






July 20, 2023
|
5 min read


احصل على وصول فوري إلى بيئة TrueFoundry مباشرة. انشر النماذج، ووجّه حركة مرور LLM، واستكشف المنصة بالكامل — بيئة الاختبار الخاصة بك جاهزة في ثوانٍ، ولا يلزم وجود بطاقة ائتمان.









Published: July 4, 2026

Blazingly fast way to build, track and deploy your models!
تزداد قوة النماذج اللغوية الكبيرة (LLMs) بشكل متزايد، ويتم استخدامها في مجموعة متنوعة من المهام، بما في ذلك روبوتات الدردشة، وتوليد النصوص، والإجابة على الأسئلة. ومع ذلك، يمكن أن تكون النماذج اللغوية الكبيرة مكلفة وتتطلب موارد كثيفة للتدريب. في منشور المدونة هذا، سنوضح لك كيفية الضبط الدقيق لنموذج لغوي كبير أصغر (7B) ليؤدي أداءً أفضل من ChatGPT.
الضبط الدقيق هو عملية تدريب نموذج لغوي كبير على مجموعة بيانات محددة لتحسين أدائه في مهمة معينة. في هذه الحالة، سنقوم بضبط دقيق لنموذج لغوي كبير بحجم 7B لضرب عددين.
لنبدأ بأداء النماذج اللغوية الكبيرة المختلفة في مهمة ضرب بسيطة: 458*987 = 452046.
في البداية، سنلقي نظرة على نموذج ميتا الذي تم إصداره مؤخرًا Llama-2-7B. لقد قمنا بنشر Llama-2 على TrueFoundry وجربناه مع تكاملات Langchain الخاصة بـ TrueFoundry. وإليكم النتيجة لذلك.
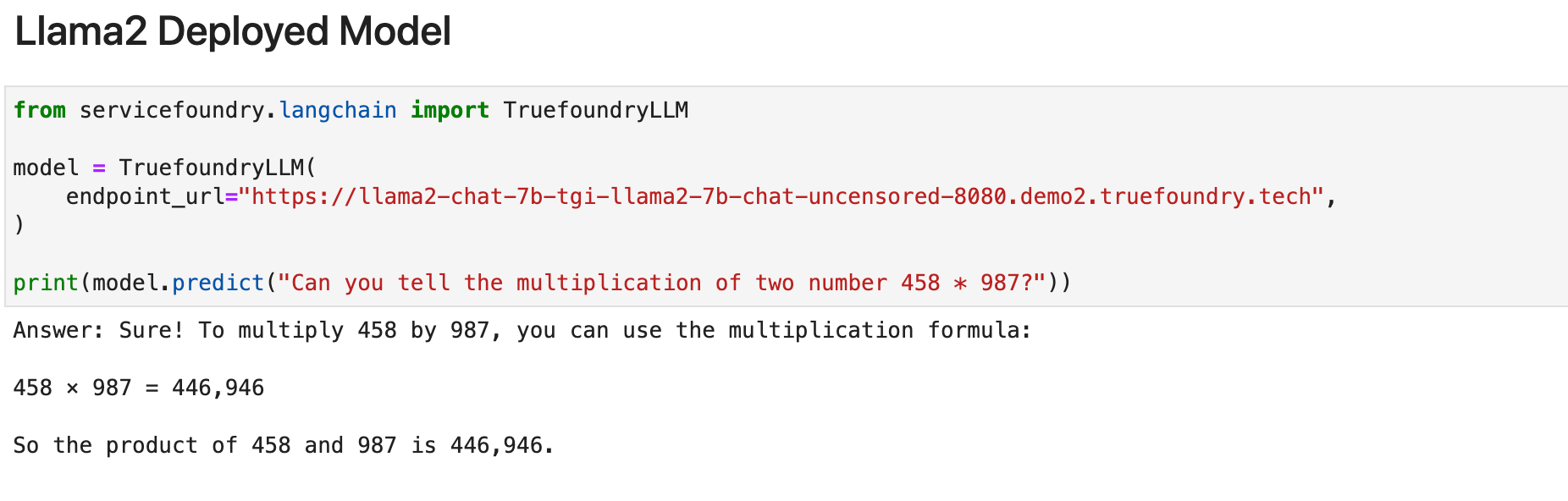
كما نرى بوضوح، فإن هذا النموذج لا يؤدي أداءً جيدًا في المهمة. (وهو أمر متوقع أيضًا نظرًا لحجم النموذج). دعونا نرى كيف تؤدي النماذج المتطورة في نفس المهمة:
دعونا نلقي نظرة على النتيجة من ChatGPT (GPT3.5 Turbo):
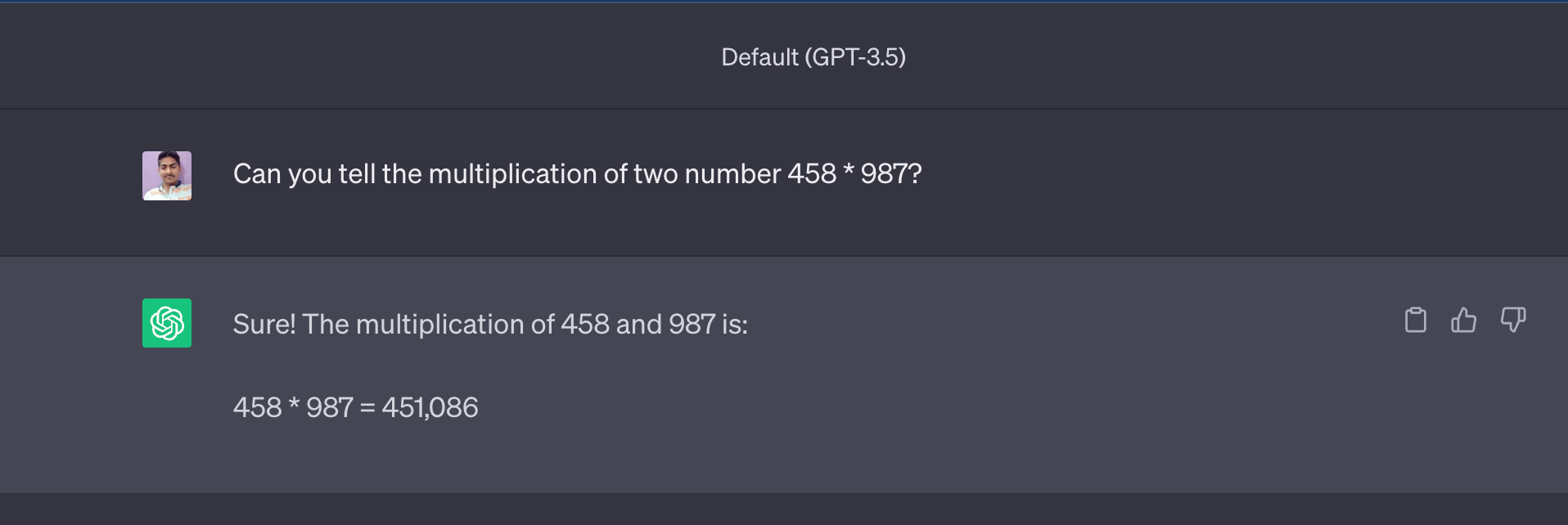
الآن الإجابة (451,086) قريبة جدًا من الإجابة الفعلية وهي 452,046، لكن الإجابة غير صحيحة.
دعونا نجرب بموجه مختلف (لإجراء حساب خطوة بخطوة ونرى ما يفعله):
0:00/1×
ChatGPT بموجه مخصص للضرب
ولكن مرة أخرى، يصل إلى نتيجة غير صحيحة: 450,606 🤨
أخيرًا، دعونا نجرب النموذج المتطور (GPT-4) ونتحقق من أدائه في المهمة:

إنها قريبة جدًا من الإجابة الصحيحة (452,046) وقد تبدو صحيحة لأي شخص. لكن من الواضح أن الإجابة غير صحيحة.
الإجابة على هذا السؤال بسيطة جدًا. لم يتم تدريبها على ذلك.
تُدرب نماذج اللغة الكبيرة (LLMs) على مجموعات بيانات ضخمة من النصوص والتعليمات البرمجية، ولكن هذه البيانات ليست دائمًا مهيكلة بطريقة مفيدة للاستدلال الرياضي. على سبيل المثال، قد لا تتضمن البيانات تمثيلات صريحة للمفاهيم الرياضية، مثل الجمع والطرح والضرب والقسمة. وهذا قد يجعل من الصعب على نماذج اللغة الكبيرة تعلم كيفية إجراء هذه العمليات بشكل صحيح.
لذلك تساءلنا عما إذا كان من الممكن تدريب نموذج لغة كبير على إجراء العمليات الرياضية؟ أجرينا تجربة وكانت النتائج واعدة للغاية!
للبدء، أعددنا مجموعة بيانات تتكون من 40,000 صف من المطالبات والتعليمات. حاولنا محاكاة الخطوات الدقيقة المتبعة في طريقة الضرب الطويل، والتي تتضمن تقسيم المضروب والمضروب فيه إلى أرقامهما الفردية، ثم ضرب كل رقم من المضروب في كل رقم من المضروب فيه ووضع النتائج في المواضع المناسبة بناءً على قيمها المكانية. أخيرًا، تُجمع جميع النواتج الفردية للحصول على النتيجة النهائية.
إليك مثال على مطالبة:
أنت مساعد مفيد تقدم إجابات مفصلة لأسئلة الضرب. تأكد من تقديم شرح شامل باستخدام طريقة الضرب الطويل للمسألة الرياضية المعطاة أدناه.
إذا لم تكن تعرف إجابة سؤال ما، فالرجاء عدم مشاركة معلومات خاطئة. ما هو ناتج 5244 * 1932؟
وإليك مثال على استجابة:
فيما يلي خطوات ضرب 5244 * 1932 باستخدام طريقة الضرب الطويل.
الخطوة 1: قسّم 5244 إلى أرقامه الفردية: 5 (منزلة الآلاف)، 2 (منزلة المئات)، 4 (منزلة العشرات)، و 4 (منزلة الآحاد).
الخطوة 2: وبالمثل، قسّم 1932 إلى أرقامه الفردية: 1 (منزلة الآلاف)، 9 (منزلة المئات)، 3 (منزلة العشرات)، و 2 (منزلة الآحاد).
- 4 (من منزلة الآحاد للرقم الأول) * 2 (من منزلة الآحاد للرقم الثاني) = 8 -> أزحها 0 خانات إلى اليسار (لأننا نضرب في منزلة الآحاد للرقم الثاني) لتحصل على 8
- 4 (من منزلة الآحاد للرقم الأول) * 3 (من منزلة العشرات للرقم الثاني) = 12 -> أزحها خانة واحدة إلى اليسار (لأننا نضرب في منزلة العشرات للرقم الثاني) لتحصل على 120
- 4 (من منزلة الآحاد للرقم الأول) * 9 (من منزلة المئات للرقم الثاني) = 36 -> أزحها خانتين إلى اليسار (لأننا نضرب في منزلة المئات للرقم الثاني) لتحصل على 3600
- 4 (من منزلة الآحاد للرقم الأول) * 1 (من منزلة الآلاف للرقم الثاني) = 4 -> أزحها 3 خانات إلى اليسار (لأننا نضرب في منزلة الآلاف للرقم الثاني) لتحصل على 4000
- 4 (من منزلة العشرات للرقم الأول) * 2 (من منزلة الآحاد للرقم الثاني) = 8 -> أزحها خانة واحدة إلى اليسار (لأننا نضرب في منزلة الآحاد للرقم الثاني) لتحصل على 80
- 4 (من منزلة العشرات للرقم الأول) * 3 (من منزلة العشرات للرقم الثاني) = 12 -> أزحها خانتين إلى اليسار (لأننا نضرب في منزلة العشرات للرقم الثاني) لتحصل على 1200
- 4 (من منزلة العشرات للرقم الأول) * 9 (من منزلة المئات للرقم الثاني) = 36 -> أزحها 3 خانات إلى اليسار (لأننا نضرب في منزلة المئات للرقم الثاني) لتحصل على 36000
- 4 (من منزلة العشرات للعدد الأول) * 1 (من منزلة الآلاف للعدد الثاني) = 4 -> أزحه 4 خانات إلى اليسار (لأننا نضرب في منزلة الآلاف من العدد الثاني) لتحصل على 40000
- 2 (من منزلة المئات للعدد الأول) * 2 (من منزلة الآحاد للعدد الثاني) = 4 -> أزحه خانتين إلى اليسار (لأننا نضرب في منزلة الآحاد من العدد الثاني) لتحصل على 400
- 2 (من منزلة المئات للعدد الأول) * 3 (من منزلة العشرات للعدد الثاني) = 6 -> أزحه 3 خانات إلى اليسار (لأننا نضرب في منزلة العشرات من العدد الثاني) لتحصل على 6000
- 2 (من منزلة المئات للعدد الأول) * 9 (من منزلة المئات للعدد الثاني) = 18 -> أزحه 4 خانات إلى اليسار (لأننا نضرب في منزلة المئات من العدد الثاني) لتحصل على 180000
- 2 (من منزلة المئات للعدد الأول) * 1 (من منزلة الآلاف للعدد الثاني) = 2 -> أزحه 5 خانات إلى اليسار (لأننا نضرب في منزلة الآلاف من العدد الثاني) لتحصل على 200000
- 5 (من منزلة الآلاف للعدد الأول) * 2 (من منزلة الآحاد للعدد الثاني) = 10 -> أزحه 3 خانات إلى اليسار (لأننا نضرب في منزلة الآحاد من العدد الثاني) لتحصل على 10000
- 5 (من منزلة الآلاف للعدد الأول) * 3 (من منزلة العشرات للعدد الثاني) = 15 -> أزحه 4 خانات إلى اليسار (لأننا نضرب في منزلة العشرات من العدد الثاني) لتحصل على 150000
- 5 (من منزلة الآلاف للعدد الأول) * 9 (من منزلة المئات للعدد الثاني) = 45 -> أزحه 5 خانات إلى اليسار (لأننا نضرب في منزلة المئات من العدد الثاني) لتحصل على 4500000
- 5 (من منزلة الآلاف للعدد الأول) * 1 (من منزلة الآلاف للعدد الثاني) = 5 -> أزحه 6 خانات إلى اليسار (لأننا نضرب في منزلة الآلاف من العدد الثاني) لتحصل على 5000000
الآن، اجمع كل هذه النتائج معًا:
مجموع 8 + 120 + 3600 + 4000 + 80 + 1200 + 36000 + 40000 + 400 + 6000 + 180000 + 200000 + 10000 + 150000 + 4500000 + 5000000 = 10131408.
ثم كتبنا سكريبت بايثون ينشئ أزواجًا من الأسئلة والأجوبة عن طريق اختيار رقمين عشوائيين للضرب. قمنا بتنظيم مجموعة بيانات تحتوي على 40,000 صف.
الآن، بمجرد أن تصبح مجموعة البيانات جاهزة، نحتاج إلى ضبط النموذج بدقة.
نحن نستخدم النسخة المضبوطة للمحادثة (7 مليارات معلمة) من Meta's - لاما-2 كنموذج أساسي.
لقد أجرينا الضبط الدقيق باستخدام الضبط الدقيق QLora باستخدام مكتبة BitsAndBytes و Peft. هذا هو إعداد lora الذي استخدمناه:
LoraConfig(
lora_alpha=16,
lora_dropout=0.1,
r=64,
bias="none",
task_type="CAUSAL_LM",
target_modules=[
"q_proj",
"k_proj",
"v_proj",
"o_proj",
],
)
استغرق التدريب حوالي 8 ساعات على جهاز GPU من نوع A100 بسعة 40 جيجابايت لمجموعة بيانات مكونة من 40,000 صف.
أخيرًا، قمنا بنشر النموذج المُعدّل بدقة على TrueFoundry مرة أخرى، وهذه هي النتائج:
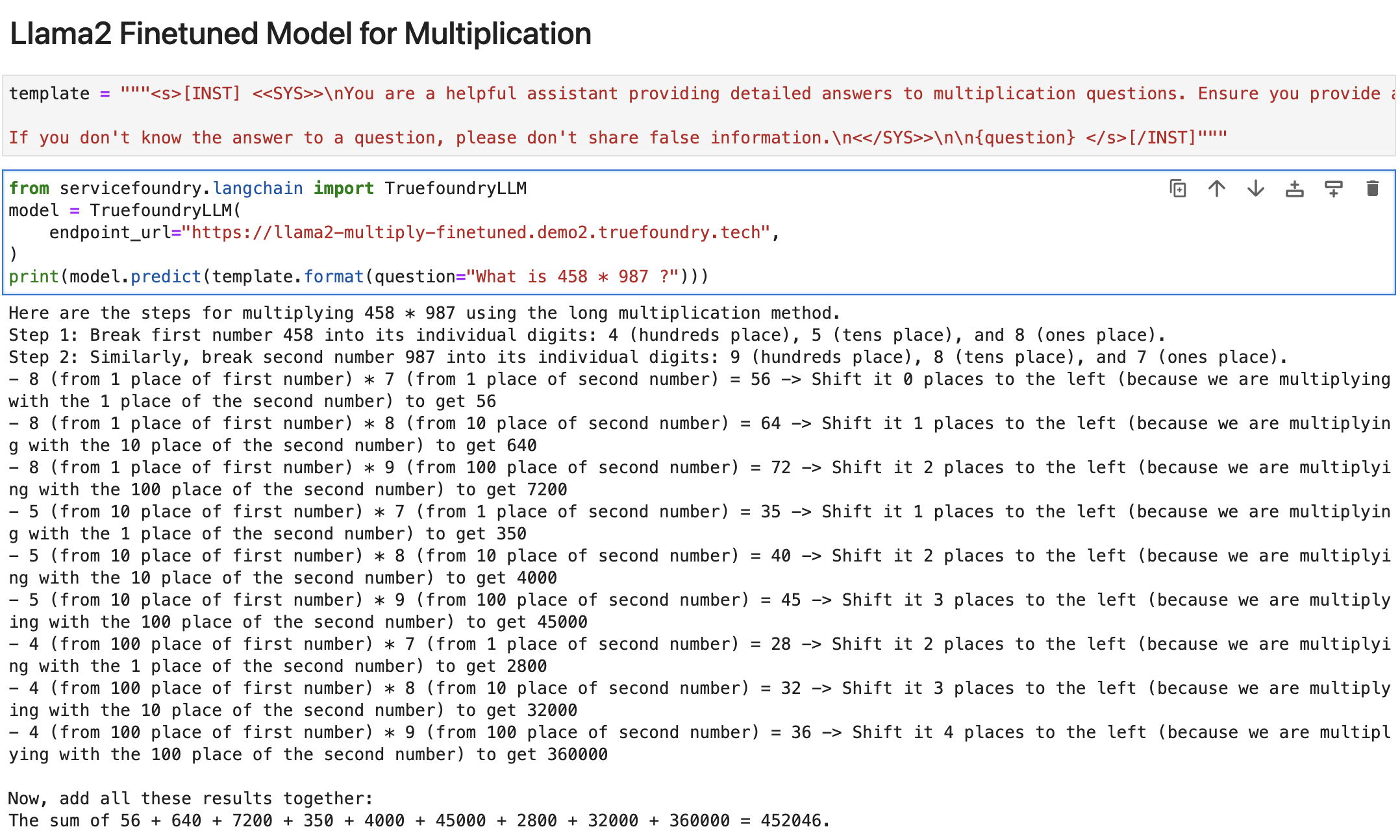
إذن أخيرًا!! يمكننا أن نرى أن النموذج المُعدّل بدقة قادر على حساب النتيجة بشكل صحيح.
على الرغم من أن العمليات الحسابية ليست مهمة سنستخدم فيها نماذج اللغة الكبيرة (LLM)، إلا أن هذا المثال يوضح كيف يمكن لنموذج لغة كبير "صغير" (7 مليار معلمة) تم تعديله بدقة لمهمة محددة أن يتفوق على نماذج اللغة الكبيرة "الضخمة" (مثل GPT3.5 turbo - 175 مليار معلمة و GPT-4) في مهمة معينة.
النماذج الأصغر المدربة بدقة منخفضة التكلفة عند الاستدلال، وأفضل في المهام المتخصصة، ويمكن نشرها بسهولة على سحابتك الخاصة!
كتبنا مقالاً مفصلاً في المدونة حول الضبط الدقيق لـ Llama 2
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








أحدث الأخبار والمقالات والموارد تصلك مباشرة إلى بريدك الوارد
© 2026 جميع الحقوق محفوظة.











.png)
.webp)










.webp)
