




November 5, 2025
|
5 min read


احصل على وصول فوري إلى بيئة TrueFoundry مباشرة. انشر النماذج، ووجّه حركة مرور LLM، واستكشف المنصة بالكامل — بيئة الاختبار الخاصة بك جاهزة في ثوانٍ، ولا يلزم وجود بطاقة ائتمان.









Published: July 4, 2026

Blazingly fast way to build, track and deploy your models!
مع تسريع الشركات لتبني نماذج اللغة الكبيرة (LLMs)، يتحول النقاش بسرعة من التجريب إلى جاهزية الإنتاج. لم تعد الفرق تسأل ما إذا كان يمكن استخدام الذكاء الاصطناعي، بل كيف يمكن نشره بشكل موثوق وآمن وعلى نطاق واسع. يطرح هذا التحول مجموعة جديدة من التحديات: ضمان جودة المطالبات، ومنع التراجعات، والحفاظ على الحوكمة مع تطور النماذج والمطالبات وحالات الاستخدام.
لمعالجة هذه التحديات، تعاونت TrueFoundry و Promptfoo لتقديم حل متكامل بإحكام يُدخل التقييم المنهجي للمطالبات إلى البنية التحتية للذكاء الاصطناعي للمؤسسات. من خلال الجمع بين إمكانيات Promptfoo القوية لاختبار المطالبات وبوابة الذكاء الاصطناعي من TrueFoundry، يمكن للمؤسسات نقل أعباء عمل الذكاء الاصطناعي بثقة إلى بيئة الإنتاج مع الحفاظ على معايير عالية للجودة والموثوقية والحوكمة.
في تطبيقات الذكاء الاصطناعي الحديثة، تُعد المطالبات فعليًا جزءًا من منطق التطبيق. يمكن أن تؤثر التغييرات الطفيفة في المطالبة — أو حتى تغيير في النموذج الأساسي — بشكل كبير على جودة المخرجات أو نبرتها أو صحتها أو سلامتها. على الرغم من ذلك، لا تزال العديد من المؤسسات تعتمد على الاختبار اليدوي أو المراجعات غير الرسمية للتحقق من صحة تغييرات المطالبات قبل الإصدار.
مع توسع أنظمة الذكاء الاصطناعي عبر الفرق والمنتجات، يصبح هذا النقص في الهيكلة خطرًا تجاريًا. يمكن أن تؤدي المخرجات غير المتسقة إلى تدهور تجربة العملاء، ويمكن أن تتسلل التراجعات إلى بيئة الإنتاج دون أن يلاحظها أحد، وتكافح فرق المنصات لفرض معايير الجودة عبر بصمة الذكاء الاصطناعي المتنامية. ما تحتاجه المؤسسات هو طريقة للتعامل مع المطالبات بنفس الصرامة التي تتعامل بها مع التعليمات البرمجية — يتم تقييمها واختبارها وحوكمتها كجزء من مسار النشر.
تم بناء Promptfoo لحل هذه المشكلة بالتحديد. يوفر إطار عمل لتقييم مطالبات نماذج اللغة الكبيرة عبر مجموعات البيانات والنماذج وحالات الاختبار، مما يمكّن الفرق من قياس الجودة بدلاً من الاعتماد على الحدس. باستخدام Promptfoo، يمكن للفرق مقارنة المخرجات عبر النماذج، وتحديد معايير تقييم مخصصة، واكتشاف التراجعات مبكرًا في دورة حياة التطوير.
الأهم من ذلك، يمكّن Promptfoo تقييم المطالبات من أن يصبح قابلاً للتكرار ومؤتمتًا. بدلاً من الاعتماد على المراجعات المخصصة، يمكن للفرق دمج اختبارات المطالبات في سير عمل CI/CD، مما يضمن التحقق من صحة كل تغيير في المطالبة مقابل توقعات محددة بوضوح قبل وصوله إلى بيئة الإنتاج.
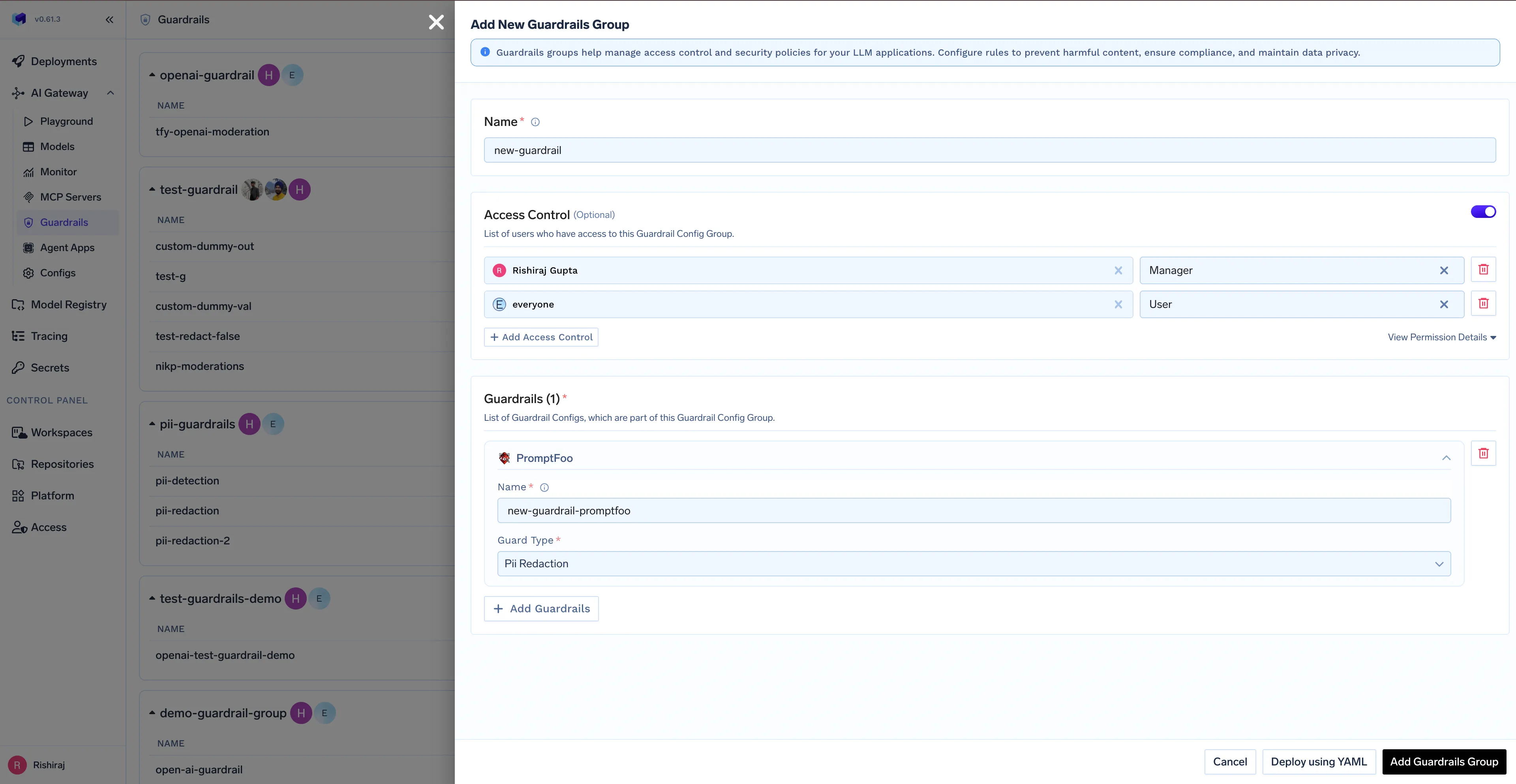
بينما يُعد تقييم المطالبات ضروريًا، تحتاج المؤسسات أيضًا إلى طريقة آمنة وموحدة لتشغيل الذكاء الاصطناعي على نطاق واسع. هنا يأتي دور الـ TrueFoundry AI Gateway تلعب دورًا حاسمًا. توفر بوابة الذكاء الاصطناعي طبقة API موحدة للوصول إلى مئات نماذج اللغة الكبيرة وخوادم MCP وإدارتها، مع فرض متطلبات المؤسسات مثل المصادقة، والتحكم في الوصول، وإمكانية المراقبة، وتطبيق السياسات.
من خلال مركزة حركة مرور الذكاء الاصطناعي عبر البوابة، تكتسب المؤسسات رؤية وتحكمًا في كيفية استخدام النماذج عبر الفرق والبيئات. يضمن هذا النهج المعماري أن ابتكار الذكاء الاصطناعي لا يأتي على حساب الأمان أو الامتثال أو التعقيد التشغيلي.
يجمع التكامل بين Promptfoo وبوابة TrueFoundry للذكاء الاصطناعي هاتين الإمكانيتين معًا في سير عمل سلس. يمكن الآن تكوين تقييمات Promptfoo كـ حواجز حماية داخل البوابة، مما يسمح بتقييم كل طلب مقابل معايير الجودة والسلوك المحددة.
هذا يعني أن تقييم الموجهات لم يعد مقتصرًا على بيئات التطوير أو الاختبار. بدلاً من ذلك، يصبح سياسة قابلة للتطبيق على مستوى البنية التحتية. يمكن وضع علامة على الطلبات التي تفشل في معايير التقييم، أو تسجيلها، أو حظرها، مما يضمن وصول سلوك الذكاء الاصطناعي المعتمد فقط إلى المستخدمين والأنظمة النهائية.
من خلال تضمين تقييم الموجهات مباشرة في بوابة الذكاء الاصطناعي، تكتسب المؤسسات آلية واحدة ومتسقة لفرض الجودة عبر النماذج والفرق والتطبيقات.
من منظور الأعمال، تساعد هذه الشراكة المؤسسات على التحرك بشكل أسرع دون زيادة المخاطر. يقلل تقييم الموجهات الآلي الوقت المستغرق في المراجعات اليدوية وتصحيح الأخطاء، مما يمكّن الفرق من إطلاق ميزات الذكاء الاصطناعي بسرعة أكبر وبثقة أكبر. في الوقت نفسه، يضمن التنفيذ المركزي عبر البوابة الاتساق، حتى مع توسع استخدام الذكاء الاصطناعي عبر المؤسسة.
بالنسبة لقادة المنصات والهندسة، يبسط هذا التكامل الحوكمة. بدلاً من الاعتماد على الأدوات المجزأة والعمليات غير الرسمية، يمكن للفرق تحديد معايير جودة الموجهات على مستوى المؤسسة وتطبيقها بشكل موحد. يؤدي هذا إلى عدد أقل من حوادث الإنتاج، وتحسين ثقة العملاء، ومواءمة أفضل بين سرعة الهندسة وتوقعات الأعمال.
تعكس الشراكة بين TrueFoundry و Promptfoo تحولًا أوسع في كيفية تعامل المؤسسات مع الذكاء الاصطناعي. مع تحول نماذج اللغة الكبيرة (LLMs) إلى أساس للمنتجات وسير العمل، تحتاج المؤسسات إلى بنية تحتية تدعم ليس فقط التجريب، بل الموثوقية والحوكمة على المدى الطويل.
من خلال الجمع بين البنية التحتية للذكاء الاصطناعي على مستوى المؤسسات مع التقييم المنهجي للموجهات، تمكّن TrueFoundry و Promptfoo الفرق من التعامل مع الموجهات كعناصر أساسية في دورة حياة البرمجيات — يتم اختبارها وحوكمتها ونشرها بثقة.
يمكن للمؤسسات البدء في استخدام التكامل عن طريق تكوين Promptfoo كحاجز حماية داخل بوابة TrueFoundry للذكاء الاصطناعي وتحديد معايير التقييم المتوافقة مع متطلبات أعمالها ومنتجاتها. من هنا، تصبح جودة الموجهات معيارًا قابلاً للتطبيق بدلاً من ممارسة تعتمد على بذل أقصى جهد.
لمعرفة المزيد حول كيفية إعداد التكامل واستخدامه، استكشف وثائق TrueFoundry:
https://truefoundry.com/docs/ai-gateway/promptfoo
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








أحدث الأخبار والمقالات والموارد تصلك مباشرة إلى بريدك الوارد
© 2026 جميع الحقوق محفوظة.











.png)
.webp)










.webp)
