






November 5, 2025
|
5 min read


احصل على وصول فوري إلى بيئة TrueFoundry مباشرة. انشر النماذج، ووجّه حركة مرور LLM، واستكشف المنصة بالكامل — بيئة الاختبار الخاصة بك جاهزة في ثوانٍ، ولا يلزم وجود بطاقة ائتمان.









Published: July 4, 2026

Blazingly fast way to build, track and deploy your models!
يُعتبر Kubernetes على نطاق واسع المنصة المثالية للفرق في المؤسسات الكبيرة والمتوسطة التي تتطلب توفرًا عاليًا وقابلية للتوسع التلقائي. ومع ذلك، فقد أضاف أيضًا تعقيدًا إلى سير عمل المطورين الحالي. يمكن فهم هذا التغيير كجزء من توجه أوسع نحو تبني نموذج الخدمات المصغرة (micro-service) والتعقيد المتزايد في كيفية تشغيل البرمجيات. في هذه المقالة، سنبحث كيف تطورت مشكلة تطوير البرمجيات مع هذا التحول النموذجي.
لنبدأ بمفهوم حلقة التطوير ودورها في سير عمل التطوير. تتكون حلقة التطوير لأي مشروع برمجي من حلقتين منفصلتين تتقاطعان عبر Git.
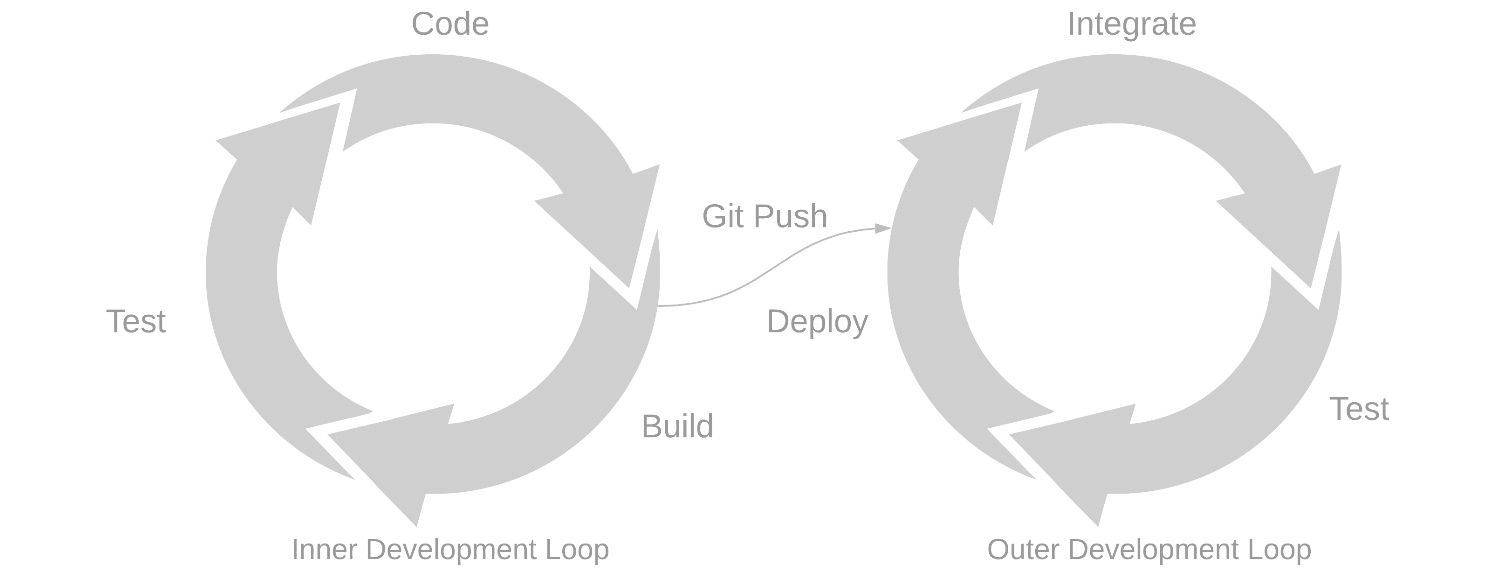
وهي كالتالي:
تتغذى هذه الحلقات على بعضها البعض وتشكل دورة حياة كاملة لتطوير البرمجيات.
لقد أدى ظهور الخدمات المصغرة إلى مكونات برمجية صغيرة ومستقلة وغير مترابطة بإحكام، والتي توفر قابلية أفضل للتوسع والموثوقية. لن نناقش المزايا هنا نظرًا لكونها معروفة على نطاق واسع، ولكن مخاوفنا تنبع من التعقيد التشغيلي المتزايد الناتج عنها.
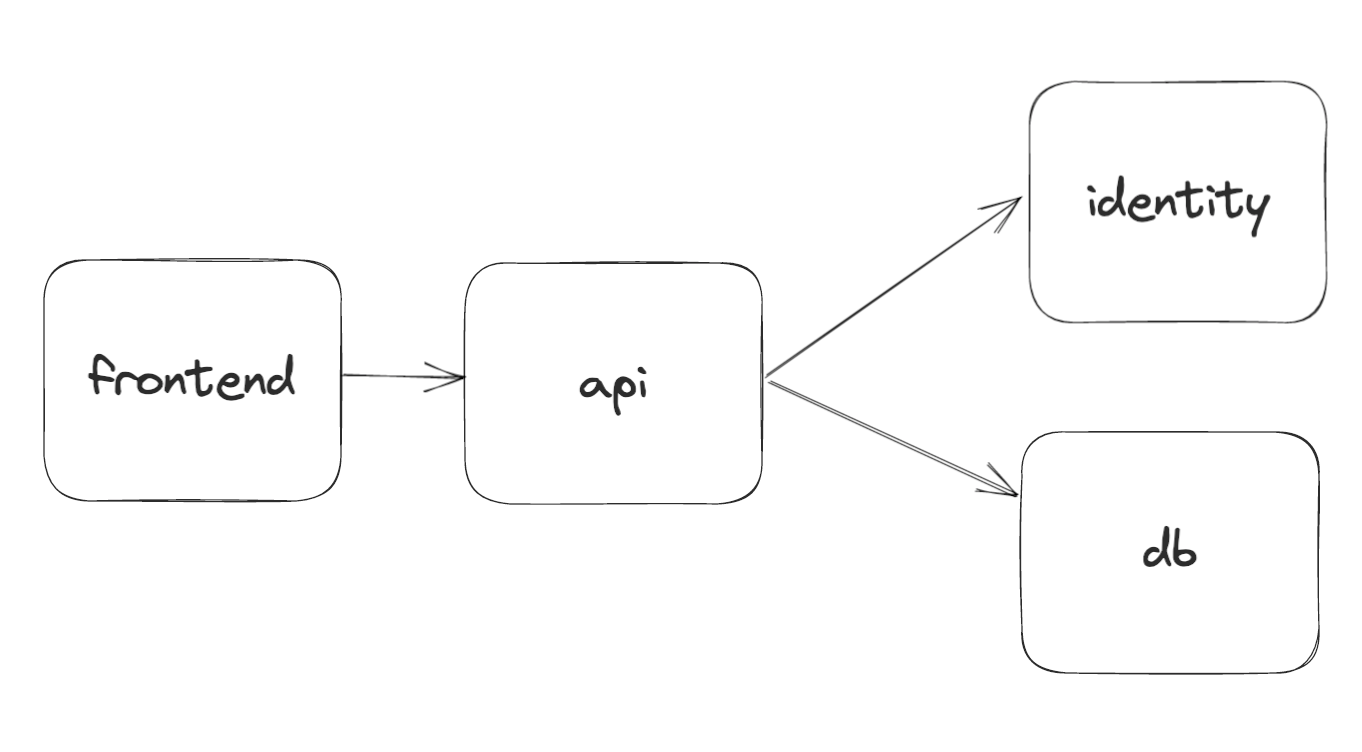
لننفترض إعدادًا بسيطًا حيث يقوم الـ الواجهة الأمامية باستدعاء الـ واجهة برمجة التطبيقات (API)، والتي بدورها تتواصل مع خدمتين أخريين تُسميان الهوية و db. في هذا السيناريو، يعمل مطورنا على api ، والتي تحتوي على تبعيات هابطة (الواجهة الأمامية) وصاعدة (الهوية، db). دعنا نستكشف كيف تتغير عملية التطوير لخدمة api في حلقتي التطوير المختلفتين -
api تحتاج الخدمة إلى التواصل مع خدمتي الهوية وdb لتعمل بنجاح.api متوافقة مع تبعياتها الهابطة، من المهم أيضًا إعادة توجيه الطلبات الهابطة إلى هذه الخدمة.api ، يجب أن يكون هناك وصول إلى نسخة عاملة من identity و db خدماتالواجهة الأمامية بالوصول إلى هذه الخدمة لأغراض الاختبار.واجهة برمجة التطبيقات (API) الخدمة بحيث يمكن اختبارها مباشرةمشكلة حلقة التطوير الداخلية هي شيء Telepresence من Ambassador Labs قد حلته. لقد حاولنا حل مشكلة حلقة التطوير الخارجية على منصة TrueFoundry من خلال Intercepts.
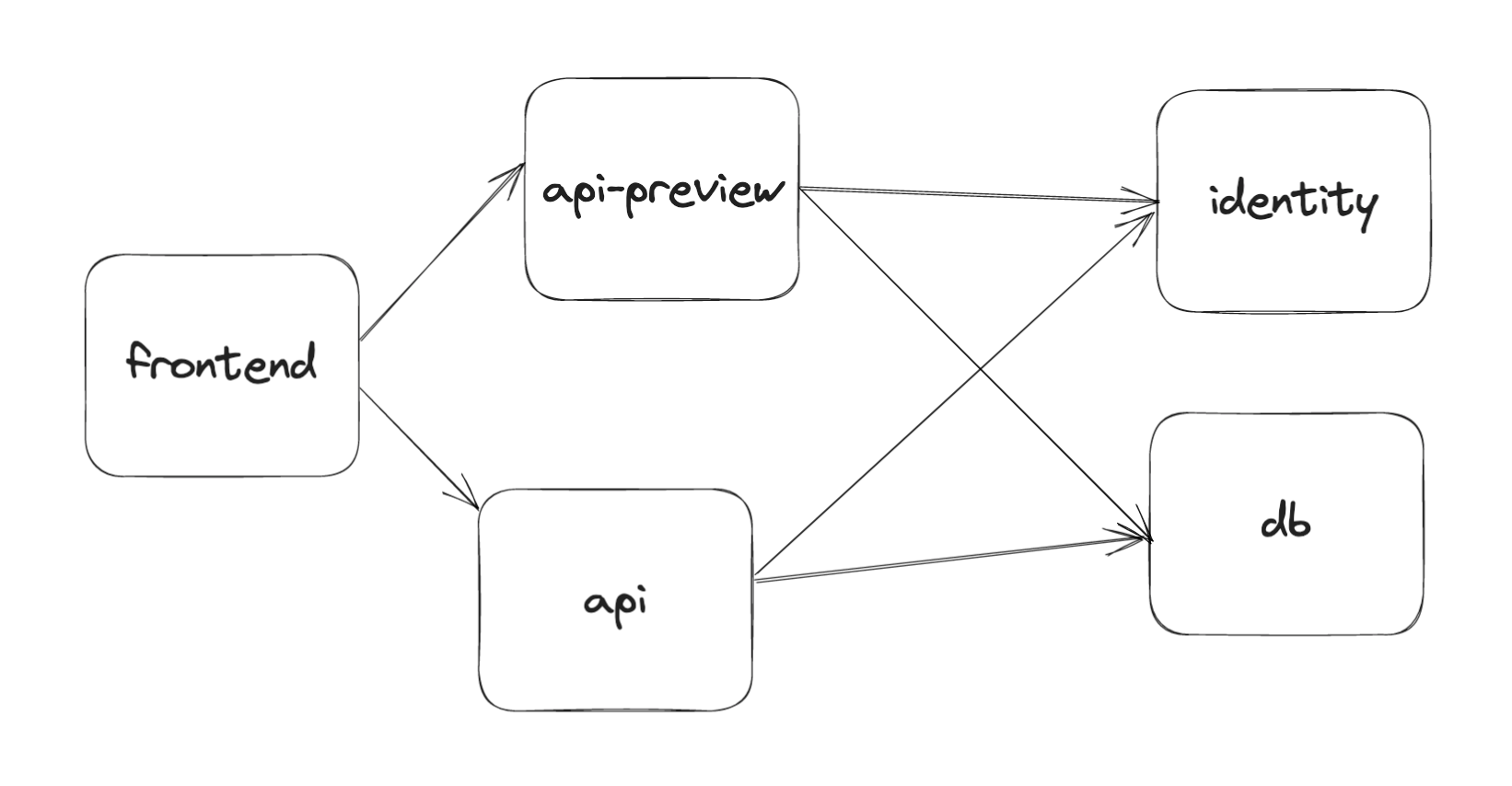
يعمل مفهوم TrueFoundry Intercepts على حل مشاكل حلقة التطوير الخارجية الثلاث الموضحة في الأقسام السابقة. نتبع الاستراتيجية التالية لمعالجة ذلك -
API خدمة تعيد التوجيه إلى نسخة تجريبية بناءً على رأس يتم تمريره إليها. هذا يعني الواجهة الأمامية يمكنها الاستمرار في العمل بنفس عنوان URL بمجرد تمرير رأس إضافي أثناء الاختبار.💡
لقراءة المزيد حول اعتراضات TrueFoundry، يرجى الرجوع إلى وثائقنا - https://docs.truefoundry.com/docs/intercepts
لقد ناقشنا التغييرات في سير العمل التطويري التي أحدثها ظهور الخدمات المصغرة (microservices) وكيف نحاول معالجتها. لا يزال هذا سؤالاً مفتوحاً، ويمكننا أن نتوقع المزيد من الحلول المبتكرة في هذا المجال مستقبلاً.
إذا كنت تتطلع إلى زيادة العوائد من مشاريع نماذج اللغة الكبيرة (LLM) الخاصة بك وتمكين عملك من الاستفادة من الذكاء الاصطناعي بالطريقة الصحيحة، يسعدنا التحدث وتبادل الأفكار.
تعرف على كيف يساعدك TrueFoundry في نشر نماذج اللغة الكبيرة (LLMs) في 5 دقائق:
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








أحدث الأخبار والمقالات والموارد تصلك مباشرة إلى بريدك الوارد
© 2026 جميع الحقوق محفوظة.











.png)
.webp)










.webp)
