




July 4, 2026
|
5 min read


احصل على وصول فوري إلى بيئة TrueFoundry مباشرة. انشر النماذج، ووجّه حركة مرور LLM، واستكشف المنصة بالكامل — بيئة الاختبار الخاصة بك جاهزة في ثوانٍ، ولا يلزم وجود بطاقة ائتمان.









Published: July 4, 2026

Blazingly fast way to build, track and deploy your models!
Healthcare, financial, and a few other sectors are deploying generative AI without ever touching the public internet. Air-gapped is not a configuration flag — it is an architecture where every dependency the system needs at runtime is already inside the enclave.
"Air-gapped" is not a marketing claim about the deployment shape. It is the deployment shape's foundational constraint. Everything else follows from "no route to the outside."
In a typical enterprise deployment, "isolated" means a private VPC, a NAT gateway, restricted egress, and an allowlist of approved external endpoints — package registries, model APIs, telemetry endpoints, identity providers. The system is segregated; it is not isolated. Egress exists, controlled but present. An auditor asking "what does the system phone home to?" gets a list of allowlisted destinations, not silence.
Air-gapped is a stronger claim. There is no NAT gateway. There is no DNS server that resolves external hostnames. There is no certificate authority chain that trusts anything outside the enclave. There is — depending on the regime — either no network connection to the outside at all, or only a one-way data diode for telemetry export. Code, data, and dependencies enter via signed physical media; nothing enters by network. The auditor asking the same question gets a definitive answer: nothing leaves, nothing enters, except on the controlled cadence the deployment was certified against.
This is the deployment posture for classified defense workloads (typical accreditation frameworks: DoD IL5 and IL6, FedRAMP High, sometimes CMMC Level 2 or Level 3 for the defense industrial base), for healthcare systems handling controlled clinical data (HIPAA with HITRUST CSF attestation, sometimes additional state-level requirements), for financial systems under stricter regulatory regimes (FFIEC and SR 11-7 for bank model risk, NYDFS Part 500 for cyber), and for industrial control environments where any outbound traffic is forbidden by policy. The distinction matters legally, not just operationally: an "isolated" deployment may still constitute a data transfer to a vendor under some regulatory frameworks; an air-gapped deployment, by construction, cannot.
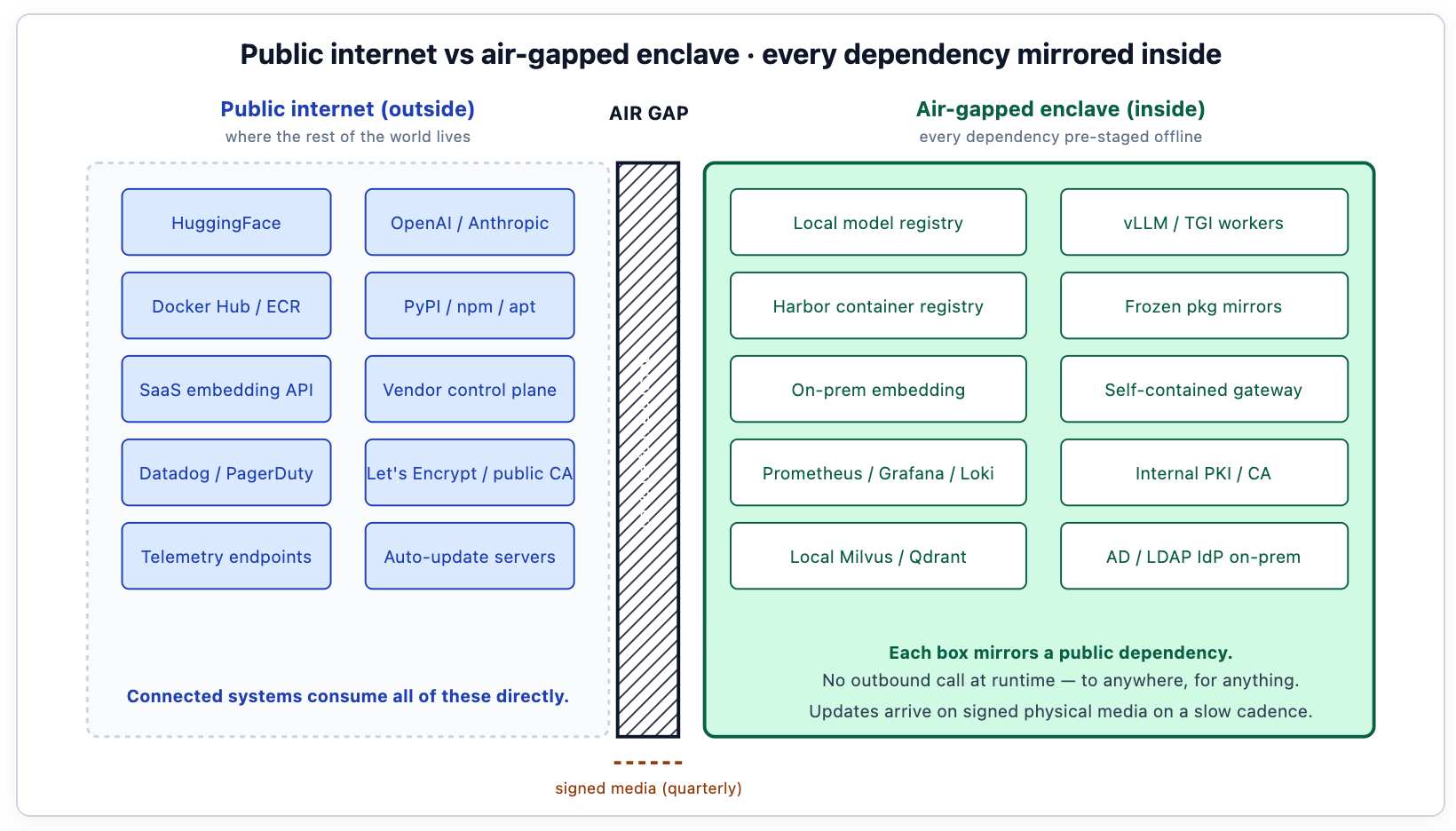
The diagram is the architecture. Every component that an internet-connected deployment would consume from somewhere external has to have a mirror inside the enclave. The mirror exists; the consumption is local. The integrity of the deployment depends on every byte of every dependency being accountable — versioned, signed, scanned, and frozen at staging time. The right side of the diagram is what a Helm-based install of an AI platform like TrueFoundry populates inside the enclave: the gateway data plane, the model registry, the serving workers, the vector store, the observability stack, the policy engine — all wired to the customer's on-prem IdP, internal CA, and SIEM via Helm values rather than vendor endpoints.
Model weights are imported once via signed package, SHA-256 verified against the published hash from the model author, and then sealed inside the enclave. Subsequent inference workers pull from the local registry, never from HuggingFace. Updates follow the same path: a new model version arrives on physical media, gets signature-verified, and is staged into the registry under a new version label.
This sounds onerous for teams used to pip install, and it is. The reason it is worth it is that the integrity of the deployment depends on every byte of every weight being accountable. The signed-import process is the audit trail. When the auditor asks "where did this model come from, and how do you know it hasn't been tampered with?", the deployment answers with a chain of signatures: the model author signed the release, the security team verified the signature on import, the registry recorded the version under a custodial process. That chain is what makes the model usable in a regulated context.
The registry's metadata schema matters as much as the storage. Each model version is recorded with its source, its hash, its import date, its responsible engineer, and the eval results that qualified it for production. This is the same versioned-artefact discipline the team applies to code, applied to model weights. On TrueFoundry the Model Registry holds these fields as first-class metadata, so the auditor's question has a structured answer in the platform itself rather than living in a spreadsheet owned by one person. Teams that treat models as ad-hoc files struggle in audits; teams that treat them as code-class artefacts have the answers ready.
Token generation happens entirely inside the enclave, on the customer's H100, A100, or MI300 cluster (or whatever the regime allows; some classified environments restrict hardware choice as part of supply-chain controls). No provider API call ever leaves the boundary. The serving stack is the same vLLM, TGI, or SGLang the rest of the world uses; what changes is that it runs in an environment where it cannot phone home for telemetry, model auto-updates, or external embedding services.
The serving engines themselves usually need patches for air-gapped operation. vLLM by default checks HuggingFace for tokenizer files if they aren't pre-staged; that check must be disabled, or the tokenizer must be on the local registry path. Some engines reach for telemetry servers on startup; those calls must be stubbed out or pointed at a local sink. The patching is one-time work but it matters: teams that skip it discover the failure modes at runtime, when a worker pod refuses to start because it can't reach the internet for a metadata check. TrueFoundry's serving stack ships with these air-gapped patches in place — tokenizer sources point at local registry paths, telemetry endpoints point at the on-prem observability stack, and auto-update is off by default in the air-gapped Helm values. The same vLLM, TGI, and SGLang backends that teams use in connected deployments run in the enclave; the difference is which values file the deployment loads.
RAG over classified documents requires that the embedding model also runs inside the enclave. Sending text to a remote embedding API, even one provided by a major cloud, is the move that breaks the air gap most often in practice. Teams discover the leak when network monitoring shows DNS queries to api.openai.com originating from the supposedly air-gapped retrieval pipeline; the embedding step was using an SDK that defaulted to the cloud provider.
The deployment uses an on-prem embedding model — typically a smaller open-source model that's fast on CPU or runs efficiently on the same GPUs as the serving workers. Common choices: a 384- or 768-dimensional embedding model like bge-small, nomic-embed, or a domain-tuned variant for specialised content. The vector index is encrypted at rest with customer-managed keys, accessed only from inside the enclave, and backed up to the same media regime the rest of the deployment uses.
The vector store choice — Milvus, Qdrant, pgvector — matters less than the deployment hygiene around it. The store needs the same versioned-artefact treatment as the model registry: the corpus snapshots are recorded, the embedding model version is recorded, the index build process is reproducible. When the corpus changes, the re-embedding job runs on a controlled cadence and the auditor can trace any retrieval result back to a specific corpus snapshot. TrueFoundry's deployment manifest pins the on-prem embedding model and the vector store as part of the same Helm install, so the team isn't sourcing them separately at staging time — the choice of embedding model and vector backend is a values-file knob; the air-gap posture is not.
TrueFoundry's AI Gateway, in air-gapped deployments, runs as a containerized workload deployed via Helm into the customer's Kubernetes cluster inside the enclave. There are no outbound network dependencies for any of its runtime operations: identity comes from the local IdP (typically Active Directory or LDAP, sometimes a customer-operated SAML provider), policy lives on local disk under version control, audit logs go to the local SIEM (Splunk on-prem in most defense deployments, sometimes a customer-built equivalent). There is no telemetry to a vendor control plane; aggregate health metrics, if exported at all, go through a one-way data diode to a separately accredited monitoring environment.
The gateway's feature set is the same in air-gapped as in connected deployments. The same tokens-per-hour rate limiting per project, team, or workflow. The same per-project budget enforcement with hard caps that block new requests when a budget is reached. The same priority-based fallback routing across local model targets. The same input and output guardrails — PII / PHI redaction on inputs before the model sees them, secrets detection on outputs before they reach the client, prompt-injection detection for agent-shaped workloads. The features run; they emit their telemetry to the on-prem stack rather than to a vendor's observability cloud. The configuration that drives them is the same YAML.
This matters in practice because a platform team that operates a connected dev environment and an air-gapped production environment isn't operating two platforms — they're operating one platform with two values files. The gateway image is the same; the chart is the same; the API surface is the same. The engineering investment in the gateway pays off across every deployment shape simultaneously.
Every container image the deployment uses has to come from somewhere. In a connected environment, that somewhere is Docker Hub or ECR. Inside the enclave, it is a local Harbor or equivalent registry, populated at staging time from external mirrors and then frozen. The same is true for PyPI, npm, apt, and any other language package manager the system depends on. Snapshots get scanned for vulnerabilities at staging, then pinned.
The discipline is that nothing the system needs at runtime can be a moving target. The world outside changes; the inside of the enclave does not, except on a controlled cadence. A CVE published yesterday in a Python dependency does not automatically propagate into the enclave; it propagates on the next scheduled update, after the security team has reviewed it. This is sometimes uncomfortable for teams used to apt-get upgrade; it is the trade the deployment posture requires.
TrueFoundry's air-gapped install workflow publishes all container images and Helm charts to an OCI-compatible registry under the customer's control. The customer either replicates from TrueFoundry's upstream registry (tfy.jfrog.io/tfy-images for the container images, tfy.jfrog.io/tfy-helm for the Helm charts) at staging time, or works from the customer's existing Harbor or Artifactory if the customer's release-engineering team already owns the upstream-mirror discipline. The container registry's catalogue becomes the dependency inventory — when an auditor asks "what software is running in this enclave?", the answer is the registry's manifest. Teams that don't keep their registry tidy fail this question; teams that treat the registry as a curated, accountable inventory pass it.
Prometheus, Grafana, and Loki cover most metrics, dashboards, and logs. All on-prem. Dashboards export to a local SOC console, not to a SaaS vendor. Alert routing goes through internal email or Slack-on-prem equivalents, not Twilio or PagerDuty. The observability stack itself is one of the larger workloads inside the enclave; it's not unusual for the monitoring infrastructure to consume more compute than the AI workloads it monitors during quiet periods.
TrueFoundry's gateway is OpenTelemetry-native; in air-gapped deployments, the OTEL pipeline emits to the local Prometheus and Loki rather than to a vendor's observability cloud. Same instrumentation, same trace schema, different destination. Per-request observability includes the identity, the workload tag, the resolved model, the policy decisions applied, the guardrail verdicts, and the trace ID — everything the audit needs to reconstruct who asked what, of which model, under which policy, and how the gateway responded. Audit log retention is configurable for the long retention periods (seven years is common in defense and regulated-finance environments) that audit regimes require.
The alert routing is the place where most teams discover their on-prem assumptions are wrong. Sending an SMS via Twilio when the gateway saturates is the right behaviour in a connected deployment and a violation of the air gap in an enclaved one. The team's incident response runbook needs to be rewritten for the enclave: the on-call gets the alert via internal channels, the SOC gets a parallel notification through internal escalation, the external vendor support escalation (if any) happens through a different, accredited channel.
Public CAs (Let's Encrypt, DigiCert) are not reachable. The deployment uses the customer's internal PKI, with trust anchors loaded at install time. mTLS between gateway and workers, between gateway and IdP, between every internal service: all verified against the internal CA. This sounds like a footnote; it is the reason most "isolated" deployments are actually not air-gapped, because somebody left certbot reaching for a public endpoint to renew a certificate.
The internal CA is the customer's responsibility, not the platform's. The platform consumes the CA's trust anchors at install time — for TrueFoundry, via Helm values that point at the trust-anchor file mounted into the gateway pods. The customer's PKI team runs the CA, issues certificates, and rotates them. The certificate lifecycle is one of the operational loads the customer's PKI team needs to plan for. Short-lived certificates (90-day or shorter) are best practice but require automation that the team needs to provision before the deployment goes live.
Updates are the operational reality that distinguishes air-gapped from theoretically air-gapped. The model gets better; the gateway gets new features; vLLM ships a critical fix. None of these can be applied via git pull.
The discipline is a signed bundle workflow. The vendor publishes a release as a signed tarball — manifests, container images, Helm chart, and (if applicable) weight artifacts, with an integrity hash. The bundle is loaded onto physical media (typically a USB stick or removable hard drive, depending on the regime's media policy), walked across the air gap, and staged on a holding server inside the enclave. Integrity is verified, signatures are checked against pre-loaded vendor public keys, and the bundle is installed under a new version label. The previous version remains available for rollback for a configurable window — typically 30 days — so that a problematic update can be reverted without another bundle import cycle.
TrueFoundry's air-gapped releases ship in exactly this shape: signed bundles containing the chart, the manifests, the gateway and worker images, and the integrity hashes. Verification happens against pre-loaded TrueFoundry public keys; the bundle is staged in the customer's registry under a new version label; rollback is a Helm rollback to the previous chart revision. The customer's accreditation review applies to the bundle, not to a continuous stream of changes — every update is a discrete accreditation event with a clear before-and-after, which is the property the bundle workflow exists to provide.
Cadence depends on the regime. Some defense environments accept quarterly updates; some healthcare environments allow monthly. Some environments accept nothing without a separate accreditation review per release — every bundle is a fresh accreditation event. The platform has to support all of these without changing shape; the configuration of "how often we update" is the customer's, not the vendor's.

The four tiers represent a continuum of trust between the deployment and the outside world. The connected tier (most workloads, most enterprises) accepts vendor connectivity as a routine part of operation. The BYOC tier accepts vendor connectivity for the control plane but not for data — payloads stay inside the customer's cloud account. The air-gapped + diode tier accepts only one-way export, typically for SOC monitoring of aggregate health metrics. The fully air-gapped tier accepts no network connectivity of any kind. Most classified defense work runs in the bottom two tiers; most healthcare and finance work runs in BYOC; most general enterprise work runs in connected.
TrueFoundry supports all four tiers from the same codebase — the same gateway image, the same Helm chart, the same configuration schema. The Helm values change between tiers; the gateway primitives do not. The control plane and the gateway data plane are deployable independently, which is what makes this work: in connected SaaS, both planes run in TrueFoundry's environment; in BYOC, the control plane is SaaS and the data plane runs in the customer's VPC; in air-gapped, both planes run inside the customer's enclave. A platform team that runs SaaS in dev and air-gapped in classified production doesn't operate two platforms — it operates one platform configured differently. Engineering investment in the gateway pays off across every deployment shape simultaneously.
Most "air-gapped" deployments that fail their first audit fail not because the architecture was wrong but because a specific dependency leaked the gap. Five patterns recur across teams' first attempts; knowing them in advance is what produces deployments that pass review.
Default SDK telemetry. Cloud-provider SDKs (boto3, google-cloud, azure-sdk) routinely emit telemetry to vendor endpoints on initialisation. The application code looks innocent — it imports a library, instantiates a client — and the library calls home before the team's code does anything. The fix is auditing every dependency's network behaviour at staging time, disabling telemetry through configuration where the SDK supports it, and patching where it doesn't. Egress monitoring during staging is what surfaces these calls before production.
Tokenizer auto-download. Many ML libraries default to downloading tokenizer files from HuggingFace on first use. The serving engine that loaded the model successfully fails three weeks later when a worker pod restarts and the cached tokenizer is gone. The fix is pre-staging tokenisers in the local registry and pointing the engine at the local path through configuration, not relying on its default download behaviour.
Container image pulls at runtime. توزيع Kubernetes الذي يشير إلى image: vllm/vllm:latest بدلاً من image: harbor.internal.example.mil/vllm/vllm:v0.6.3 سيفشل عند التشغيل في بيئة معزولة هوائياً. الحل هو سياسة مرآة السجل: كل مرجع صورة في كل بيان يشير إلى Harbor المحلي؛ لا يوجد بيان يشير إلى سجل خارجي، إطلاقاً. يمكن لوحدات التحكم بالقبول فرض ذلك وقت النشر.
تجديد الشهادة يتصل بالخارج. تم تثبيت التوزيع بشهادات داخلية؛ أتمتة التجديد تستخدم افتراضياً Let's Encrypt أو سلطة تصديق عامة مماثلة. بعد ثلاثة أشهر، يتم تشغيل مهمة التجديد وتفشل — أو الأسوأ من ذلك، تنجح في الوصول إلى نقطة النهاية العامة، مما يخل بوضع التدقيق. الحل هو ربط تجديد الشهادة بالبنية التحتية للمفاتيح العامة (PKI) الداخلية للعميل من اليوم الأول، وليس كفكرة لاحقة.
NTP و DNS عبر الشبكة. مزامنة الوقت تستخدم افتراضياً مجمعات NTP العامة؛ حل DNS يستخدم افتراضياً خوادم عامة. شبكة التوزيع "معزولة" ولكن بطريقة ما لا تزال حاويات العمل تتصل بـ pool.ntp.org. الحل هو البنية التحتية الداخلية للعميل لـ NTP و DNS، تم تكوينها على مستوى المجموعة بحيث لا يمكن لأي حاوية أن تتصل بالخارج عن طريق الخطأ حتى لو لم يكن رمز تطبيقها يقصد ذلك.
النمط الشائع: الفشل يكمن في طبقة المنصة أسفل عبء عمل الذكاء الاصطناعي، وليس في عبء عمل الذكاء الاصطناعي نفسه. يكتب الفريق خط أنابيب RAG الخاص بهم بشكل صحيح، ولكن تبعية عابرة تتصل بالخارج. الدفاع هو مراقبة الخروج المرحلية — تشغيل التوزيع في بيئة اختبار (sandbox) متصلة مع تسجيل كامل لحركة الخروج، والتعامل مع أي اتصال صادر غير متوقع كـ "اكتشاف"، والمضي قدماً في التثبيت المعزول هوائياً فقط بعد أن تكون بيئة الاختبار نظيفة. بيئة TrueFoundry المرحلية ذات الوضع المتصل موجودة لهذا الغرض تحديداً: نفس صورة البوابة ونفس مخطط Helm التي ستعمل في البيئة المعزولة يتم تشغيلها أولاً في بيئة اختبار حيث يمكن ملاحظة كل اتصال صادر، بحيث تظهر أنماط الفشل قبل أن تصل إلى بيئة منظمة. يتم ضمان سلامة التوزيع المعزول هوائياً إلى حد كبير في مرحلة التحضير.
عمليات الطرح المعزولة هوائياً أبطأ من عمليات طرح BYOC، والتي هي أبطأ من عمليات تبني SaaS. التسلسل أدناه هو الخطة النموذجية متعددة الأشهر؛ التسرع في ذلك ينتج عنه عمليات نشر تفشل في مراجعة الاعتماد.
الشهران 1-2 — مشاركة الاعتماد. يراجع فريق أمن العميل وسلطة الاعتماد وثائق المنصة، وجرد البيانات، وسير عمل التحديث، والوضع التشفيري. الناتج هو حزمة اعتماد تحدد بدقة كيف سيبدو التوزيع وما هي الضوابط التي تنطبق عليه. هذا هو العنصر الذي سيتم قياس التوزيع بناءً عليه لاحقاً؛ إنجازه بشكل صحيح يوفر أسابيع من المعالجة. يشارك فريق هندسة التوزيع في TrueFoundry عادةً في هذه المرحلة، بتوفير وثائق الهندسة المعمارية، والوضع التشفيري FIPS 140-3 (حيث يعمل التوزيع داخل AWS GovCloud or Azure Government)، وعملية توقيع الحزمة التي ستراجعها سلطة الاعتماد.
الشهران 3-4 — بيئة التحضير. يقوم العميل ببناء بيئة تحضير معزولة تعكس بنية الإنتاج ولكن لا تحتوي على بيانات سرية. يتم تثبيت المنصة عبر Helm مقابل مرآة السجل المحلية؛ يتم توصيل التكاملات (IdP، SIEM، سلطة التصديق الداخلية، المراقبة المحلية)؛ يتم اختبار سير عمل التحديث باستخدام حزمة موقعة نموذجية. يعمل التوزيع المرحلي لمدة شهر واحد على الأقل تحت حمل محاكى، مع تمكين تسجيل كامل لحركة الخروج بحيث تظهر أي اتصالات صادرة غير متوقعة كـ "اكتشاف" قبل الإنتاج.
الأشهر 5-6 — تثبيت الإنتاج والاعتماد. يتم تثبيت المنصة في بيئة الإنتاج المعزولة. تجري سلطة الاعتماد المراجعة الرسمية مقابل الحزمة المتفق عليها مسبقًا. يتم معالجة النتائج؛ ويتم اعتماد النشر بموجب إطار التفويض المناسب (DoD IL5/IL6 للدفاع المصنف، FedRAMP High للقطاع المدني الفيدرالي، أطر عمل خاصة بالقطاع للرعاية الصحية والمالية).
الأشهر 7+ — التشغيل في الحالة المستقرة. تخدم المنصة أعباء العمل الخاضعة للتنظيم. يتم تشغيل سير عمل التحديث بوتيرته المعتمدة (ربع سنوية، شهرية، أو حسب حدث الاعتماد). يتولى فريق أمان العميل مسؤولية وضع الامتثال التشغيلي؛ ويتولى فريق SRE الخاص بالعميل العمليات اليومية. تتراجع TrueFoundry إلى قناة التصعيد المعتمدة لدعم الحوادث ووتيرة الإصدارات ربع السنوية — فالنشر يخص العميل، وليس البائع، في هذه المرحلة.
العزل الهوائي ليس هو نفسه مجرد التشغيل المحلي. فالتثبيت المحلي النموذجي لا يزال يتصل بمديري الحزم، ويسحب صور الحاويات من سجلات خارجية، ويرسل بيانات القياس عن بعد إلى بائع مراقبة SaaS. يعيش هذا التثبيت في مركز بيانات المؤسسة. إنه ليس معزولًا هوائيًا. يتم الخلط بين الاثنين بشكل روتيني، وهذا الخلط هو بالضبط ما يبحث عنه المنظمون أثناء عمليات التدقيق.
كما أنه ليس بدون تكلفة تشغيلية. فصيانة السجلات المعكوسة، وتشغيل بنية تحتية للمفاتيح العامة (PKI) داخلية، وهندسة الإصدارات وفق وتيرة ربع سنوية — كلها أعباء هندسية حقيقية لا توجد في التثبيتات المتصلة. الفرق التي تدير الأنظمة المعزولة هوائيًا تعرف ذلك؛ أما الفرق التي على وشك أن ترث واحدًا فعادة لا تعرف، والفجوة بين الاثنين هي مصدر معظم التثبيتات الفاشلة. غالبًا ما تقلل مراجعات المشتريات للمنصات المعزولة هوائيًا من تقدير العبء التشغيلي المستمر للعميل بمقدار ضعفين أو ثلاثة أضعاف.
وهو ليس بديلاً لممارسات الامتثال. فالهندسة المعمارية تزيل المخاطر الناشئة عن الشبكة؛ لكنها لا تزيل المخاطر الناشئة عن العنصر البشري. لا يزال التهديد الداخلي، وسوء التكوين، وانتهاك السياسة، والخطأ التشغيلي مخاطر يجب على فريق أمان العميل إدارتها. العزل الهوائي هو تحكم مادي قوي؛ لكنه ليس بديلاً عن بقية وضع الدفاع متعدد الطبقات.
وهو ليس الحل المناسب لكل فريق. فالمؤسسات التي لا تتطلب أعباء عملها فعليًا وضع عزل هوائي تدفع التكلفة التشغيلية دون الحصول على الفائدة التنظيمية؛ وبالنسبة لأعباء العمل هذه، يوفر BYOC معظم فائدة سيادة البيانات بجزء بسيط من التكلفة التشغيلية، والطبقة المتصلة لا تزال أسهل بكثير. أما المؤسسات التي قامت بالفعل ببناء منصات عزل هوائي ناضجة ذات سجل اعتماد خاص بها فتواجه تكلفة ترحيل في بيئة معتمدة قد يكون من الصعب تبريرها. العزل الهوائي هو شكل النشر لأعباء العمل التي يتطلب فيها النظام التنظيمي عدم وجود اتصال خارجي؛ أما بالنسبة لكل شيء آخر، فالطبقات الأبسط موجودة لسبب.
مهمة المنصة هي جعل العبء التشغيلي قابلاً للإدارة، وليس التظاهر بأنه غير موجود.
يوفر العميل سجلًا متوافقًا مع OCI داخل البيئة المعزولة (عادةً Harbor، وأحيانًا JFrog Artifactory أو المكافئ السحابي). يقوم فريق هندسة الإصدارات بعكس صور حاويات TrueFoundry ومخططات Helm — على سبيل المثال، المستمدة من tfy.jfrog.io/tfy-images و tfy.jfrog.io/tfy-helm — إلى السجل، إما عن طريق النسخ المتماثل المباشر من بيئة ترحيل متصلة أو عبر حزمة موقعة يتم نقلها عبر العزل الهوائي على وسائط مادية. ثم يتم تشغيل تثبيت Helm مقابل السجل المحلي، وبيانات صور الحاويات المحلية، ومجموعة Kubernetes الخاصة بالعميل. تشير قيم Helm إلى IdP العميل، وCA الداخلية، وSIEM، ومكدس المراقبة. يتم تثبيت نفس المخطط الذي يتم تثبيته في بيئة تطوير متصلة في بيئة الإنتاج المعزولة هوائيًا؛ يختلف ملف القيم فقط.
من خلال سير عمل الحزمة الموقعة. ينشر مؤلف النموذج إصدارًا؛ ويقوم فريق هندسة الإصدارات لدى العميل باستيراده وفق الوتيرة المعتمدة (ربع سنوية، شهرية، أو لكل حدث اعتماد). يتم التحقق من توقيع الحزمة، وتجهيزها في السجل المحلي، ونشرها إلى مجموعة فرعية تجريبية (canary)، ثم ترقيتها إلى الإنتاج بعد المراقبة. يظل الإصدار السابق متاحًا للاستعادة ضمن نافذة قابلة للتكوين.
لا — النماذج الحدودية المستضافة تعيش خارج البيئة المعزولة بحكم تعريفها؛ استدعاؤها سيكسر الفجوة الهوائية. تستخدم عمليات النشر المعزولة هوائيًا نماذج مفتوحة المصدر مستضافة ذاتيًا (Llama, Mistral, Qwen, Phi-3) على وحدات معالجة الرسوميات المحلية. غالبًا ما تكون الجودة كافية لفئة أعباء العمل (الاستخراج، التلخيص، التصنيف، RAG على المجموعات النصية الداخلية)؛ أعباء العمل التي تتطلب حقًا استدلالًا حدوديًا لا تتناسب عادةً مع وضع العزل الهوائي وتحتاج إلى تصميمها لطبقة أقل تقييدًا.
تحديثات الأمان الحيوية لها مسار خارج النطاق: حزمة طوارئ موقعة، معتمدة بوتيرة أسرع من الوتيرة القياسية، وتُوزع عبر نفس سير عمل الوسائط المادية. يقرر فريق أمان العميل ما إذا كانت ثغرة CVE مؤهلة كحالة طوارئ؛ تدعم عملية إصدار المنصة الوتيرة الأسرع للحالات التي تتطلب ذلك. المقايضة هي أن حزم الطوارئ تتجاوز أجزاء من مراجعة الاعتماد العادية وتتطلب تحققًا لاحقًا.
أكبر مما هو عليه في عملية نشر متصلة لنفس عبء العمل — بمتوسط 2-3 أضعاف تقريبًا. يحتاج العميل إلى عمليات البنية التحتية للمفاتيح العامة (PKI)، وصيانة النسخ المتطابقة، وهندسة الإصدارات، والتنسيق للاعتماد، والتناوب المعتاد لمهندسي موثوقية الموقع (SRE rotation). لعبء عمل واحد، قد يعني هذا 3-5 مهندسين متخصصين؛ أما بالنسبة لعملية نشر تستضيف أعباء عمل متعددة، فإن التكلفة الهامشية لكل عبء عمل تكون أقل لأن البنية التحتية التشغيلية مشتركة.
وحدات معالجة الرسوميات نفسها هي ذاتها؛ ما يتغير هو سلسلة التوريد وسياسة البرامج الثابتة. قد تقيد البيئات المصنفة أجهزة البائعين المقبولة، وتتطلب إصدارات محددة من البرامج الثابتة، وتتطلب إثباتًا موثقًا لأصل سلسلة التوريد. تعمل المنصة على ما تسمح به سياسة الأجهزة الخاصة بالنظام؛ يتولى فريق المشتريات لدى العميل مسؤولية توفير الأجهزة.
بالنسبة لطبقة الصمام، نعم — يمكن تصدير القياس عن بعد بشكل مستمر، ولكن باتجاه واحد فقط. الصمام هو ضمان مادي بعدم إمكانية دخول أي بيانات إلى البيئة المعزولة عبر قناة التصدير. ما يتدفق للخارج هو ما وافق عليه اعتماد العميل: مقاييس مجمعة، قياس عن بعد تشغيلي منظم، وربما بيانات أداء مجهولة الهوية. لا تتدفق حمولات كل طلب إلى الخارج تحت أي ظرف من الظروف.
مطابق لعملية نشر متصلة، ولكن مع كل شيء محلي. المجموعة الذهبية موجودة على التخزين المحلي. تُشغل مهمة الإعادة مقابل أسطول الخدمة المحلي. نموذج التحكيم هو أحد النماذج مفتوحة المصدر المنشورة محليًا. لوحات معلومات التقطيع موجودة في Grafana المحلي. يرتبط التراجع التلقائي بسجل إصدارات المطالبات المحلي. انضباط التقييم هو نفسه؛ تختلف الوجهات فقط.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








أحدث الأخبار والمقالات والموارد تصلك مباشرة إلى بريدك الوارد
© 2026 جميع الحقوق محفوظة.







.png)
.webp)










.webp)
