




July 4, 2026
|
5 min read


احصل على وصول فوري إلى بيئة TrueFoundry مباشرة. انشر النماذج، ووجّه حركة مرور LLM، واستكشف المنصة بالكامل — بيئة الاختبار الخاصة بك جاهزة في ثوانٍ، ولا يلزم وجود بطاقة ائتمان.









Published: July 4, 2026

Blazingly fast way to build, track and deploy your models!
ذات مرة – قبل حوالي ستة أشهر بمقاييس الشركات الناشئة – كان هناك جيسون، مهندس تعلم آلة لامع في شركة تكنولوجيا مالية سريعة النمو. كان جيسون هو "ساحر الذكاء الاصطناعي" المقيم. عندما احتاج فريق المنتج إلى جعل روبوت الدردشة الجديد المدعوم بنماذج اللغة الكبيرة يبدو أكثر تعاطفًا ولكن أقل عرضة للهلوسة بشأن أسعار الفائدة، اتصلوا بجيسون.
كانت مجموعة أدوات جيسون واسعة النطاق: قواعد بيانات متجهية حديثة، ومجموعات Kubernetes محسّنة للغاية، وخطوط أنابيب CI/CD متطورة. لكن جوهر العملية، المطالبات الفعلية التي تدفع هذه الميزات التي تبلغ قيمتها ملايين الدولارات، كانت تعيش في نظام بيئي محفوف بالمخاطر.
كانت بعض المطالبات مبرمجة بشكل ثابت في سلاسل Python f-strings، مدفونة بعمق داخل المنطق الشرطي كتحف أثرية. بينما كانت مطالبات أخرى موجودة في مستند Google مشترك من 40 صفحة بعنوان "FINAL_PROMPTS_v3_REAL_FINAL(2).docx"، ويتم تحديثه بواسطة ثلاثة مديري منتجات مختلفين. أما أحدث المطالبات التجريبية، فكان الرئيس التنفيذي يرسلها إلى جيسون عبر Slack في الساعة 11:30 مساءً.
عندما اشتكى عميل من أن روبوت الدردشة قد عرض عليه قرضًا عقاريًا بلغة الكلينغون بشكل مربك، لم يقم جيسون بتصحيح الأخطاء البرمجية. بل قام جيسون بعملية تنقيب أثرية عبر سجلات Slack وتغييرات Git لمعرفة أي إصدار من "مطالبة التعاطف" كان يعمل في بيئة الإنتاج ومن قام بتغييره آخر مرة.
لم يعد جيسون يقوم بعمل هندسي. كان جيسون يقوم بأعمال صيانة رقمية. لقد بنى الفريق محرك فيراري لكنه كان يقوده بقطع خيط مفككة.
الألم وراء القصة المذكورة أعلاه حاد وعالمي في الواقع. إن نقل الذكاء الاصطناعي التوليدي من نموذج أولي لمسابقة هاكاثون إلى نظام إنتاجي موثوق يكشف عن جزء حاسم مفقود في مكدس MLOps التقليدي.
في الأيام الأولى، بدا التعامل مع المطالبات كتعليمات برمجية منطقيًا. تقوم بتحديد إصداراتها في Git، وتنشرها مع التطبيق. ولكن مع توسع الفرق، ينهار هذا النموذج. المطالبات ليست تعليمات برمجية تقليدية؛ إنها إعدادات، ومنطق عمل، وواجهة مستخدم، كلها مدمجة في حزمة لغة طبيعية واحدة.
عندما تكون المطالبات مرتبطة ارتباطًا وثيقًا بقواعد التعليمات البرمجية، تظهر عدة مشكلات حرجة:
لعبور الفجوة من النموذج الأولي إلى الإنتاج، يجب أن نتوقف عن التعامل مع المطالبات على أنها "سلاسل سحرية" متناثرة في جميع أنحاء بنيتنا التحتية. نحتاج إلى التعامل معها كمواطنين من الدرجة الأولى.
قبل تطبيق نهج منظم، غالبًا ما يبدو سير العمل وكأنه شبكة معقدة من سوء التواصل والجهد اليدوي.
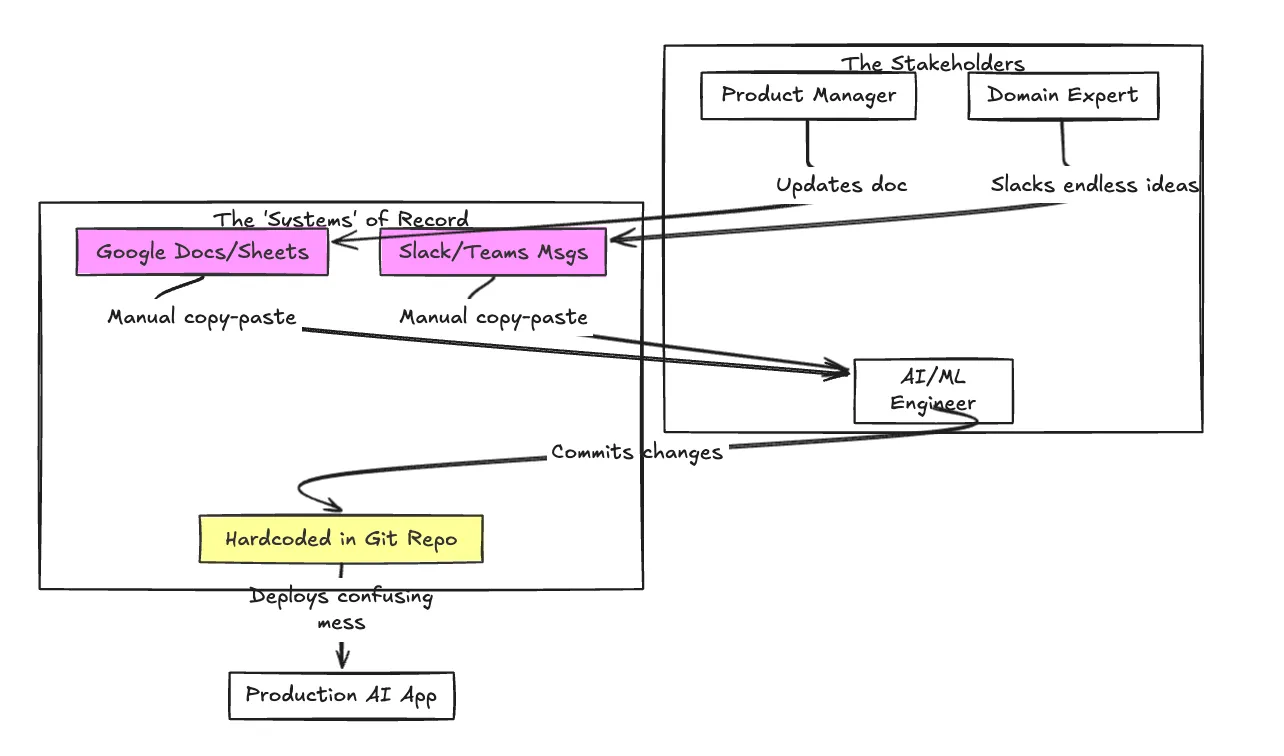
هنا يصبح نظام إدارة المطالبات المخصص ضروريًا. إنه الجسر بين الفن التجريبي لهندسة المطالبات والانضباط الصارم لهندسة برمجيات الإنتاج.
يعمل TrueFoundry كنظام التحكم المركزي هذا. وهو مصمم لفصل إدارة المطالبات عن منطق التطبيق، مما يسمح للفرق بالتعاون، وتحديد الإصدارات، وتقييم، ونشر المطالبات بنفس الدقة التي يطبقونها على التعليمات البرمجية التقليدية، ولكن بواجهات مصممة لتلبية الاحتياجات الخاصة لسير عمل نماذج اللغة الكبيرة (LLM).
يحول TrueFoundry إدارة المطالبات من مهمة عشوائية إلى طبقة بنية تحتية منظمة وقابلة للتدقيق.
يوفر TrueFoundry سجلًا مركزيًا للمطالبات. لا مزيد من البحث في مستندات Google أو قواعد التعليمات البرمجية. كل مطالبة، لكل حالة استخدام، توجد في مكان واحد آمن ويمكن الوصول إليه.
هذا هو التحول الأكثر أهمية للسرعة. في TrueFoundry، لا يحتوي رمز تطبيقك على نص المطالبة. بدلاً من ذلك، يحتوي على استدعاء خفيف الوزن لحزمة تطوير البرامج (SDK) يجلب الإصدار النشط من المطالبة المطلوبة.
هذا يعني أن مدير المنتج يمكنه تكرار العمل على مطالبة، واختبارها ضمن بيئة TrueFoundry التجريبية، و"ترقيتها" إلى مرحلة الإنتاج دون أن يحتاج مهندس إلى لمس رمز التطبيق أو تشغيل إعادة نشر.
مع TrueFoundry، تتحول الفوضى إلى دورة حياة مبسطة. يتعاون أصحاب المصلحة في المركز، ويتم تتبع الإصدارات بدقة، وتستهلك التطبيقات المطالبات بشكل موثوق عبر واجهة برمجة التطبيقات (API)، مع تحديد المعدل في بوابة الذكاء الاصطناعي ضمان سلوك إنتاجي مستقر تحت الاستخدام الكثيف.
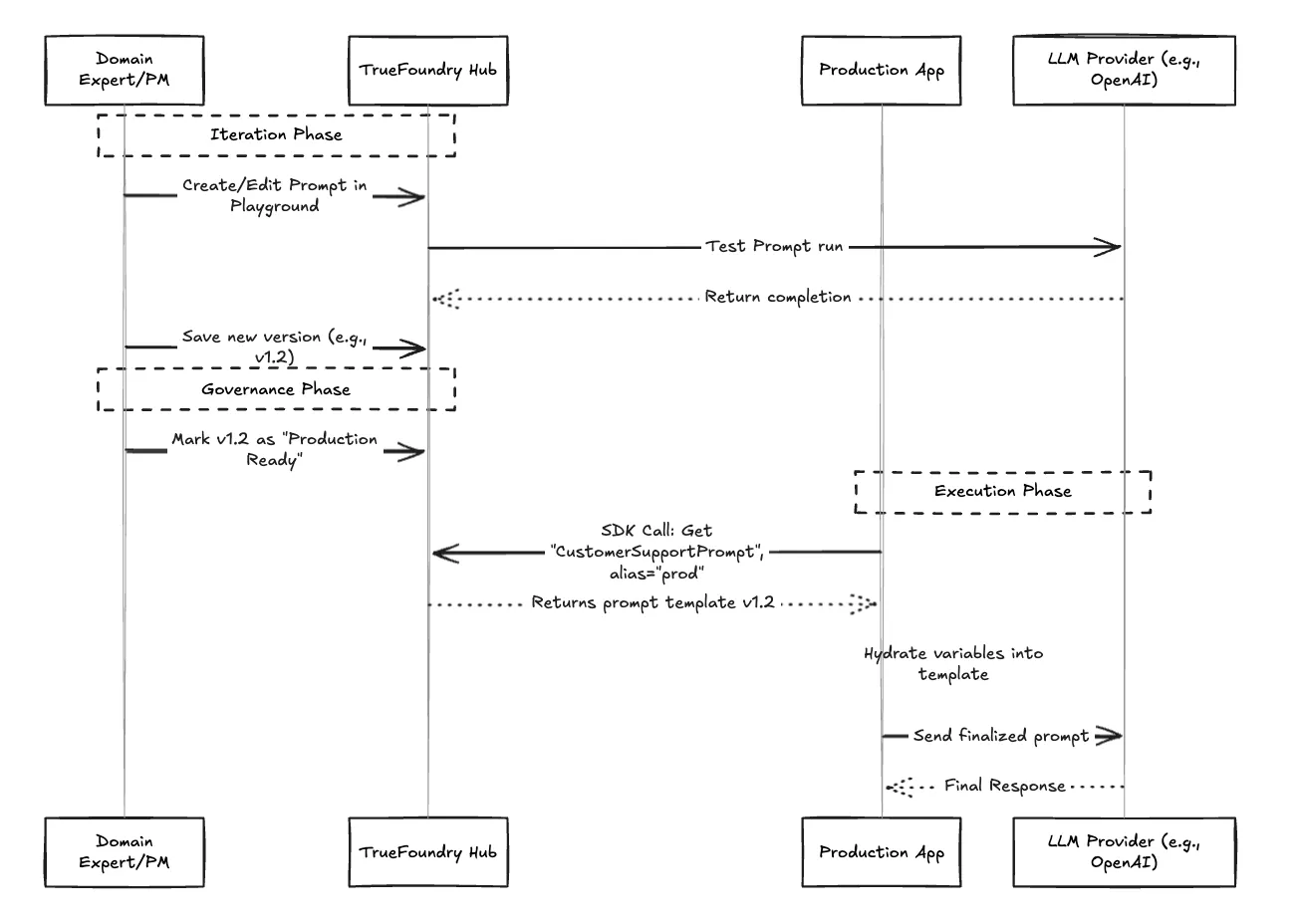
إدارة نص المطالبة ليست سوى نصف المعركة. كيف تعرف ما إذا كان الإصدار 2.0 أفضل بالفعل من الإصدار 1.5؟ يدمج TrueFoundry التقييم جنبًا إلى جنب مع الإدارة. قبل ترقية مطالبة إلى مرحلة الإنتاج، يمكنك تشغيلها مقابل مجموعات بيانات ذهبية لضمان عدم تراجع الدقة والنبرة والسلامة.
لمزيد من المعلومات، يرجى زيارة https://www.truefoundry.com/docs/ai-gateway/prompt-management
بالعودة إلى قصتنا، قام جيسون بتطبيق TrueFoundry. تمت أرشفة مستندات جوجل. وتم استبدال السلاسل المبرمجة باستدعاءات SDK.
الآن، عندما يرغب الرئيس التنفيذي في تغيير نبرة الروبوت الدردشة، يسجل الدخول إلى TrueFoundry، ويصيغ نسخة جديدة، ويختبرها مقابل بضعة أمثلة، ويشير إلى جيسون للمراجعة. يمكن لجيسون رؤية الفروقات الدقيقة بالضبط، وتشغيل مجموعة تقييم عليها، والموافقة عليها للنشر في دقائق—كل ذلك دون كتابة سطر واحد من بايثون.
يتطلب التحول إلى الذكاء الاصطناعي الإنتاجي إدراك أن المطالبات هي فئة جديدة من المكونات البرمجية. إنها تحتاج إلى بنيتها التحتية المخصصة. توفر TrueFoundry الأدوات اللازمة لتحويل فن هندسة المطالبات إلى منهجية هندسية قابلة للإدارة والتوسع، مما يضمن أن تطبيقات الذكاء الاصطناعي التوليدي لديك قوية بقدر بقية مكدسك التقني.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








أحدث الأخبار والمقالات والموارد تصلك مباشرة إلى بريدك الوارد
© 2026 جميع الحقوق محفوظة.







.png)
.webp)










.webp)
