





July 20, 2023
|
5 min read


احصل على وصول فوري إلى بيئة TrueFoundry مباشرة. انشر النماذج، ووجّه حركة مرور LLM، واستكشف المنصة بالكامل — بيئة الاختبار الخاصة بك جاهزة في ثوانٍ، ولا يلزم وجود بطاقة ائتمان.









Published: July 4, 2026

Blazingly fast way to build, track and deploy your models!
نقوم في هذه المقالة بقياس أداء LLama2-13B من منظور زمن الاستجابة والتكلفة وعدد الطلبات في الثانية. سيساعدنا هذا في تقييم ما إذا كان خيارًا جيدًا بناءً على متطلبات العمل. يرجى ملاحظة أننا لا نغطي الأداء النوعي في هذه المقالة - هناك طرق مختلفة لمقارنة نماذج اللغات الكبيرة (LLMs) يمكن العثور عليها هنا.
في هذه المدونة، قمنا بقياس أداء Llama-2-13B نموذج من NousResearch. هذه نسخة مدربة مسبقًا من Llama-2 تحتوي على 13 مليار معلمة.
قامت ميتا بتطوير وإطلاق علني لعائلة Llama 2 من نماذج اللغات الكبيرة (LLMs)، وهي مجموعة من نماذج النصوص التوليدية المدربة مسبقًا والمُحسّنة تتراوح أحجامها من 7 مليارات إلى 70 مليار معلمة.
العوامل الرئيسية التي قمنا بقياس أدائها هي:
نوع وحدة معالجة الرسوميات (GPU):
طول المطالبة:
لقياس الأداء، استخدمنا Locust، وهي أداة مفتوحة المصدر لاختبار التحميل. تعمل Locust عن طريق إنشاء مستخدمين/عاملين لإرسال الطلبات بالتوازي. في بداية كل اختبار، يمكننا تعيين عدد المستخدمين و معدل التوليد. هنا، يشير عدد المستخدمين إلى العدد الأقصى للمستخدمين الذين يمكنهم الظهور/العمل بالتزامن، بينما يشير معدل الظهور يمثل عدد المستخدمين الذين سيتم إنشاؤهم في الثانية.
في كل اختبار أداء لتكوين نشر، بدأنا من 1 مستخدم واستمررنا في زيادة عدد المستخدمين تدريجياً حتى لاحظنا زيادة مطردة في RPS. خلال الاختبار، قمنا أيضًا برسم أوقات الاستجابة (بالمللي ثانية) و إجمالي الطلبات في الثانية.
في كل من تكويني النشر، استخدمنا خادم نموذج huggingface text-generation-inference الذي يحمل version=0.9.4. فيما يلي المعلمات التي تم تمريرها إلى text-generation-inference صورة لتكوينات النماذج المختلفة:
نحسب أفضل وقت استجابة بناءً على إرسال طلب واحد فقط في كل مرة. لزيادة الإنتاجية، نرسل الطلبات بالتوازي إلى نموذج اللغة الكبير (LLM). تتحقق أقصى إنتاجية عندما يكون النموذج قادرًا على معالجة طلبات الإدخال دون تدهور كبير في وقت الاستجابة.
تعالج نماذج اللغة الكبيرة (LLMs) الرموز المدخلة وعملية التوليد بشكل مختلف - لذلك، قمنا بحساب معدل معالجة الرموز المدخلة والرموز المخرجة بشكل منفصل.

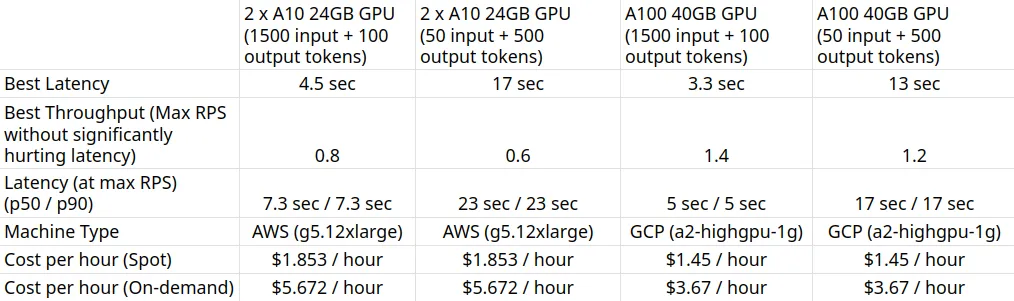
2 وحدة معالجة رسوميات A10 بسعة 24 جيجابايت (1500 رمز إدخال + 100 رمز إخراج)
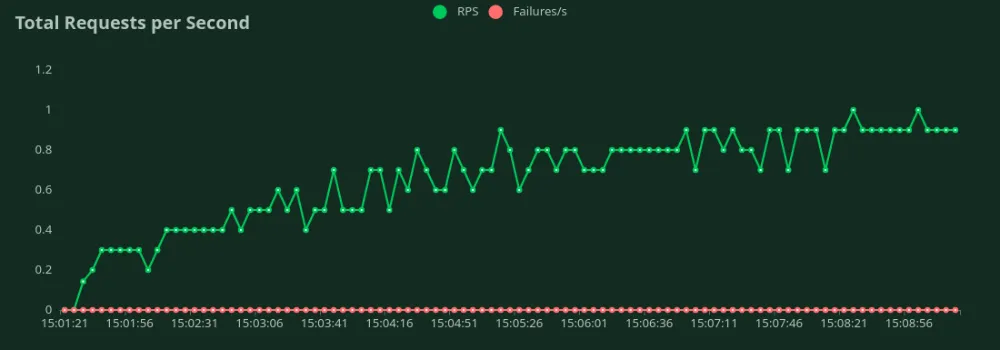
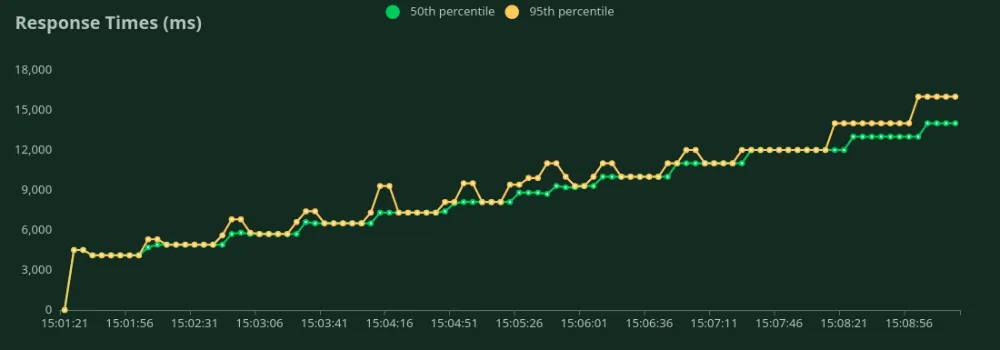
يمكننا أن نلاحظ في الرسوم البيانية أعلاه أن الـ أفضل وقت استجابة (عند مستخدم واحد) يبلغ 4.5 ثانية. يمكننا زيادة عدد المستخدمين لتوجيه المزيد من حركة المرور إلى النموذج - نلاحظ زيادة الإنتاجية حتى 0.8 طلب في الثانية (RPS) دون انخفاض كبير في وقت الاستجابة. بعد تجاوز 0.8 طلب في الثانية (RPS)، يزداد وقت الاستجابة بشكل كبير مما يعني أن الطلبات تتراكم في قائمة الانتظار.
2 وحدة معالجة رسوميات A10 بسعة 24 جيجابايت (50 رمز إدخال + 500 رمز إخراج)
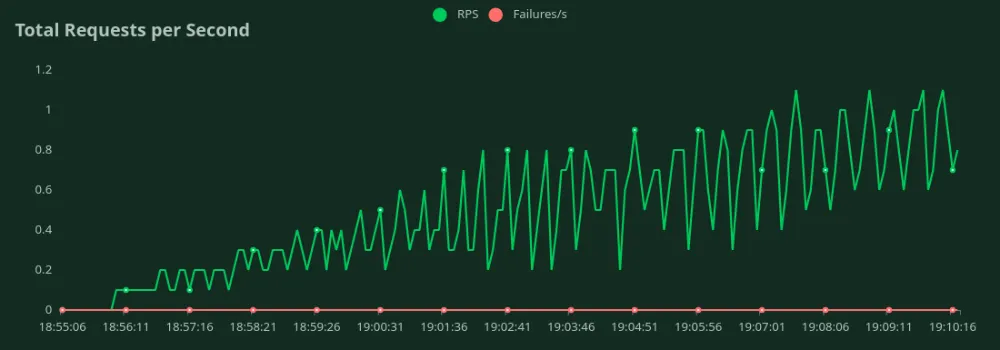
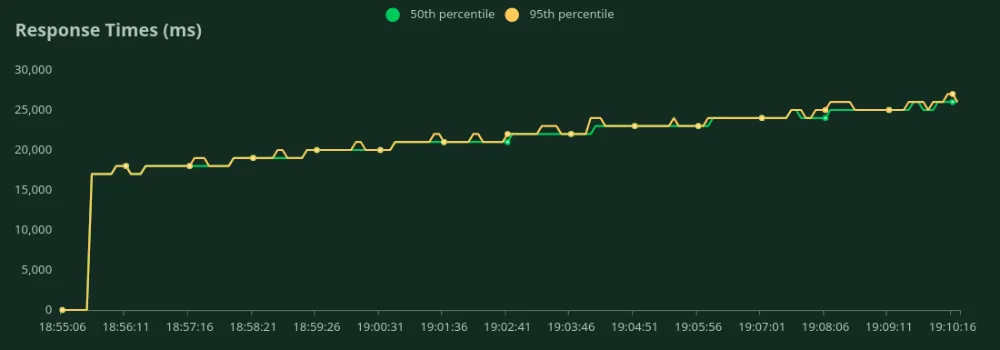
يمكننا أن نلاحظ في الرسوم البيانية أعلاه أن أفضل وقت استجابة (عند مستخدم واحد) هو 17 ثانية. يمكننا زيادة عدد المستخدمين لزيادة الحمل على النموذج - نلاحظ أن الإنتاجية تزداد حتى 0.6 طلب في الثانية دون انخفاض كبير في زمن الاستجابة. بعد 0.6 طلب في الثانية، يزداد زمن الاستجابة بشكل كبير مما يعني أن الطلبات توضع في قائمة الانتظار.
وحدة معالجة رسوميات A100 بسعة 40 جيجابايت (1500 رمز إدخال + 100 رمز إخراج)
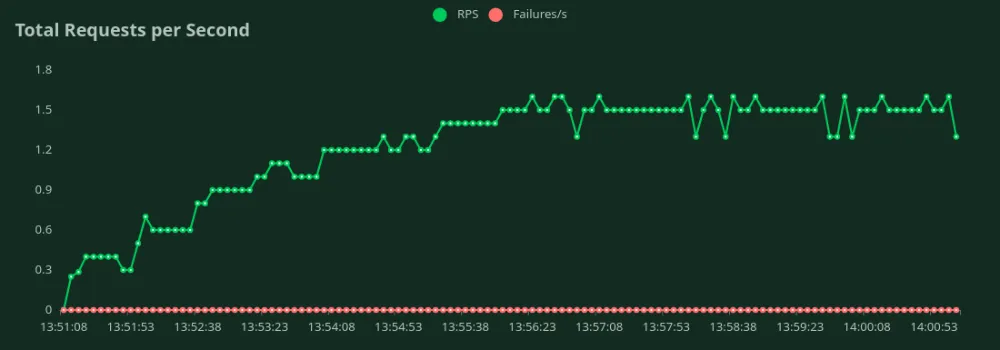
يمكننا أن نلاحظ في الرسوم البيانية أعلاه أن أفضل وقت استجابة (عند مستخدم واحد) هو 3.3 ثانية. يمكننا زيادة عدد المستخدمين لزيادة الحمل على النموذج - نلاحظ أن الإنتاجية تزداد حتى 1.4 RPS دون انخفاض كبير في زمن الاستجابة. بعد تجاوز 1.4 RPS، يزداد زمن الاستجابة بشكل كبير مما يعني أن الطلبات تتراكم في قائمة الانتظار.
وحدة معالجة رسوميات A100 40GB (50 رمز إدخال + 500 رمز إخراج)
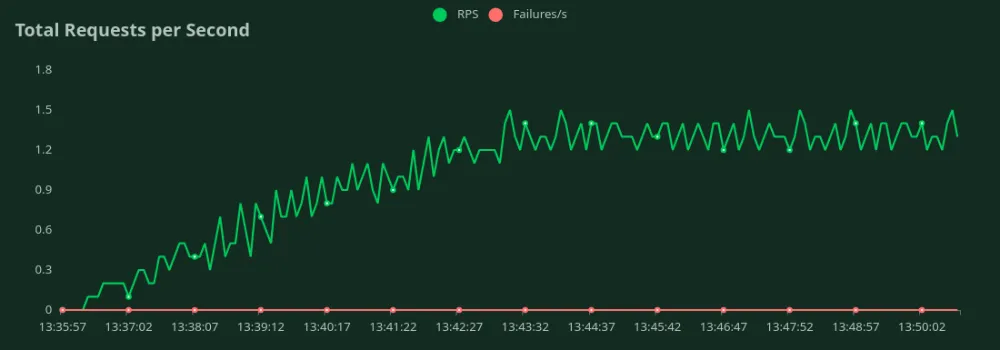
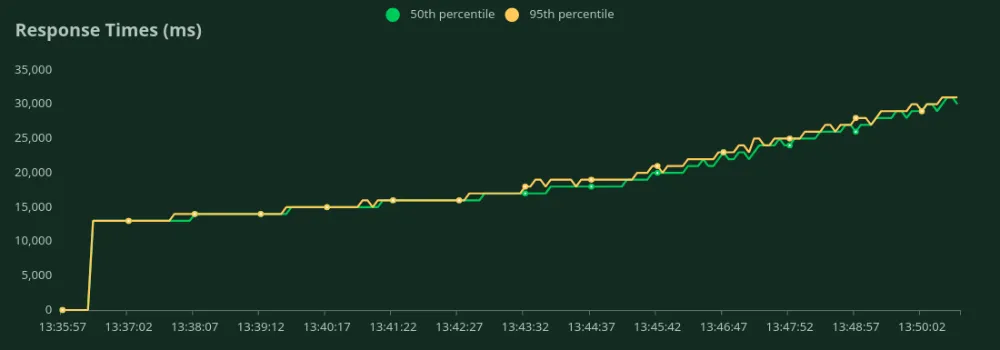
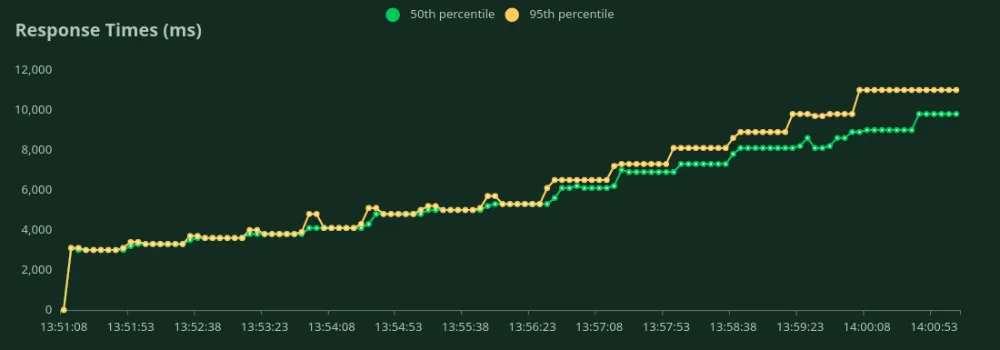
يمكننا ملاحظة في الرسوم البيانية أعلاه أن الـ أفضل زمن استجابة (عند مستخدم واحد) هو 13 ثانية. يمكننا زيادة عدد المستخدمين لتوجيه المزيد من حركة المرور إلى النموذج - نلاحظ أن الإنتاجية تزداد حتى 1.2 RPS دون انخفاض كبير في زمن الاستجابة. بعد تجاوز 1.2 RPS، يزداد زمن الاستجابة بشكل كبير مما يعني أن الطلبات تتراكم في قائمة الانتظار.
نأمل أن يكون هذا مفيدًا لك لتحديد ما إذا كان LLama2-13B سيناسب حالة استخدامك والتكاليف التي يمكنك توقعها عند استضافة LLama2-13B.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








أحدث الأخبار والمقالات والموارد تصلك مباشرة إلى بريدك الوارد
© 2026 جميع الحقوق محفوظة.











.png)
.webp)










.webp)
