احصل على وصول فوري إلى بيئة TrueFoundry مباشرة. انشر النماذج، ووجّه حركة مرور LLM، واستكشف المنصة بالكامل — بيئة الاختبار الخاصة بك جاهزة في ثوانٍ، ولا يلزم وجود بطاقة ائتمان.
٩.٩
Gemini 3 مقابل Kimi-K2 Thinking مقابل Grok-4.1 مقابل GPT-5.1: من يفوز حقًا في "اختبار البشرية الأخير"؟
Published: July 4, 2026
Built for Speed: ~10ms Latency, Even Under Load
Blazingly fast way to build, track and deploy your models!
Handles 350+ RPS on just 1 vCPU — no tuning needed
عندما تقول جوجل "خطط لأي شيء" باستخدام Gemini 3، وتدعي Moonshot أن Kimi-K2 Thinking هو الـ أحدث ما توصلت إليه تقنيات الاستدلال، وتصف xAI نموذج Grok-4 بأنه "النموذج الأكثر ذكاءً في العالم"، وتواصل OpenAI دفع GPT-5.1 قدمًا، فيصعب معرفة ما هو حقيقي وما هو مجرد انطباعات.
بدلاً من كومة أخرى من رسوم بيانية المقارنات المعيارية، إليكم سؤال أكثر تحديدًا:
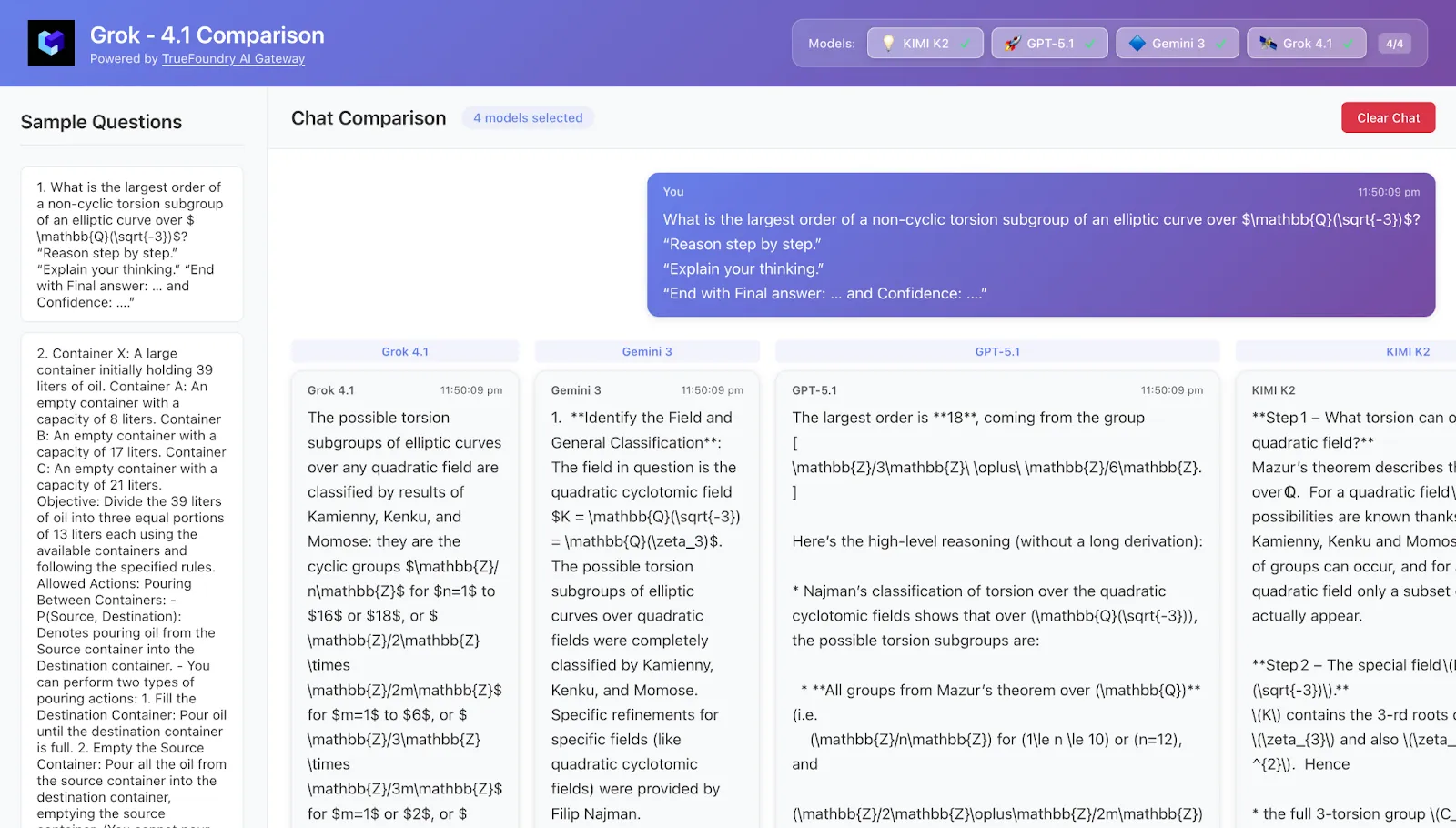
ماذا يحدث إذا أخضعت Gemini 3 و Kimi-K2 Thinking و Grok-4.1 و GPT-5.1 لنفس مجموعة المشكلات على غرار "اختبار البشرية الأخير" — وتشاهد بالفعل كيف تفكر؟
في هذا المنشور:
لماذا اختبار البشرية الأخير (HLE) أصبح "الزعيم الأخير" للمقاييس الأكاديمية.
جولة سريعة في Gemini 3 و Kimi-K2 Thinking و Grok-4.1 و GPT-5.1 كنماذج "تفكير".
خمس دراسات حالة ملموسة بأسلوب HLE تشمل الرياضيات، والفيزياء متعددة الوسائط، والعلوم ذات السياق الطويل، ونظرية الألعاب، والتخطيط.
كيفية إجراء نفس التجارب بنفسك عبر بوابة TrueFoundry للذكاء الاصطناعي.
1. الامتحان الأخير للبشرية في دقيقتين
المقاييس المعيارية مثل MMLU وصلت إلى أقصى حدودها تقريبًا في الطليعة. العديد من النماذج الرائدة تتجاوز 90% فيها، لذا فإن نموذجًا آخر يحقق +1% أو -1% لا يخبرك الكثير عن كيفية العمل معه فعليًا.
الامتحان الأخير للبشرية (HLE) مختلف:
إنه امتحان صممه خبراء يشمل الرياضيات، والعلوم الطبيعية، والهندسة، والاقتصاد، والعلوم الإنسانية، والقانون، وغيرها.
يجمع بين الاختيار من متعدد والمطابقة الدقيقة الأسئلة، والعديد منها تتطلب عدة خطوات استدلال غير بديهية.
جزء كبير من الأسئلة هي متعددة الوسائط، مما يجبر النماذج على الاستدلال بشكل مشترك على النصوص والصور.
الأهم من ذلك، حتى أفضل النماذج اليوم لا تزال بعيدة كل البعد عن مستوى الخبراء البشريين على HLE، وغالبًا ما تكون ثقتهم غير دقيقة.
يطلب المؤلفون صراحةً من الناس عدم إعادة نشر الأسئلة الأصلية، لأنهم يريدون أن يظل HLE معيارًا مفيدًا طويل الأمد. لذا في هذا المنشور:
نحن لا نعرض الصياغة الأصلية لأي سؤال.
بدلاً من ذلك، نصف خمس مهام نموذجية "بنمط HLE" وكيف تتصرف النماذج عليها.
يمكنك تكرار هذه الأنماط بنفسك باستخدام مجموعة بيانات HLE العامة أو مشكلات مماثلة من مجالك الخاص.
2. أربعة نماذج "تفكير" في عام 2025
نحن لا نقارن "روبوتات الدردشة" هنا، بل ننظر إلى نماذج تُقدم صراحةً على أنها نماذج استدلال: تسلسل التفكير العميق، أدوات، سياق طويل، تخطيط.
Gemini 3 (احترافي + تفكير عميق)
تقدم جوجل Gemini 3 كنموذجها الأكثر قدرة حتى الآن:
أقوى استدلال و فهم متعدد الوسائط من جيل Gemini 2.5.
نتائج تنافسية في HLE بدون أدوات، بالإضافة إلى أداء ممتاز في GPQA وMMMU-Pro وVideo-MMMU ومعايير الاستدلال الأخرى.
تركيز كبير على الوكلاء الذين يستدعون الأدوات وذوي الأفق الطويل: قصة "خطط لأي شيء"، بما في ذلك أفضل النتائج في معايير التخطيط مثل Vending-Bench.
يكشف Gemini 3 أيضًا عن التفكير العميق وضع يستهلك المزيد من قوة المعالجة والرموز على المشكلات الصعبة لاستخلاص قدر أكبر من الدقة.
Kimi-K2 Thinking
نموذج Moonshot Kimi-K2 Thinking هو نموذج "تفكير" مفتوح الوزن:
بنية مزيج الخبراء ذات ميزانية إجمالية ضخمة للمعاملات ولكن مجموعة فرعية نشطة أصغر لكل رمز.
سياق طويل (مئات الآلاف من الرموز) و سلسلة تفكير مكثفة للغاية حسب التصميم.
غالبًا ما تُظهر التحليلات العامة أن Kimi-K2 Thinking ونسخته "الثقيلة" (Heavy) تتصدر أو تقترب من الصدارة في HLE ومعايير الاستدلال الأخرى.
إذا رأيت نموذجًا يخرج صفحات من المونولوج الداخلي لمسألة رياضية واحدة: هذه هي جمالية أسلوب كيمي.
Grok-4 / Grok-4.1
الخاصة بـ xAI Grok-4 يُقدم هذا الخط على أنه:
نموذج ذو قدرات عالية استدلال نموذج مع استخدام أدوات مدمج وبحث عبر الإنترنت.
قوي في HLE و GPQA والمهام طويلة الأمد حيث يجب على الوكلاء الحفاظ على سلوك متماسك على مدى عدة خطوات.
يضيف Grok-4.1 تركيزًا أكبر على الذكاء "العاطفي" والإبداعي، لكنه لا يزال يحافظ على قوة الاستدلال الأساسية.
اعتبر Grok-4.x النموذج الذي يرغب حقًا في أن يكون وكيل: يخطط، يبحث، يتصرف، يتأمل، يكرر.
GPT-5.1 (GPT-5 family)
الخاصة بـ OpenAI GPT-5 عائلة هي المعيار الأساسي الذي يلجأ إليه معظم الناس:
قوي جدًا في مجموعات المعايير الواسعة: البرمجة، الاستدلال، الوسائط المتعددة، والسياق الطويل.
عند تشغيله في وضع "جهد استدلال" عالٍ / "تفكير"، فإنه يخصص المزيد من الرموز ويعالج المشكلات الصعبة ويميل إلى سد الفجوة في المعايير المتقدمة مثل HLE و GPQA.
سنشير إلى تفكير GPT-5.1 كمتغير من GPT-5 يعمل بوضع الجهد العالي هذا.
3. كيف قارناهم (دون تسريب HLE)
لم يكن الهدف هنا بناء لوحة صدارة أخرى، بل لمعرفة كيف تتصرف هذه النماذج في المهام المشابهة لـ HLE.
على نحو عام:
اخترنا مجموعة من أسئلة HLE النموذجية (الرياضيات، الفيزياء متعددة الوسائط، المقاطع العلمية الطويلة، نظرية الألعاب، التخطيط).
لكل سؤال، استخدمنا موجهًا ثابتًا لـ "وضع الاختبار":
"استدل خطوة بخطوة."
"اشرح طريقة تفكيرك."
"اختتم بـ الإجابة النهائية: ... والثقة: ...."
طبقنا نفس السؤال والإطار بالضبط على:
كيمي-K2 تفكير
جروك-4.1
جي بي تي-5.1 تفكير
جيميني 3 برو (وحيثما أمكن، جيميني 3 تفكير عميق)
تم ربط كل هذا من خلال بوابة TrueFoundry AI:
نقطة نهاية واحدة نربط بها OpenAI و Google و xAI و Moonshot وأكثر من 1000 نموذج آخر.
مكان واحد لتسجيل الاستجابات والرموز وزمن الاستجابة والتكلفة لكل استدعاء.
مجموعة واحدة من المصادقة والحصص والضوابط الوقائية لجميع الموردين.
المزيد عن ذلك لاحقًا — أما الآن، لننظر إلى دراسات الحالة الخمس.
4. دراسة الحالة 1 – الرياضيات العميقة: الدقة مقابل التفكير المستهلك للرموز
المهمة مسألة رياضيات على مستوى الدراسات العليا (مثل نظرية الأعداد / التوافقيات):
إجابة قصيرة واحدة (عدد صحيح أو تعبير بسيط).
تتطلب حوالي 4-6 خطوات استدلالية غير بديهية.
من الصعب للغاية التخمين بشكل صحيح دون معالجته فعليًا.
ما ننظر إليه
هل النموذج يُعد الهيكل بشكل صحيح (على سبيل المثال، النظرية / التصنيف الصحيح)؟
هل يكمل الاستدلال حتى النهاية دون أن يفقد إشارة سالبة؟
كم عدد التوكنات يستهلك للوصول إلى ذلك؟
ما مدى معايرة ثقته؟
الأنماط النموذجية الملاحظة
تفكير كيمي-ك2
سلسلة تفكير طويلة للغاية: تستدعي النظريات ذات الصلة، وتستكشف مقاربات مرشحة متعددة، وغالبًا ما تتفرع وتتراجع.
قوي جدًا في الدقة، خاصة في وضع "الثقيل" (Heavy)، ولكنه غالبًا ما يستهلك عددًا أكبر بكثير من التوكنات مقارنة بالآخرين.
الثقة المبلغ عنها ذاتيًا غالبًا ما تكون 90-100%، حتى في المشكلات الحساسة جدًا.
جروك-4.1
جريء واستكشافي: يرسم بسرعة إجابة بديهية، ثم يحاول تبريرها.
عندما يكون صحيحًا، يبدو رائعًا؛ وعندما يخطئ، يمكن أن يكون جدًا واثقًا.
GPT-5.1 التفكير
بنية جيدة: يعدد الحالات بوضوح، ويصنفها، ويشير إليها بشكل نظيف.
غالبًا ما يكون أكثر تواضعًا بقليل في تقديراته للثقة، خاصة عندما تتطلب المشكلة حقائق عميقة متعددة.
Gemini 3 (Pro / Deep Think)
استدلال متعدد الخطوات، ولكن بشكل ملحوظ أكثر إيجازًا من كميات النصوص الهائلة لـ Kimi-K2.
وضع التفكير العميق يسد الكثير من الفجوة في HLE مع Kimi/Grok، مع البقاء أكثر اتزانًا إلى حد ما في تفسيراته.
الخلاصة إذا كنت تسعى وراء كل نقطة إضافية في الرياضيات على غرار HLE، يبدو أن Kimi-K2 Thinking و Grok-4.x هما الرائدان، مع Gemini 3 Deep Think يليهما عن كثب. إذا كنت تهتم بـ التكلفة والسرعة بقدر اهتمامك بالدقة المطلقة، فإن Gemini 3 و GPT-5.1 Thinking خياران جذابين لأنهما يحققان نتائج مماثلة بينما يستهلكان عددًا أقل من الرموز.
5. دراسة حالة 2 – الفيزياء متعددة الوسائط: "النظر فعليًا إلى الرسم البياني"
المهمة سؤال في الفيزياء/الهندسة يعتمد بشكل كبير على الرسوم البيانية:
يتم تضمين رسم بياني لدائرة كهربائية، أو رسم بياني للجسم الحر، أو إعداد بصري كصورة.
لا يمكنك الإجابة بشكل صحيح دون تحليل الشكل بشكل صحيح.
ما نركز عليه
هل النموذج يصف الرسم البياني بطريقة تتطابق مع الصورة؟
هل يقوم بـ افتراضات غير موجودة في الصورة؟
ما مدى جودة دمجه للصورة والنص في استنتاج متماسك؟
الأنماط الشائعة الملاحظة
جيميني 3
دقيق جدًا بشأن الصورة نفسها: "السهم يشير إلى اليسار"، "توجد ثلاثة مقاومات متصلة على التوالي"، "الكتلة متصلة بنابضين".
هلوسات أقل بخصوص محتوى الرسم البياني.
بشكل عام يبدو الأكثر واقعية في استدلاله متعدد الوسائط.
تفكير GPT-5.1
فهم قوي متعدد الوسائط، ولكنه غالبًا ما يكون أقل وضوحًا: يستخدم الرسم البياني بشكل صحيح، ومع ذلك لا يصفه دائمًا بالتفصيل.
عندما يفشل، يكون ذلك عادةً بسبب سوء قراءة للنص وليس للصورة.
تفكير Kimi-K2
بمجرد أن تكون المعطيات صحيحة، تكون الفيزياء متينة.
ولكن تحت الضغط، يمكن أن يخطئ في عد العناصر في الرسم البياني (على سبيل المثال، عدد المكونات) ثم ينشر هذا الخطأ عبر اشتقاق طويل جدًا.
غروك-4.1
مشابه لـ GPT-5.1 في الأسلوب: بديهي، وغالبًا ما يكون صحيحًا، ولكنه يبالغ في الثقة أحيانًا بشأن سطر أو تسمية تم تفسيرها بشكل خاطئ.
الخلاصة إذا كان جزء كبير من عبء عملك بأسلوب HLE يتضمن رسومًا بيانية أو مخططات أو ألغازًا بصرية، فإن مكدس Gemini 3 متعدد الوسائط متميز. GPT-5.1 و Kimi-K2 و Grok-4.1 كلها قادرة، ولكنها أكثر عرضة "لرؤية" تفاصيل غير موجودة بالفعل.
6. دراسة حالة 3 – علم السياق الطويل: قراءة، وليس مجرد حل
المهمة مقطع علمي طويل وكثيف (أحياء / طب / كيمياء):
عدة فقرات تصف تجربة وأساليب ونتائج ومحاذير.
ثم سؤال يتطلب دمج المعلومات عبر المقطع بأكمله، وليس فقط الفقرة الأخيرة.
ما نركز عليه
هل النموذج يلخص المقطع بدقة؟
هل يتتبع المتغيرات والشروط والاستثناءات عبر الفقرات؟
هل يحدد بشكل صحيح أي التفاصيل تعد مهمة بالفعل للإجابة على السؤال؟
الأنماط الشائعة التي لوحظت
جيميني 3
جيد في ضغط المقاطع الطويلة إلى نقاط مركزة بدقة.
يميل إلى إعادة ذكر الحقائق الرئيسية، ثم يستنتج "من الملاحظات" للوصول إلى الإجابة.
نادراً ما يناقض نفسه عند الإشارة إلى أجزاء سابقة من النص.
تفكير GPT-5.1
ممتاز في تتبع المتغيرات والإعدادات التجريبية؛ يبدو وكأنه مساعد تدريس دقيق.
غالباً ما يكون مسار "قراءة ← تلخيص ← استنتاج" الأكثر وضوحاً.
تفكير Kimi-K2
شديد التفصيل: يكرر الكثير من النص وأحياناً يعيد استنتاج النظرية الأساسية.
هذا العمق مفيد، لكن طوله المفرط يعني أن الانحراف العرضي أو التناقض الداخلي يمكن أن يتسلل.
Grok-4.1
جيد جداً في استخلاص التداعيات العملية ("هذا يشير إلى أن العلاج أ هو الأفضل عندما...").
أحياناً يغفل الحالات الهامشية النادرة المذكورة في النص.
الخلاصة لنمط HLE-style اقرأ هذا واستوعبه فعلاً الأسئلة، Gemini 3 و GPT-5.1 Thinking قوية بشكل خاص: فهي تلخص بوضوح، وتحافظ على التفاصيل المهمة، وتحافظ على اتساق المنطق. Kimi-K2 و Grok-4.1 قادرتان أيضًا، لكن سردهما الأطول يمكن أن يؤدي إلى المزيد من الانحرافات.
7. دراسة حالة 4 – نظرية الألعاب والاقتصاد الجزئي: من يفكر مثل مساعد تدريس؟
المهمة سؤال في الاقتصاد الجزئي / نظرية الألعاب:
عدة لاعبين، مجموعة صغيرة من الإجراءات، وأوصاف العوائد.
يُطلب منك إيجاد نقاط التوازن، أو توصيف الاستراتيجيات، أو مقارنة نتائج الرفاهية.
ما نركز عليه
هل النموذج يعدد جميع الحالات ذات الصلة؟
هل يحافظ على اتساق المنطق من تحليل الحالة إلى الإجابة النهائية؟
هل يدرك الجوانب الدقيقة مثل الاستراتيجيات المختلطة، أو السيادة، أو التماثل؟
الأنماط النموذجية الملاحظة
Kimi-K2 Thinking
يبدو وكأنه مساعد تدريس طالب دراسات عليا: الكثير من التحليل حالة بحالة، والبناء الصريح للأمثلة المضادة، والنظر الدقيق في الحالات الهامشية.
قوي جدًا عندما تريد رؤية شجرة الاستدلال بأكملها.
Grok-4.1
ممتاز بشكل حدسي في الاستدلال التحفيزي ("إذا انحرف اللاعب أ، فإنه يكسب X، لذا لا يمكن أن يكون هذا توازنًا").
ينغلق أحيانًا على توازن حدسي مبكر ويحتاج إلى دفعة لإعادة النظر.
تفكير GPT-5.1
منهجي: يصنف الحالات (الحالة 1، الحالة 2، ...)، ويلخص النتائج، ويربطها ببعضها بسلاسة.
توازن جيد بين العمق والإيجاز.
جيميني 3
مشابه لـ GPT-5.1 في الهيكل، مع ميل أكبر للتراجع الصريح ("دعنا نعيد النظر في الافتراض بأن..."), خاصة في وضع "التفكير العميق".
الخلاصة في أسئلة HLE المتعلقة بنظرية الألعاب، تفكير Kimi-K2 و غروك-4.1 يبدوان الأقرب إلى مساعد تدريس بشري: الكثير من دراسة الحالات الصريحة والنقاش الحدسي. جيميني 3 و GPT-5.1 الوصول إلى الإجابة بتشتت أقل، وهو ما قد يكون مفضلاً عند تمرير المخرجات مباشرة إلى التعليمات البرمجية أو مسارات اتخاذ القرار.
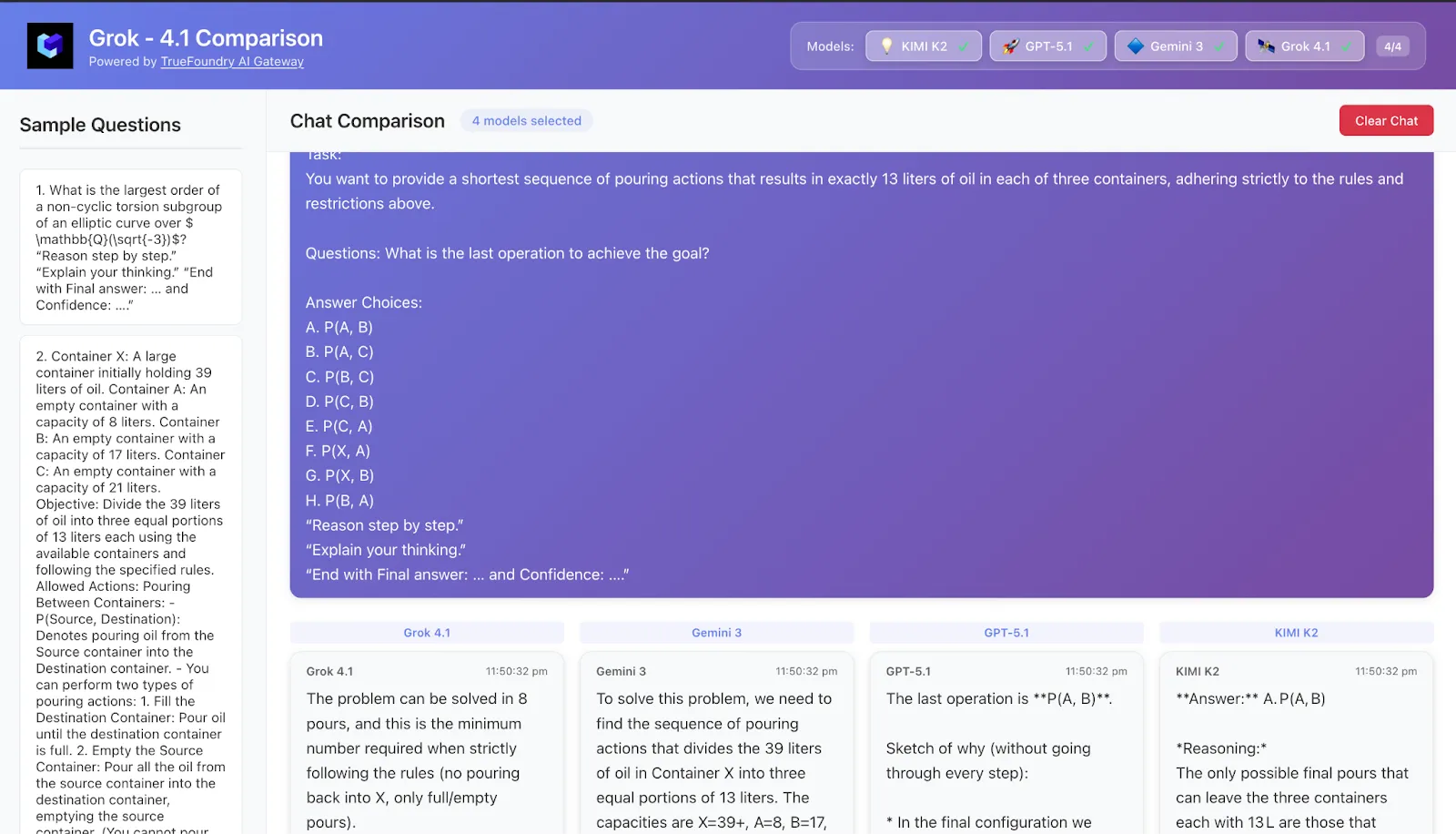
8. دراسة حالة 5 – مشاكل التخطيط: وكلاء مصغرون داخل موجه
المهمة لغز على غرار التخطيط / بحوث العمليات:
عدة حاويات، سعات، وقواعد صب، أو إعداد جدولة / إدارة مخزون.
يجب عليك اختيار سياسة أو تسلسل من الإجراءات يصل إلى هدف في أقل عدد من الخطوات تحت قيود.
ما نركز عليه
هل النموذج يحدد مساحة الحالة بوضوح؟
هل يحاكي التسلسلات بشكل صحيح دون نسيان الإجراءات السابقة؟
هل يلتزم بالقيود التي ذكرها هو نفسه؟
الأنماط الشائعة الملاحظة
Grok-4.1
شبيه جداً بالوكيل: يكتب الحالات بوضوح ("بعد الخطوة 3: المخزون هو X، Y، Z")، ويتحقق من كل منها مقابل الهدف، ويصحح المسار عند الحاجة.
يبدو الأقرب إلى استخدام وكيل تخطيط حقيقي داخل موجه واحد.
Gemini 3
أسلوب تخطيط مشابه: يعيد صياغة الهدف والقيود، يقترح سياسة، ثم يحاكي عدة خطوات.
جيد بشكل خاص في عدم فقدان التتبع للحالة على مدى تسلسلات أطول، وهو ما يتوافق تمامًا مع رؤيته طويلة المدى / Vending-Bench.
تفكير GPT-5.1
تخطيط مفاهيمي جيد، ولكنه أكثر عرضة لأخطاء حسابية صغيرة أو أخطاء في تتبع السجلات عبر العديد من الخطوات.
عندما يُطلب منه ضمان "أقصر تسلسل"، فإنه يحتاج أحيانًا إلى محاولة ثانية.
تفكير Kimi-K2
يقدم الكثير من المحاكاة التفصيلية، لكن الجمع بين CoT الطويل + الحالة المعقدة يؤدي أحيانًا إلى تناقضات صغيرة (على سبيل المثال، كمية تتغير بصمت بين الخطوات).
الخلاصة في مهام HLE ذات الطابع التخطيطي، Grok-4.1 و Gemini 3 تبدوان وكأنهما العوامل المصغرة الأكثر موثوقية. Kimi-K2 و GPT-5.1 قادرتان جدًا، لكن مسارات استدلالهما الطويلة يمكن أن تعمل ضدهما أحيانًا عندما يكون تتبع الحالة أمرًا بالغ الأهمية.
9. إذن... من "يفوز" في امتحان البشرية الأخير؟
إذا نظرت فقط إلى نسب HLE الرئيسية، Kimi-K2 Thinking (خاصةً الإصدارات الثقيلة) وبعض تكوينات Grok-4 تتصدر حاليًا أو تقترب من الصدارة، مع Gemini 3 Deep Think تتبعها عن كثب و GPT-5 Pro أقل بقليل.
لكن HLE معقدة بطريقة إيجابية:
الدقة لا تزال أقل بكثير من الخبراء البشريين.
الثقة غالبًا ما تكون غير معايرة بشكل صحيح: يمكن أن تكون النماذج جدًا واثقة و جدًا مخطئة.
المجالات المختلفة (الرياضيات مقابل العلوم مقابل التخطيط مقابل العلوم الإنسانية) تظهر فائزين مختلفين.
من دراسات الحالة الخمس:
Kimi-K2 Thinking
الأفضل عندما تريد أقصى عمق ومرتاحون لدفع التكلفة من حيث الرموز والكمون لاستخلاص كل ذرة أداء.
Grok-4.1
يتألق في التخطيط والاستدلال الشبيه بالوكيل؛ إذا كانت مهامك تشبه المحاكاة أو قرارات العمل متعددة الخطوات، فإن Grok يبدو طبيعيًا جدًا.
GPT-5.1 Thinking
خيار افتراضي قوي وآمن: قراءة ممتازة للسياقات الطويلة، وهيكل نظيف بشكل عام، وسهل جدًا للدمج في الأنظمة الحالية.
Gemini 3 (Pro + Deep Think)
مقنع بشكل خاص في الاستدلال متعدد الوسائط، فهم القراءة المنظم، و التخطيط — وشعار "خطط لأي شيء" ليس مجرد تسويق؛ بل يظهر في كيفية تعامله مع المشكلات الطويلة وذات الحالة.
لا يوجد فائز وحيد في "اختبار البشرية الأخير". النموذج "الأفضل" هو الذي الأقل سوءًا على مهامك الفعلية، ضمن قيودك الفعلية.
10. كيف قمنا بتشغيل هذا عبر بوابة TrueFoundry للذكاء الاصطناعي
في الواقع، لم نقم ببناء أربعة عمليات تكامل منفصلة. كل شيء مر عبر الـ TrueFoundry AI Gateway (truefoundry.com/ai-gateway):
نقطة نهاية واحدة لـ OpenAI (GPT-5.1)، جوجل (Gemini 3)، xAI (Grok-4.x)، مونشوت (Kimi-K2)، ومئات النماذج الأخرى.
قابلية مراقبة مركزية : سجلات للمطالبات، الاستجابات، الرموز، زمن الاستجابة، والأخطاء عبر البائعين.: سجلات للمطالبات، الاستجابات، الرموز، زمن الاستجابة، والأخطاء عبر البائعين.
حوكمة وأمان مدمجان حوكمة وأمان مدمجان: التحكم في الوصول المستند إلى الدور (RBAC)، سجلات التدقيق، وخيارات النشر التي تحافظ على البيانات في سحابتك أو في موقعك.
على صعيد التجارب، كان ذلك يعني:
قمنا بتوصيل نظام التقييم الخاص بنا بالبوابة مرة واحدة.
قمنا بتسجيل gpt-5.1-thinking، kimi-k2-thinking، grok-4.1، gemini-3-pro و gemini-3-deep-think على أنها مجرد معرفات نماذج مختلفة.
كان التبديل بينها مجرد تغيير في سطر واحد في الإعدادات، وليس دمجًا جديدًا لحزمة تطوير البرامج (SDK).
11. جرب Gemini 3 (والبقية) على "اختبارك الأخير" الخاص بك
إذا كنت ترغب في إعادة إنتاج (أو تحدي) الأنماط الواردة في هذا المنشور:
اختر اختبارك.
استخدم HLE أو "اختبارًا أخيرًا" داخليًا مبنيًا على مجال عملك الخاص: أسئلة بحثية، تذاكر دعم، مراجعات أكواد، تحليلات ما بعد الحوادث.
قم بتشغيله عبر نماذج متعددة.
وجه نظام التقييم الخاص بك نحو بوابة TrueFoundry للذكاء الاصطناعي وقم بتشغيل نفس المطالبات عبر Gemini 3 و Kimi-K2 Thinking و Grok-4.1 و GPT-5.1 Thinking.
قارن في مكان واحد.
انظر إلى الدقة وجودة الاستدلال واستخدام الرموز والكمون والتكلفة جنبًا إلى جنب.
حدد أي نموذج "تفكير" يستحق درجته بالفعل في مهامك .
لأنه في عام 2025، المعيار الوحيد الذي يهم حقًا ليس HLE أو MMLU أو GPQA — بل هو الاختبار الذي يشبه عملك الخاص. وليس عليك اختيار نموذج واحد بناءً على الثقة عندما يمكنك توصيل أربعة منها خلف بوابة واحدة وتدع النتائج تتحدث عن نفسها.
الأسئلة الشائعة
ما الفرق بين كيمي K2 وجميني 3؟
يركز Gemini 3 من Google على الفهم متعدد الوسائط وقدرات استدعاء الأدوات القوية مع وضع التفكير العميق (Deep Think). أما Kimi-K2 Thinking، وهو نموذج مفتوح الوزن، فيشتهر بسياقه الطويل الشامل ومنطقه التفصيلي المتسلسل (chain-of-thought reasoning). يكشف فهم مقارنة Kimi K2 بـ Gemini 3 عن مقاربات متميزة لحل المشكلات المتقدمة في الذكاء الاصطناعي.
ما هو أفضل استخدام لـ Kimi K2 Thinking؟
يُعد Kimi-K2 Thinking الأفضل لمهام الاستدلال المعقدة وحل المشكلات العميقة. بفضل سياقه الطويل وتصميمه الذي يعتمد على تسلسل التفكير المكثف، يتفوق **Kimi K2** في التحديات التي تتطلب حوارًا داخليًا واسعًا، مثل مسائل الرياضيات المتقدمة والمعايير القياسية مثل "اختبار البشرية الأخير" (Humanity's Last Exam)، وغالبًا ما يصنف ضمن أفضل النماذج.
Gemini 3 مقابل GPT-5: أيهما أفضل؟
تتعمق مدونتنا في مقارنة Gemini 3 بـ GPT-5.1 من خلال تقييم أدائهما في "اختبار البشرية الأخير" (Humanity's Last Exam). وجدنا أن "الأفضل" يعتمد على مهمة الاستدلال المحددة وسلوك النموذج. يسلط تحليل TrueFoundry، الذي أُجري عبر بوابة الذكاء الاصطناعي الخاصة بنا، الضوء على مقارباتهما الفريدة لحل المشكلات، مما يساعدك على تحديد الأنسب لحلول الذكاء الاصطناعي الخاصة بك.
Gemini 3 مقابل Grok-4: أي نموذج يقدم أداءً أفضل؟
عند مقارنة Gemini 3 بـ Grok-4، يتفوق كلاهما كوكلاء استدلال أقوياء، ويظهران أداءً قويًا في المهام المعقدة مثل "اختبار البشرية الأخير" (Humanity's Last Exam). يتميز Gemini 3 بفهم متقدم متعدد الوسائط ووضع التفكير العميق (Deep Think)، بينما يركز Grok-4 على استخدام الأدوات الأصلي والقدرات الوكيلية. غالبًا ما يعتمد الأداء الأمثل على متطلبات المهمة المحددة.
ما هو أفضل نموذج ذكاء اصطناعي لمهام الاستدلال؟
لمهام الاستدلال المعقدة، تُظهر نماذج مثل Gemini 3 و Kimi-K2 Thinking و GPT-5.1 قدرات قوية. تقيّم مدونتنا أداء كل منها عبر تحديات مختلفة، مما يساعدك على فهم نقاط قوتها المحددة. يعتمد الخيار الأمثل عند مقارنة Gemini 3 بـ Kimi-K2 Thinking بـ GPT-5 في النهاية على متطلبات مشروعك الفريدة ونوع الاستدلال المطلوب.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.
































.png)
.webp)










.webp)
