




July 4, 2026
|
5 min read


احصل على وصول فوري إلى بيئة TrueFoundry مباشرة. انشر النماذج، ووجّه حركة مرور LLM، واستكشف المنصة بالكامل — بيئة الاختبار الخاصة بك جاهزة في ثوانٍ، ولا يلزم وجود بطاقة ائتمان.









Published: July 4, 2026
.webp)
Blazingly fast way to build, track and deploy your models!
تتوقع غارتنر أن ما يصل إلى 40% من تطبيقات المؤسسات ستتضمن وكلاء ذكاء اصطناعي خاصين بالمهام بحلول عام 2026، مرتفعًا من أقل من 5% في عام 2025. هذه قفزة سريعة. مع انتقال الأنظمة الوكيلة من المشاريع التجريبية إلى الإنتاج، يصبح طبقة التنسيق أحد أهم قرارات البنية التي تتخذها فرق المنصات.
اختر النموذج الخاطئ لكيفية تنسيق الوكلاء، وسيرث فريقك تعقيدًا في التنسيق ينمو بسرعة. يؤثر نفس الاختيار على إدارة الحالة، وسلوك الاسترداد، وزمن الاستجابة، والتعرض للتكلفة، وقابلية التوسع على المدى الطويل. بمجرد أن تتبنى فرق متعددة نفس إطار العمل، يصبح من الصعب التراجع عن الديون المعمارية المبكرة.
تغفل معظم منشورات المقارنة النقطة الأهم. يحدد إطار العمل كيف يفكر وكلاؤك، ويسلمون المهام، ويتعافون من الأخطاء، ويصمدون تحت الضغط. لكنه لا يحدد كيفية إدارتهم، أو ما يمكنهم الوصول إليه، أو تكلفتهم في الإنتاج.
تلك الأسئلة تنتمي إلى طبقة البنية التحتية والحوكمة التي تعلو إطار العمل. لا يوجد إطار عمل في هذه القائمة يجيب عليها بالكامل. يقارن هذا الدليل أطر عمل تنسيق الوكلاء المتعددين الرائدة في عام 2026، أين يعمل كل منها بشكل جيد، وأين يتوقف كل منها، وكيف توفر TrueFoundry طبقة الحوكمة التي يحتاجونها جميعًا.
قبل مقارنة الأسماء، من المفيد الاتفاق على معنى جاهزية الإنتاج. تفصل أربع خصائص بين إطار عمل يقدم عروضًا جيدة وآخر يصمد أمام النشر الفعلي في المؤسسات. تشكل هذه الخصائص ما إذا كانت الفرق تستطيع تشغيل أنظمة الذكاء الاصطناعي بوضوح وتحكم ومرونة كافية.
تحتاج أطر العمل الجاهزة للإنتاج أيضًا إلى إدارة سياق قوية. غالبًا ما يجمع الوكلاء معلومات جديدة من مصادر البيانات، وقاعدة المعرفة، والمستندات، وواجهات برمجة التطبيقات (APIs)، والأنظمة الخارجية. إذا لم تتمكن طبقة التنسيق من الحفاظ على سياق أوسع مستقر، يصبح سير العمل صعب الثقة.
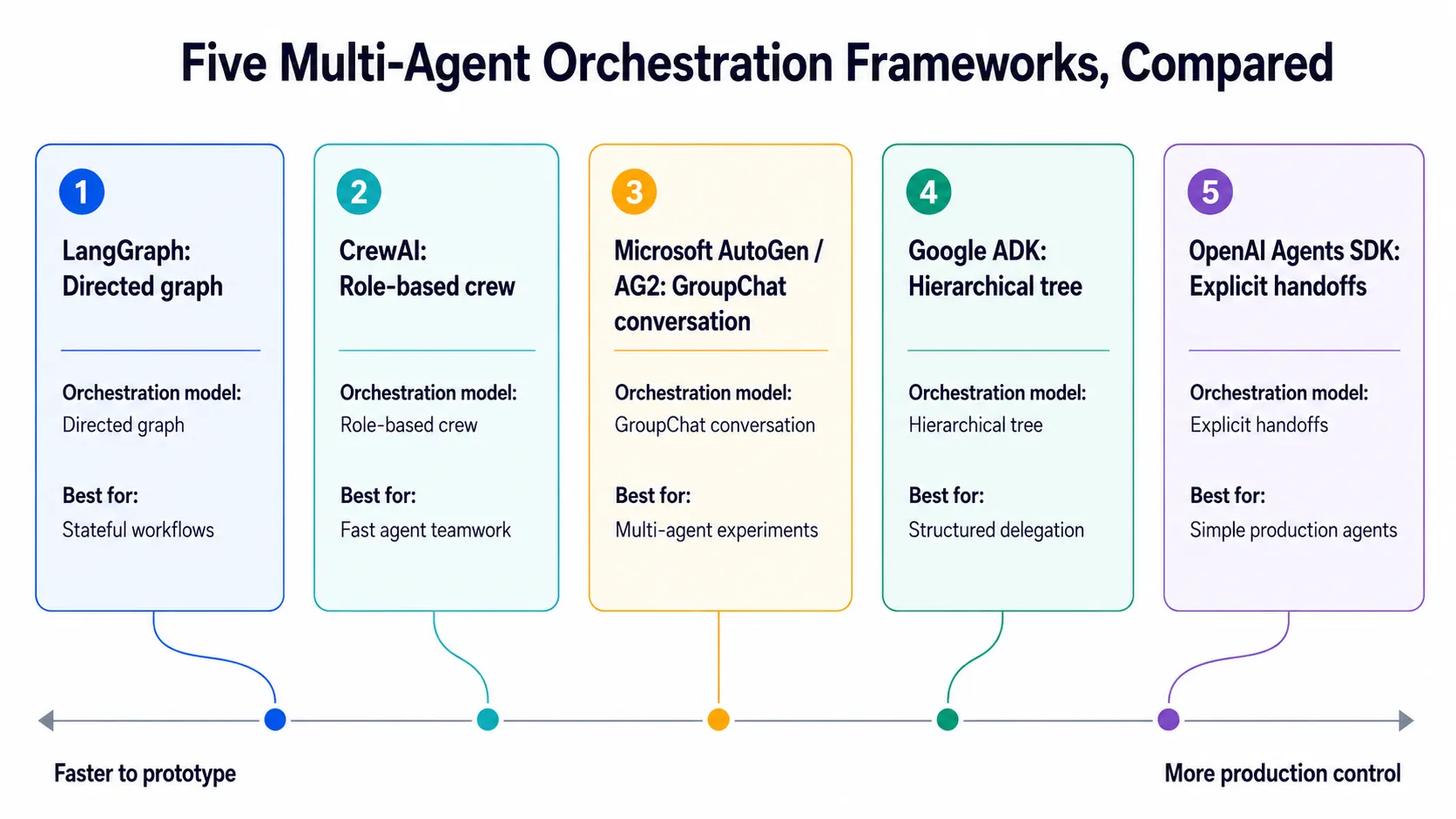
تستخدم أطر عمل تنسيق الوكلاء المتعددين الرائدة أنماطًا مختلفة للتنسيق، والتفويض، والذاكرة، والاسترداد. يعتمد الخيار الأفضل على حالة الاستخدام الخاصة بك، ونضج الفريق، ومتطلبات الإنتاج، ونموذج الحوكمة.

لانج جراف ينمذج سير عمل متعدد الوكلاء كبيان موجه: العقد هي وكلاء أو وظائف، والحواف تحدد ما الذي سيتم تشغيله بعد ذلك. تقوم حوافه الشرطية بتقييم الحالة الحالية وتوجيهها بناءً على ذلك، وهذا ما يتيح لك بناء حلقات حقيقية، مثل إعادة التحكم إلى عقدة LLM بعد استدعاء أداة أو إنهاء التشغيل عندما يقرر الوكيل أنه انتهى.
يحفظ التخزين المؤقت لقطة لحالة الرسم البياني في كل خطوة، منظمة حسب الخيط، بحيث تحصل على استئناف متسامح مع الأخطاء، وذاكرة محادثة، وتصحيح الأخطاء عبر الزمن، وتوقفات "الإنسان في الحلقة" جاهزة للاستخدام.
ما هي قيود LangGraph؟
يتطلب LangGraph الكثير من الفرق مقدمًا. تحتاج الفرق إلى التفكير في آلات الحالة، وتنفيذ الرسوم البيانية غير المتزامن، والتحكم الصريح في التدفق. التكلفة الأولية للإعداد عالية، خاصة عندما تحتاج الفرق إلى نماذج أولية سريعة أو أتمتة خفيفة الوزن بحلول نهاية الأسبوع.
لمن يعتبر LangGraph الأفضل؟
LangGraph هو الأفضل لأعباء العمل المنظمة وبيئات خطوط الأنابيب الحيوية. يناسب الفرق التي تحتاج إلى تحكم حتمي، وتسامح مع الأخطاء، وقرارات توجيه قابلة للتدقيق عبر سير العمل المعقدة.
.webp)
يصور CrewAI التنسيق كفريق من الوكلاء الذين يلعبون أدوارًا. يحصل كل وكيل على دور وهدف وقصة خلفية ومجموعة أدوات، وهو ما يتوافق تمامًا مع العديد من العمليات التجارية. وهذا يساعد الفرق على وصف العمل من خلال أدوار تشغيلية مألوفة.
يمكن للفرق العمل بشكل تسلسلي، حيث تغذي مخرجات كل مهمة الخطوة التالية. يمكنهم أيضًا العمل من خلال تنسيق هرمي، حيث يقوم وكيل مدير بتفويض العمل إلى المتخصصين. بالنسبة للعديد من الفرق، يعد هذا النموذج الذهني البسيط أقوى ميزة لـ CrewAI.
ما هي قيود LangGraph؟
تجريد الدور له تكلفة رمزية. يضيف CrewAI قبل كل استدعاء وكيل سياق الدور والهدف والقصة الخلفية، وتشير مقارنات مستقلة أجريت عام 2026 إلى أنه يمتلك أكبر بصمة رمزية بين الأطر الشائعة في المهام البسيطة والمتكررة.
يعتمد المضاعف الدقيق على سير عملك، لذا تعامل مع الأرقام المنشورة كإرشادات. كما يحد نفس التجريد القائم على الدور من التحكم الدقيق في سير العمل المتفرعة التي تحتاج إلى توجيه ديناميكي.
لمن يعتبر CrewAI الأفضل؟
أتمتة سير العمل التجاري، وخطوط أنابيب المحتوى، وخدمة العملاء، حيث وضوح الدور أهم من دقة التنفيذ والتحرك بسرعة هو الأولوية.
.webp)
كان AutoGen رائدًا في نمط المحادثة، حيث يتناقش الوكلاء وينتقدون ويصقلون الإجابة على مدار عدة جولات. يحدد مُحدد من يتحدث بعد ذلك ومتى تنتهي المحادثة. يمكن لهذا النمط التكراري تحسين الاستدلال، على الرغم من أنه يزيد التكلفة وزمن الاستجابة.
يتطلب تاريخ المشروع الآن صياغة دقيقة. انقسم مشروع AutoGen الأصلي، بينما يحافظ المجتمع على AG2 كنسخة متفرعة تعتمد على Python أولاً. دمجت مايكروسوفت اتجاهها الرسمي في إطار عمل وكيل مايكروسوفت، والذي وصل إلى الإصدار 1.0 GA في أبريل 2026 مع دعم .NET و Python.
يدعم إطار عمل وكيل مايكروسوفت أيضًا سير العمل القائمة على الرسوم البيانية، والمحادثات الجماعية (GroupChat)، وأنماط التسليم (handoff patterns)، ودعم مزودي الخدمة المتعددين (multi-provider support)، و A2A، و MCP. وهذا يعزز مسار مايكروسوفت للفرق التي تسعى إلى التوجه المؤسسي، خاصة في البيئات التي تعتمد بشكل كبير على Azure.
ما هي قيود مايكروسوفت أوتو جين (AG2)؟
يمكن أن يصبح التنسيق التخاطبي مكلفًا لأن كل جولة إضافية تزيد من الرموز ووقت الاستجابة. يناسب هذا النمط الأعمال غير المتصلة بالإنترنت والحساسة للجودة بشكل أفضل من حركة المرور الإنتاجية في الوقت الفعلي أو ذات الحجم الكبير التي تتطلب أوقات استجابة يمكن التنبؤ بها.
لمن يعتبر مايكروسوفت أوتو جين (AG2) الأفضل؟
الفرق الأصلية في Azure التي تبني سير عمل يعتمد بشكل كبير على الاستدلال، حيث تكون جودة المخرجات هي المقياس الأهم وليست الإنتاجية هي القيد.
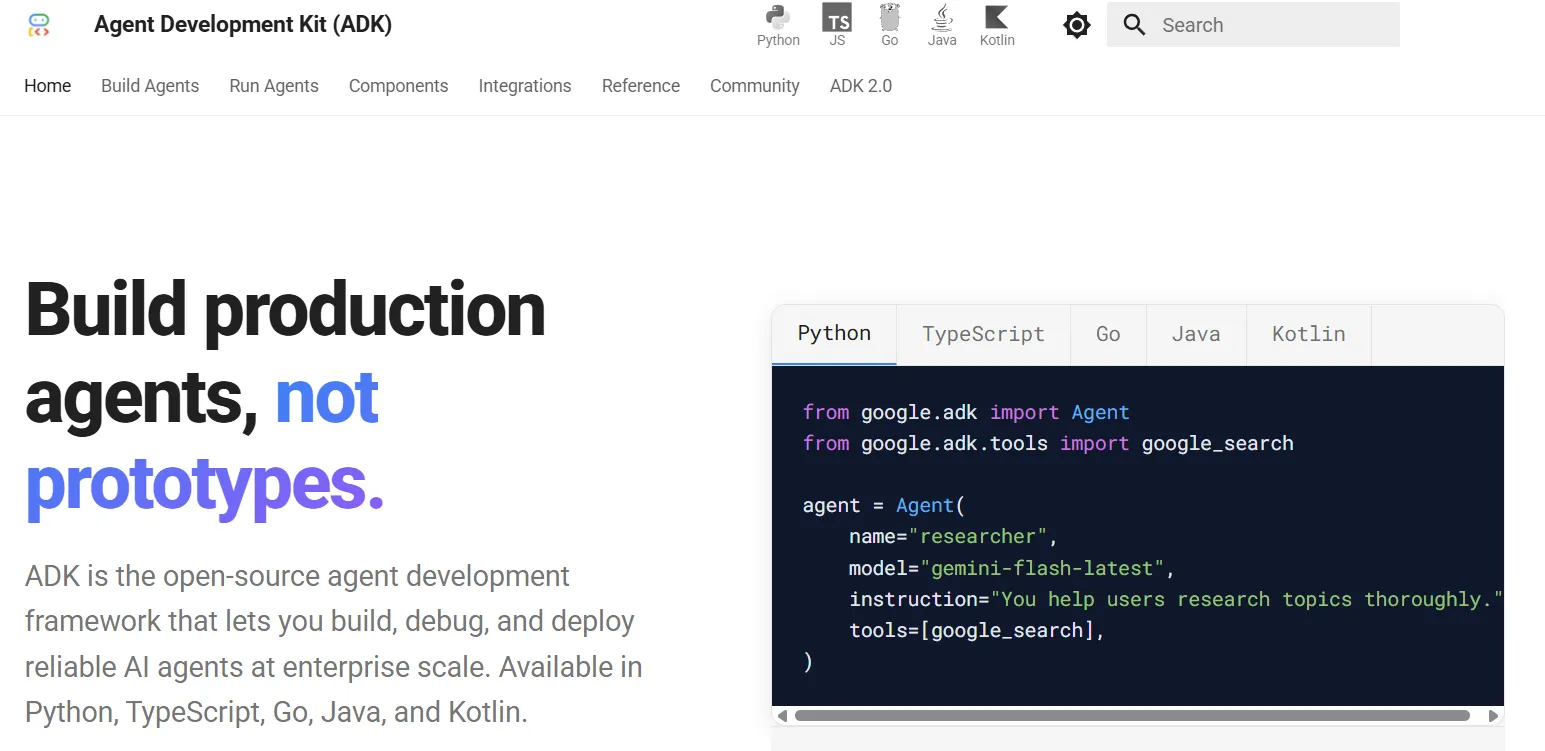
تستخدم مجموعة أدوات تطوير الوكلاء من جوجل (ADK) شجرة هرمية. يقوم المنسق الرئيسي بتفويض المهام إلى وكلاء فرعيين، ويمكن لكل وكيل فرعي تنسيق وكلاء من مستوى أدنى. كل وكيل له والد واحد، مما يجعل تدفق الأوامر وتدفق البيانات أسهل في المتابعة.
تدعم ADK أيضًا بروتوكول Agent2Agent (A2A). يساعد A2A الوكلاء المبنيين على أطر عمل مختلفة على التواصل والتعاون عبر HTTP و JSON-RPC. هذا مهم عندما ترغب الشركات في قابلية التشغيل البيني عبر أنظمة الوكلاء البيئية، ومنصات السحابة، وأدوات الشركاء.
ما هي قيود مجموعة أدوات تطوير الوكلاء من جوجل (ADK)؟
ADK مفتوحة المصدر ومحايدة للنماذج، ومع ذلك فهي محسّنة بوضوح لبيئة جوجل. تحصل الفرق التي تستخدم Gemini و Vertex AI على قيمة أصلية أكبر. يجب على الفرق التي تعمل على بيئات سحابية متعددة تقييم قابلية النقل، وتوافق البائعين، وجهد التكامل بعناية.
لمن تعتبر مجموعة أدوات تطوير الوكلاء من جوجل (ADK) الأفضل؟
تعتبر مجموعة أدوات تطوير الوكلاء من جوجل (ADK) الأفضل لبيئات جوجل السحابية التي تبني أنظمة وكلاء هرمية. تناسب الفرق التي تعتبر فيها قابلية التشغيل البيني لـ A2A والتفويض المنظم أهدافًا معمارية معلنة.
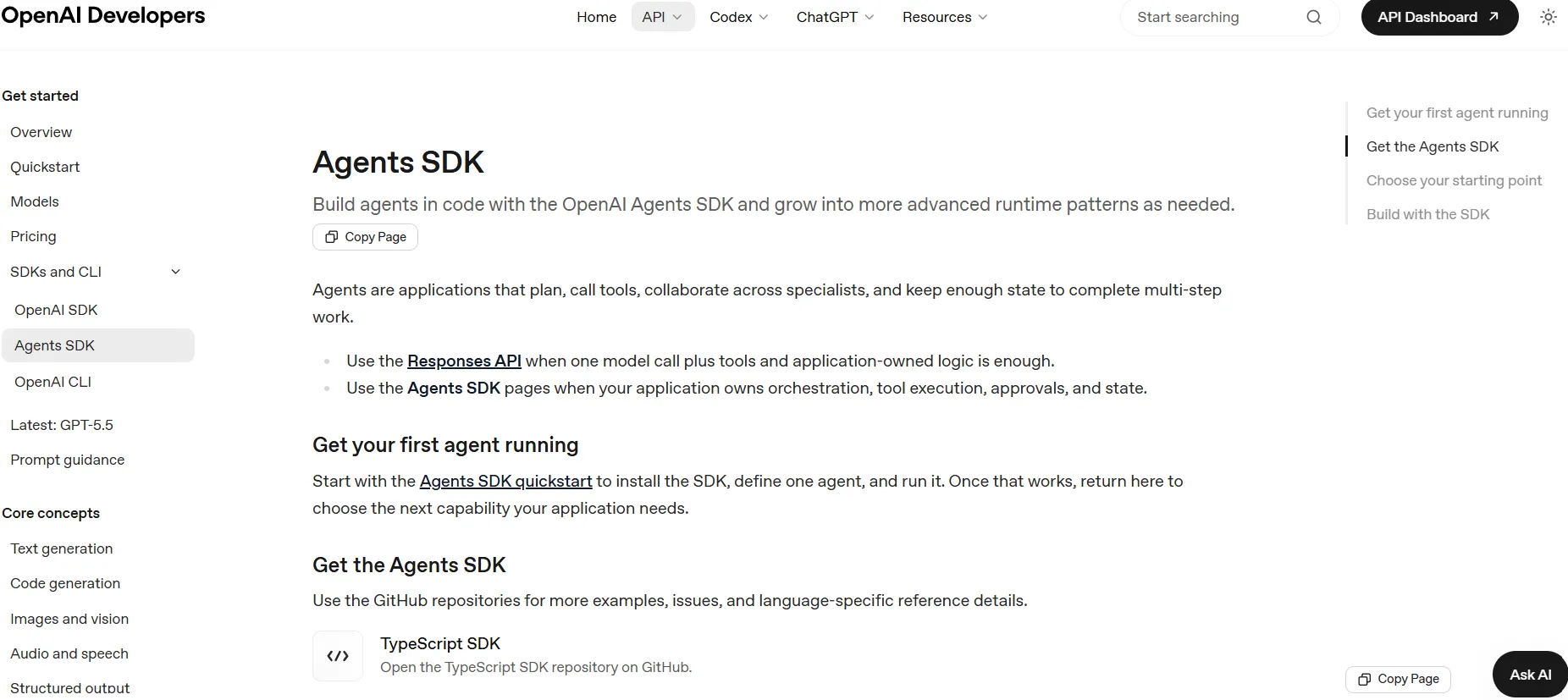
تحافظ حزمة تطوير برامج وكلاء OpenAI على شفافية التنسيق من خلال عمليات التسليم الصريحة. التسليم هو نقل تحكم باتجاه واحد، يتم تنفيذه كاستدعاء أداة. الوكيل لا يتخذ قرار توجيه مبهمًا؛ بل يستدعي دالة تنقل التحكم.
يمكن للفرق تشغيله كسلسلة تسليم لامركزية أو نمط مدير. في نموذج المدير، يستدعي وكيل ذكاء اصطناعي واحد وكلاء متخصصين كأدوات. كلا النمطين يجعلان تدفق التحكم أسهل في التتبع من الأنظمة التخاطبية بالكامل.
ما هي قيود حزمة تطوير برامج وكلاء OpenAI؟
تم ضبط حزمة تطوير البرامج (SDK) لنماذج OpenAI. يمكن للمزودين الآخرين العمل من خلال تكاملات المجتمع، على الرغم من أن هذا ليس المسار الافتراضي. يجب على المشترين من الشركات أيضًا ملاحظة محدودية التحكم في الوصول المستند إلى الدور (RBAC) المدمج، وأدلة الامتثال، وأدوات الحوكمة على مستوى الإطار.
لمن تعتبر حزمة تطوير برامج وكلاء OpenAI الأفضل؟
تعتبر حزمة تطوير برامج وكلاء OpenAI الأفضل للنماذج الأولية السريعة والإنتاج ذي التعقيد المتوسط. تناسب الفرق التي تم فيها تأكيد OpenAI وتأتي أدلة الامتثال من طبقة أخرى.
إذا طبقت أيًا من هذه الأطر على فريق واحد، فستظهر نفس الفجوات الأربع. لا شيء منها يمثل خطأ في المنتج. كلها صور لنفس المشكلة: يحدد الإطار كيفية عمل الوكلاء، وليس ما يُسمح لهم بفعله.
لا يفرض أي إطار عمل بشكل كامل أي المستخدمين أو الفرق أو الوكلاء يمكنهم استدعاء أي أدوات أو نماذج. يُترك التحكم في الوصول لتنفيذ كل تطبيق. تتغير هذه التطبيقات مع نمو الفرق، مما يخلق نقاط عمياء بين التطبيقات التي يجب أن تتبع نفس السياسة.
تتضاعف تكاليف الرموز بشكل مضاعف، لا تراكمي. سير عمل بخمسة وكلاء يقوم بثلاث استدعاءات للنموذج في كل خطوة يمكن أن ينتج عنه خمسة عشر استدعاء استدلال أو أكثر لكل طلب مستخدم. لا يوفر أي إطار عمل هنا للشركات سقفًا أصليًا عبر كل سير عمل وبيئة وفريق.
مسارات التدقيق هي فجوة أخرى. تُظهر سجلات الإطار ما تم تشغيله، على الرغم من أن أدلة الامتثال تتطلب المزيد. تحتاج الفرق الخاضعة للتنظيم إلى هوية المستخدم، وإصدار النموذج، وتصنيف البيانات، ونتيجة السياسة. هذا المتطلب مهم في قطاعات الرعاية الصحية، والمالية، والقطاع العام، وبيئات الشركات عالية المخاطر.
يمكن لاتصالات أدوات MCP أيضًا تجاوز الحوكمة التنظيمية ما لم يكن هناك شيء يعترض طريقها. يمكن للإطار أن يسمح لوكيل باستدعاء أدوات خارجية لا ينبغي له الوصول إليها أبدًا. يخلق ذلك مخاطر عندما تكون البيانات الحساسة أو الأنظمة ذات الامتيازات متضمنة.
أخيرًا، لا تزيل أطر العمل نقاط الفشل الفردية في تصميم الحوكمة. إنها تنسق التنفيذ، لكنها لا توفر تحكمًا متسقًا في الوصول المستند إلى الدور (RBAC)أو ميزانيات النماذج، أو مسارات التدقيق، أو سياسات الأدوات عبر جميع الفرق. لهذا السبب تحتاج الشركات إلى طبقة مشتركة فوق الإطار.
.webp)
TrueFoundry ليس إطار عمل وكلاء منافسًا، وقراءته بهذه الطريقة يغفل النقطة الأساسية. إنه حل على مستوى المؤسسات بوابة وكلاء تجلس فوق الإطار الذي تختاره فرقك. يمكنك الاستمرار في استخدام LangGraph. يمكنك الاستمرار في استخدام CrewAI. تنتقل الحوكمة إلى طبقة مشتركة بينها جميعًا.
# Gateway default applies to every workflow unless overridden
defaults:
token_budget_per_request: 50000 # gateway-wide default
loop_detection: on
workflows:
research-crew:
token_budget_per_request: 120000 # overrides the 50k default for this workflow
support-router:
# no override; inherits the 50,000-token gateway defaultهنا، الإعداد الافتراضي على مستوى البوابة هو 50,000 رمز لكل طلب، مع تفعيل اكتشاف الحلقات. يتجاوز سير عمل فريق البحث هذا الحد الأقصى إلى 120,000 رمز لأن البحث العميق متعدد الوكلاء يحتاج إلى سياق أكبر. يرث موجه الدعم (support-router) الإعداد الافتراضي البالغ 50,000 رمز، مما يجعل التجاوز صريحًا.
مسارات تدقيق جاهزة للامتثال داخل شبكتك الافتراضية الخاصة (VPC): يمكن تسجيل كل استدعاء نموذج، واستدعاء أداة، وخطوة تنسيق ببيانات وصفية منظمة داخل حدود AWS أو GCP أو Azure أو في الموقع أو المعزولة هوائيًا. تساعد TrueFoundry الشركات في الحفاظ على جاهزية SOC 2 و HIPAA و GDPR دون توجيه بيانات الحوكمة خارج نطاقها.
توفر بوابة الذكاء الاصطناعي توجيهًا موحدًا وحوكمة وقابلية للمراقبة عبر أعباء عمل الذكاء الاص8ناعي. تُركز بوابة LLM توجيه النماذج عبر المزودين. تدعم TrueFoundry أيضًا الضوابط الوقائية، وإنفاذ التكلفة، والتحكم في وقت التشغيل للوكلاء المستقلين وسير العمل المعقدة القائمة على الوكلاء.
.webp)
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.


Multi-agent orchestration frameworks are software frameworks that coordinate several agents working toward one outcome. They decide which agent runs, how agents pass state, and how the system recovers when a step fails. LangGraph, CrewAI, Microsoft AutoGen or AG2, Google ADK, and OpenAI Agents SDK are leading options in 2026.
There is no single best framework because each optimizes for different use cases. LangGraph suits deterministic workflows, CrewAI fits role-based business processes, AutoGen or AG2 supports reasoning-heavy work, Google ADK fits Google Cloud environments, and OpenAI Agents SDK works well when OpenAI is confirmed. Governance should still sit above the framework.
It varies by framework. LangGraph's checkpointing lets a failed workflow resume from its last saved state instead of restarting. Most frameworks offer some retry and timeout configuration, but recovery behavior, fallback paths, and human escalation differ widely, and few treat them as first-class. For consistent behavior across frameworks, teams often enforce retries, timeouts, and loop detection at a gateway layer so the policy doesn't depend on each framework's defaults.
Single-agent tool use means one agent calls tools in a loop to complete tasks. multi-agent orchestration coordinates several types of agents, often specialized, that hand work to each other. It adds harder problems such as shared state, inter-agent communication, failure recovery, and multiplied inference cost across the chain.
They start with the framework's orchestration and recovery model, then check what it doesn't provide: access control tied to user identity, per-workflow cost limits, and audit trails that map calls to model versions and data classifications for SOC 2 or HIPAA. Since no framework supplies those, the practical pattern is to choose a framework on technical fit and add a governance layer, like TrueFoundry's Agent Gateway, that enforces RBAC, cost controls, and compliance logging inside the company's own cloud boundary.






أحدث الأخبار والمقالات والموارد تصلك مباشرة إلى بريدك الوارد
© 2026 جميع الحقوق محفوظة.







.png)
.webp)










.webp)
