




August 27, 2025
|
5 min read


احصل على وصول فوري إلى بيئة TrueFoundry مباشرة. انشر النماذج، ووجّه حركة مرور LLM، واستكشف المنصة بالكامل — بيئة الاختبار الخاصة بك جاهزة في ثوانٍ، ولا يلزم وجود بطاقة ائتمان.









Published: July 4, 2026
Blazingly fast way to build, track and deploy your models!
في العدد الأخير، استعرضنا سير عمل عالم البيانات، وأين يمكن أن يكون Kubernetes قاعدة مفيدة لبناء منصة له.
في هذا العدد، دعنا نستعرض مثالاً بسيطاً لاكتساب خبرة عملية في هذا الصدد.
قبل البدء، نحتاج إلى بيئة عمل لإجراء العرض التوضيحي. سنقوم بإعداد مجموعة Kubernetes على الجهاز المحلي للقيام بذلك. على الرغم من أن المجموعة يجب أن تحتوي على عقد متعددة لتحمل الأخطاء والتوافر العالي، إلا أننا سنحاكي هذا السلوك باستخدام أداة رائعة kind (kubernetes-in-docker).
في نهاية هذا القسم، سيكون لدينا عدة حاويات تعمل، بحيث تعمل كل حاوية كعقدة مجموعة منفصلة.
اتبع الإرشادات المتوفرة هنا
اختبر التثبيت بتشغيل
$ kind --version
kind version 0.14.0
الآن نبدأ مجموعة محلية باستخدام kind. سنقوم بإنشاء عقدة مستوى تحكم واحدة وعقدتي عامل. من الممكن أن يكون هناك عدة من كليهما.
<aside> 💡 يمكن أن تحتوي Kubernetes على عدة عقد لمستوى التحكم وعقد عاملة. تعيش جميع مكونات إدارة المجموعة المركزية على عقد مستوى التحكم بينما تعمل أحمال عمل المستخدم على العقد العاملة. اقرأ المزيد هنا
</aside>
أولاً، أنشئ kind تهيئة في ملف يسمى kind-config.yaml. يمكنك العثور عليه هنا. سيحدد هذا بنية مجموعتنا -
kind: Cluster
apiVersion: kind.x-k8s.io/v1alpha4
nodes:
- role: control-plane
- دور: عامل
- دور: عامل
هنا، قمنا بتعريف ثلاث عقد، واحدة منها بدور مستوى التحكم والاثنتين الأخريين كعقد عاملة.
شغّل مجموعة باستخدام هذا التكوين. قد يستغرق هذا بعض الوقت. تأكد من أن خدمة Docker تعمل على نظامك قبل تنفيذ هذا -
$ kind create cluster --config kind-config.yaml
...
شكراً لاستخدامك kind! 😊
kubectl للتأكد من أن مجموعتنا تعمل -$ kubectl cluster-info
مستوى التحكم في Kubernetes يعمل على <https://127.0.0.1:63122>
CoreDNS يعمل على <https://127.0.0.1:63122/api/v1/namespaces/kube-system/services/kube-dns:dns/proxy>
...
هذا يخبرنا أن المجموعة تعمل بالفعل. يمكننا أيضاً رؤية الحاويات الفردية التي تعمل كعقد عن طريق تنفيذ docker ps.
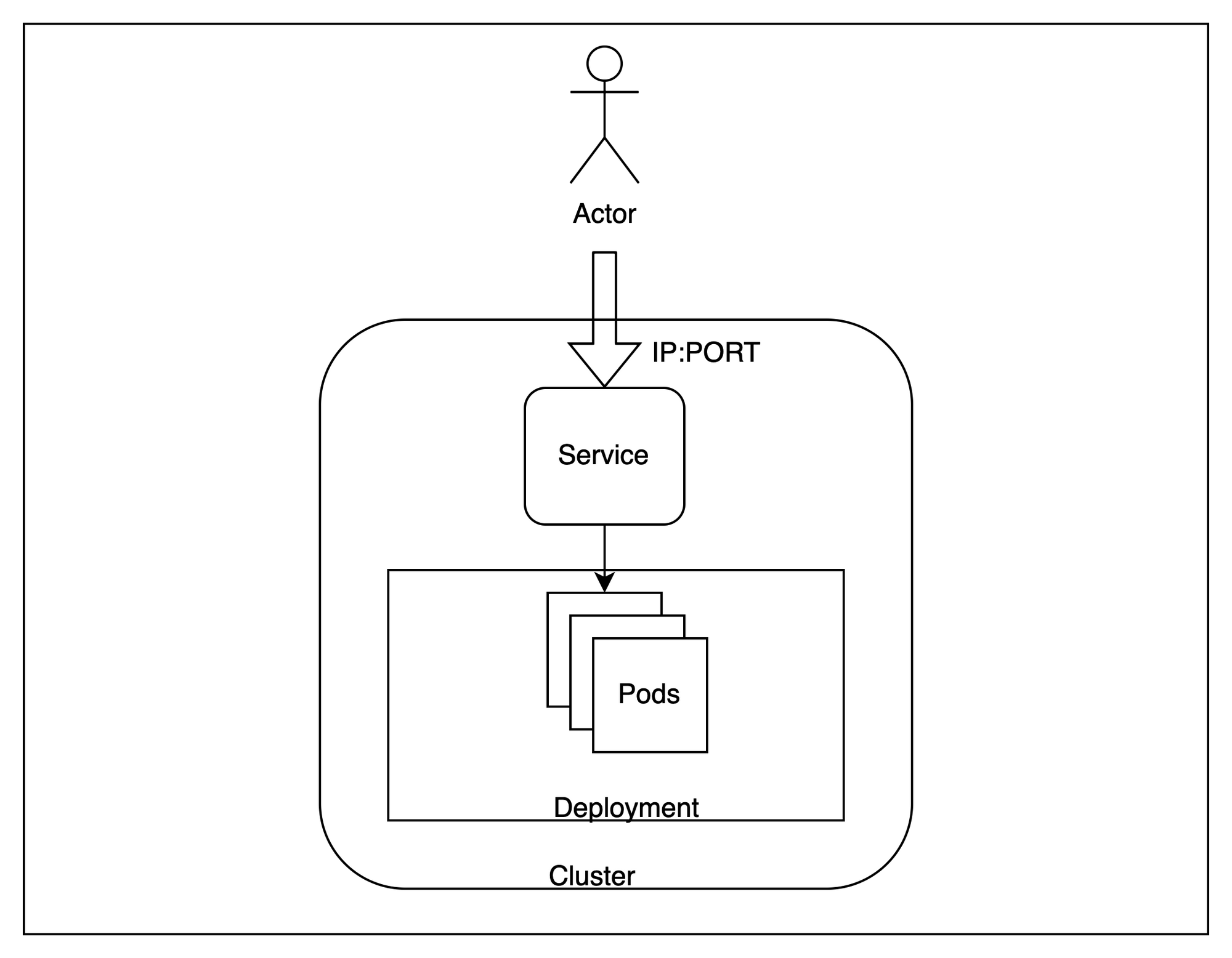
بعد أن أصبحت مجموعتنا جاهزة، دعنا نلقي نظرة على بنية عامة لما سنقوم بتوفيره.
بشكل عام، سنستضيف نسخًا متعددة من تطبيقنا داخل التجمع (cluster) ونحاول الوصول إليها من الخارج مع موازنة التحميل للطلبات عبر المثيلات المختلفة.
لتحقيق ذلك، هناك بعض المصطلحات الخاصة بـ Kubernetes التي يجب أن نكون على دراية بها -
بود (Pod) - البودات (Pods) هي أصغر وحدات الحوسبة القابلة للنشر التي يمكنك إنشاؤها وإدارتها في Kubernetes. في حالتنا، سيعمل مثيل واحد من التطبيق داخل بود مستقل واحد. هذه موارد مؤقتة، ويمكن لمستوى التحكم نقلها بين العقد إذا لزم الأمر.نشر (Deployment) - النشر (Deployment) مفيد عندما نريد الحصول على أكثر من نسخة متماثلة (replica) لتطبيق ما. تحاول Kubernetes دائمًا الحفاظ على عدد النسخ المتماثلة مساويًا لما هو محدد في النشر. سنقوم بإنشاء ثلاث نسخ متماثلة متطابقة لتطبيقنا.خدمة (Service) - الخدمة (Service) مفيدة لموازنة التحميل عبر مجموعة من البودات التي تعمل على التجمع (cluster). نظرًا لأن البودات مؤقتة بطبيعتها ويمكن استبدالها في أي وقت، توفر الخدمة واجهة مستقرة للوصول إلى البودات التي تعمل خلفها. سنستخدم خدمة لاختبار تطبيقنا.ستمكننا هذه الموارد الثلاثة من استضافة نقطة نهاية قابلة للتوسع لتقديم تطبيقنا.
مع جاهزية التجمع (cluster)، يمكننا الآن نشر تطبيق واختباره. سنقوم بإنشاء تطبيق باستخدام مجموعة بيانات مصنف القزحية (iris classifier) الشهيرة.
المستودع متاح على https://github.com/shubham-rai-tf/iris-classifier-kubernetes. يحتوي بالفعل على الكود لبناء وتقديم التنبؤات عند /iris/classify_iris نقطة النهاية باستخدام fastapi.
نحتاج إلى تغليف هذا الكود في صورة دوكر لإعداده لـ kubernetes. يتوفر Dockerfile في المستودع للقيام بذلك - هنا.
يحدد هذا الـ Dockerfile الصورة التي سنحتاجها لإنشاء حاوية تستضيف نقاط نهاية التنبؤ في خادم uvicorn على المنفذ 5000. مزيد من التفاصيل حول بناء الجملة متاح هنا.
نفّذ هذا الأمر لبناء صورة محلية -
$ docker build . -t iris-classifier:poc
...
$ docker image ls
REPOSITORY TAG IMAGE ID CREATED SIZE
iris-classifier poc 549913d5b1f9 12 seconds ago 737MB
يمكننا أن نرى أنه تم إنشاء الصورة بنجاح بالاسم iris-classifier والعلامة poc. سنقوم الآن بتحميل هذه الصورة إلى المجموعة لاستخدامها داخل المجموعة
<aside> 💡 هذه الخطوة ضرورية فقط لأنه ليس لدينا سجل صور لسحب الصورة التي تم إنشاؤها حديثًا منه. في بيئة الإنتاج، يجب استضافة الصورة في سجل خاص مثل Dockerhub أو AWS ECR ثم سحبها إلى المجموعة مباشرةً
</aside>
نفّذ هذا الأمر لتحميل الصورة التي تم إنشاؤها محليًا إلى المجموعة -
$ kind load docker-image iris-classifier:poc
الصورة: "iris-classifier:poc" بالمعرف "sha256:549913d5b1f9456a4beedc73e04c3c0ad70da8691a8745a6b56a4f483c4f0862" غير موجودة بعد على العقدة "kind-worker2"، جارٍ التحميل...
الصورة: "iris-classifier:poc" بالمعرف "sha256:549913d5b1f9456a4beedc73e04c3c0ad70da8691a8745a6b56a4f483c4f0862" غير موجودة بعد على العقدة "kind-control-plane"، جارٍ التحميل...
...
يمكنك التحقق من تحميل الصور عن طريق سرد الصور داخل أي من الحاويات الثلاثة -
$ docker exec -it kind-worker crictl images
IMAGE TAG IMAGE ID SIZE
docker.io/library/iris-classifier poc 549913d5b1f94 753MB
Kubernetes هو في الأساس نظام تصريحي. وهذا يعني أننا نصف الخطوط العريضة لما نريد القيام به، وتقوم مكونات مستوى التحكم باستمرار بدفع النظام نحو تحقيق تلك الحالة.
لتطبيق البنية التي ناقشناها سابقًا، سنصف نيتنا في شكل yaml ملف يعمل كسجل للنية. في مصطلحات Kubernetes، تُسمى هذه بـ المانيفست.
تحتوي جميع ملفات المانيفست في Kubernetes على الحقول التالية -
apiVersion - يتم تجميع موارد متعددة معًا في نفس إصدارات API. يوفر هذا طريقة موحدة لإهمال أو ترقية مورد عبر إصدارات Kubernetes.kind - يحدد نوع الكائن الدقيق الذي سيتم إنشاؤهmetadata - يحتوي على حقول تعمل كبيانات وصفية (metadata) للكائن الذي تم إنشاؤه. تحدد حقول apiVersion، kind و metadata.name معًا موردًا فريدًا داخل namespacespec - يحتوي هذا الحقل على المواصفات الخاصة بالكائن المراد إنشاؤه. يحدد كل نوع بنيته الخاصة لهذا الحقل مع تنفيذه الخاص.سنستخدم البيانات التعريفية الموجودة في المستودع ضمن الملفات داخل manifests دليل هنا.
تحدد موردين من موارد Kubernetes، Deployment و Service في deployment.yaml و service.yaml على التوالي. دعنا نستعرض كلا القسمين.
apiVersion: apps/v1
kind: Deployment
spec:
# عدد النسخ المتماثلة
replicas: 3
قالب:
مواصفات:
حاويات:
# اسم الصورة
- image: iris-classifier:poc
name: iris-classifier
يحدد بيان النشر في deployment.yaml بشكل أساسي مواصفات الـ pod التي نريد نشرها من حيث اسم الصورة وعدد النسخ المتماثلة. بمجرد تطبيق هذا، ستتخذ Kubernetes خطوات مستمرة للحفاظ على عدد النسخ المتماثلة كما نحدده هنا.
apiVersion: v1
النوع: خدمة
مواصفات:
# نوع الخدمة
النوع: ClusterIP
المنافذ:
# المنفذ الذي ستكون الخدمة متاحة عليه
- المنفذ: 8080
# المنفذ على الحاوية الذي سيتم توجيه حركة المرور إليه
المنفذ المستهدف: 5000
البروتوكول: TCP
المحدد:
التطبيق: iris-classifier
ملف تعريف الخدمة في service.yaml يحدد كيفية موازنة التحميل عبر النسخ المتماثلة التي أنشأها النشر. هنا، حددنا كيفية ربط المنفذ على الخدمة بالمنفذ على الحاويات. بما أن تطبيقنا يعمل على المنفذ 5000، فإن الـ targetPort مضبوط على 5000. يتم عرض الخدمة على المنفذ 8080. سيتم موازنة تحميل حركة مرور TCP المرسلة إلى 8080 عبر المنفذ 5000 على الحاويات.
قم بتشغيل الأمر التالي لتطبيق ملفات التعريف على Kubernetes -
$ kubectl apply -f manifests/
deployment.apps/iris-classifier تم الإنشاء
service/iris-classifier تم الإنشاء
تم إنشاء كلا الموردين بنجاح على المجموعة. يمكننا التحقق من ذلك بتشغيل الأوامر التالية -
$ kubectl get service iris-classifier
الاسم النوع IP المجموعة IP الخارجي المنفذ (المنافذ) العمر
iris-classifier ClusterIP 10.96.107.238 <none> 8080/TCP 37د
$ kubectl get deployment iris-classifier
الاسم جاهز محدث متاح العمر
iris-classifier 3/3 3 3 38د
$ kubectl get pods
الاسم جاهز الحالة إعادة التشغيل العمر
iris-classifier-5d97498ff9-77wqw 1/1 قيد التشغيل 0 39د
iris-classifier-5d97498ff9-8twjm 1/1 قيد التشغيل 0 39د
iris-classifier-5d97498ff9-znrz8 1/1 قيد التشغيل 0 39د
كما نرى، الخدمة مكشوفة على المنفذ 8080 وتم إنشاء ثلاثة pods كما حددنا.
عدّل deployment.yaml ليصبح عدد النسخ المتماثلة 2 بدلاً من 3 وأعد التطبيق. سيقوم Kubernetes بحذف إحدى النسخ المتماثلة لتتوافق مع المواصفات.
الآن بعد أن تم إنشاء الموارد في المجموعة، يمكننا التحقق من نشرنا عن طريق استدعاء النموذج باستخدام نقطة نهاية الخدمة. بما أننا نستخدم إعدادًا محليًا، سيتعين علينا إعادة توجيه المنفذ الخدمة إلى منفذ على الجهاز المحلي.
<aside> 💡 في إعداد مزود خدمة سحابية، سيتم ربط هذه الخدمة بموازن تحميل خارجي يمكن الوصول إليه من الإنترنت إذا لزم الأمر.
</aside>
قم بتشغيل الأمر التالي لإجراء إعادة توجيه المنفذ للخدمة -
$ kubectl port-forward services/iris-classifier 8080
إعادة التوجيه من 127.0.0.1:8080 -> 5000
إعادة التوجيه من [::1]:8080 -> 5000
يمكننا التحقق من ذلك عن طريق استدعاء الـ /healthcheck نقطة نهاية على النموذج -
$ curl '<http://localhost:8080/healthcheck>'
"مصنف Iris جاهز!"
لإجراء تنبؤ اختباري، سنرسل مدخلات عينة للحصول على تنبؤ -
$ curl '<http://localhost:8080/iris/classify_iris>' -X POST \\
-H 'Content-Type: application/json' \\
-d '{"sepal_length": 2, "sepal_width": 4, "petal_length": 2, "petal_width": 4}'
{"class":"setosa","probability":0.99}
نحصل على تنبؤ للفئة setosa باحتمالية 99%. من خلال تشغيل العديد من هذه التنبؤات، يمكننا التحقق من أن الطلبات يتم توجيهها بالفعل إلى وحدات (pods) مختلفة بطريقة التناوب.
لنقم بإزالة جميع موارد Kubernetes التي قمنا بتثبيتها أولاً -
$ kubectl delete -f manifests/
سيؤدي هذا إلى تنظيف جميع موارد Kubernetes التي أنشأناها في الأقسام السابقة. الآن يمكننا إيقاف تشغيل المجموعة (cluster) أيضًا -
$ kind delete cluster
جارٍ حذف المجموعة "kind" ...
في هذا المقال، استعرضنا كيفية استضافة نموذج كخدمة قابلة للاستدعاء في Kubernetes. على الرغم من أن هذا كان مثالاً توضيحيًا بسيطًا حيث قمنا ببناء صورة Docker محليًا وتشغيلها على مجموعة (cluster) تعمل على نفس الجهاز، إلا أن إعداد الإنتاج النموذجي يعمل على مبادئ مماثلة. يمكن تحقيق الكثير باستخدام هذين الموردين فقط.
في الأعداد اللاحقة، سنستكشف ميزات أخرى أكثر تقدمًا مثل تعدد المستأجرين والتحكم في الوصول، والتي تصبح ضرورية مع انتقالنا إلى عمليات اليوم الثاني.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








أحدث الأخبار والمقالات والموارد تصلك مباشرة إلى بريدك الوارد
© 2026 جميع الحقوق محفوظة.











.png)
.webp)










.webp)
