






July 4, 2026
|
5 min read


احصل على وصول فوري إلى بيئة TrueFoundry مباشرة. انشر النماذج، ووجّه حركة مرور LLM، واستكشف المنصة بالكامل — بيئة الاختبار الخاصة بك جاهزة في ثوانٍ، ولا يلزم وجود بطاقة ائتمان.









Published: July 4, 2026

Blazingly fast way to build, track and deploy your models!
عدنا إليكم بحلقة أخرى من محادثات ML حقيقية. في هذه الحلقة، نتعمق مرة أخرى في تطبيقات MLOps ونماذج اللغة الكبيرة (LLMs) في GitLab، ونتحدث مع Monmayuri Ray.
تقود Monmayuri قسم أبحاث الذكاء الاصطناعي في GitLab مع تركيز كبير على نماذج اللغة الكبيرة (LLMs) خلال العام الماضي. وقبل ذلك، كانت مديرة هندسية في قسم ModelOps في GitLab. كما عملت مع شركات أخرى مثل Microsoft و eBay.
📌
ستغطي محادثاتنا مع Monmayuri الجوانب التالية:
- حالات استخدام التعلم الآلي (ML) ونماذج اللغة الكبيرة (LLM) في GitLab
- تطور البنية التحتية للتعلم الآلي (ML) في GitLab لدعم نماذج اللغة الكبيرة (LLMs)
- رحلة GitLab مع نماذج اللغة الكبيرة (LLMs): من المصادر المفتوحة إلى الضبط الدقيق
- تدريب نماذج اللغة الكبيرة في GitLab
- Triton مقابل PyTorch، ووحدات معالجة الرسوميات المجمعة (Ensembled GPUs)، والتجميع الديناميكي (Dynamic Batching) لاستدلال نماذج اللغة الكبيرة (LLM Inference)
- التحديات والأبحاث في تقييم نماذج اللغة الكبيرة (LLMs) في GitLab
- بنية نماذج اللغة الكبيرة (LLM) في GitLab ومستقبلها
يُحدث التعلم الآلي (ML) تحولًا في دورة حياة تطوير البرمجيات، وتتصدر GitLab هذا الابتكار. تستخدم GitLab التعلم الآلي لتمكين المطورين طوال رحلتهم، بدءًا من إنشاء المشكلات ووصولًا إلى دمج الطلبات ونشر التطبيقات.
تُعد نماذج اللغة الكبيرة (LLMs) إحدى حالات الاستخدام الأكثر إثارة للتعلم الآلي في GitLab. تستخدم GitLab نماذج اللغة الكبيرة والذكاء الاصطناعي التوليدي لتطوير ميزات جديدة لمنتجاتها، مثل إكمال التعليمات البرمجية وتلخيص المشكلات.
كانت GitLab في طليعة استخدام نماذج اللغة الكبيرة (LLMs) لتمكين المطورين. ونتيجة لذلك، كان على GitLab تطوير بنيتها التحتية للتعلم الآلي لدعم هذه النماذج المعقدة.
لمواجهة التحديات المذكورة أعلاه، أجرت GitLab عددًا من التغييرات على بنيتها التحتية للتعلم الآلي (ML). يمكن تصنيف هذه التغييرات ضمن المجالات التالية:
كانت GitLab في طليعة الشركات التي تستخدم نماذج اللغة الكبيرة (LLMs) لتمكين المطورين. في البداية، بدأت GitLab باستخدام نماذج اللغة الكبيرة مفتوحة المصدر، مثل Salesforce code gen. ومع ذلك، ومع تغير المشهد وأصبحت نماذج اللغة الكبيرة (LLMs) أكثر قوة، تحولت GitLab إلى الضبط الدقيق لنماذج اللغة الكبيرة الخاصة بها لحالات استخدام محددة، مثل توليد الأكواد.
يتطلب الضبط الدقيق لنماذج اللغة الكبيرة (LLMs) استثمارًا كبيرًا في البنية التحتية، نظرًا لأن هذه النماذج كبيرة ومعقدة للغاية. اضطرت GitLab إلى تطوير مسارات تدريب ونشر جديدة لنماذج اللغة الكبيرة، بالإضافة إلى طرق جديدة لإدارة بنيتها التحتية للتعلم الآلي في بيئة موزعة.
أحد التحديات الرئيسية التي واجهتها GitLab في الضبط الدقيق لنماذج اللغة الكبيرة هو إيجاد التوازن الصحيح بين التكلفة وزمن الاستجابة. يمكن أن تكون نماذج اللغة الكبيرة مكلفة للغاية للتدريب والنشر، وقد تكون بطيئة في توليد النتائج. اضطرت GitLab إلى تجربة أحجام مجموعات مختلفة، وتكوينات وحدات معالجة الرسوميات (GPU)، وتقنيات التجميع لإيجاد التوازن المناسب لاحتياجاتها.
تحدٍ آخر واجهته GitLab هو ضمان دقة وموثوقية نماذج اللغة الكبيرة الخاصة بها. يمكن تدريب نماذج اللغة الكبيرة على مجموعات بيانات ضخمة من النصوص والأكواد، ولكن هذه المجموعات قد تحتوي أيضًا على أخطاء وتحيزات. اضطرت GitLab إلى تطوير تقنيات جديدة لتقييم نماذج اللغة الكبيرة الخاصة بها وإزالة التحيز منها.
على الرغم من التحديات، حققت GitLab تقدمًا كبيرًا في استخدام نماذج اللغة الكبيرة لتمكين المطورين. أصبحت GitLab الآن قادرة على تدريب ونشر نماذج اللغة الكبيرة على نطاق واسع، وهي تستخدم هذه النماذج لتطوير ميزات ومنتجات جديدة من شأنها أن تجعل عملية تطوير البرمجيات أكثر كفاءة ومتعة.
يعد تدريب نماذج اللغة الكبيرة (LLMs) مهمة صعبة تتطلب استثمارًا كبيرًا في البنية التحتية والموارد. كانت GitLab في طليعة الشركات التي تستخدم نماذج اللغة الكبيرة لتمكين المطورين، وقد تعلمت الشركة الكثير على طول الطريق.
فيما يلي بعض الرؤى والدروس المستفادة من تجربة GitLab في تدريب نماذج اللغة الكبيرة:
بالإضافة إلى الرؤى المذكورة أعلاه، تعلمت GitLab أيضًا عددًا من الدروس القيمة حول أهمية الفهم الجيد للنموذج الأساسي وبيانات التدريب. على سبيل المثال، وجدت GitLab أنه من المهم معرفة بنية النموذج الأساسي وكيفية تنظيم بيانات التدريب لتحسينها لحالة الاستخدام المطلوبة.
تستخدم GitLab Triton لاستدلال النماذج اللغوية الكبيرة (LLM) لأنه أكثر ملاءمة للتوسع للتعامل مع الحجم الكبير من الطلبات التي تتلقاها GitLab. كما أن Triton أسهل في التغليف والتوسع من خوادم النماذج الأخرى، مثل خوادم PyTorch.
لم تجرب GitLab بعد خوادم نماذج TGI أو VLLM من Hugging Face، حيث كانت هذه الخوادم لا تزال في المراحل المبكرة من التطوير عندما نشرت GitLab خط أنابيب استدلال النماذج اللغوية الكبيرة (LLM) الخاص بها لأول مرة.
عندما يتعلق الأمر بالتجميع الديناميكي، تتمثل استراتيجية GitLab في التحسين لحالة الاستخدام المحددة، والحمل، ومستوى الاستعلام، والحجم، وعدد وحدات معالجة الرسوميات (GPUs) المتاحة. على سبيل المثال، إذا كان لدى GitLab 500 وحدة معالجة رسوميات (GPUs) لنموذج 7B، فيمكنها استخدام استراتيجية تجميع مختلفة عما لو كان لديها عدد قليل فقط من وحدات معالجة الرسوميات (GPUs) لنموذج أصغر.
تستخدم GitLab أيضًا مجموعة من وحدات معالجة الرسوميات (GPUs) للتعامل مع الطلبات. هذا يعني أن GitLab تستخدم مزيجًا من أنواع مختلفة من وحدات معالجة الرسوميات (GPUs)، بما في ذلك وحدات معالجة الرسوميات عالية الأداء ووحدات معالجة الرسوميات الأقل أداءً. توازن GitLab الحمل للطلبات عبر مجموعة وحدات معالجة الرسوميات (GPUs) لتحسين الأداء والتكلفة.
إليك بعض النصائح لتصميم بنية لتجميع وحدات معالجة الرسوميات (GPUs) وتحسين موازنة الحمل:
إليك بعض الأمثلة المحددة لكيفية قيام GitLab بتحسين بنيتها لوحدات معالجة الرسوميات المجمعة والتجميع الديناميكي:
باتباع هذه النصائح، يمكنك تصميم بنية يمكنها التعامل بكفاءة مع أحجام كبيرة من طلبات استدلال نماذج اللغة الكبيرة (LLM).
لقد جربنا التدفق أيضًا، وأعتقد أننا نبحث في إمكانية توفير التدفق لأطرافنا الثالثة أيضًا - Monmayuri
يُعد تقييم أداء نماذج اللغة الكبيرة (LLMs) مهمة صعبة. تعمل GitLab على هذه المشكلة وقد واجهت العديد من التحديات، منها:
تتصدى GitLab لهذه التحديات من خلال:
هدف GitLab هو تطوير نهج قابل للتطوير ومدفوع بالبيانات لتقييم نماذج اللغات الكبيرة (LLMs). سيساعد هذا النهج GitLab على ضمان أن نماذج اللغات الكبيرة الخاصة بها تعمل بشكل جيد في بيئة الإنتاج وتلبي احتياجات مستخدميها.
تجري GitLab أيضًا أبحاثًا حول طرق جديدة لتقييم نماذج اللغات الكبيرة (LLMs). تتضمن بعض اتجاهات البحث التي تستكشفها GitLab ما يلي:
أبحاث GitLab حول تقييم نماذج اللغات الكبيرة (LLMs) مستمرة. تلتزم GitLab بتطوير طرق جديدة ومبتكرة لتقييم نماذج اللغات الكبيرة (LLMs) لضمان أن نماذج اللغات الكبيرة الخاصة بها تلبي احتياجات مستخدميها.
تُعد هندسة نماذج اللغات الكبيرة (LLM) في GitLab نهجًا شاملاً للتدريب والتقييم و نشر نماذج اللغات الكبيرة (LLMs). صُممت هذه الهندسة لتكون مرنة وقابلة للتطوير، حتى تتمكن GitLab من تبني التقنيات الجديدة بسهولة وتلبية احتياجات مستخدميها.
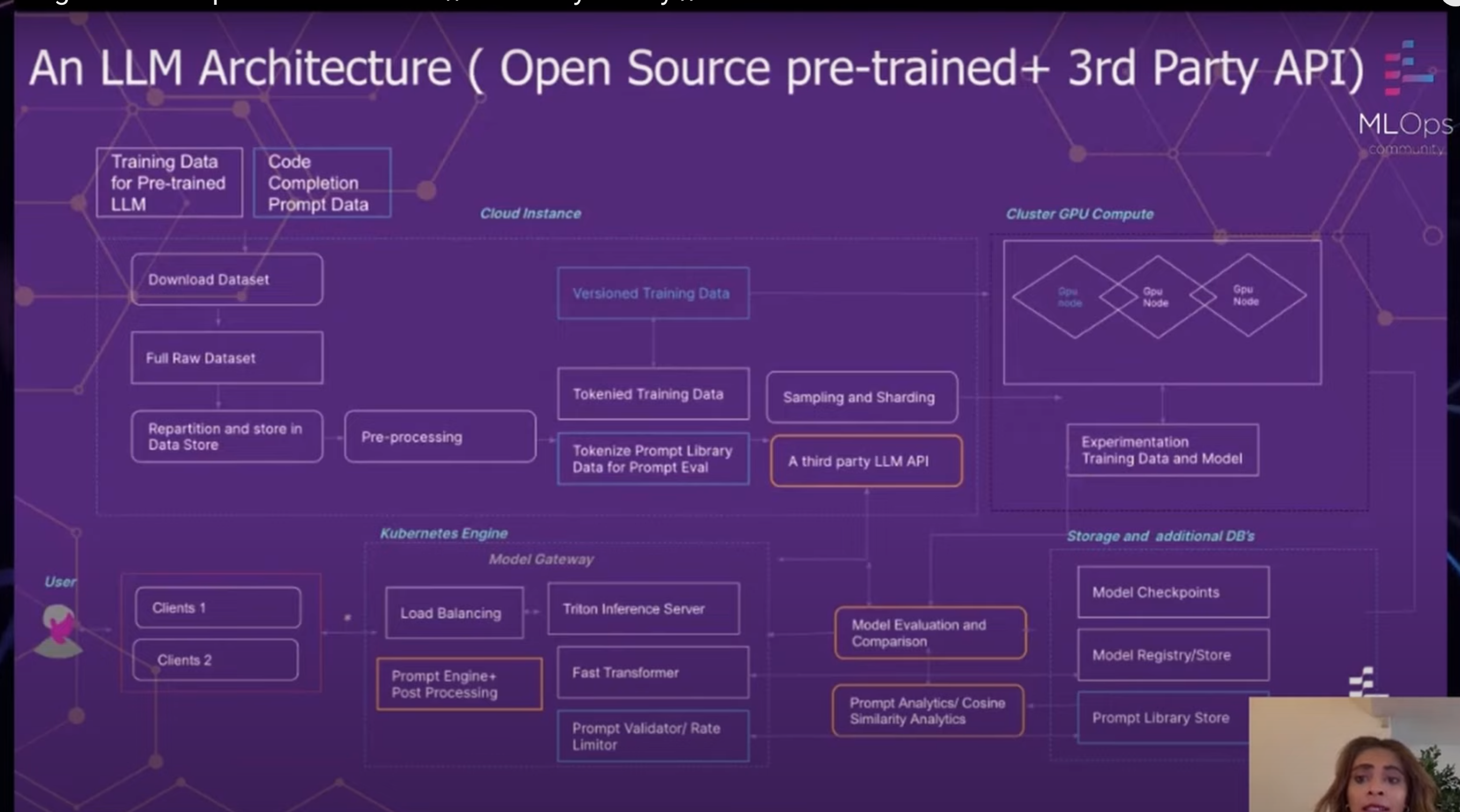
تتكون هذه الهندسة من عدة مكونات رئيسية:
تُعد بنية LLM الخاصة بـ GitLab أداة قوية تمكّن GitLab من تدريب وتقييم ونشر نماذج اللغة الكبيرة (LLMs) على نطاق واسع. تم تصميم البنية لتكون مرنة وقابلة للتوسع، بحيث يمكن لـ GitLab تبني التقنيات الجديدة بسهولة وتلبية احتياجات مستخدميها.
لا تزال نماذج اللغة الكبيرة (LLMs) تقنية جديدة نسبيًا، ولكن لديها القدرة على إحداث ثورة في العديد من الصناعات. تعتقد GitLab أن نماذج LLMs سيكون لها تأثير كبير على صناعة تطوير البرمجيات.
تستخدم GitLab بالفعل نماذج LLMs لتحسين منتجاتها وخدماتها. على سبيل المثال، تستخدم GitLab نماذج LLMs لإنشاء اقتراحات التعليمات البرمجية، وشرح الثغرات الأمنية، وتحسين تجربة المستخدم لمنتجاتها.
تعتقد GitLab أنه يجب على المنظمات الأخرى أيضًا الاستثمار في نماذج اللغة الكبيرة (LLMs). تتمتع نماذج LLMs بالقدرة على تحسين الإنتاجية والكفاءة والجودة في العديد من الصناعات.
توصي GitLab المنظمات بالاستثمار في المجالات التالية للبقاء في الطليعة في مجال نماذج اللغة الكبيرة (LLM):
من خلال الاستثمار في هذه المجالات، يمكن للمؤسسات البقاء في طليعة مجال نماذج اللغة الكبيرة (LLM) وجني ثمار هذه التقنية القوية.
تابعوا مشاهدة TrueML سلسلة يوتيوب وقراءة TrueML سلسلة المدونات.
TrueFoundry هي منصة كخدمة (PaaS) لنشر تعلم الآلة (ML) عبر Kubernetes لتسريع سير عمل المطورين مع منحهم مرونة كاملة في اختبار ونشر النماذج، مع ضمان الأمان والتحكم الكامل لفريق البنية التحتية. من خلال منصتنا، نمكّن فرق تعلم الآلة من نشر ومراقبة النماذج في 15 دقيقة بموثوقية وقابلية للتوسع بنسبة 100%، والقدرة على التراجع في ثوانٍ - مما يسمح لهم بتوفير التكاليف وإطلاق النماذج إلى الإنتاج بشكل أسرع، وبالتالي تحقيق قيمة تجارية حقيقية.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








أحدث الأخبار والمقالات والموارد تصلك مباشرة إلى بريدك الوارد
© 2026 جميع الحقوق محفوظة.








.png)
.webp)










.webp)
