




July 4, 2026
|
5 min read


احصل على وصول فوري إلى بيئة TrueFoundry مباشرة. انشر النماذج، ووجّه حركة مرور LLM، واستكشف المنصة بالكامل — بيئة الاختبار الخاصة بك جاهزة في ثوانٍ، ولا يلزم وجود بطاقة ائتمان.









Published: July 4, 2026
.webp)
Blazingly fast way to build, track and deploy your models!
TL;DR: An AI agent registry is a centralized catalog of autonomous agents and their capabilities - a "phone book" for AI agents. Enterprises use it for discovery, governance, and reuse across multi-agent systems.
AI systems are becoming more modular and collaborative, with specialized agents designed to handle specific tasks—whether that’s retrieving data, executing workflows, or making autonomous decisions. As these agents multiply within an enterprise or across platforms, managing them efficiently becomes critical. This is where an AI Agent Registry comes in.
AI agents are autonomous programs that can reason, act, and collaborate on tasks. As organizations deploy more specialized agents (e.g. resume-parsing bots, scheduling assistants, analytics agents), teams need a way for these agents to discover each other, share capabilities, and integrate into workflows.
An AI Agent Registry serves as a centralized (or federated) catalog of running agents and their metadata, much like a model registry for ML models. This registry enables capability discovery and orchestration: agents (or humans) query the registry to find the right agent for a task, inspect its abilities, and obtain connection details. In essence, it acts as a “phone book” or AI agent discovery platform for autonomous agents.
For enterprise AI and MLOps teams, an agent registry provides standardization and governance over agent deployments. This is becoming essential for scaling agentic AI in enterprise environments securely. Similar to how TrueFoundry offers a model registry UI, an agent registry gives a single window for browsing, versioning, and controlling agents.
By indexing each agent’s identity, version, and capabilities in a common format (e.g. “agent cards” or JSON schemas), the registry makes it far easier for teams to reuse agents, track what’s deployed, and ensure secure interactions. As a result, it has become a critical enterprise AI registry architecture component for enabling agent interoperability and autonomous agent governance across departments.
An AI Agent Registry provides several essential functions for an agentic ecosystem:
1. Agent Registration: Agents register by submitting a metadata payload to the registry (often via a REST endpoint). This agent card includes fields like agent name, description, version, endpoint URL, and the agent’s declared capabilities or skills.
For example, a FastAPI endpoint might accept a JSON payload and store an AgentCard object in the registry’s database. A simple FastAPI snippet could look like:
@app.post("/agents/register", status_code=201)
def register_agent(registration: AgentRegistration):
agent_card = AgentCard(**registration.dict())
registry.register_agent(agent_card) # store in database or in-memory list
return {"status": "registered", "name": agent_card.name}
This matches the pattern from the A2A protocol examples, where teams “publish their agents’ Agent Cards to this registry, making their capabilities discoverable by other agents”.
2. Discovery and Search: Clients (other agents, orchestration services, or user interfaces) query the registry to find agents by capability, tag, or keyword. For instance, a search API could filter agents whose metadata matches a query. Standardized discovery may use well-known URLs (e.g. fetching an agent’s .well-known/agent.json file) or a central search endpoint (e.g. GET /agents?skill=document-extraction). This enables the platform to function as an “AI agent discovery platform” where tasks can be automatically routed to the right agent.
3. Metadata Management: The registry maintains rich metadata for each agent. Besides name and version, metadata may include authentication credentials, supported interaction protocols (A2A, REST, etc.), data types (text, images, files), and trust credentials. For example, research proposals suggest using “cryptographically verifiable” AgentFacts or PKI certificates to ensure trust. The registry might also track lifecycle information like last heartbeat or health.
4. Health Monitoring & Heartbeats: To keep the registry accurate, agents often send periodic heartbeats. If an agent fails to check in (e.g. within 30 seconds), the registry can mark it stale or remove it. This ensures that only active agents are discoverable and helps with autonomous agent governance by detecting unhealthy or offline agents.
5. Access Control and Governance: A registry enforces who can register or call which agent. Just as not every user should see every AI tool, not every agent should be accessible to all callers. The registry can implement RBAC policies, returning specific Agent Cards based on client permissions. For instance, internal agents may access private endpoints, while external agents see only public capabilities. By centralizing agent endpoints and their ACLs, the platform ensures that agent interactions comply with enterprise security policies.
6. Audit Logging and Observability: Recording each registration, discovery query, or invocation provides an audit trail. Enterprise teams can log when agents are used, by whom, and for what purpose. Registry-driven orchestration (like TrueFoundry’s AI Gateway) can stream LLM tool calls and responses back to a UI. Similarly, agent registries may feed logs and metrics into monitoring tools for observability, helping teams understand usage patterns and debug integration issues. For example, frameworks like Kagent emphasize “metrics, logging, and tracing for all tool calls, giving deeper insights into how your AI agent is interacting with external APIs”. An agent registry can aggregate this data at the platform level.
Together, these functions make an agent registry more than just a database – it is an integration backbone, enabling agents to find and use each other reliably under enterprise governance.
Below is a conceptual architecture of an enterprise AI registry. Autonomous agents register with the central service, which stores their metadata and provides search/discovery APIs. The platform UI or orchestration layer interacts with this registry to find agents.
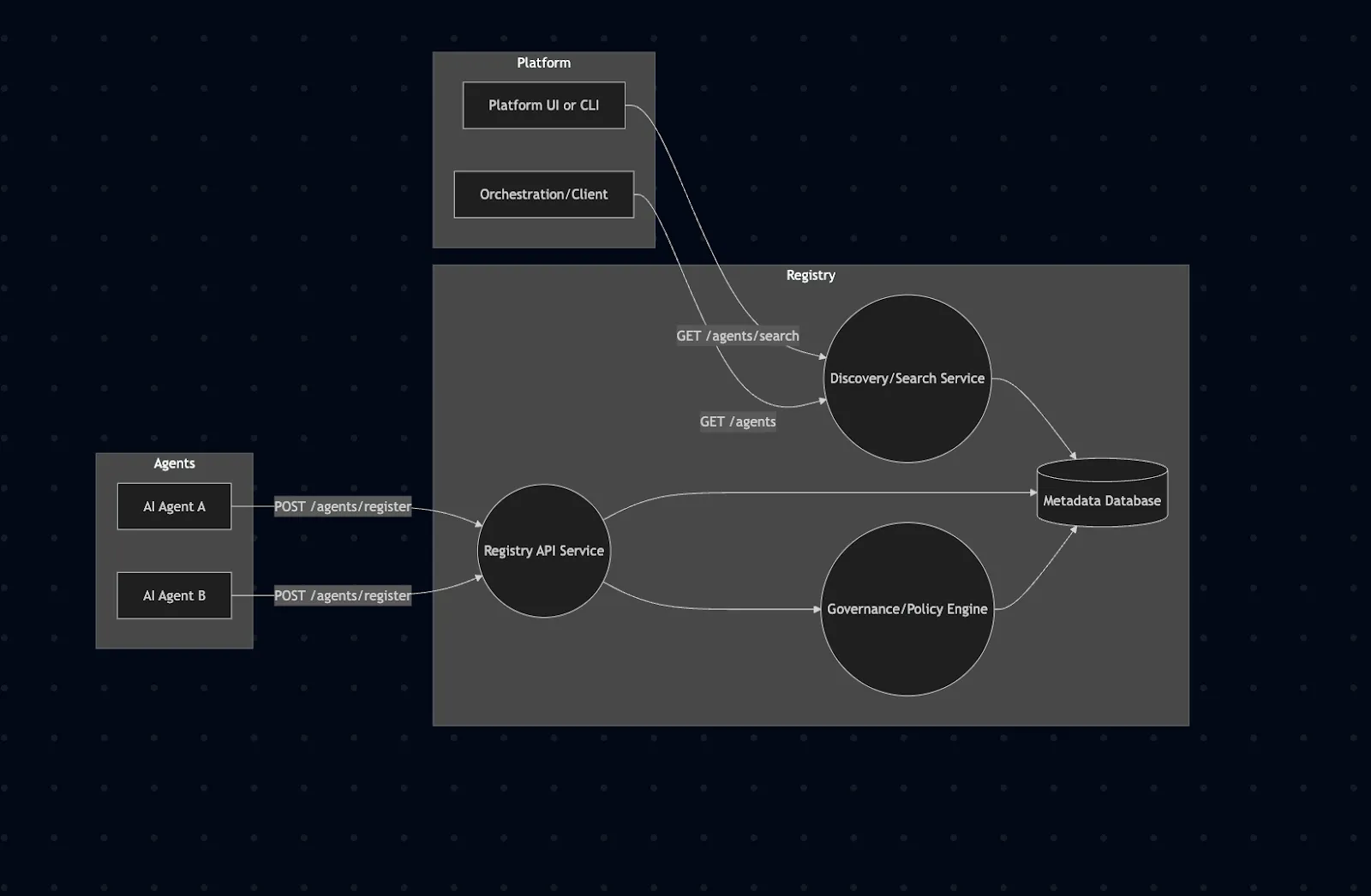
In this enterprise AI registry architecture, agents (A, B) register by calling the Registry API, which stores their AgentCard in the Metadata Database. The Policy/Governance module enforces access controls on registrations and lookups. The Discovery/Search service allows clients and the UI to find agents by querying the DB (for example, full-text search or filtering by capability tags). An administrative UI (like TrueFoundry’s model registry interface) can visualize all registered agents, their versions, and access rules.
Under the hood, one might use a high-performance key-value store or graph database for metadata, and standard web frameworks (e.g. FastAPI) to implement the API. The Agent Name Service (ANS) proposal, for example, suggests a DNS-inspired directory using PKI for identity. TrueFoundry’s AI Gateway similarly centralizes “access to AI development tools” with a registry and OAuth flows for secure token management. Our architecture mirrors these enterprise-grade patterns: a central registry service for discovery, integrated with authentication (OAuth/PKI), an orchestration layer for agent workflows, and a UX layer for visibility.
Several open frameworks and protocols are emerging to make AI agent registries interoperable, standardized, and secure:
from python_a2a.discovery import AgentRegistryregistry = AgentRegistry(name="Enterprise Registry")agents = list(registry.get_all_agents()) # returns registered AgentCardsThis implements the A2A “phone book” design. Agents can also self-register and send heartbeats via the enable_discovery helper.
Together, these frameworks address key aspects of the registry challenge: discovery (A2A, NANDA), interoperability (Agent Protocol, LangGraph), identity (LOKA), and governance (Kagent, TrueFoundry-like gateways). By aligning with one or more of these standards, enterprises can ensure smooth agent interoperability while keeping security and scalability in mind.
Key Metrics for Evaluating Gateway
| Criteria | What should you evaluate ? | Priority | TrueFoundry |
|---|---|---|---|
| Latency | Adds <10ms p95 overhead for time-to-first-token? | Must Have | ✅ Supported |
| Data Residency | Keeps logs within your region (EU/US)? | Depends on use case | ✅ Supported |
| Latency-Based Routing | Automatically reroutes based on real-time latency/failures? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |

Implementing an AI agent registry provides many advantages for enterprise AI teams:
Each of these benefits helps enterprises move towards robust AI ops. By treating agents as first-class assets in a registry, organizations gain the governance, discoverability, and auditing that have long been standard for data and models, extending them to autonomous agents.
Building an enterprise-grade agent registry is not trivial. Teams must navigate several challenges:
على الرغم من هذه التحديات، تتناول المقترحات الحديثة ودراسات الحالة العديد منها. على سبيل المثال، يستخدم ANS نظام تسمية شبيهًا بـ DNS مع خوارزميات حل آمنة، وقد نشر مجتمع A2A أفضل الممارسات لأمان بطاقة الوكيل. من المرجح أن يجمع تطبيق سجل المؤسسة بين استراتيجيات متعددة: الاكتشاف الموحد، والهوية القوية، وطبقة حوكمة متينة.
Here's The Evaluation Framework for Proposal Template
| Criteria | What should you evaluate ? | Priority | TrueFoundry |
|---|---|---|---|
| Gateway & Developer Experience | |||
| Unified model access | Does the platform provide one consistent interface for hosted models, self-hosted models, and provider-native requests? | Must have | ✅ Supported: unified access to 1000+ LLMs. |
| OpenAI-compatible API | Can teams keep existing OpenAI, Anthropic, or provider-compatible client code while moving traffic behind a governed gateway? | Must have | ✅ Supported: OpenAI-compatible API plus native SDK support. |
| Prompt lifecycle management | Can prompts be created, versioned, A/B tested, and reused with a built-in playground for rapid iteration? | Should have | ✅ Supported: versioned prompts, playground, and experimentation. |
| Playground and experimentation | Is there a playground UI for non-developers to test prompts, models, and tools without code? | Should have | ✅ Supported: playground with model and tool experimentation. |
لنشر وإدارة سجل وكلاء بنجاح، يجب على الفرق اتباع هذه التوصيات:
requests.post("http://registry/v1/agents/register", json=agent_card)
باتباع هذه الممارسات الفضلى، يمكن للفرق جعل سجل وكلاء الذكاء الاصطناعي مكونًا قويًا وقابلاً للتوسع في منصة MLOps أو ModelOps الخاصة بهم. مع مرور الوقت، سيتطور ليصبح جزءًا أساسيًا من منصة اكتشاف الذكاء الاصطناعي للمؤسسات – على غرار كيف أصبحت سجلات النماذج لا غنى عنها لإدارة دورة حياة تعلم الآلة.
تستعد سجلات وكلاء الذكاء الاصطناعي لتصبح عنصرًا أساسيًا في البنية التحتية للذكاء الاصطناعي للمؤسسات. مع انتشار الوكلاء المستقلين، يضمن وجود آلية اكتشاف موحدة أن يتمكن الوكلاء من التنسيق بدلاً من التصادم. الإجماع البحثي واضح: "أصبحت الحاجة إلى أنظمة سجل موحدة لدعم الاكتشاف والهوية ومشاركة القدرات أمرًا ضروريًا". من خلال مركزة بيانات الوكلاء الوصفية وتسجيلهم وحوكمتهم، تمكّن المؤسسات التشغيل البيني السلس للوكلاء والحوكمة القوية للوكلاء المستقلين.
مستقبلًا، نتوقع المزيد من التقارب حول البروتوكولات (مثل A2A، بروتوكول الوكيل، AgentFacts) والمزيد من الأدوات (مثل بوابة TrueFoundry للأدوات). في نهاية المطاف، سيصبح سجل الوكلاء أمرًا روتينيًا مثل سجل النماذج اليوم – حيث يوفر سجلات تدقيق، وتحكمًا في الإصدارات، وكتالوجًا قابلاً للبحث لقدرات الذكاء الاصطناعي. بالنسبة لفرق الذكاء الاصطناعي في المؤسسات، يعني الاستثمار في سجل الوكلاء الآن الحصول على منصة قابلة للتوسع لتنسيق مهام سير عمل الذكاء الاصطناعي المعقدة، وتقليل احتكاك التكامل، وإطلاق العنان للإمكانات الكاملة للذكاء الاصطناعي الوكيلي في الإنتاج.
يعمل سجل وكلاء الذكاء الاصطناعي كـ "دليل هاتف" مركزي حيث يسجل الوكلاء المستقلون بياناتهم الوصفية وقدراتهم عبر بطاقة وكيل. يسمح هذا النظام للوكلاء أو المستخدمين الآخرين بالبحث عن مهارات محددة، والتحقق من الهويات، والحصول على تفاصيل الاتصال من خلال بروتوكولات اكتشاف موحدة.
يُعد سجل وكلاء الذكاء الاصطناعي ضروريًا للمؤسسات لإدارة التعقيد المتزايد لأنظمة الذكاء الاصطناعي المعيارية على نطاق واسع. يوفر لوحة تحكم موحدة للحوكمة، مما يمكّن الفرق من فرض سياسات الأمان، وتتبع الإصدارات، ومراقبة صحة الوكلاء مع تشجيع إعادة استخدام الوكلاء الحاليين عبر الأقسام المختلفة.
بينما يتتبع سجل النماذج عناصر تعلم الآلة الثابتة، يركز سجل الذكاء الاصطناعي الوكيلي على البرامج الحية والمستقلة التي تفكر وتتصرف. يدير سجل النماذج الإصدارات والأوزان، لكن سجل الوكلاء يتعامل مع الاكتشاف في الوقت الفعلي، ومراقبة نبضات القلب، والتنسيق الديناميكي لمهام سير العمل النشطة بين وكلاء متخصصين متعددين.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








أحدث الأخبار والمقالات والموارد تصلك مباشرة إلى بريدك الوارد
© 2026 جميع الحقوق محفوظة.







.png)
.webp)










.webp)
