




July 4, 2026
|
5 min read


احصل على وصول فوري إلى بيئة TrueFoundry مباشرة. انشر النماذج، ووجّه حركة مرور LLM، واستكشف المنصة بالكامل — بيئة الاختبار الخاصة بك جاهزة في ثوانٍ، ولا يلزم وجود بطاقة ائتمان.









Published: July 4, 2026

Blazingly fast way to build, track and deploy your models!
باختصار: Kimi-K2 Thinking (Moonshot AI) هو نموذج "تفكير" مفتوح الوزن وواعٍ بالأدوات يدفع حدود التفكير متعدد الخطوات، وتنسيق الأدوات طويل الأمد، ونوافذ السياق الضخمة. في اختبار البشرية الأخير (HLE) والعديد من معايير الأنظمة الوكيلة، يحقق أرقامًا رائدة (خاصة عند تمكين الوصول إلى الأدوات)، مما يؤكد بقوة أن الحدود الكبيرة التالية في نماذج اللغة الكبيرة (LLMs) هي التفكير + الأدوات + السياق الطويل، وليس مجرد عدد المعاملات الخام.
استخدم بوابة الذكاء الاصطناعي من Truefoundry لتجربتها الآن.
لقد أخبرتنا المعايير مثل MMLU واختبارات البرمجة ومعايير الدردشة الكثير، لكنها لا تقيس بشكل كامل التفكير متعدد الخطوات، أو تنسيق الأدوات، أو التخطيط طويل الأمد. فئة جديدة من نماذج "التفكير" تتدرب صراحة على هذه القدرات: يجب على النموذج أن يدمج التفكير الداخلي خطوة بخطوة مع استدعاءات الأدوات الخارجية (البحث، مفسرات الأكواد، تصفح الويب)، وأن يحافظ على الترابط عبر العديد من الخطوات المتتالية.
يُعد Kimi-K2 Thinking مثالاً رائداً لهذا الاتجاه. لقد صُمم كنظام وكيل ذكي: فهو يفكر، ويقرر استدعاء الأدوات، ويستوعب مخرجات الأدوات، ويواصل التفكير — كل ذلك مع الحفاظ على السياق عبر مئات الخطوات. النتيجة: مكاسب كبيرة في معايير "التفكير" الصعبة مثل HLE و BrowseComp.
أبرز النقاط التقنية الرئيسية من بطاقة النموذج الرسمية:
هذه العناصر — نطاق MoE، والسياق الضخم، والتنسيق الواضح للأدوات، والاستدلال الفعال منخفض البتات — هي اللبنات الأساسية التي تسمح لـ Kimi-K2 بالتصرف كوكيل أكثر من كونه محولًا للمحادثة.
امتحان البشرية الأخير (HLE) يهدف إلى أن يكون معيارًا صعبًا للغاية على غرار الامتحانات يركز على الاستدلال الحقيقي، وليس الاسترجاع أو الاختصارات. يحتوي على مسائل معقدة ومتعددة الخطوات غالبًا في مجالات الرياضيات والعلوم والهندسة ومواضيع أخرى. نظرًا لأن مسائل HLE تتطلب عادةً استدلالًا متعدد الخطوات، وفي بعض الحالات، بحثًا خارجيًا أو حسابات، فهو اختبار إجهاد ممتاز للوكلاء القادرين على استخدام الأدوات وذوي السياق الطويل. ركز تطوير Kimi-K2 على HLE ومعايير الوكلاء الأخرى — وتبرز بطاقة النموذج HLE كأحد أهداف التقييم الأساسية.
وفقًا لنتائج التقييم المنشورة من Moonshot AI:
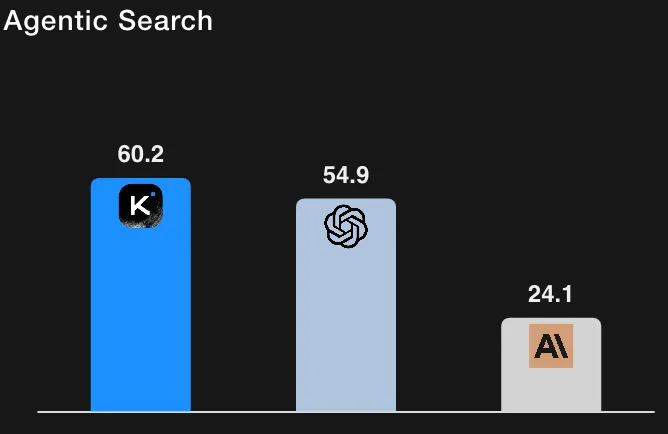
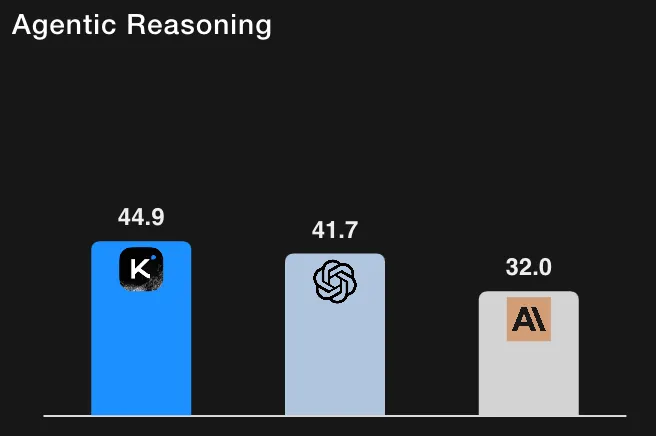
للمقارنة، حقق GPT-5 (إصدار عالي) حوالي 41.7% في HLE باستخدام الأدوات (إعادة تشغيلهم الداخلية) و Claude Sonnet 4.5 حوالي 32.0% (وضع التفكير). وبالتالي، تضع نتائج Kimi-K2 النموذج متقدمًا على الخطوط الأساسية المبلغ عنها في تشغيل HLE المدعوم بالأدوات. (جميع الأرقام مأخوذة من جدول تقييم Moonshot AI والحواشي).
فروق دقيقة مهمة: توثق بطاقة النموذج بعناية كيفية التعامل مع الوصول إلى الأدوات، وإعدادات المحكم، وميزانيات الرموز، وحدود السياق؛ ويشير المؤلفون أيضًا إلى أن بعض الأرقام الأساسية أُخذت من منشورات رسمية بينما أُعيد اختبار البعض الآخر داخليًا. باختصار: هذه مؤشرات قوية، ولكن يجب على القراء ملاحظة أنها مقدمة من Moonshot AI وتعتمد على بروتوكول التقييم المفصل الموضح مع النتائج.
أخذنا عينة من 50 صفًا من البيانات من HLE، وهذه هي النتائج
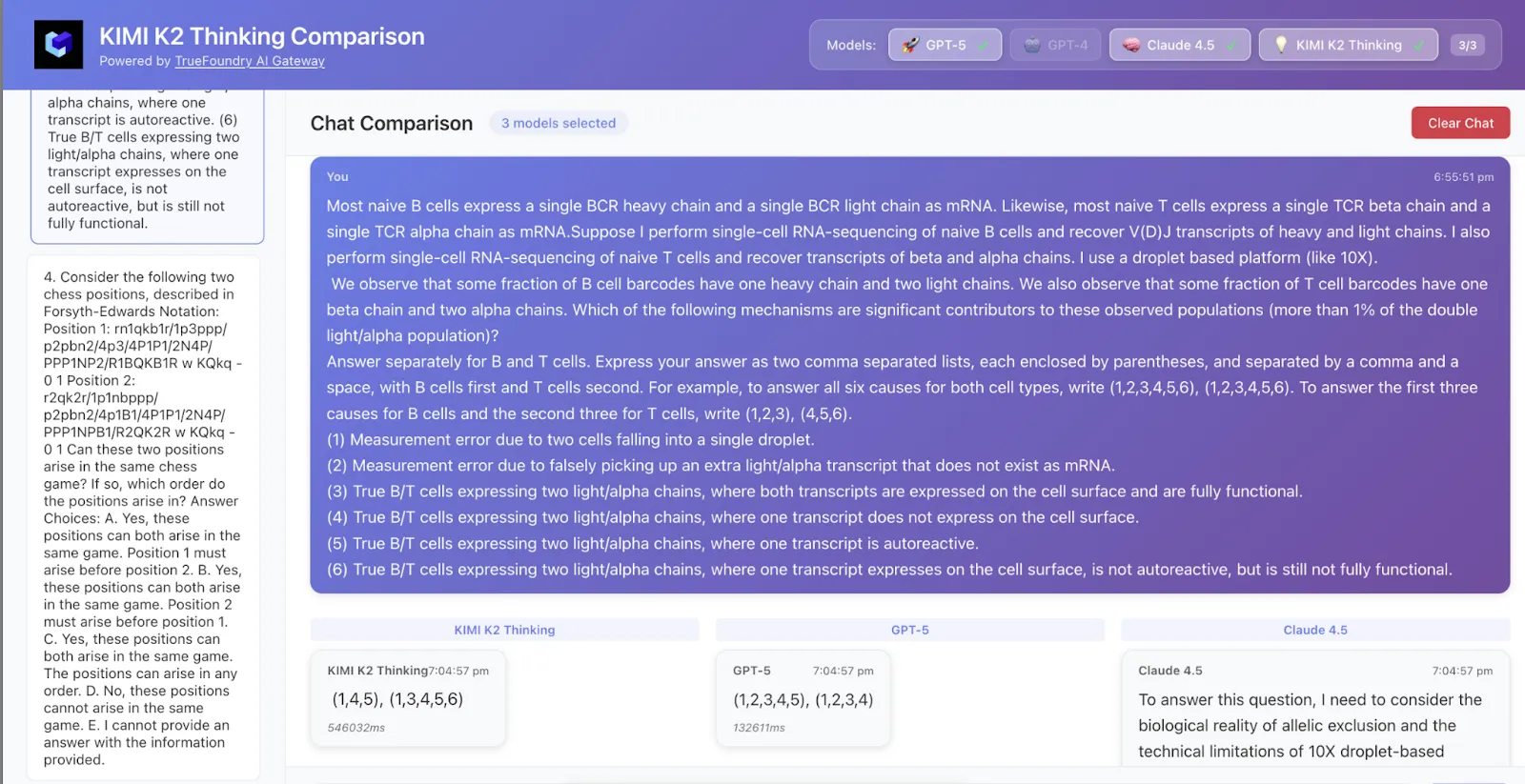
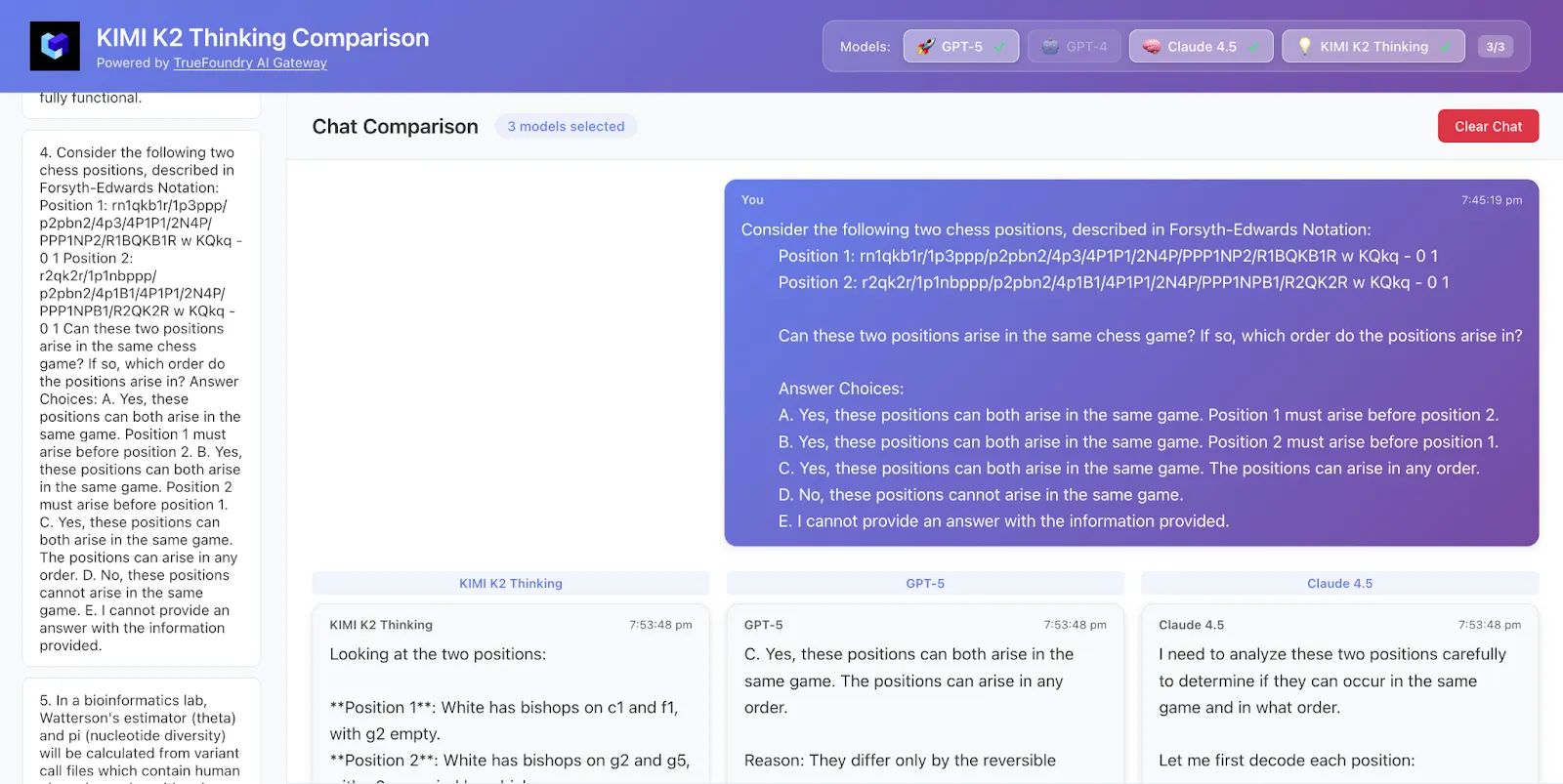
حصل Kimi K2 على الإجابة والمنطق الصحيحين، بينما حصل GPT-5 على الإجابة الصحيحة فقط، ولم يكن كلود صحيحًا.
تضاعف أداء Kimi-K2 تقريبًا مضاعفة في HLE من عدم استخدام الأدوات إلى استخدامها (≈24% إلى 45%) يوضح نقطة حاسمة:
ببساطة: تشير مكاسب HLE إلى أن المشكلة الأساسية هي كيف يستدل النموذج ويستخدم الأدوات، وليس فقط حجم النموذج الخام.
أبعد من المعايير، الأكثر إثارة هو مدى سهولة الوصول إلى هذا النوع من الإمكانات. لا يتعين عليك الانتظار لأشهر للتجربة — يمكنك تجربته بنفسك. TrueFoundry AI Gateway يسهّل الوصول إلى Kimi-K2 Thinking والنماذج المتطورة الأخرى مباشرةً، وقياس أدائها على بياناتك الخاصة، أو دمجها في سير العمل.
إذا كنت ترغب في الحصول على مساعدة أكثر تخصيصًا، احجز عرضًا توضيحيًا — يمكن للفريق أن يشرح لك الأداء، وخيارات النشر، والتكلفة، وكيفية تقييم هذه النماذج لمهامك. نحن نبقى على اطلاع دائم بالسوق ونتأكد من توفير النماذج الجديدة لك بأسرع وقت ممكن.
الخلاصة: Kimi-K2 Thinking ليس مجرد نموذج لغوي كبير آخر (LLM) — إنه لمحة واضحة عن مستقبل الوكلاء القادرين على الاستدلال: مفتوح، فعال، مدرك للأدوات، ومُعدّ لحل المشكلات متعددة الخطوات. جربه، قارنه بمشكلاتك الخاصة، وشاهد الفارق الذي يحدثه تنسيق الأدوات الوكيلية في المهام الحقيقية.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








أحدث الأخبار والمقالات والموارد تصلك مباشرة إلى بريدك الوارد
© 2026 جميع الحقوق محفوظة.







.png)
.webp)










.webp)
