Currently, only Anthropic models support this caching feature. See Anthropic documentation for more details.
Minimum Cacheable Length
| Model | Minimum Token Length |
|---|---|
| Claude Opus 4, Claude Sonnet 4, Claude Sonnet 3.7, Claude Sonnet 3.5, Claude Opus 3 | 1024 tokens |
| Claude Haiku 3.5, Claude Haiku 3 | 2048 tokens |
Usage
This feature is only available through direct REST API calls. The OpenAI SDK doesn’t recognize the
cache_control field.cache_control parameter to any message content you want to cache:
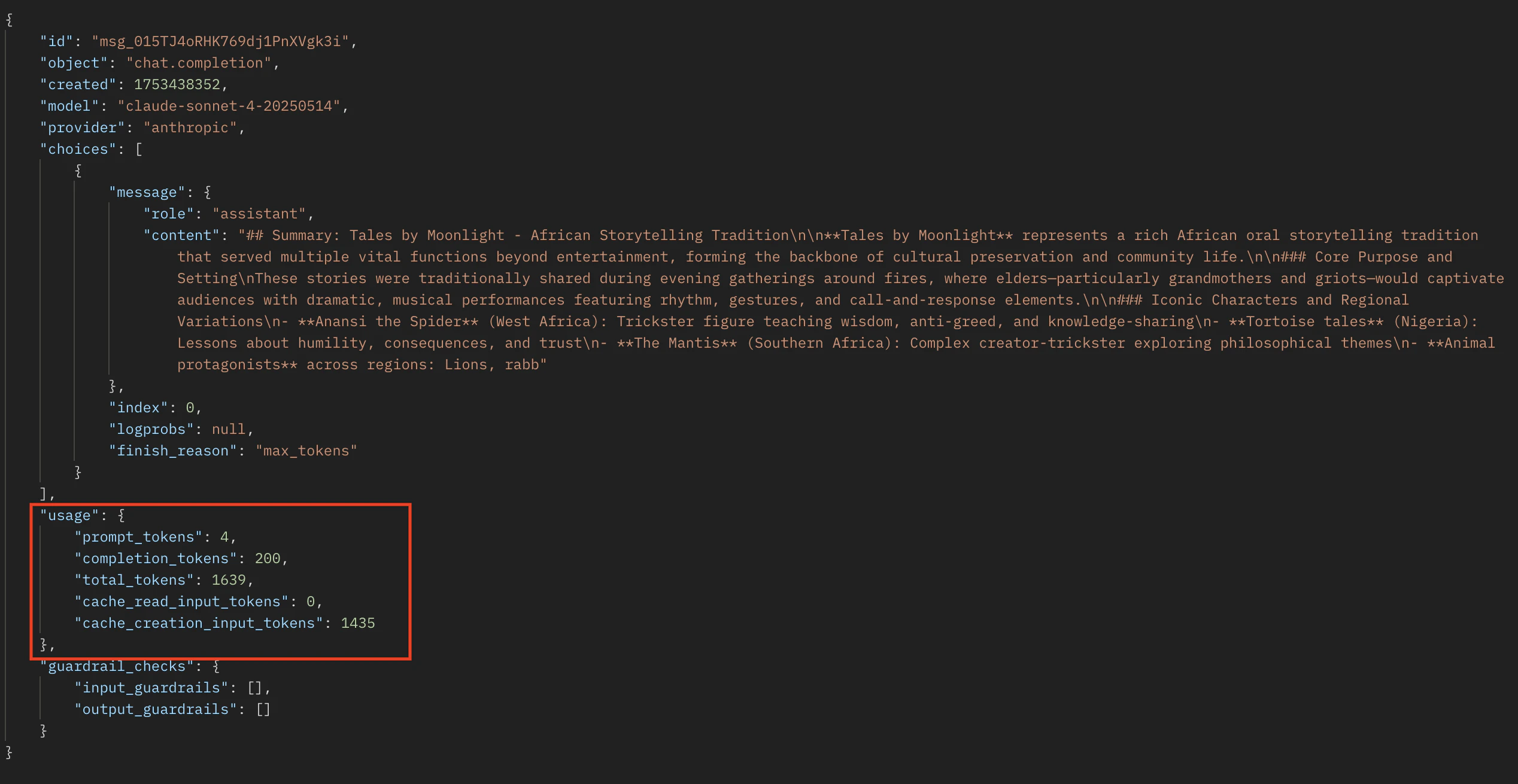
Monitoring Cache Performance
Monitor cache performance using these API response fields, withinusage in the response (or message_start event if streaming):
cache_creation_input_tokens: Tokens written to the cache when creating a new entrycache_read_input_tokens: Tokens retrieved from the cache for this request