلفة، مع الحفاظ على سلامة البيانات للمدققين والخبراء والمشغلين، مما يتيح التنفيذ الفوري دون الحاجة إلى هندسة مخصصة واسعة النطاق.
تجربة تشغيلية: تواصل معنا عبر هذا الرابط. يمكننا إنشاء نموذج أولي عملي لحالة الاستخدام الخاصة بك ومساعدتك في تقديم تطبيق جاهز للإنتاج في عُشر وقت التطوير المعتاد!
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.



































.png)
.webp)










.webp)
