




November 5, 2025
|
5 min read


احصل على وصول فوري إلى بيئة TrueFoundry مباشرة. انشر النماذج، ووجّه حركة مرور LLM، واستكشف المنصة بالكامل — بيئة الاختبار الخاصة بك جاهزة في ثوانٍ، ولا يلزم وجود بطاقة ائتمان.









Published: July 4, 2026

Blazingly fast way to build, track and deploy your models!
في الأشهر القليلة الماضية، أتيحت لنا الفرصة للعمل مع فريق صغير لكنه فعال. لقد طوروا نموذج تعلم عميق متطورًا وأنشأوا شراكات لتقديمه لأكثر من 10 ملايين مستخدم.
كانت القطعة الأخيرة المفقودة في قصة تأثيرهم هي معالجة الجانب الهندسي لتحقيق ذلك. كان النموذج يتطلب قدرة حاسوبية عالية، وبالحجم الذي أرادوا به تقديم هذا النموذج للمستخدمين النهائيين، كانوا بحاجة إلى بنية تحتية موثوقة وعالية الأداء يمكن لشخصين منهم إدارتها (مهندس DevOps واحد ومهندس تعلم آلة واحد).
تم بناء النموذج لمعالجة مدخلات صوتية بأحجام مختلفة. نظرًا لأن النموذج كان يستغرق وقتًا طويلاً في المعالجة (بمتوسط حوالي 5 ثوانٍ)، فقد احتاج إلى استدلال غير متزامن لكل طلب لمعالجة هذه الطلبات والاستجابة لها.
لقد بنى الفريق بنيته الأولية لتقديم النموذج على Sagemaker. ومع ذلك، عندما أجروا تجربتهم الأولية باستخدام هذا التصميم، أدركوا أن تقديم النموذج بشكل موثوق بالحجم المطلوب سيكون صعبًا باستخدام هذه البنية.
حتى بعد استخدام الإعداد غير المتزامن، نظرًا لأن تشغيل المثيلات استغرق وقتًا للتوسع (8-10 دقائق لكل جهاز)، تضررت تجربة المستخدم النهائي عندما اضطروا إلى تحمل هذا التأخير.
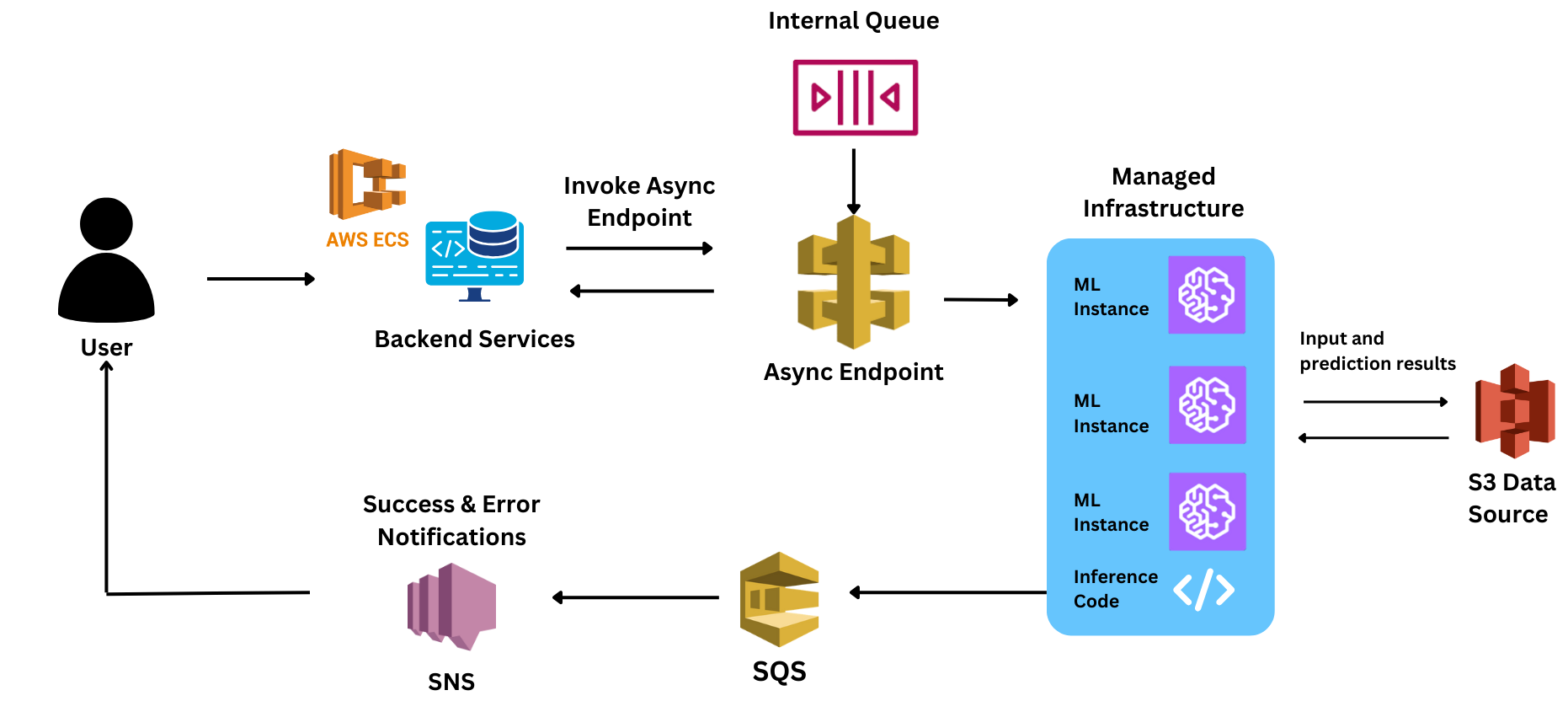
ومع ذلك، خلال إثبات المفهوم، واجهوا تأخيرات كبيرة في أوقات الاستجابة. نظرًا لأنهم كانوا جددًا على العديد من عناصر التحكم المتعلقة بـ Sagemaker، فقد فقدوا وقتًا ثمينًا في البحث عن سبب التأخيرات. بعض التحديات التي واجهوها كانت:
بعد إثبات المفهوم، فقد الفريق الثقة في Sagemaker وقرروا أنهم بحاجة إلى حل يمكن لشخصين (مهندس تعلم آلة واحد ومهندس DevOps واحد) تقديمه لجمهورهم المستهدف الذي يزيد عن 10 ملايين مستخدم.
عندما بدأنا العمل مع الفريق، كان مشروعهم التجريبي على بعد حوالي 7 أيام. أكدنا للفريق أننا نستطيع مساعدتهم في ترحيل المكدس بالكامل وإعادة بنائه باستخدام وحدات TrueFoundry في أقل من يومين، حتى يحصلوا على وقت كافٍ للاختبار قبل أن يدخل مشروعهم التجريبي مرحلة الإنتاج.
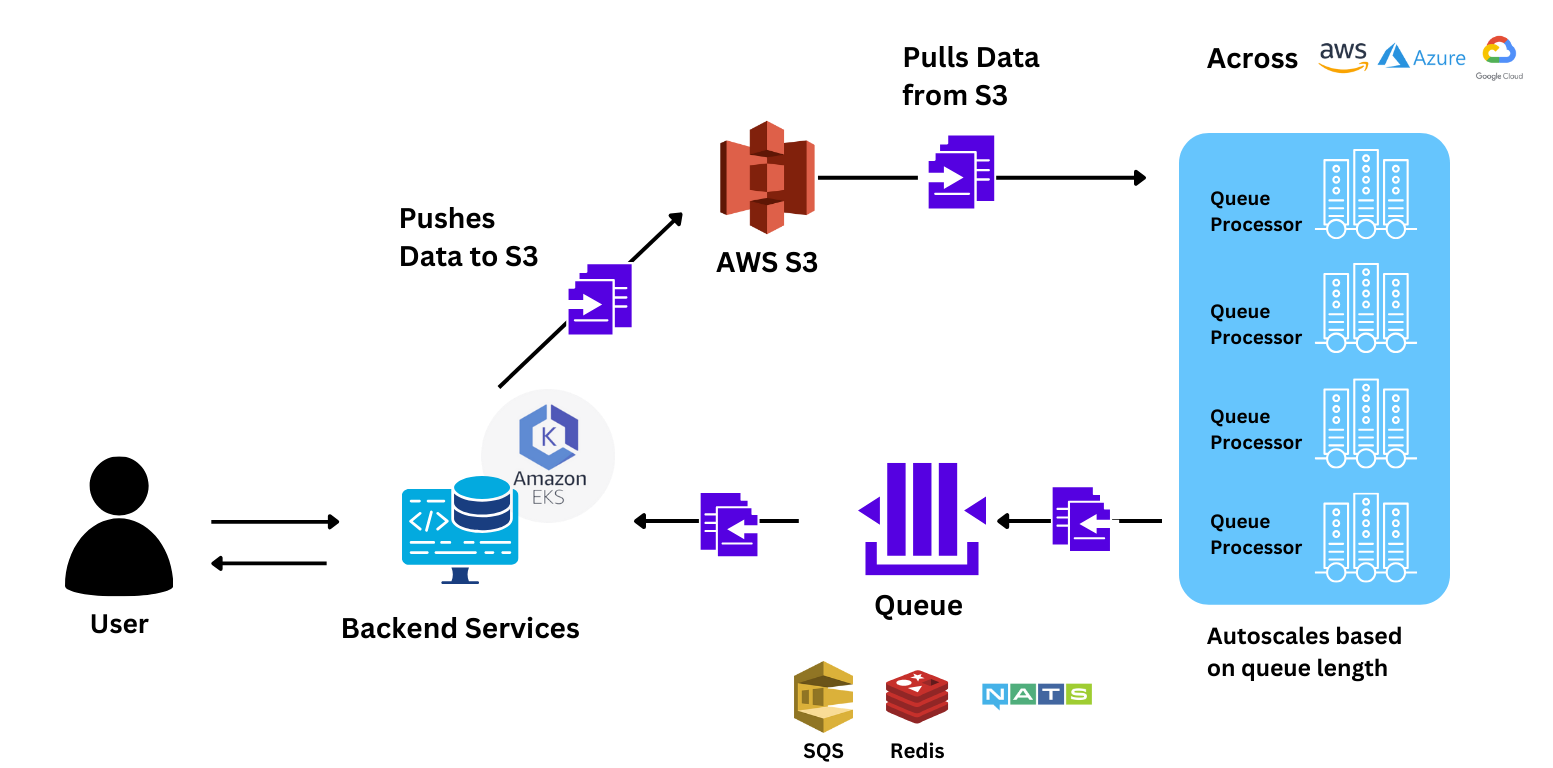
أجرى الفريق اختبارات أداء عن طريق إرسال دفعة من 88 طلبًا إلى النموذج لمقارنة الأداء مع Sagemaker. TrueFoundry توسعت أسرع بنسبة 78% من Sagemaker، مما يوفر للمستخدم استجابات أسرع بكثير. كان الوقت المستغرق للاستجابة للطلب من البداية إلى النهاية أسرع بنسبة 40% مع TrueFoundry.
تمكن الفريق ببساطة من توسيع نطاق التطبيق إلى أكثر من 150 عقدة GPU للأسباب التالية:
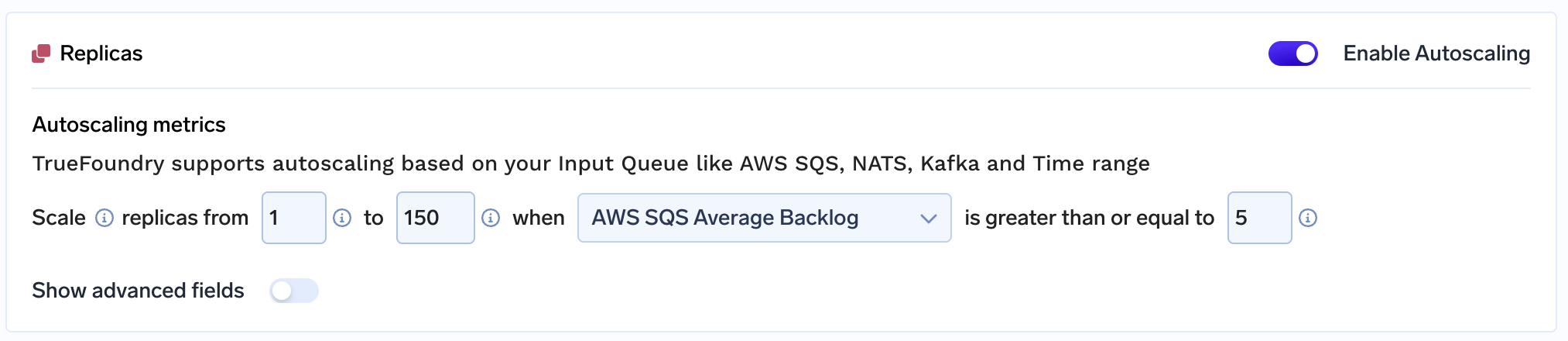

باستخدام TrueFoundry، يمكن للفريق المكون من عضوين إدارة عبء عملهم بالكامل، والذي يتوسع غالبًا إلى أكثر من 150 عقدة GPU!! بمفردهم. أثناء العمل معنا، كان الشيء الأكثر تميزًا الذي لفت انتباه الفريق هو دعم العملاء وأوقات الاستجابة المنخفضة لدينا. تلتزم TrueFoundry بنجاح عملائها ونأمل أن يتمكن جميع عملائنا من التوسع وإحداث تأثير على نطاقات مماثلة لهذا المشروع!
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








أحدث الأخبار والمقالات والموارد تصلك مباشرة إلى بريدك الوارد
© 2026 جميع الحقوق محفوظة.











.png)
.webp)










.webp)
