




July 4, 2026
|
5 min read


احصل على وصول فوري إلى بيئة TrueFoundry مباشرة. انشر النماذج، ووجّه حركة مرور LLM، واستكشف المنصة بالكامل — بيئة الاختبار الخاصة بك جاهزة في ثوانٍ، ولا يلزم وجود بطاقة ائتمان.









Published: July 4, 2026
Blazingly fast way to build, track and deploy your models!
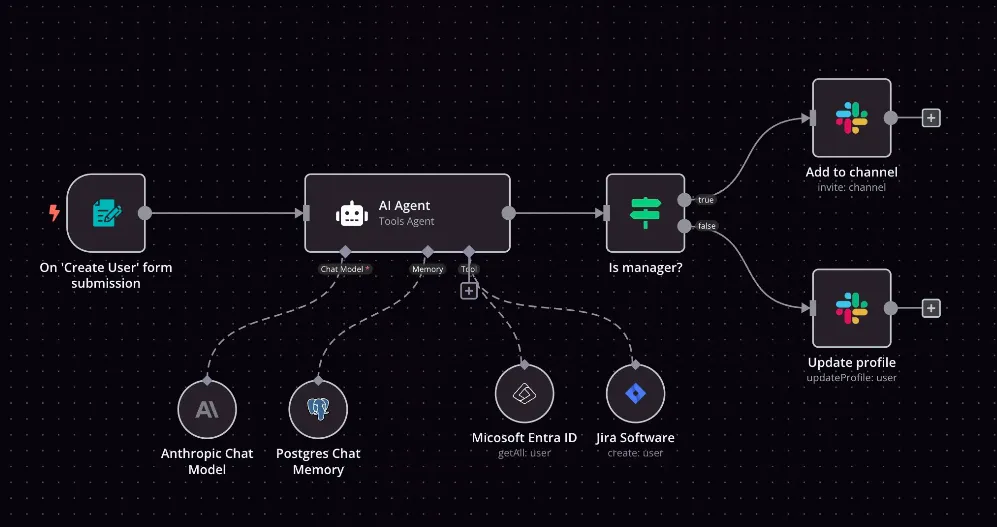
ازدهرت أدوات البناء منخفضة الكود مثل Flowise لسرعتها. تتيح لوحة السحب والإفلات لعلماء البيانات ومديري المنتجات ربط المطالبات والأدوات والبحث المتجه والوكلاء متعددي الخطوات - دون الحاجة إلى بايثون. يتم إطلاق إثباتات المفهوم في ساعات، وليس أسابيع. ولكن عندما تبدأ هذه النماذج الأولية في تحقيق قيمة حقيقية، تظهر التكلفة الخفية: كل عقدة تستدعي نقطة نهاية نموذج مختلفة، ولكل منها مفتاح API الخاص بها، وسجلات الاستخدام الخاصة بها، وبندها الخاص في بطاقة الشركة. اضرب ذلك عبر الفرق والتجارب ولن يتمكن أحد من الإجابة على الأساسيات: من استدعى ماذا؟ كم كلّف ذلك؟ هل كان آمنًا؟
هذا هو بالضبط ما تحله بوابة الذكاء الاصطناعي TrueFoundry. تعالج أكثر من مليون استدعاء لنموذج لغوي كبير يوميًا للمؤسسات، وتطبق مصادقة على مستوى المشروع، وضوابط تكلفة لكل طلب، واتفاقيات مستوى خدمة زمن الاستجابة (SLOs)، وسجلات تدقيق كاملة - سواء كنت تستخدم GPT‑5 أو Claude 4 أو Mistral أو نموذجًا داخليًا مُعدلاً بدقة. طلبت منا الفرق تطبيق نفس الضوابط الوقائية على وكلاء Flowise. لذا إليك المدونة المفصلة حول: لماذا يجب أن تكون وكلاء الكود المنخفض خلف البوابة
هذه هي نفس الحوكمة التي نطبقها بالفعل على حركة المرور الحيوية (>1 مليون استدعاء/يوم). إضافة Flowise ببساطة يوسعها لتشمل تجاربك منخفضة الكود. لإلقاء نظرة سريعة على بوابة الذكاء الاصطناعي TrueFoundry، تفضل بزيارة: رابط
المتطلبات المسبقة
الإعداد في خطوتين قصيرتين
يمكنك العثور على دليل إرشادي أكثر تفصيلاً، مكتمل بلقطات الشاشة، في وثائقنا
بمجرد ملء هذين الحقلين، يرث Flowise كل ما تفعله البوابة بالفعل لأعباء العمل الإنتاجية:
هل تريد البدء؟ سجل حسابك هنا: ترو فاوندري لا يلزم وجود بطاقة ائتمان :), اتبع خطوات الإعداد في دليل البدء السريع، وستحصل على حزمة ذكاء اصطناعي جاهزة للإنتاج تعمل في حوالي 15 دقيقة. لا توجد عمليات ترحيل معقدة، ولا إعادة كتابة للتعليمات البرمجية - فقط أداء أفضل وأمان وتحكم لتطبيقات الذكاء الاصطناعي الخاصة بك.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








أحدث الأخبار والمقالات والموارد تصلك مباشرة إلى بريدك الوارد
© 2026 جميع الحقوق محفوظة.







.png)
.webp)










.webp)
