




November 5, 2025
|
5 min read


احصل على وصول فوري إلى بيئة TrueFoundry مباشرة. انشر النماذج، ووجّه حركة مرور LLM، واستكشف المنصة بالكامل — بيئة الاختبار الخاصة بك جاهزة في ثوانٍ، ولا يلزم وجود بطاقة ائتمان.









Published: July 4, 2026

Blazingly fast way to build, track and deploy your models!
Elasti هو حل مبتكر مفتوح المصدر مصمم لتحسين استخدام موارد Kubernetes عن طريق تمكين الخدمات من التحجيم إلى الصفر خلال فترات الخمول والتحجيم مرة أخرى عند الطلب. تم بناؤه ببنية مكونة من جزأين — وحدة تحكم Kubernetes ومحلل طلبات — يدير Elasti توفر الخدمة بسلاسة مع تقليل التكاليف. يهدف هذا المنشور إلى تقديم شرح فني لبنيته، وتثبيته، وسير عملياته، مما يضمن قدرتك على دمج Elasti وتوسيعه بفعالية في بيئات Kubernetes الخاصة بك.
💡تُدرج هذه الميزة ضمن مجموعة Truefoundry للتحجيم التلقائي. للحصول على تفاصيل إضافية، يرجى الرجوع إلى الـ وثائق.
بينما يوفر Kubernetes إمكانيات تحجيم قوية من خلال HPA وحلول مثل KEDA، يظل التحجيم إلى صفر نسخة متماثلة يمثل تحديًا. تندرج الأساليب الحالية عادةً ضمن فئتين:
تم إنشاء Elasti لمعالجة هذه القيود بثلاثة أهداف تصميم رئيسية:
يتكون Elasti من مكونين أساسيين يعملان معًا لإدارة توسيع نطاق الخدمة:
وحدة التحكم (المشغل):
المحلل:
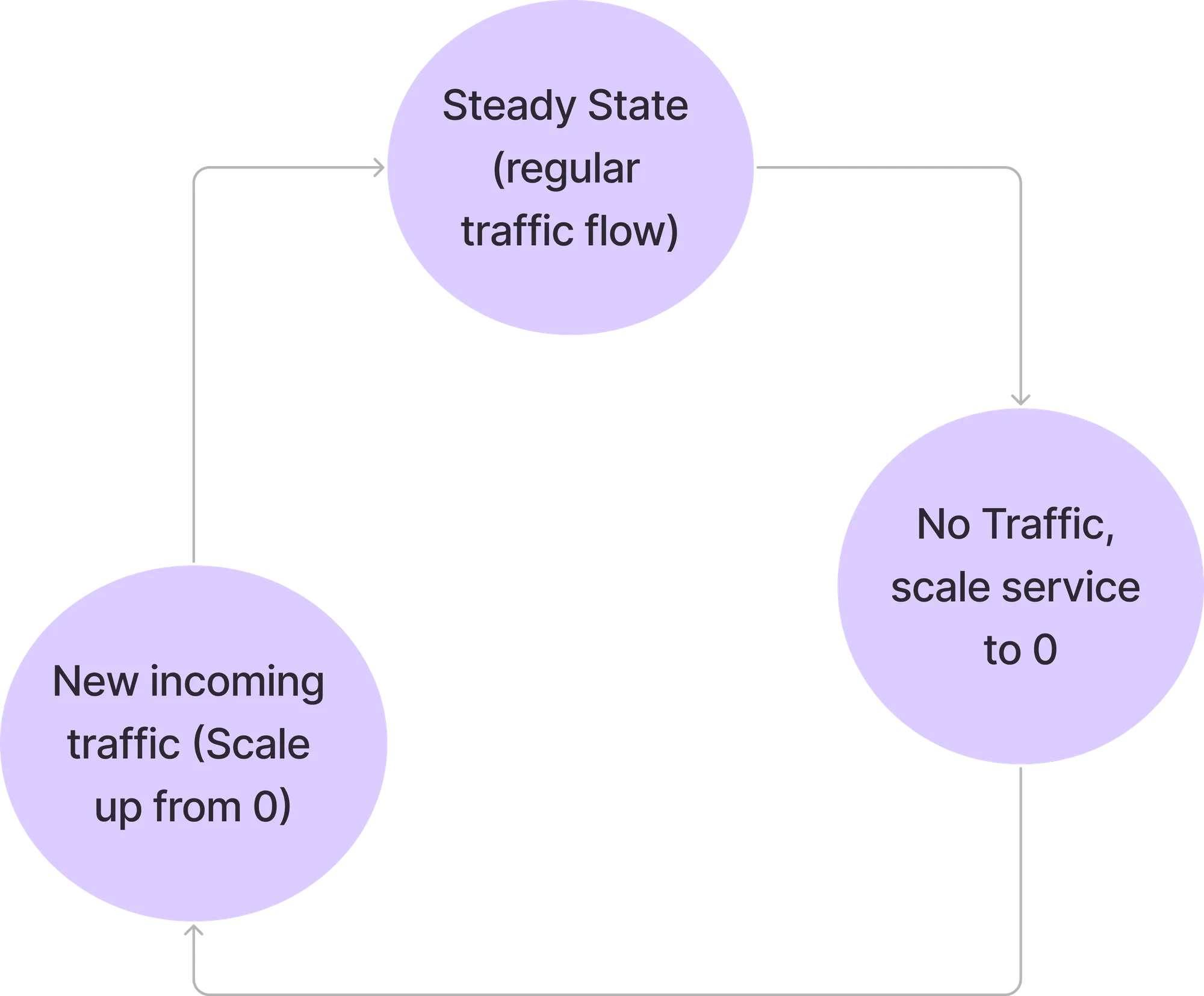
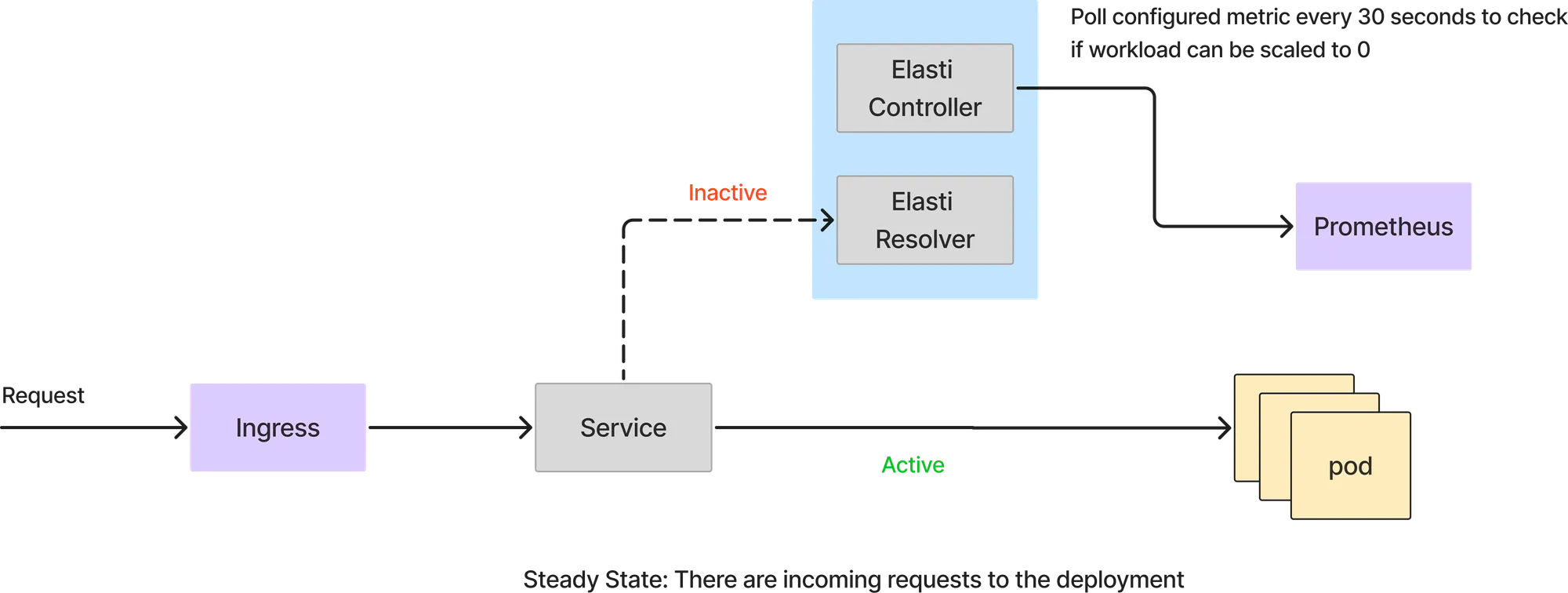
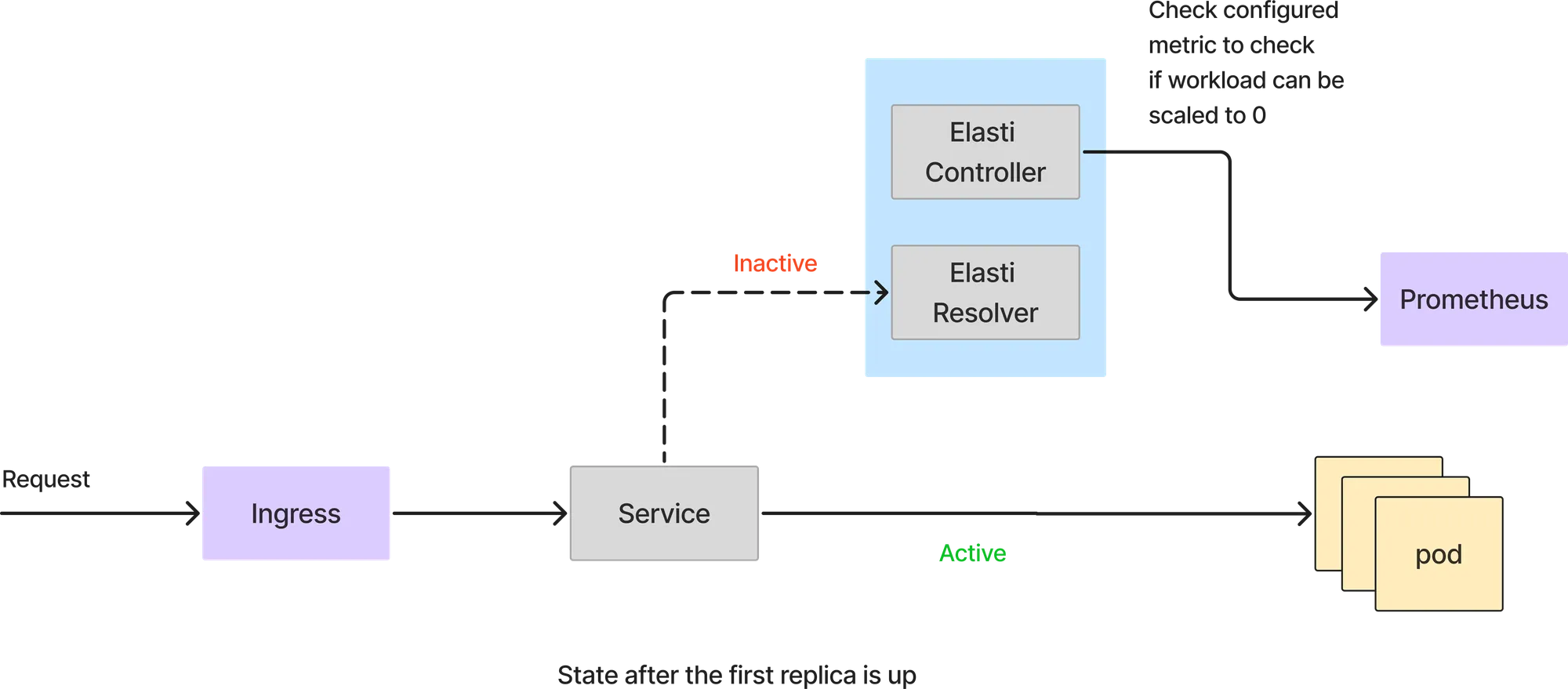
في هذا الوضع، يتم التعامل مع جميع الطلبات مباشرة بواسطة وحدات خدمة البودات (service pods). لا يتدخل محلل Elasti في مسار الطلب. تستمر وحدة تحكم Elasti في استقصاء Prometheus بالاستعلام المكون وتتحقق من النتيجة مقابل قيمة العتبة لمعرفة ما إذا كان يمكن تقليص حجم الخدمة.
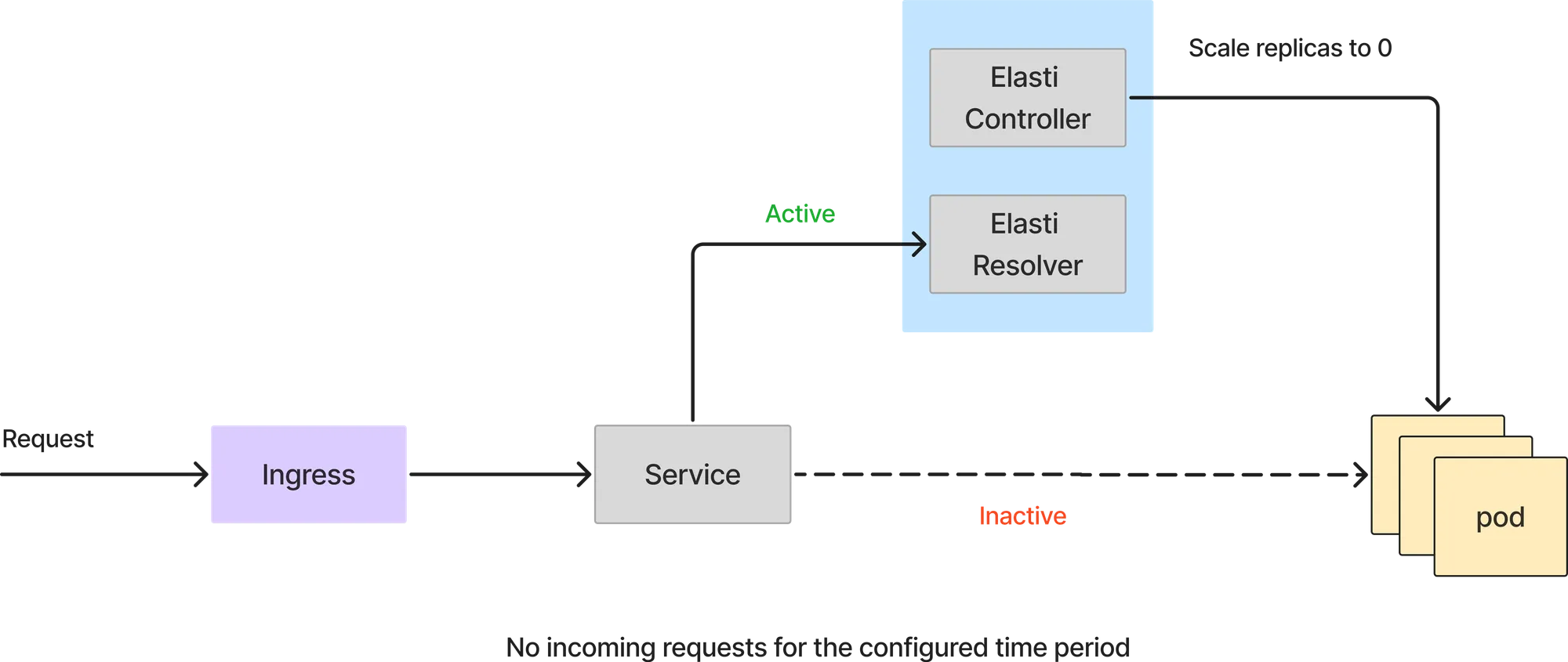
إذا أعاد الاستعلام من Prometheus قيمة أقل من العتبة، فسيقوم Elasti بتقليص حجم الخدمة إلى 0. قبل أن يتم تقليصها إلى 0، يقوم بإعادة توجيه الطلبات ليتم إرسالها إلى محلل Elasti ثم يقوم بتعديل Rollout/deployment ليصبح عدد النسخ المتماثلة (replicas) 0. كما يقوم بعد ذلك بإيقاف Keda مؤقتًا (إذا كان Keda قيد الاستخدام) لمنعه من توسيع نطاق الخدمة، نظرًا لأن Keda مُكوّن بـ minReplicas كـ 1.
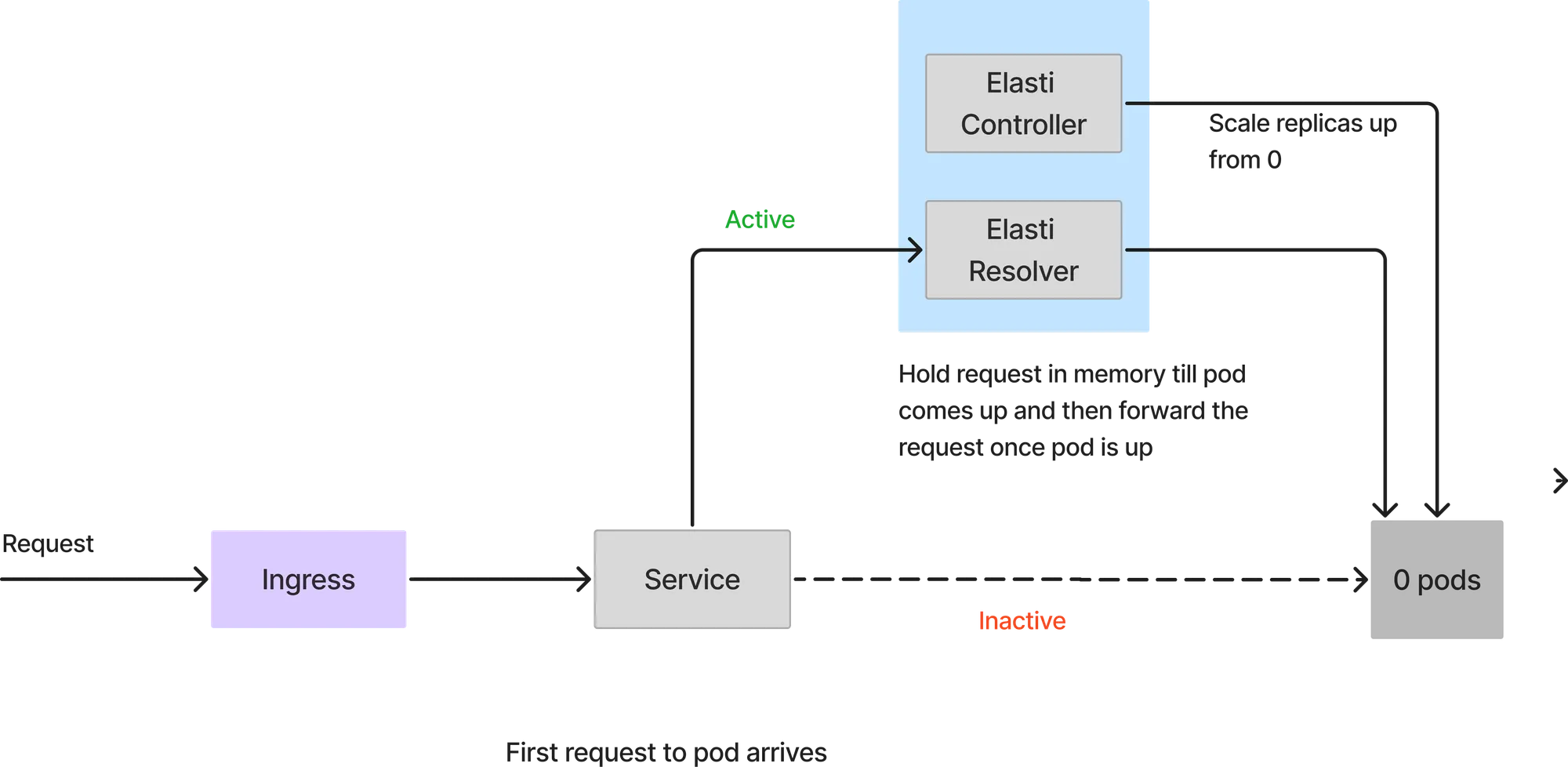
نظرًا لتقليص الخدمة إلى 0، ستصل جميع الطلبات إلى محلل Elasti. عند وصول الطلب الأول، سيقوم Elasti بتوسيع نطاق الخدمة إلى الحد الأدنى من النسخ المستهدفة (minTargetReplicas) المكونة. ثم يستأنف Keda لمواصلة التوسيع التلقائي في حال وجود تدفق مفاجئ للطلبات. كما يغير الخدمة لتشير إلى وحدات الخدمة الفعلية (pods) بمجرد تشغيل الوحدة. تتم إعادة محاولة الطلبات التي وصلت إلى ElastiResolver لمدة تصل إلى 6 دقائق ويتم إرسال الاستجابة مرة أخرى إلى العميل. إذا استغرقت الوحدة (pod) أكثر من 6 دقائق للتشغيل، يتم إسقاط الطلب.
minikube start
أو
kind create cluster --name elasti-demo
أو
إنشاء مجموعة محلية باستخدام Docker Desktop
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
helm repo update
helm install kube-prometheus-stack prometheus-community/kube-prometheus-stack \
--namespace monitoring \
--create-namespace \
--set alertmanager.enabled=false \
--set grafana.enabled=false \
--set prometheus.prometheusSpec.serviceMonitorSelectorNilUsesHelmValues=false
تثبيت وإعداد Prometheus في مساحة اسم المراقبة مساحة الاسم
سيتم استخدام Prometheus لقراءة المقاييس من مدخل Nginx، والتي ستستخدمها Elasti لاحقًا للاستعلام عن المقاييس، وبناءً عليها ستقرر متى يتم توسيع نطاق الخدمة إلى الصفر ومنه.
helm repo add ingress-nginx https://kubernetes.github.io/ingress-nginx
helm repo update
helm install ingress-nginx ingress-nginx/ingress-nginx \
--namespace ingress-nginx \
--set controller.metrics.enabled=true \
--set controller.metrics.serviceMonitor.enabled=true \
--create-namespace
ينشر وحدة تحكم Nginx في ingress-nginx مساحة الاسم
ستُستخدم وحدة التحكم لتوجيه حركة المرور إلى خدمة httpbin التجريبية الخاصة بنا.
4. إعداد Elasti:
helm repo add elasti https://charts.truefoundry.com/elasti
helm repo update
helm install elasti oci://tfy.jfrog.io/tfy-helm/elasti \
--namespace elasti --create-namespace
تثبيت Elasti باستخدام helm في مساحة الاسم elasti
بعد تثبيت Elasti، ستلاحظ أن مكونيه الأساسيين يعملان:
لمزيد من التكوينات المتقدمة، اطلع على values.yaml للاطلاع على جميع خيارات التكوين في ملف قيم helm.
kubectl create namespace elasti-demo
kubectl apply -n elasti-demo -f \
https://raw.githubusercontent.com/truefoundry/elasti/refs/heads/main/playground/config/demo-application.yaml
نشر خدمة httpbin في elasti-demo مساحة الاسم
ستُستخدم خدمة httpbin هذه لتوضيح كيفية تكوين خدمة للتعامل مع حركة المرور عبر elasti.
أنشئ ملف yaml بالتكوين التالي لـ ElastiService.
apiVersion: elasti.truefoundry.com/v1alpha1
kind: ElastiService
metadata:
name: httpbin-elasti
namespace: elasti-demo
spec:
minTargetReplicas: 1
service: httpbin
cooldownPeriod: 5
scaleTargetRef:
apiVersion: apps/v1
kind: deployments
name: httpbin
triggers:
- type: prometheus
metadata:
query: sum(rate(nginx_ingress_controller_nginx_process_requests_total[1m])) or vector(0)
serverAddress: http://kube-prometheus-stack-prometheus.monitoring.svc.cluster.local:9090
threshold: "0.5"
demo-elasti-service.yaml
بمجرد إنشاء الملف، قم بتطبيق ElastiService
kubectl apply -f https://raw.githubusercontent.com/truefoundry/elasti/refs/heads/main/playground/config/demo-elastiService.yaml
بعض الحقول الرئيسية في مواصفات CRD هي:
minTargetReplicas: الحد الأدنى من النسخ المتماثلة التي يتم تشغيلها عند وصول الطلب الأول.cooldownPeriod: الحد الأدنى للوقت (بالثواني) للانتظار بعد التوسع قبل النظر في تقليص الحجمtriggers: قائمة بالشروط التي تحدد متى يتم تقليص الحجم (يدعم حاليًا مقاييس Prometheus فقط)scaleTargetRef: مرجع إلى هدف التوسع مماثل للمستخدم في HorizontalPodAutoscaler.لمزيد من التفاصيل وتكوين ElastiService لحالة الاستخدام الخاصة بك، يرجى الرجوع إلى هذا المستند.
بهذه الخطوات، أصبح لديك الآن:
يساعدك هذا التكوين على اختبار سيناريوهات التوجيه الواقعية ومراقبة أداء ومقاييس حركة مرور الدخول الخاصة بك.
لاختبار هذا الإعداد، يمكنك إرسال طلبات إلى موازن التحميل nginx ومراقبة وحدات البود (pods) لخدمتنا التجريبية.
kubectl port-forward svc/nginx-ingress-nginx-controller \
-n ingress-nginx 8080:80
توجيه المنفذ إلى وحدة التحكم nginx
kubectl get pods -n elasti-demo -w
ابدأ بمراقبة خدمة httpbin
الآن يمكنك إرسال طلب إلى http://localhost:8080/httpbin وستلاحظ توسيع نطاق الخدمة إلى نسخة واحدة بواسطة elasti.
curl -v http://localhost:8080/httpbin
أرسل طلبًا إلى خدمة httpbin
سيتم تقليص حجم الخدمة مرة أخرى بعد عدم وجود نشاط لمدة cooldownPeriod ثانية محددة في ElastiService (5 ثوانٍ في هذه الحالة).
لإلغاء تثبيت Elasti، ستحتاج إلى إزالة جميع خدمات ElastiService المثبتة أولاً. ثم، احذف ملف التثبيت ببساطة.
kubectl delete elastiservices --all
helm uninstall elasti -n elasti
kubectl delete namespace elasti
Elasti هو الخيار الأمثل عندما:
تم تطوير Elasti لمعالجة تحدٍ محدد في Kubernetes: تطبيق التوسع الحقيقي إلى الصفر (scale-to-zero) دون التضحية بسلامة الطلبات أو فرض أعباء إضافية مفرطة. يدعم هذا الحل التحجيم التلقائي الأصلي (native autoscaling) مع HPA و KEDA، مما يضمن بقاء تكوينات الخدمات الحالية دون تغيير مع تحقيق الاستخدام الفعال للموارد.
من خلال إتاحة هذه الأداة كمصدر مفتوح، نهدف إلى توفير حل قوي للبيئات التي تتطلب توسعًا حقيقيًا إلى الصفر، وعدم فقدان أي طلبات، وبصمة تشغيلية ضئيلة.
نرحب بالمساهمات والملاحظات من المجتمع — استكشف الـ وثيقة التطوير لمزيد من التفاصيل.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.


Kubernetes scale to zero means reducing the number of running pods for a workload all the way down to zero replicas during periods of inactivity. When no traffic or demand is present, the deployment consumes no compute resources and incurs no cloud costs. When a new request arrives, the system automatically scales back up from zero and serves the workload.
The primary tools enabling scale to zero in Kubernetes include KEDA (Kubernetes Event-Driven Autoscaling), which scales based on external event sources like queues and HTTP traffic, and Knative Serving, which provides serverless-style scale-to-zero behavior for containerized workloads. TrueFoundry's deployment infrastructure also builds on these primitives to offer scale-to-zero for ML model serving, reducing GPU and CPU costs during idle periods.
Kubernetes does not support scale to zero natively through its built-in Horizontal Pod Autoscaler (HPA), as HPA has a minimum replica count of one. Achieving true scale-to-zero requires additional tools such as KEDA or Knative, which extend Kubernetes' autoscaling capabilities to include zero-replica deployments triggered by external events or HTTP request-based scaling.






أحدث الأخبار والمقالات والموارد تصلك مباشرة إلى بريدك الوارد
© 2026 جميع الحقوق محفوظة.











.png)
.webp)










.webp)
