




November 5, 2025
|
5 min read


احصل على وصول فوري إلى بيئة TrueFoundry مباشرة. انشر النماذج، ووجّه حركة مرور LLM، واستكشف المنصة بالكامل — بيئة الاختبار الخاصة بك جاهزة في ثوانٍ، ولا يلزم وجود بطاقة ائتمان.









Published: July 4, 2026
Blazingly fast way to build, track and deploy your models!
إدارة التكوين جانب مهم من هندسة البرمجيات. ستسلط هذه المقالة الضوء على أسباب المشكلة وماهيتها وتناقش الحلول المختلفة الموجودة.

النهج المتبع في إدارة تغييرات التكوين مع توسع التطبيق — سواء من حيث حركة المرور أو حجم فريق المطورين. لتوضيح هذه الرحلة، لنبدأ بتطبيق بسيط.
هذا تطبيق خادم بسيط يتصل بقاعدة بيانات MongoDB ويعيد قائمة المستخدمين. الرمز هو مجرد رمز زائف وليس المقصود منه الالتزام بأي لغة.

تضمين التكوين في التطبيق: ممنوع تمامًا!

تضمين URI الخاص بـ MongoDB في التطبيق بشكل ثابت سيجعل تشغيل التطبيق صعبًا للغاية في أي بيئة أخرى — مثل أجهزة الكمبيوتر المحمولة للزملاء، أو للإنتاج. يجب أن نتبع الـ منهجية التطبيق ذي العوامل الـ 12 هنا لفصل التكوين عن الرمز.
“ فصل التكوين عن الرمز “
السؤال الآن هو ما الذي يشكل تكوين التطبيق؟ نقلاً عن https://12factor.net/config
تكوين التطبيق هو كل ما من المرجح أن يختلف بين عمليات النشر (بيئات الاختبار، والإنتاج، والمطورين، وما إلى ذلك). ويشمل ذلك:
1. مقابض الموارد لقاعدة البيانات، وMemcached، وغيرها الخدمات المساندة
2. بيانات الاعتماد للخدمات الخارجية مثل Amazon S3 أو Twitter
3. قيم خاصة بكل عملية نشر مثل اسم المضيف الأساسي لعملية النشر
الطريقة الأسهل والأكثر شيوعًا لفصل التكوين عن الكود هي وضع المتغيرات في ملف .env.
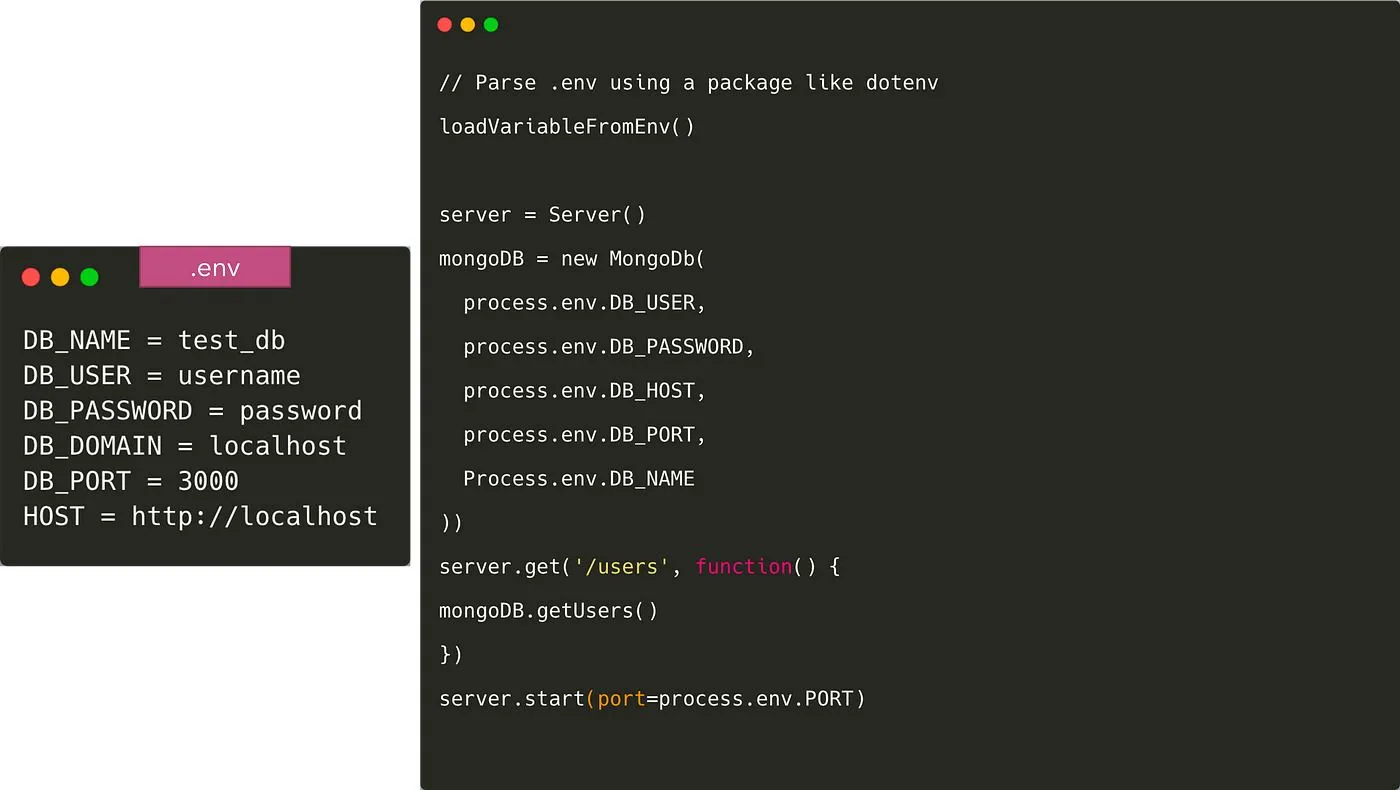
بمجرد القيام بذلك، نحتاج إلى تحميل المتغيرات في الكود من ملف .env. توجد عدة حزم للقيام بذلك مثل dotenv و dotenv-expand. ملف .env لا يتم دفعه إلى Git في هذه الحالة ويقوم كل مطور بتجاوز المتغير وفقًا لبيئته الخاصة. لإعطاء جميع المطورين فكرة عن متغيرات البيئة التي يجب إضافتها، نقوم عادةً بتثبيت ملف مثل .env.example إلى Git.

سنحتاج أيضًا إلى توفير قيم هذه المتغيرات في بيئات الاختبار والإنتاج. توفر جميع أنظمة النشر تقريبًا طريقة لتخزين وتوفير متغيرات البيئة مثل ConfigMap و Secrets في Kubernetes، أو S3 لخدمة الحاويات المرنة (Elastic Container Service).
سنحتاج إلى نسخ هذه المتغيرات إلى تلك البيئات وإبقائها متزامنة كلما أضاف المطورون / أزالوا متغيرات البيئة. أحد الأساليب الممكنة هو وجود ملف .env منفصل لبيئات الاختبار والإنتاج وما إلى ذلك.

قد يقترح البعض تخزين هذه الملفات في Git ولكن هناك مشكلة أمنية كبيرة في هذه الحالة — خاصة بالنسبة لبعض بيانات الاعتماد الحساسة في ملفات البيئة.
يستخدم الناس أساليب مختلفة هنا — ومع ذلك، فإن بعض الطرق المعروفة هي:

أثناء استخدام أي من هذه الأنظمة الخارجية، لقد قمنا الآن بتقسيم التكوين بين ملفات .env ومديري الأسرار. ستأتي بعض المعلمات غير الحساسة من ملفات .env وسيأتي بعضها من التخزين البعيد لبيانات الاعتماد. يمكننا القول إنه يمكننا تخزين جميع المعلمات في التخزين البعيد — ولكن قد يكون ذلك مبالغة في بعض الأحيان. لذا، ما نصل إليه الآن هو:
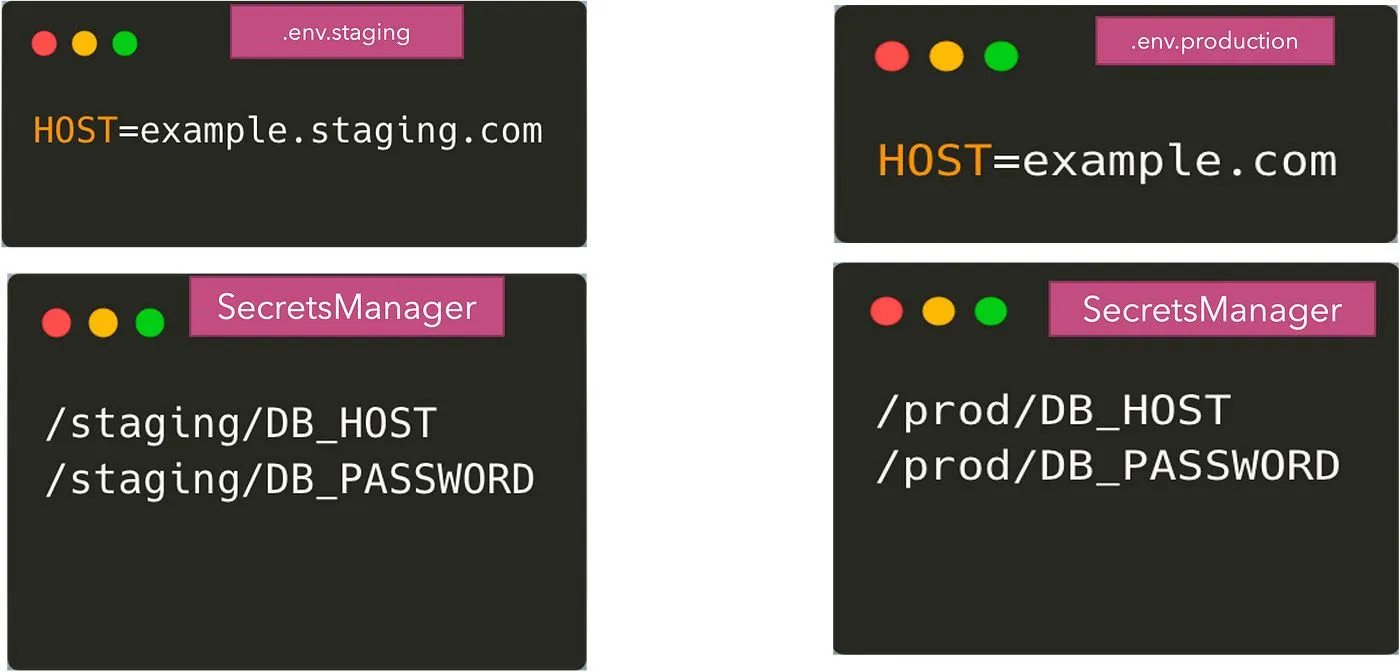
يحتاج تطبيقنا الآن إلى كود للقراءة من مصدري التكوين هذين. يمكن القراءة من ملفات .env باستخدام حزمة dotenv، ومع ذلك، فإن الحصول على متغيرات البيئة من مديري الأسرار يتطلب منا استخدام واجهات برمجة التطبيقات (APIs) الخاصة بهم للحصول على القيم.

هذا يحل مشكلة الحفاظ على تكويننا آمنًا ويتبع أيضًا منهجية العوامل الـ 12.
ومع ذلك، فإن كتابة كود التطبيق للحصول على الأسرار ينتهي به الأمر إلى ممارسة متكررة حيث يحتاج كل تطبيق الآن إلى إضافة كود خاص بمدير الأسرار للحصول على القيم من واجهة برمجة التطبيقات. وهذا يعني أيضًا أنه إذا قمنا بتغيير مزود مدير الأسرار الخاص بنا، فيجب تغيير الكود في جميع التطبيقات. لحل هذه المشكلة، يمكن أن تكون هناك بعض الأساليب:
إدارة التكوين معقدة ويجب أن تتم بشكل صحيح منذ البداية لضمان بقاء سرعة المطورين عالية دون التضحية بالجوانب الأمنية. يأتي Kubernetes، الذي يُستخدم على نطاق واسع اليوم لنشر التطبيقات، مع إدارة التكوين والأسرار الخاصة به، والتي سأتعمق فيها في مقال آخر. أيضًا، إذا كنت تستخدم طريقة أخرى لإدارة التكوين، فيرجى ذكرها في التعليقات — أود أن أعرف المزيد وأتعلم منكم!
TrueFoundry هي بوابة ذكاء اصطناعي على مستوى المؤسسات تشمل بوابات LLM و MCP والوكلاء، مما يمكّن المؤسسات من الاتصال الآمن ومراقبة وحوكمة الوصول إلى النماذج والأدوات والحواجز والوكلاء من لوحة تحكم واحدة. تتيح بوابة الذكاء الاصطناعي أعباء عمل وكيلة تتسم بـ:
أ) الأمان — معالجة إدارة المفاتيح والمصادقة والترخيص
ب) الكفاءة — تحسين التكلفة وزمن الاستجابة وتجاوز الفشل متعدد المناطق
ج) مقاومة للمستقبل — تمكين اتصالات موحدة وقابلة للتركيب عبر LLMs و MCPs والحواجز من أي مزود
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








أحدث الأخبار والمقالات والموارد تصلك مباشرة إلى بريدك الوارد
© 2026 جميع الحقوق محفوظة.











.png)
.webp)










.webp)
