July 25, 2026
|
5 min read

Published: January 24, 2026
Blazingly fast way to build, track and deploy your models!
n8n is popular because it is easy to use. You drag nodes onto a canvas and build automations quickly. Many teams now add AI steps to these flows, like drafting replies or summarizing text.
As these workflows move into daily operations, new problems show up. API keys end up in many places. Each workflow may call a different model vendor. Finance gets several invoices. Security loses a single audit trail. Engineering finds it hard to swap models across dozens of flows.
TrueFoundry AI Gateway fixes this. It becomes the single place that handles policy, cost limits, routing, and logs for every LLM call. Builders keep using n8n the same way. Platform, security, and finance get the control they need.
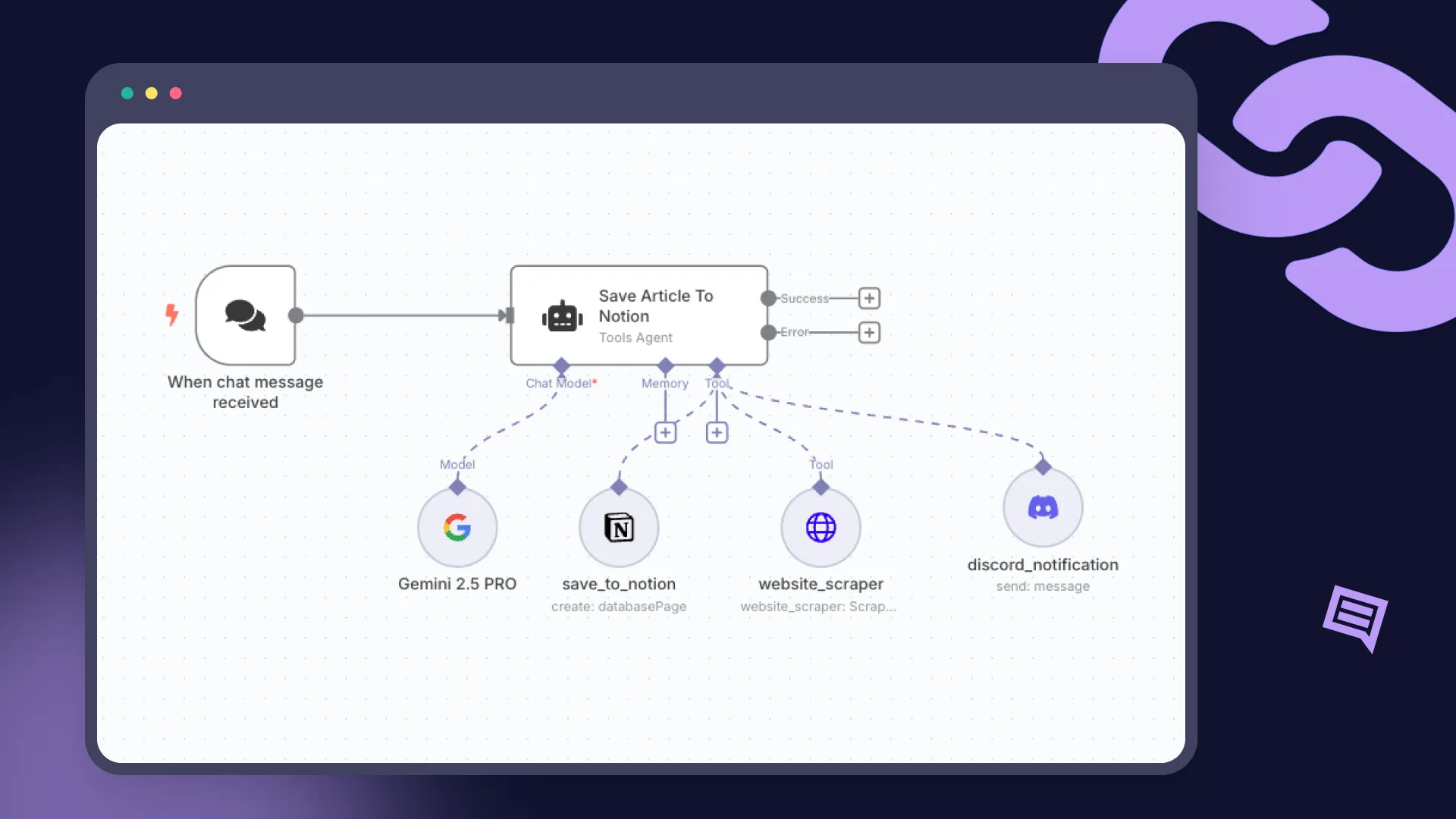
Imagine a common use case: automating customer support. In an n8n workflow, this might look simple. An incoming email is passed to an LLM to draft a reply. The generated text is then sent to a second sentiment-analysis model to flag urgent cases for human review.
But when these model calls are routed directly to vendors, chaos ensues for the platform teams:
By routing all n8n traffic through the TrueFoundry AI Gateway, the entire picture changes. The Gateway acts as a single, intelligent control plane. Support agents keep the drag-and-drop speed they love, while the organization gains complete governance and cost control—closing the blind spots for every single LLM call.
Key Metrics for Evaluating Gateway
| Criteria | What should you evaluate ? | Priority | TrueFoundry |
|---|---|---|---|
| Latency | Adds <10ms p95 overhead for time-to-first-token? | Must Have | ✅ Supported |
| Data Residency | Keeps logs within your region (EU/US)? | Depends on use case | ✅ Supported |
| Latency-Based Routing | Automatically reroutes based on real-time latency/failures? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |

Wiring n8n into the Gateway is a one-time setup that takes minutes.
Prerequisites:
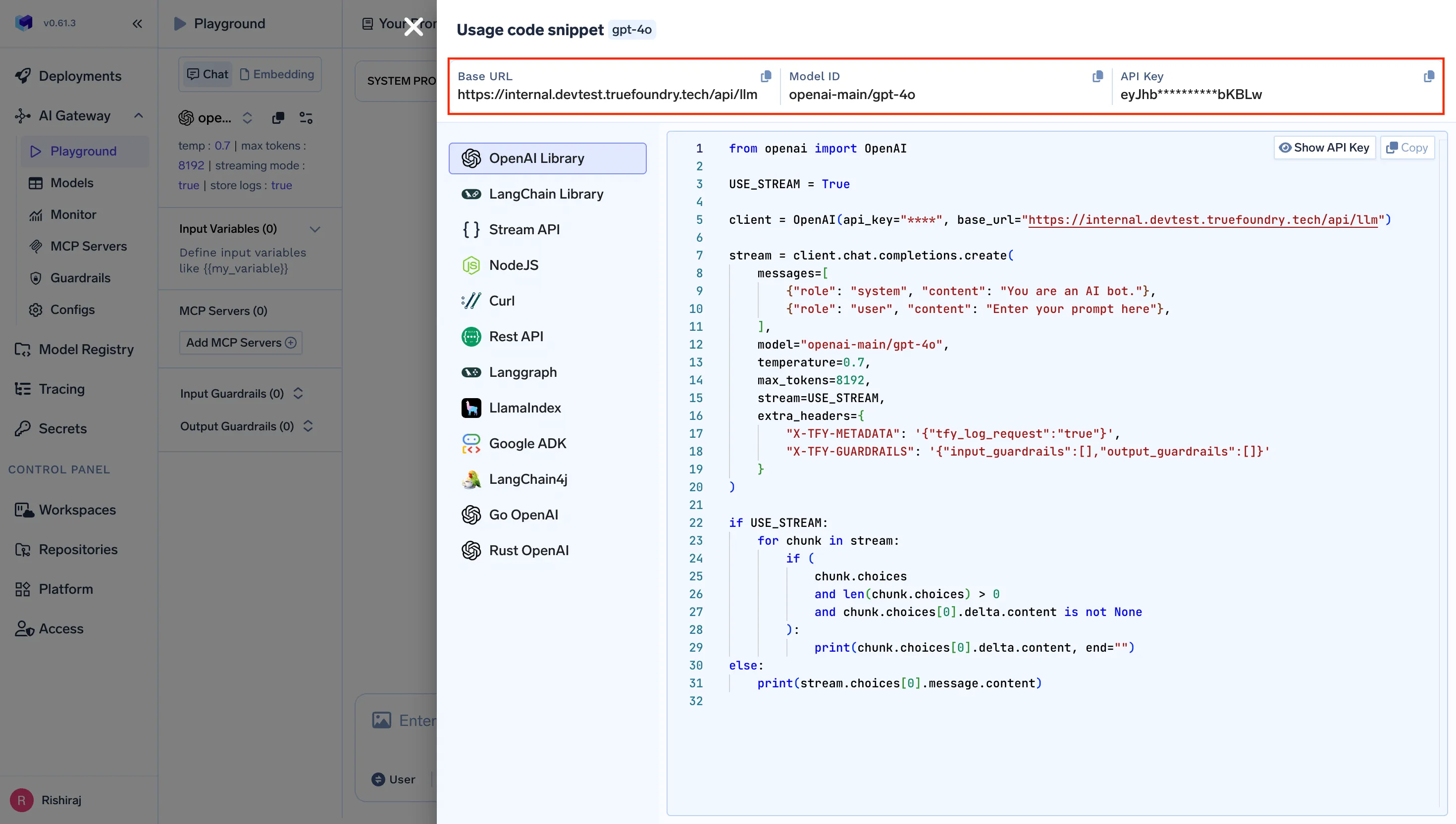
Steps:
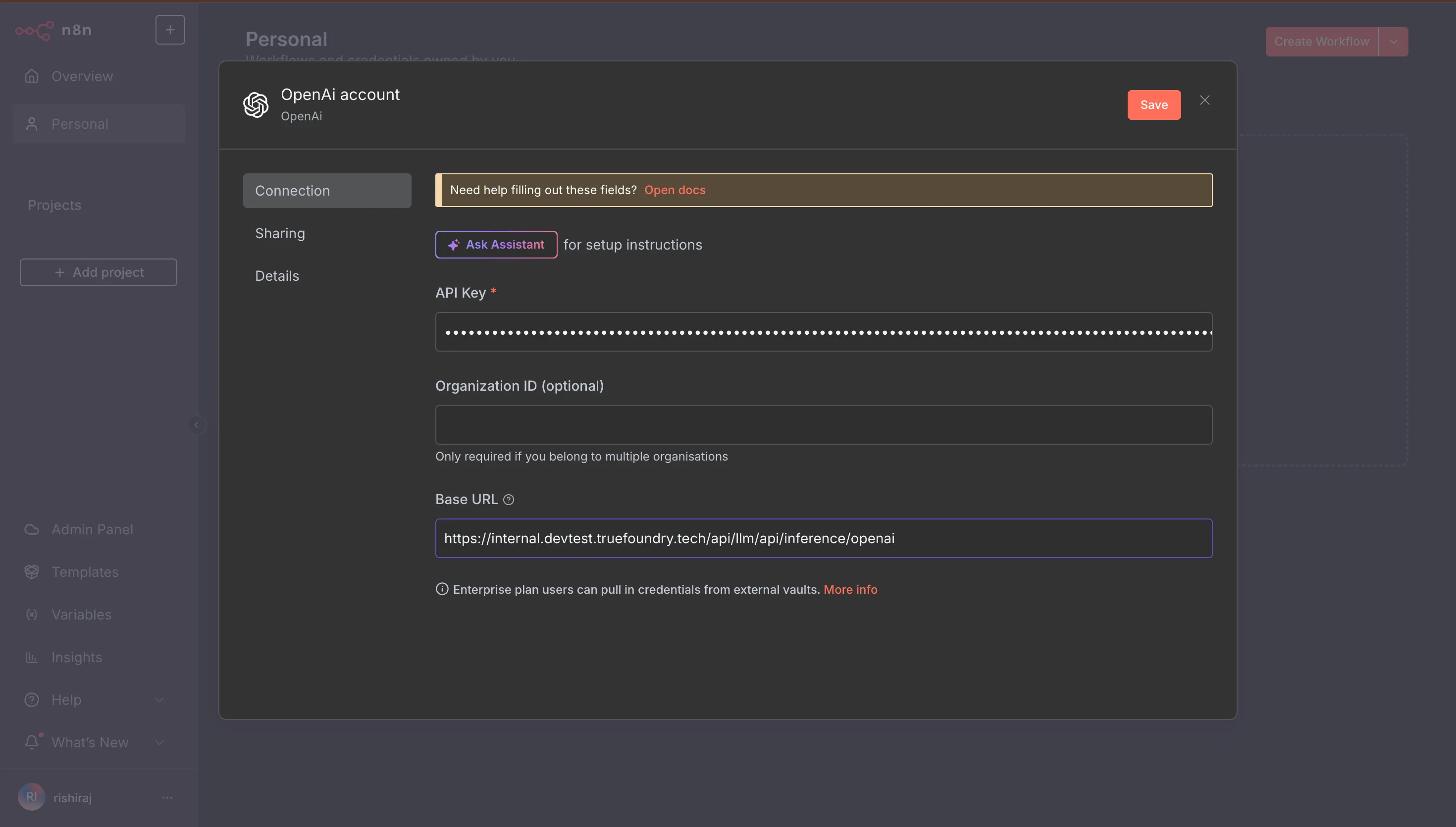
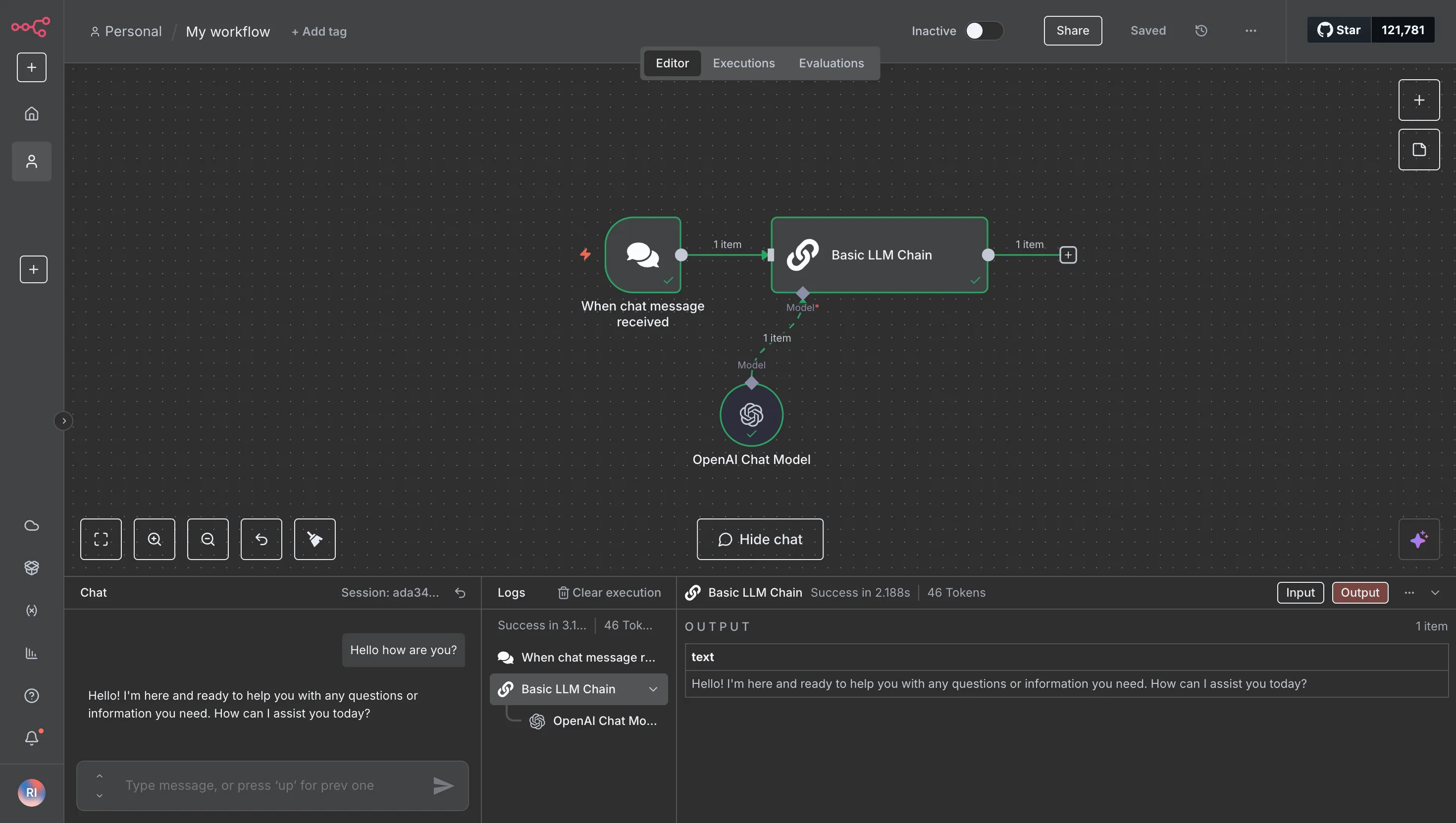
That’s it. Run your workflow. Every LLM request from that point forward will be routed through the TrueFoundry Gateway, giving you immediate observability and policy enforcement.
When n8n runs through TrueFoundry AI Gateway, your organization gains powerful new capabilities without altering existing workflows. By centralizing control, the gateway provides immediate, tangible benefits for observability, security, and financial governance. Here’s a breakdown of what that looks like.
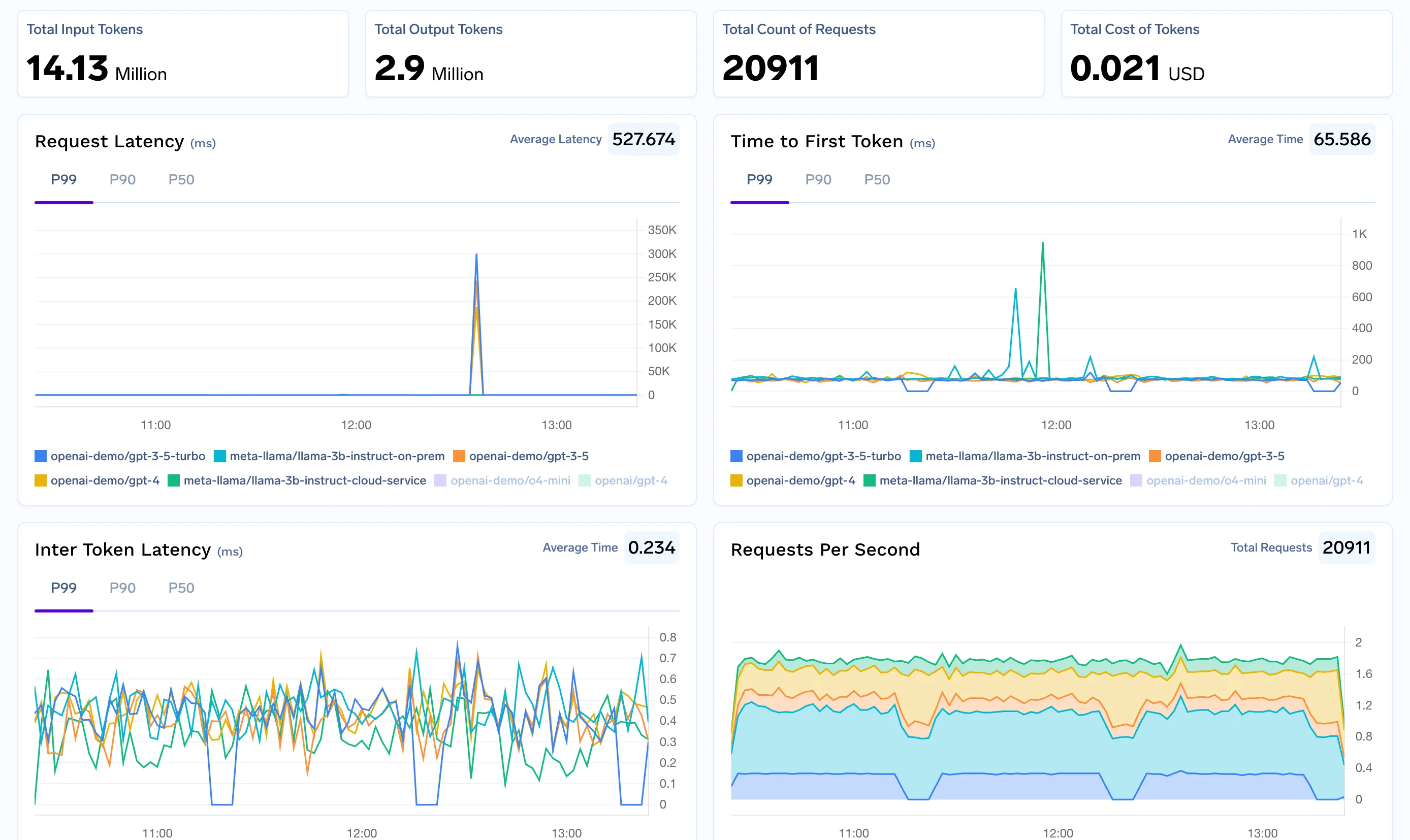
For finance and operations teams, gaining real-time visibility into AI expenditure is critical. The AI Gateway provides a comprehensive solution for n8n cost tracking from day one.
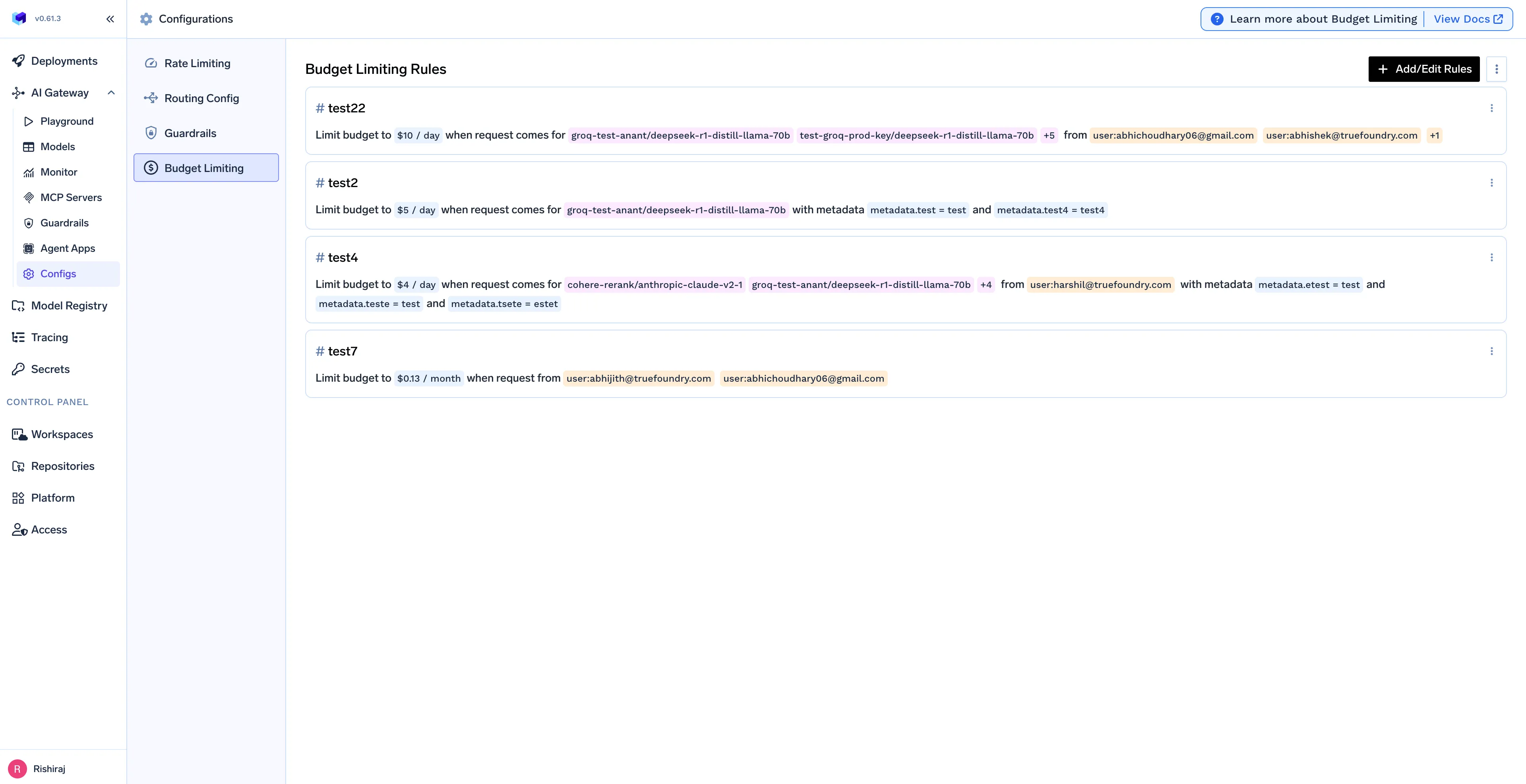
Security can't be an afterthought. The AI Gateway acts as a central checkpoint, applying powerful n8n guardrails to every LLM request automatically, ensuring your data and operations remain secure.
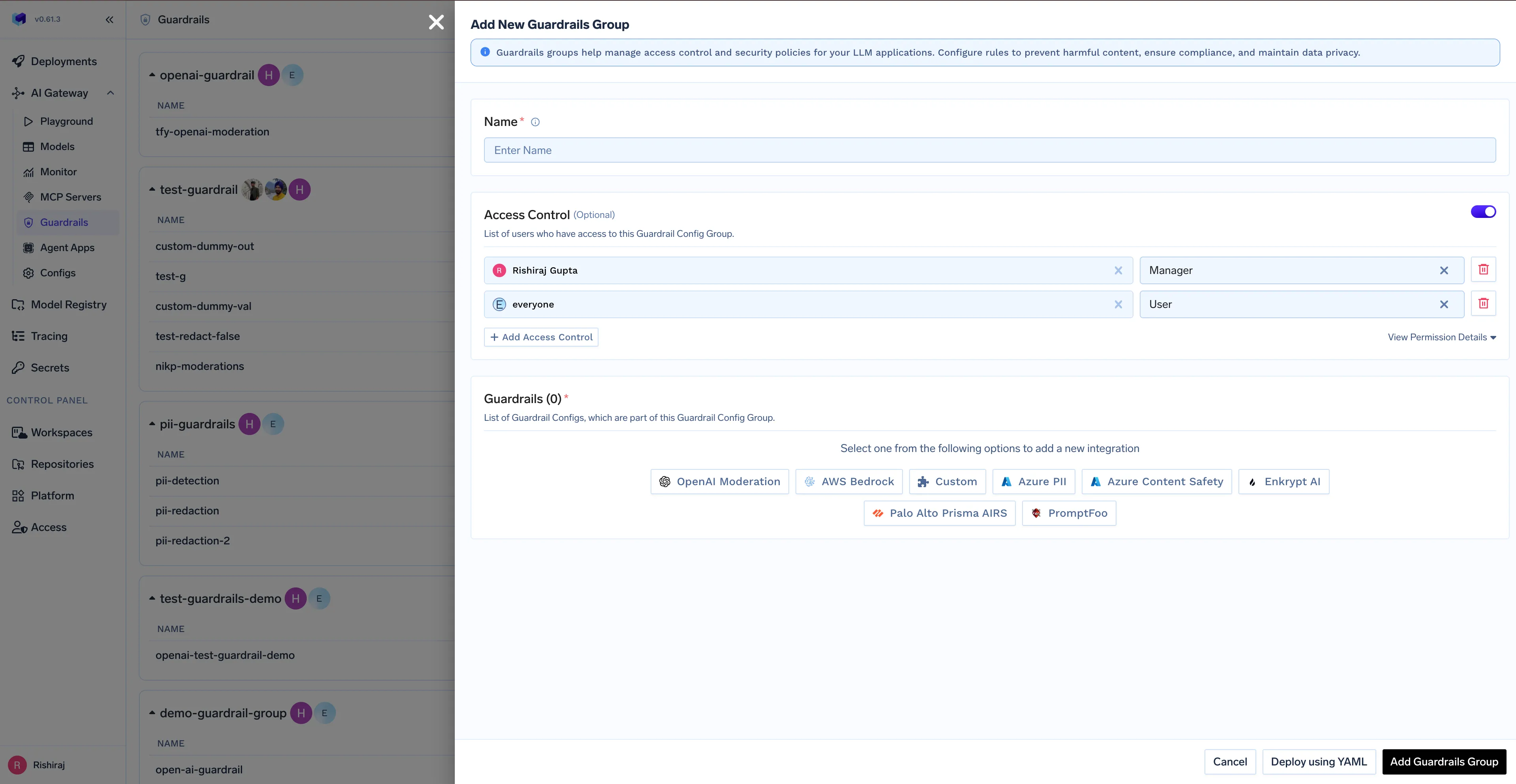
Platform engineering teams can ensure system stability and high performance without editing individual workflows. The gateway provides a central control plane for reliability.
claude-3-haiku, while the platform team can switch the underlying model version behind the scenes in the gateway to roll out changes safely and without downtime.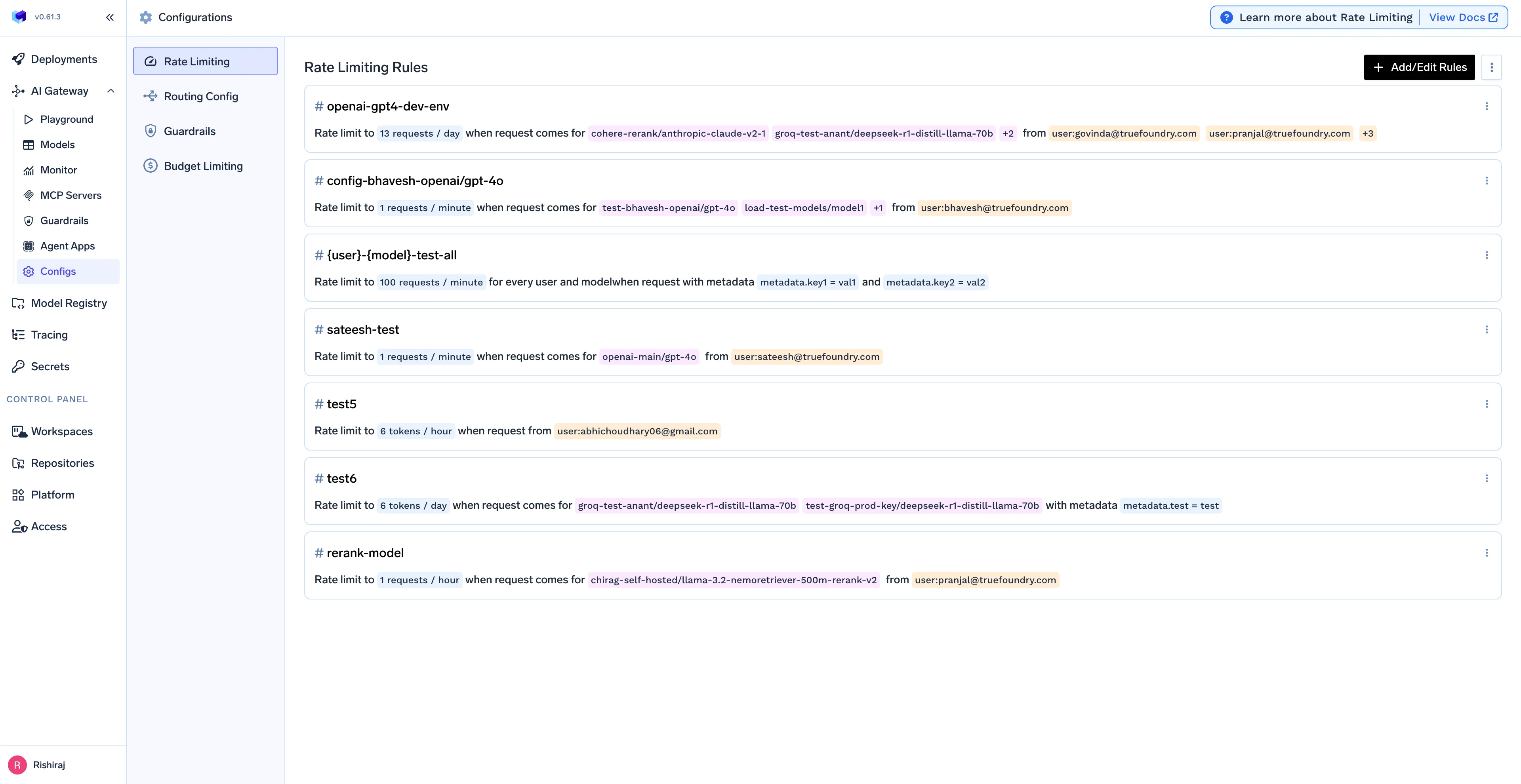
For data, analytics, and operations teams, debugging complex AI workflows can be a challenge. The gateway integrates n8n tracking with deep model tracing to provide a single, unified view of system health.
With these pieces in place, finance gets predictable costs, security gets clean audit trails, platform teams get reliable operations, and builders keep their speed. It’s the fastest path to scale n8n safely, with real‑time n8n tracking, strong n8n logs, and simple, centralized n8n cost monitoring that works from the first run.
This is just the beginning. Over the next quarter, the TrueFoundry team plans to deepen the integration to further streamline the builder experience. Your feedback is crucial in guiding our roadmap. Feel free to connect with us with your feature requests.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








The latest news, articles, and resources sent to your inbox

.webp)