




November 5, 2025
|
5 min read


احصل على وصول فوري إلى بيئة TrueFoundry مباشرة. انشر النماذج، ووجّه حركة مرور LLM، واستكشف المنصة بالكامل — بيئة الاختبار الخاصة بك جاهزة في ثوانٍ، ولا يلزم وجود بطاقة ائتمان.









Published: July 4, 2026
Blazingly fast way to build, track and deploy your models!
في سلسلة مدوناتنا حول Kubernetes، تحدثنا عن بناء عمليات تعلم الآلة (MLOps) القابلة للتوسع على Kubernetes، هندسة معمارية لعمليات تعلم الآلة (MLOps)، و حل مشكلات تطوير التطبيقات. في هذه المدونة، سنتحدث عن استضافة خدمة GRPC على مجموعة AWS EKS. العملية ستكون متشابهة تقريبًا لكل مجموعة Kubernetes — ومع ذلك، كان علينا إجراء بعض الإعدادات المحددة على موازن تحميل AWS لكي يعمل هذا.
gRPC هو إطار عمل RPC مفتوح المصدر يمكن تشغيله في أي بيئة. إنه قادر على ربط الخدمات بكفاءة داخل مراكز البيانات وفيما بينها، مع القدرة على إضافة دعم لموازنة التحميل والتتبع وفحص السلامة والمصادقة.
حالة استخدامنا: استضافة نماذج Tensorflow كواجهات برمجة تطبيقات (APIs) تقبل حمولة بحجم حوالي 100 ميجابايت. يؤدي GRPC أداءً أفضل بكثير للحمولات الأكبر — لذلك قمنا بتعريض منفذ GRPC على المنفذ 5000.
لقد استضفنا الخدمة على Kubernetes باستخدام ملف Deployment YAML أدناه:
apiVersion: apps/v1
kind: Deployment
metadata:
name: ml-api
namespace: ml-services
spec:
replicas: 1
selector:
matchLabels:
truefoundry.com/component: ml-api
template:
metadata:
labels:
truefoundry.com/application: ml-api
spec:
containers:
- name: ml-api
image: >-
XXXX.dkr.ecr.us-east-1.amazonaws.com/ml-services-ml-api:latest
ports:
- name: port-8500
containerPort: 8500
protocol: TCP
resources:
limits:
cpu: '4'
ephemeral-storage: 2G
memory: 4G
requests:
cpu: '1'
ephemeral-storage: 1G
memory: 500M
imagePullPolicy: IfNotPresent
restartPolicy: Always
terminationGracePeriodSeconds: 30
dnsPolicy: ClusterFirst
securityContext: {}
imagePullSecrets:
- name: ml-api-image-pull-secret
schedulerName: default-scheduler
strategy:
type: RollingUpdate
rollingUpdate:
maxUnavailable: 25%
maxSurge: 0
سيؤدي هذا إلى تشغيل الـ pod. نحتاج إلى إنشاء كائن الخدمة (Service object) باستخدام ملف YAML التالي:
apiVersion: networking.istio.io/v1alpha3
kind: Gateway
metadata:
labels:
argocd.argoproj.io/instance: tfy-istio-ingress
name: tfy-wildcard
namespace: istio-system
spec:
selector:
istio: tfy-istio-ingress
servers:
- hosts:
- 'ml.example.com'
port:
name: http-tfy-wildcard
number: 80
protocol: HTTP
tls:
httpsRedirect: true
- المضيفون:
- 'ml.example.com'
المنفذ:
الاسم: https-tfy-wildcard
الرقم: 443
البروتوكول: HTTP
نحن نستخدم Istio كطبقة دخول في Kubernetes. يوفر Istio موازن تحميل عند تثبيت istio-ingress. يمكن تخصيص إعدادات موازن التحميل باستخدام التعليقات التوضيحية على بوابة Istio. مواصفات إنشاء بوابة Istio هي كما يلي:
apiVersion: networking.istio.io/v1alpha3
النوع: Gateway
البيانات الوصفية:
التصنيفات:
argocd.argoproj.io/instance: tfy-istio-ingress
الاسم: tfy-wildcard
مساحة الاسم: istio-system
المواصفات:
المحدد:
istio: tfy-istio-ingress
الخوادم:
- المضيفون:
- 'ml.example.com'
port:
name: http-tfy-wildcard
number: 80
protocol: HTTP
tls:
httpsRedirect: true
- hosts:
- 'ml.example.com'
port:
name: https-tfy-wildcard
number: 443
protocol: HTTP
نقوم بإنهاء SSL على موازن التحميل الخاص بـ AWS. ولهذا، يجب علينا إرفاق الشهادة بموازن التحميل. يمكن تحقيق ذلك باستخدام التعليقات التوضيحية أدناه لمخطط بوابة Istio (https://istio-release.storage.googleapis.com/charts).
"service.beta.kubernetes.io/aws-load-balancer-type": "nlb"
"service.beta.kubernetes.io/aws-load-balancer-backend-protocol": "tcp"
"service.beta.kubernetes.io/aws-load-balancer-ssl-cert": "<certificate-arn>"
"service.beta.kubernetes.io/aws-load-balancer-ssl-ports": "https"
"service.beta.kubernetes.io/aws-load-balancer-alpn-policy": "HTTP2Preferred"
تعد سياسة alpn-policy مهمة لتحديدها للسماح بحركة مرور GRPC. يمكن كشف خدمتنا ml-api عن طريق إنشاء VirtualService يشير إلى خدمة Kubernetes. YAML لـ Virtual Service هو كما يلي:
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
labels:
argocd.argoproj.io/instance: ml-services_ml-api
name: ml-apiport-8500-vs
namespace: ml-services
spec:
gateways:
- istio-system/tfy-wildcard
hosts:
- ml.example.com
http:
- route:
- destination:
host: ml-api
port:
number: 8500
بمجرد إتاحة الخدمة الافتراضية، يمكننا إرسال طلبات إلى خدمتنا على ml.example.com. أردنا بعد ذلك إضافة مصادقة إلى واجهة برمجة التطبيقات (API) حتى لا يتمكن الجميع من استدعائها. كان بإمكاننا إضافة المصادقة في الكود، لكننا قررنا إضافتها في طبقة Istio لتكون طبقة موحدة عبر جميع الخدمات.
لإضافة المصادقة في طبقة istio-ingress، قررنا المضي قدمًا بـ مكون IstioWasm الإضافي. يبدو ملف YAML الخاص بالمكون الإضافي كالتالي:
apiVersion: extensions.istio.io/v1alpha1
kind: WasmPlugin
metadata:
name: ml-services-ml-api-0
namespace: istio-system
spec:
phase: AUTHN
pluginConfig:
basic_auth_rules:
- credentials:
- username:password
hosts:
- ml.example.com
prefix: /
request_methods:
- GET
- PUT
- POST
- باتش
- حذف
محدد:
تطابق التسميات:
istio: tfy-istio-ingress
عنوان URL: oci://ghcr.io/istio-ecosystem/wasm-extensions/basic_auth:1.12.0
بمجرد تطبيق المواصفات المذكورة أعلاه على المجموعة، سيطلب التطبيق اسم المستخدم وكلمة المرور عند فتحه في المتصفح.
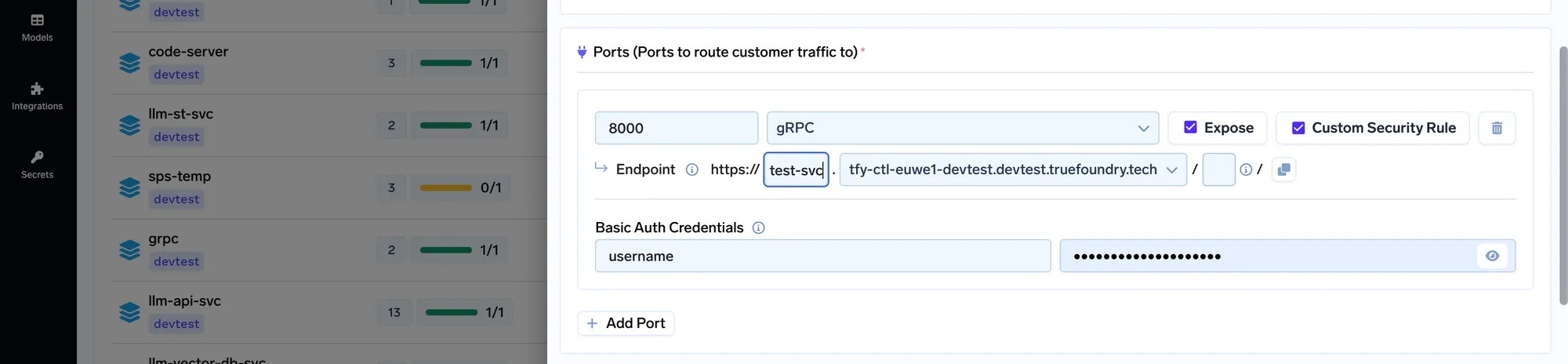
لجعل العملية المذكورة أعلاه أسهل بكثير، قررنا أن نجعله سهلاً للغاية على الـ Truefoundry منصة.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








أحدث الأخبار والمقالات والموارد تصلك مباشرة إلى بريدك الوارد
© 2026 جميع الحقوق محفوظة.











.png)
.webp)










.webp)
