




November 5, 2025
|
5 min read


احصل على وصول فوري إلى بيئة TrueFoundry مباشرة. انشر النماذج، ووجّه حركة مرور LLM، واستكشف المنصة بالكامل — بيئة الاختبار الخاصة بك جاهزة في ثوانٍ، ولا يلزم وجود بطاقة ائتمان.









Published: July 4, 2026

Blazingly fast way to build, track and deploy your models!
يبدو بناء نموذج لحل حالة استخدام تجارية فكرة رائعة لنا جميعًا. يبدو بديهيًا أنه إذا تمكنا من زيادة التفاعل من خلال التخصيص على موقع ويب معين باستخدام تعلم الآلة بنسبة 5%، فإن ذلك سيدفع الإيرادات للارتفاع بنسبة معينة.
ومع ذلك، غالبًا ما يتم التغاضي عن عاملين يمكن أن يعرضا هذا المشروع للخطر:
حسنًا، ألا ينبغي أن يكون اختبار هذين الأمرين بسيطًا؟ دعنا نتعمق في ما يتطلبه الأمر للانتقال من فكرة بناء نموذج إلى وضع النموذج في الإنتاج وتقييم تأثيره التجاري. لنفترض أن تطبيق توصيل طعام يريد عرض الوقت المتوقع للتسليم بمجرد أن يطلب العميل طلبًا عبر التطبيق. بما أننا لا نعرف وقت التسليم مسبقًا، سنحتاج إلى بناء نموذج تعلم آلة يمكنه إجراء التنبؤ بناءً على عوامل معينة مثل المدينة، المطعم، وقت اليوم، المسافة من العميل إلى المطعم، إلخ.
عرض وقت التسليم المقدر للمستخدم لتطبيق توصيل طعام
سير العمل لإخراج هذا النموذج سيشمل الفرق التالية:
سيقوم مدير المنتج بابتكار المشروع لتقدير وقت التسليم. التوقع هو أنه إذا كان وقت التسليم دقيقًا بشكل معقول، فإنه سيوفر تجربة أفضل للمستخدمين. ستكون هناك استفسارات أقل من العملاء تتعلق بأوقات التسليم، ويجب أن يرتفع إجمالي نقاط رضا العملاء. سيطلب فريق العمل بعد ذلك من فريق علم البيانات تطوير هذا النموذج.
يبدأ علماء البيانات بجمع البيانات التاريخية لجميع الطلبات التي تم إجراؤها وأوقات تسليمها.
سيقوم عالم البيانات بعد ذلك بتحليل البيانات للتأكد من صحة كل شيء - لا توجد قيم فارغة أو خاطئة، وأن جميع البيانات المطلوبة موجودة. في كثير من الأحيان، سيكتشف عالم البيانات بعض الأخطاء في مجموعة البيانات - أو ربما تكون هناك أيام قليلة من البيانات السيئة بسبب بعض الأخطاء العابرة. سنحتاج إلى استبعاد البيانات الخاطئة لأنه عندها فقط يمكننا بناء نموذج جيد. قد يؤدي هذا إلى عدة تكرارات مع فريق المنتج وهندسة البيانات.
بمجرد أن تبدو البيانات جيدة، في بعض الحالات، سيرغب علماء البيانات في إنشاء مسار لحساب الميزات وتخزينها لضمان عدم وجود انحراف بين التدريب والخدمة، وتسهيل الحصول على قيم الميزات أثناء الاستدلال.
ومع ذلك، هذه خطوة اختيارية ويتم تخطيها عندما تكون البيانات أو عدد النماذج المبنية على نفس مجموعة البيانات صغيرًا. في حال قرر فريق ما القيام بهندسة الميزات، سنحتاج إلى نظام تنسيق مسارات مثل Airflow وPrefect وقاعدة بيانات / ذاكرة تخزين مؤقت لتخزين الميزات لاسترجاعها (على سبيل المثال Feast). إن بناء متجر ميزات هو بحد ذاته مهمة ضخمة ويتطلب جهدًا كبيرًا.
بمجرد أن تصبح البيانات جاهزة بالكامل، سيقوم عالم البيانات الآن بتجربة خوارزميات وميزات ونماذج مختلفة لمعرفة أيها يقدم أفضل أداء. سيرغبون في تسجيل جميع المقاييس والمعاملات والنماذج حتى يتمكنوا من الرجوع إليها لاحقًا أو مشاركتها مع أعضاء الفريق الآخرين. هنا يأتي دور تتبع التجارب ومتجر بيانات تعريف النموذج.
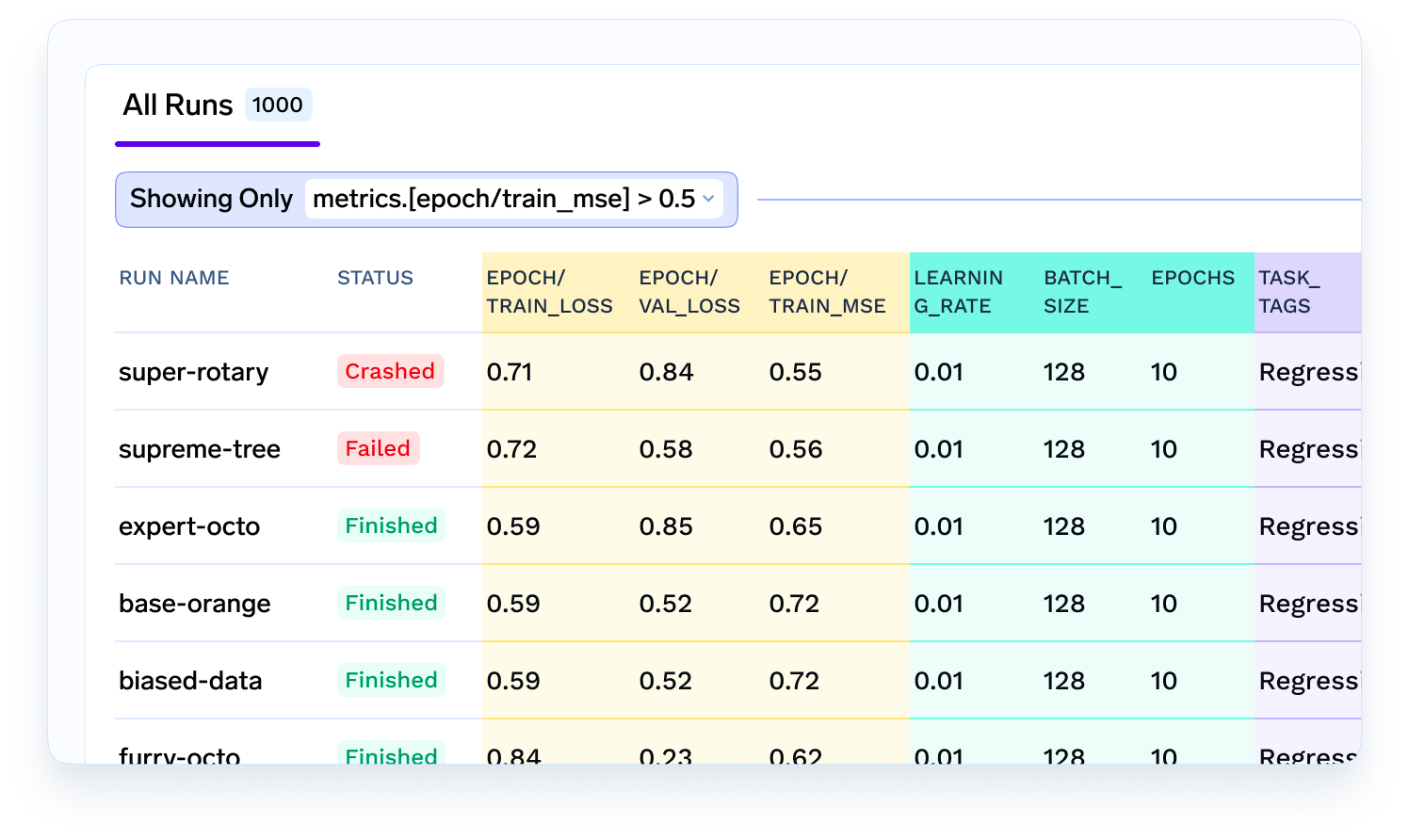
بمجرد بناء النموذج، يجب استضافته كخدمة مصغرة (microservice) أو كعملية استدلال دفعي (batch inference job). في حالتنا لتوقع وقت التسليم، يجب أن تكون هذه خدمة فورية عبر الإنترنت - لذا من المنطقي نشرها كخدمة ذاتية التوسع (autoscaling service). في هذه الحالة، يتدخل مهندس تعلم الآلة الذي يأخذ النموذج، ويغلفه في خدمة Flask أو FastAPI ويبني صورة Docker. ثم يقوم مهندس تعلم الآلة بمساعدة فريق DevOps بنشره كخدمة مصغرة على البنية التحتية.
بمجرد استضافة واجهة برمجة تطبيقات النموذج (API)، سيحتاج فريق المنتج أو الواجهة الخلفية إلى استدعاء واجهة برمجة التطبيقات في تعليماتهم البرمجية للاستفادة من وقت التسليم المتوقع وعرضه على التطبيق. سيتطلب هذا تعاونًا بين فرق عالم البيانات والمنتج وهندسة تعلم الآلة. خلال هذا الوقت، قد يرغب مدير المنتج في اختبار التوقعات، وسيكون رائعًا إذا تمكنوا من اختبار النموذج بسرعة على بعض المدخلات النموذجية. قد يتطلب هذا بناء عرض توضيحي سريع للنموذج.
بمجرد نشر النموذج واستخدامه في المنتج، سنحتاج إلى مقاييس حول النموذج المنشور.
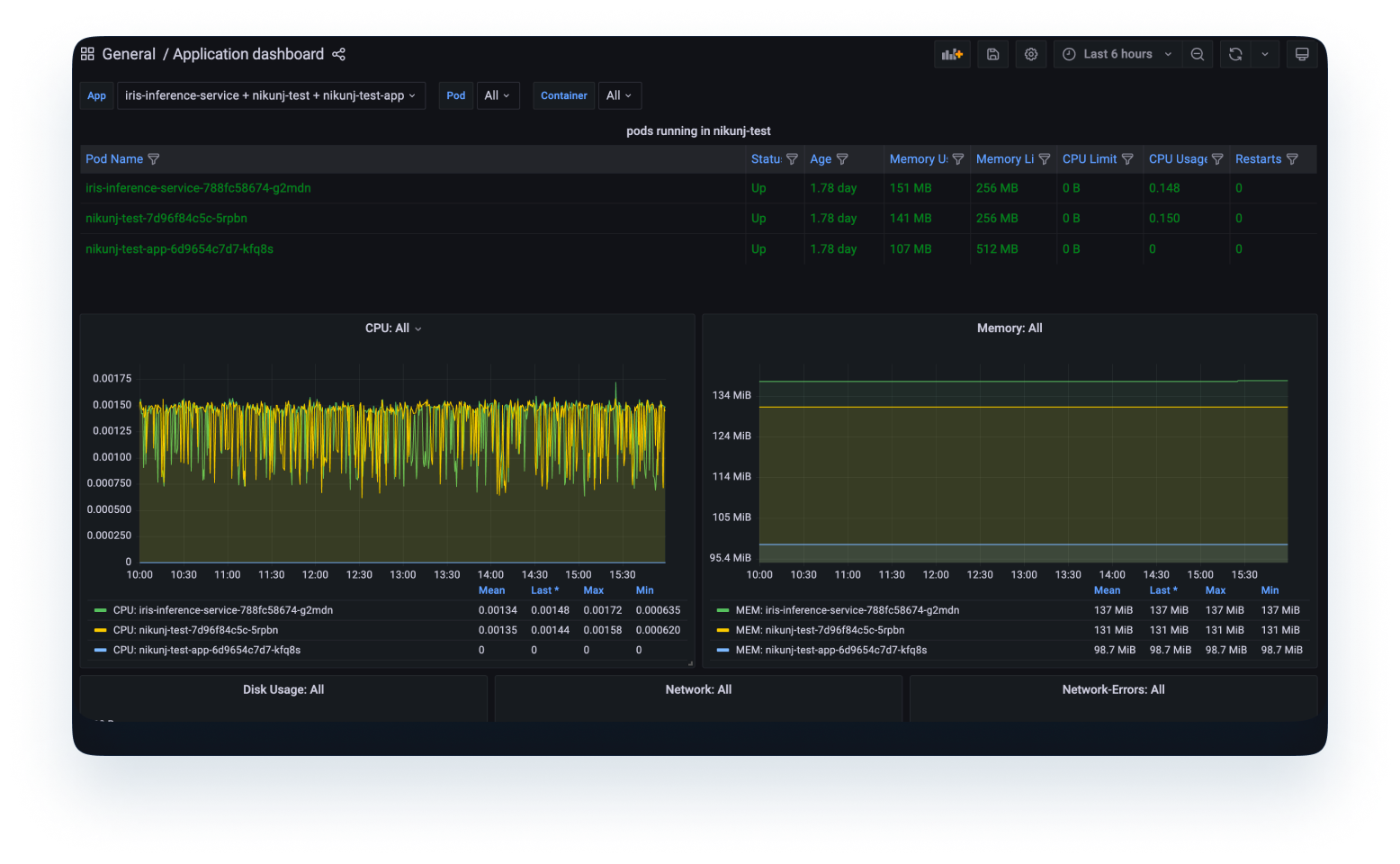
2. مراقبة النموذج: يتضمن ذلك المقاييس المتعلقة بتنبؤ النموذج على بيانات الإنتاج الواردة. هذه هي البيانات التي سيهتم بها عالم البيانات بشكل أساسي، وتشمل مقاييس مثل دقة النموذج، وانحراف الميزات، وانحراف التنبؤ، وما إلى ذلك. يساعد هذا عالم البيانات على تحديد ما إذا كان النموذج يتصرف بطريقة مماثلة لما كان عليه أثناء التدريب، وما إذا كانت توزيعات بيانات الإدخال الخارجية لم تتغير، وما إذا لم تكن هناك أخطاء في أي مكان آخر في النظام.

للحصول على مراقبة كاملة للنموذج، سيتطلب ذلك جهودًا كبيرة من فرق علم البيانات والهندسة وعمليات التطوير (DevOps).
بمجرد ترتيب جميع عمليات المراقبة، سيرغب عالم البيانات بشكل مثالي في أتمتة حلقة إعادة التدريب الكاملة. سيتطلب ذلك إطار عمل لتنسيق خطوط الأنابيب مثل Kubeflow أو Airflow.
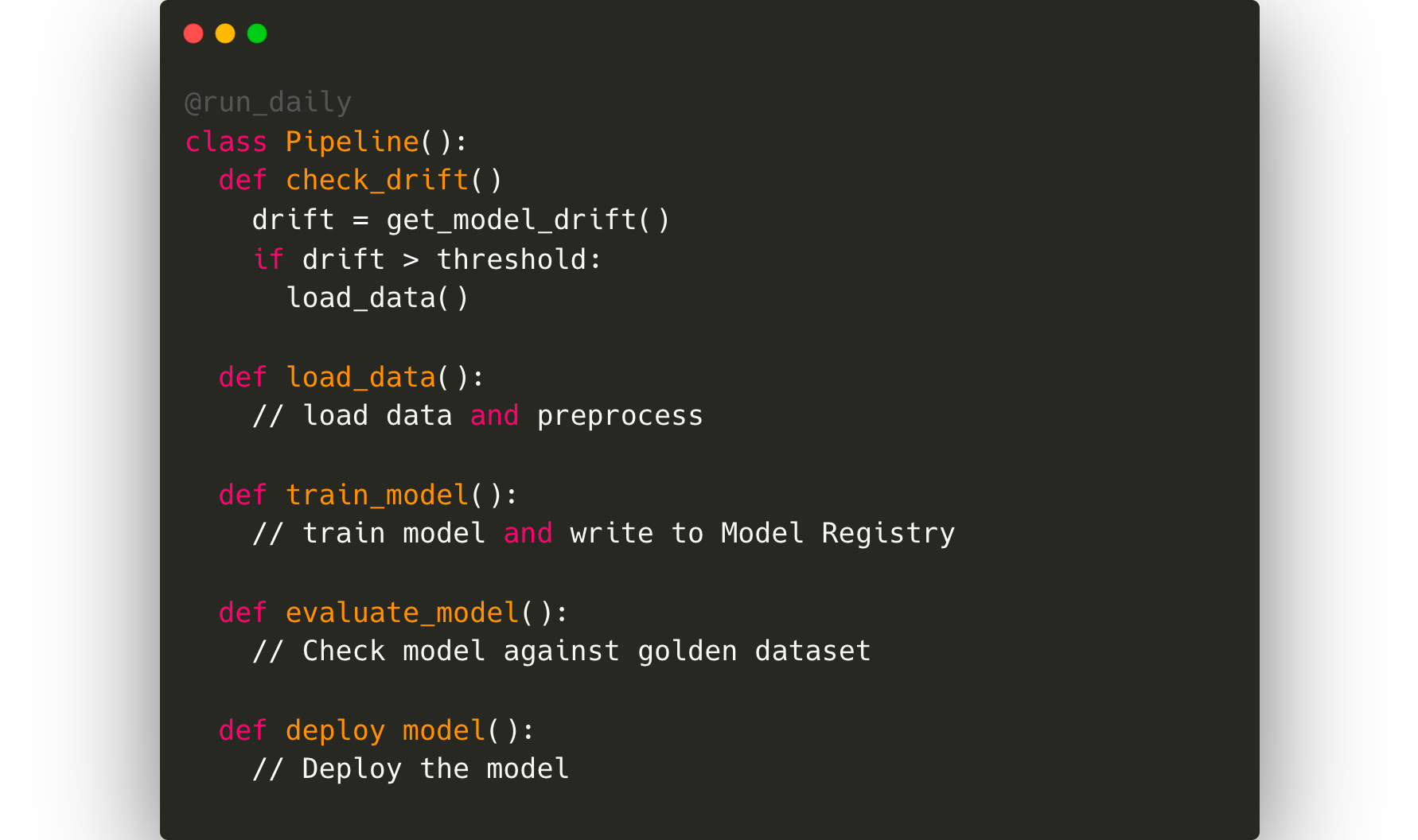
نحتاج بعد ذلك أيضًا إلى تقدير تأثير هذا النموذج على مقاييس رضا المستخدم الفعلية. ستكون بعض المقاييس البديلة في هذه الحالة هي عدد استفسارات العملاء المتعلقة بأوقات التسليم، ودرجة الرضا العامة للعملاء عن طلب ما. ستحتاج مقاييس الأعمال إلى دمجها مع مقاييس النموذج، ومن المحتمل أن يقوم فريق هندسة البيانات بإنشاء خط أنابيب ETL للحصول على هذه البيانات ورسمها على أداة لوحات معلومات داخلية ليراقبها قادة الأعمال.
لتلخيص الأمر تقريبًا، يشمل هذا 5 أصحاب مصلحة:

تستغرق العملية الشاملة بسهولة أكثر من 2-3 أشهر في أي شركة، ويمكن أن تصل أحيانًا إلى 6 أشهر للنماذج القليلة الأولى. ويرجع ذلك إلى تعدد أصحاب المصلحة المعنيين وتعدد مجموعات المهارات المطلوبة، مما يجعل تحقيق تأثير تعلم الآلة يستغرق الكثير من الوقت والاستثمار الأولي الكبير.
لم نتحدث بعد عن بعض جوانب قابلية التوسع والموثوقية المتضمنة في العملية. نأمل أن نغطي بعض الجوانب أدناه في مقال مستقبلي.
الحل هنا هو أتمتة الأجزاء القابلة للأتمتة، وتوفير الاستقلالية لعالم البيانات/مهندس تعلم الآلة لأداء معظم الخطوات دون الحاجة لتعلم جميع الأدوات المعنية. يجري الكثير من العمل في هذا المجال، ونأمل أن يصبح بناء نموذج تعلم آلة مؤثر، في غضون سنوات قليلة، سهلاً مثل بناء صفحة هبوط اليوم!
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








أحدث الأخبار والمقالات والموارد تصلك مباشرة إلى بريدك الوارد
© 2026 جميع الحقوق محفوظة.











.png)
.webp)










.webp)
