







July 20, 2023
|
5 min read


احصل على وصول فوري إلى بيئة TrueFoundry مباشرة. انشر النماذج، ووجّه حركة مرور LLM، واستكشف المنصة بالكامل — بيئة الاختبار الخاصة بك جاهزة في ثوانٍ، ولا يلزم وجود بطاقة ائتمان.









Published: July 4, 2026

Blazingly fast way to build, track and deploy your models!
قد يكون نشر نماذج اللغة الكبيرة مفتوحة المصدر (LLMs) على نطاق واسع، مع ضمان الموثوقية وزمن الاستجابة المنخفض والفعالية من حيث التكلفة، مسعىً صعبًا. استنادًا إلى خبرتنا الواسعة في بناء البنية التحتية لـ LLM ونشرها بنجاح لعملائنا، قمت بتجميع قائمة بالتحديات الرئيسية التي يواجهها الأفراد عادةً في هذه العملية.
هناك خيارات متعددة لخوادم النماذج لاستضافة نماذج اللغة الكبيرة ومعلمات تكوين متنوعة لضبطها للحصول على أفضل أداء لحالة الاستخدام الخاصة بك. TGI، VLLM، OpenLLM هي بعض من الأطر الأكثر شيوعًا لاستضافة نماذج اللغة الكبيرة هذه. يمكنك العثور على تحليل مفصل في هذا الـ المدونة. لاختيار الإطار الصحيح لاستضافتك، من المهم قياس أداء هذه الأطر لحالة الاستخدام الخاصة بك واختيار الأنسب لها. بالإضافة إلى ذلك، تحتوي هذه الأطر على معلمات قابلة للضبط يمكن أن تساعدك في الحصول على أفضل نتائج القياس.
وحدات معالجة الرسوميات (GPUs) باهظة الثمن ويصعب العثور عليها. هناك العديد من مزودي خدمات السحابة لوحدات معالجة الرسوميات، بدءًا من السحابات البارزة مثل AWS و GCP و Azure وصولاً إلى مزودي السحابة الصغيرة مثل Runpod و Fluidstack و Paperspace و Coreweave. يوجد تباين كبير في الأسعار والعروض لكل من هؤلاء المزودين. كما تظل الموثوقية مصدر قلق لدى بعض مزودي السحابة لوحدات معالجة الرسوميات الأحدث.
هذا في الواقع أصعب مما يبدو. من خلال تجربتنا في تشغيل نماذج اللغة الكبيرة في بيئة الإنتاج، يجب أن تكون مستعدًا للأخطاء الغريبة التي تحدث لمرة واحدة في خوادم النماذج والتي يمكن أن تتسبب في تعليق عمليتك وانتهاء مهلة جميع الطلبات. من المهم جدًا إعداد مديري عمليات مناسبين ومجسات الجاهزية/الحيوية (readiness/liveness probes) حتى تتمكن خوادم النماذج من التعافي من الأعطال أو يمكن تحويل حركة المرور بسلاسة من مثيل غير صحي إلى مثيل صحي.
أثناء قياس الأداء، من المهم جدًا تحديد المفاضلة بين زمن الاستجابة والإنتاجية. مع زيادة عدد الطلبات المتزامنة للنموذج، سيزداد زمن الاستجابة قليلاً حتى نقطة معينة، وبعد ذلك يتدهور زمن الاستجابة بشكل كبير. قد يكون العثور على التوازن الصحيح بين زمن الاستجابة والإنتاجية والتكلفة مستهلكًا للوقت وعرضة للأخطاء. لدينا بعض المدونات التي تحدد مثل هذه المعايير لـ Llama7B و Llama13B.
نماذج LLM ضخمة الحجم - تتراوح أحجامها من عشرات إلى مئات الجيجابايت. قد يستغرق تنزيل النموذج وقتًا طويلاً بمجرد أن يصبح خادم النموذج جاهزًا، ثم تحميله من القرص إلى الذاكرة. من الضروري تخزين النموذج مؤقتًا على القرص حتى لا نضطر إلى تنزيل النموذج مرة أخرى في حال إعادة تشغيل العملية. وللتوفير في تكاليف الشبكة، من الأفضل تنزيل النموذج مرة واحدة ومشاركة القرص بين عدة نسخ متماثلة بدلاً من أن تقوم كل نسخة متماثلة بتنزيل النموذج مرارًا وتكرارًا عبر الإنترنت.
التحجيم التلقائي معقد في حالة استضافة نماذج LLM بسبب وقت بدء التشغيل الطويل لنسخة متماثلة أخرى. إذا كان الحمل متقلبًا للغاية، عادة ما نحتاج إلى توفير البنية التحتية وفقًا لعدد النسخ المتماثلة القصوى - ولكن إذا كان من المتوقع أن تحدث الذروة في أوقات معينة من اليوم، فإن التحجيم التلقائي المستند إلى الوقت يعمل بشكل جيد.
بدأنا بالنهج المذكور أعلاه، ولكن سرعان ما انتقلنا إلى البنية أدناه التي تتيح لنا استضافة نماذج اللغة الكبيرة (LLMs) بتكاليف منخفضة جدًا وموثوقية عالية.
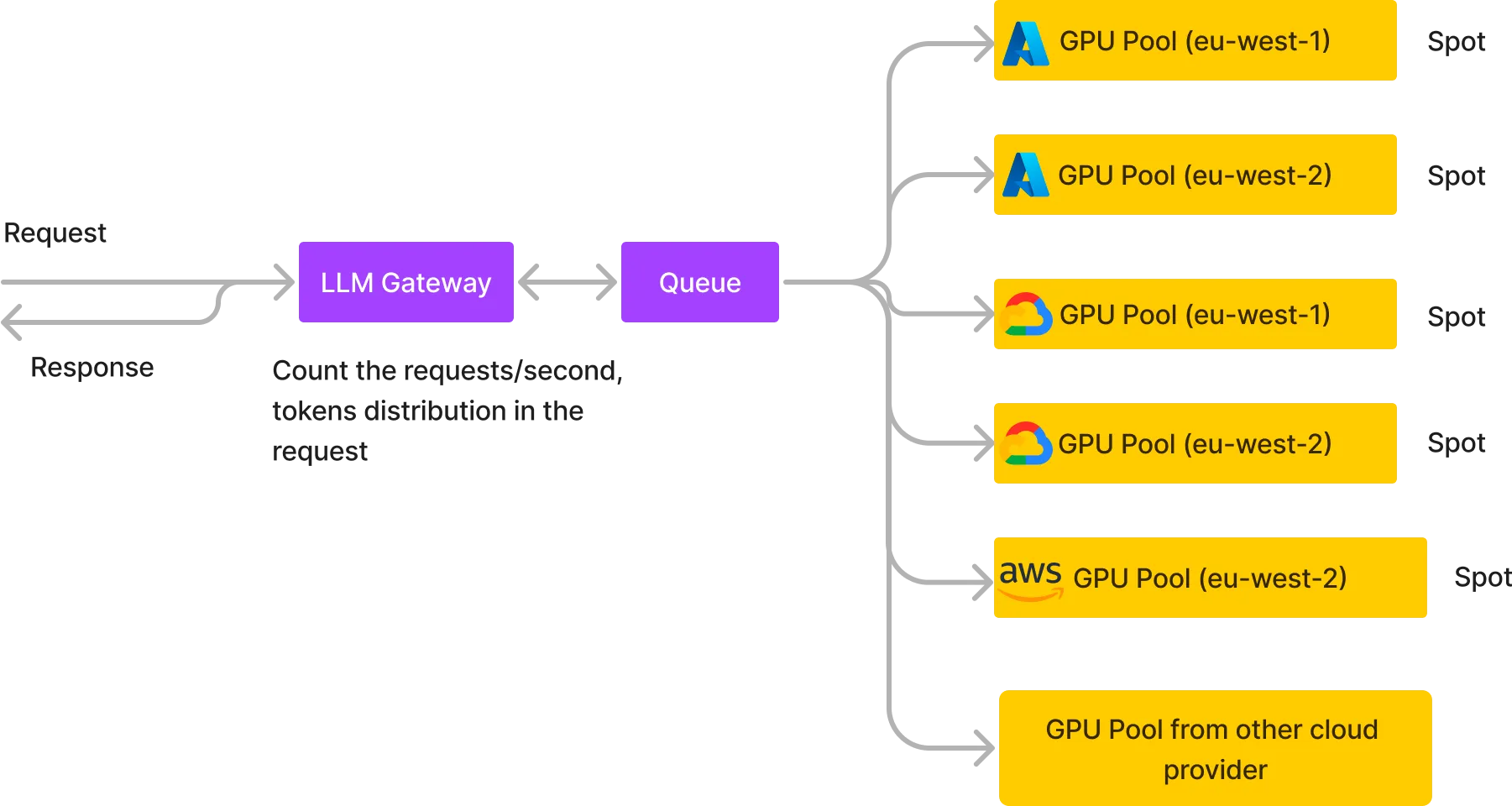
نقوم أساسًا بإنشاء مجموعات متعددة من وحدات معالجة الرسوميات (GPU) لدى مقدمي خدمات سحابية مختلفين وفي مناطق مختلفة، وعادة ما نستخدم المثيلات الفورية إذا كان أحدها AWS أو GCP أو Azure، أو العقد حسب الطلب من مقدمي الخدمات السحابية الأصغر. كما نضع قائمة انتظار في المنتصف تستقبل جميع الطلبات، وتستهلك مجموعات وحدات معالجة الرسوميات المختلفة من قائمة الانتظار وتعيد الاستجابة إليها، ومن ثم يتم إرجاع استجابة HTTP للمستخدم. بعض مزايا هذه البنية:
لنفترض سيناريو استضافة نموذج لغة كبير (LLM) بمعدل 10 طلبات في الثانية في الذروة و7 طلبات في الثانية في المتوسط. لنقل إننا اكتشفنا باستخدام المقارنة المعيارية أن جهاز GPU واحد من نوع A100 بحجم 80 جيجابايت يمكنه معالجة 0.5 طلب في الثانية. دعنا نأخذ في الاعتبار أيضًا أن حركة المرور تكون أعلى لمدة 12 ساعة في اليوم (حوالي 9-10 طلبات في الثانية) ومنخفضة لبقية الـ 12 ساعة في اليوم (7-8 طلبات في الثانية).
بناءً على البيانات المذكورة أعلاه، يمكننا إيجاد عدد أجهزة GPU المطلوبة في فترة الذروة التي تبلغ 12 ساعة وفي فترة غير الذروة التي تبلغ 12 ساعة:
فترة الذروة (12 ساعة): 20 وحدة معالجة رسوميات (GPU)
فترة غير الذروة (12 ساعة): 15 وحدة معالجة رسومية (GPU)
سنقارن تكلفة تشغيل نموذج اللغة الكبير (LLM) باستخدام Sagemaker، والاستضافة المباشرة على أجهزة عند الطلب في AWS وGCP وAzure، واستخدام بنيتنا الخاصة مع التحجيم التلقائي.
تكلفة الاستضافة على Sagemaker (منطقة us-east-1):
تكلفة جهاز واحد من نوع 8 A100 80GB (ml.p4de.24xlarge) -> 47.11 دولارًا في الساعة
سنحتاج إلى جهازين خلال ساعات خارج الذروة وثلاثة أجهزة خلال ساعات الذروة.
التكلفة الشهرية الإجمالية: 85 ألف دولار
تكلفة الاستضافة على عقد AWS مباشرة:
تكلفة جهاز واحد من نوع 8 A100 80GB (p4de.24xlarge) -> 40.966 دولارًا في الساعة
سنحتاج إلى جهازين خلال ساعات خارج الذروة وثلاثة أجهزة خلال ساعات الذروة:
التكلفة الشهرية الإجمالية: 73 ألف دولار
تكلفة الاستضافة على Truefoundry
باستخدام النسخ الفورية ومقدمي وحدات معالجة الرسوميات الآخرين، تمكنا من خفض متوسط أسعار وحدات معالجة الرسوميات إلى 2.5 دولار في الساعة. بافتراض 15 وحدة معالجة رسوميات خلال ساعات خارج الذروة و20 وحدة معالجة رسوميات خلال ساعات الذروة، ستكون التكلفة الإجمالية:
2.5 دولار * (15*12 + 20*12) * 30 (يومًا في الشهر) = 31 ألف دولار
كما نرى، يمكننا استضافة نفس نموذج اللغة الكبير (LLM) بحوالي 30% من سعر Sagemaker وبموثوقية عالية. ومع ذلك، سيتطلب ذلك جهودًا لبناء هذه البنية وصيانتها. TrueFoundry يمكن أن تساعد في استضافته لك أو استضافته على حسابك السحابي الخاص بدون أي عناء مع توفير التكاليف في نفس الوقت.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








أحدث الأخبار والمقالات والموارد تصلك مباشرة إلى بريدك الوارد
© 2026 جميع الحقوق محفوظة.











.png)
.webp)










.webp)
