




July 4, 2026
|
5 min read


احصل على وصول فوري إلى بيئة TrueFoundry مباشرة. انشر النماذج، ووجّه حركة مرور LLM، واستكشف المنصة بالكامل — بيئة الاختبار الخاصة بك جاهزة في ثوانٍ، ولا يلزم وجود بطاقة ائتمان.









Published: July 4, 2026

Blazingly fast way to build, track and deploy your models!
كل يوم جمعة، أكتب نفس الشيء:
"أنا براثاميش. مهندس برمجيات أول في TrueFoundry. أعمل على خدمة الذاكرة. التنسيق: ما تم تسليمه، ما هو قيد التنفيذ، المعوقات. اجعلها موجزة."
ثم أطلب تحديثي الأسبوعي.
يكتبه الذكاء الاصطناعي بشكل مثالي. ولكن في الجمعة القادمة؟ نفس الروتين. لن يتذكر اسمي، أو دوري، أو مشروعي، أو أنني ذكرت نفس المعوق لثلاثة أسابيع متتالية.
لقد بنيت هذا المساعد بنفسي: واجهة مستخدم دردشة بسيطة، وبوابة الذكاء الاصطناعي لـ TrueFoundry في الواجهة الخلفية. يتعامل مع اجتماعات الوقوف، ورسائل البريد الإلكتروني، ورسائل Slack، ومسودات الوثائق. إنه مفيد حقًا. لكن كل جلسة تبدأ من الصفر. أنا لا أستخدم ذاكرة الذكاء الاصطناعي. أنا أكون ذاكرة الذكاء الاصطناعي.
حل ChatGPT هذه المشكلة بذاكرة مدمجة. ولكن عندما تبني تطبيق نموذج اللغة الكبير الخاص بك، فإن تلك البنية التحتية غير موجودة. أنت وحدك. ما لم تبنيها بنفسك.
وهكذا فعلت. TrueMem هي طبقة ذاكرة دائمة لتطبيقات الذكاء الاصطناعي. تمنح أي نموذج لغة كبير (LLM) ذاكرة طويلة المدى تعمل عبر الجلسات وحتى عبر نماذج مختلفة. لا مزيد من تكرار نفسك. الذكاء الاصطناعي يتذكر بالفعل.
الحلول الواضحة لها مشاكل واضحة.
ذاكرة ChatGPT المدمجة محصورة داخل نظام OpenAI البيئي. لا يمكنك الوصول إليها برمجيًا، أو استخدامها مع نماذج أخرى، أو تدقيق ما يتم تخزينه. بوابة الذكاء الاصطناعي لـ Truefoundry تساعدنا في الوصول إلى نماذج متعددة، وتدقيق ما يتم تخزينه. بالنسبة لأي شخص يبني تطبيقاته الخاصة، فهذا أمر غير وارد.
التوليد المعزز بالاسترجاع (RAG) يحل مشكلة مختلفة. تسترجع تقنية RAG المعلومات من المستندات. وتجيب على سؤال "ماذا يقول هذا الملف بصيغة PDF؟" ذاكرة المستخدم مختلفة جوهريًا. إنها شخصية، متطورة، وتعتمد على العلاقات. الحقائق التي أشاركها في المحادثة ليست مستندات ليتم فهرستها؛ بل هي سياق يجب أن يشكل كل تفاعل مستقبلي.
توسيع نوافذ السياق هو النهج القسري: يتضمن سجل المحادثة بالكامل. تدعم النماذج الحديثة 128 ألف رمز أو أكثر، فلماذا لا؟ لأن الرموز مكلفة، والمزيد من السياق يعني استدلالًا أبطأ، وكل شيء يختفي عند انتهاء الجلسة. أنت تدفع ثمنًا باهظًا للنسيان بخطوات إضافية.
ما نحتاجه هو طبقة مخصصة تخزن الحقائق المستخلصة عن المستخدمين بشكل دائم وتسترجع فقط ما هو ذو صلة لكل استعلام. هذه هي الفجوة التي TrueMem تسدها.
لا تعمل الذاكرة البشرية بتخزين كل محادثة حرفيًا. لدينا ذاكرة عاملة للمهمة الحالية وذاكرة طويلة المدى للمعرفة الدائمة. يتفاعل النظامان باستمرار: فذكريات المدى الطويل تُعلمنا كيفية تفسير المعلومات الجديدة، بينما يتم دمج التجارب الجديدة المهمة في التخزين طويل المدى.
TrueMem يحاكي هذه البنية بمكونين متميزين: الذاكرة قصيرة المدى (STM) لسياق المحادثة و الذاكرة طويلة المدى (LTM) للحقائق الدائمة عن المستخدم.
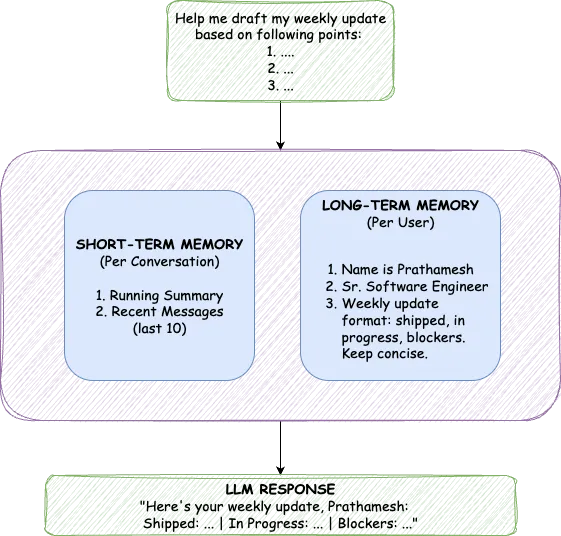
الفصل مهم لأن أنواع الذاكرة هذه تخدم أغراضًا مختلفة. تلتقط الذاكرة قصيرة المدى (STM) ما يحدث الآن، والتدفق الكامل للمحادثة الحالية. تخزن الذاكرة طويلة المدى (LTM) الحقائق المستخلصة التي تستمر عبر جميع المحادثات. يتم تضمين الذاكرة قصيرة المدى (STM) دائمًا في السياق؛ بينما يتم استرجاع الذاكرة طويلة المدى (LTM) بناءً على الصلة الدلالية. محاولة حل كليهما بآلية واحدة تفرض حلًا وسطًا. النهج المزدوج يتجنب ذلك تمامًا.
ضمن جلسة دردشة واحدة، يحتاج الذكاء الاصطناعي إلى تذكر ما ناقشته قبل خمس دقائق. هذه هي مهمة الذاكرة قصيرة المدى (STM)، وهي تحافظ على مكونين: ملخص مستمر للرسائل القديمة وآخر عشرين رسالة بدقتها الكاملة.
مع نمو المحادثة، نراقب باستمرار العدد الإجمالي للرموز. عندما يتجاوز هذا العدد حدًا معينًا، يقوم عامل في الخلفية بضغط الرسائل القديمة في الملخص المستمر مع الحفاظ على الرسائل الحديثة سليمة.

الملخص غير متزامن، لذا لا ينتظر المستخدمون أبدًا. عندما يتم تجاوز الحد، تقوم مهمة خلفية بجلب الرسائل غير الملخصة، وتدمجها مع أي ملخص موجود، وتنشئ ملخصًا شاملاً محدثًا. تُعلّم هذه الرسائل بأنها "ملخصة" وتستمر الدورة. يعني الضغط التدريجي أن المحادثات التي تستغرق ساعة كاملة تظل ضمن حدود سياقية معقولة.
لكن سياق المحادثة وحده لا يكفي. ماذا يحدث عندما يعود المستخدم غدًا؟ هنا يأتي دور الذاكرة طويلة المدى.
تخزن الذاكرة طويلة المدى حقائق عن المستخدمين تستمر إلى أجل غير مسمى: اسمهم، مهنتهم، تفضيلاتهم، أسلوب تواصلهم، وأي شيء آخر يستحق التذكر عبر المحادثات. لا تُخزن هذه الحقائق كنص خام، بل تُحوّل إلى تضمينات متجهية (vector embeddings)، مما يتيح البحث الدلالي عن التشابه.
عندما يسأل المستخدم "ما هي لغة البرمجة التي يجب أن أستخدمها؟"، فإننا لا نطابق الكلمات المفتاحية مع الذكريات المخزنة. بل نضمّن الاستعلام ونجد الذكريات ذات الصلة الدلالية. تظهر ذكريات مثل "المستخدم يفضل بايثون" و"يعمل على بنية تحتية للتعلم الآلي" لأنها ذات صلة مفاهيمية، حتى بدون كلمات مفتاحية مشتركة.
يملأ النظام الذاكرة طويلة المدى عبر قناتين. تأتي الذكريات الصريحة من طلبات مباشرة: "تذكر أنني أفضل النقاط التعدادية" أو "لا تنسَ أنني أعاني من حساسية تجاه الفول السوداني". نكتشف العبارات المحفزة، ونستخرج الحقيقة الأساسية، ونخزنها بأقصى أهمية. لا تُحذف هذه الذكريات تلقائيًا أبدًا.
تأتي الذكريات التلقائية من تحليل المحادثة. عندما يذكر المستخدم "كنت أقود فريق منصة التعلم الآلي"، فهذا سياق قيّم حتى بدون طلب حفظ صريح. بعد كل تفاعل، يفحص عامل خلفي المحادثة ويستخرج الحقائق الجديرة بالتخزين، وكل منها موسوم بدرجة أهمية.
تتراوح درجات الأهمية من واحد إلى خمسة. خمسة تعني معلومات حاسمة لا ينبغي نسيانها أبدًا: تعليمات المستخدم الصريحة، التفضيلات القوية، الحساسيات. أربعة تمثل حقائق شخصية رئيسية مثل المهنة أو الموقع. ثلاثة هي سياق عام مثل الهوايات والاهتمامات. اثنان تغطي معلومات مؤقتة مثل المشاريع الحالية. واحد هي تفاصيل ثانوية. تحصل الذكريات الصريحة تلقائيًا على خمسة؛ وتحصل الاستخلاصات التلقائية عادةً على درجة تتراوح بين واحد وأربعة بناءً على مدى أهمية الحقيقة.
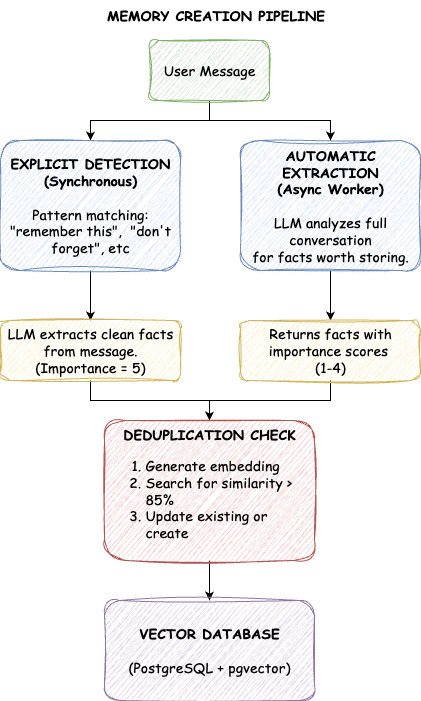
يظهر تحدٍ مع الاستخلاص التلقائي: ماذا لو قال المستخدم "أنا أحب بايثون" في جلسة واحدة و"أفضل بايثون على جافاسكريبت" في جلسة أخرى؟ التخزين الساذج ينشئ تكرارات. تحل TrueMem هذه المشكلة بإزالة التكرار الدلالي. قبل التخزين، نبحث عن ذكريات موجودة بتشابه يزيد عن 85%. إذا كان هناك تكرار شبه مطابق، نحدّثه بدلاً من إنشاء إدخال جديد. تظل قاعدة البيانات نظيفة مع كل حقيقة تظهر مرة واحدة بالضبط في شكلها الأكثر اكتمالاً.
تُعالج الخصوصية من خلال الشفافية. يمكن للمستخدمين عرض وتعديل وحذف أي ذاكرة مخزنة. جميع الذكريات معزولة تمامًا لكل مستخدم. لعمليات النشر المؤسسية، يعمل النظام بأكمله على بنيتك التحتية. لا شيء يغادر بيئتك.
ماذا عن دقة الاستخلاص؟ تتناول عدة آليات هذا الأمر: تسجيل الأهمية يعني أن الاستخلاصات التلقائية تُهذّب قبل الذكريات الصريحة؛ يمكن للمستخدمين مراجعة الأخطاء وتصحيحها؛ والمعلومات الصحيحة التي تُعزز عبر المحادثات تتراكم أهمية أعلى بينما تتلاشى الاستخلاصات الخاطئة لمرة واحدة من خلال التهذيب الطبيعي.
تخزين الذكريات هو نصف المشكلة فقط. عندما يرسل المستخدم رسالة، نحتاج إلى المجموعة الفرعية الصحيحة: ليس كل شيء، فقط ما هو ذو صلة. قد يكون لدى المستخدم المتقدم 150 حقيقة مخزنة؛ وتضمينها جميعًا سيؤدي إلى تضخم نافذة السياق.
تقوم العملية بتضمين رسالة المستخدم، وتُجري بحث التشابه بجيب التمام (cosine similarity)، وتُعيد أفضل عشرة تطابقات. يستغرق هذا أقل من 10 مللي ثانية مع الفهرسة الصحيحة.
استثناء واحد: المستخدمون الجدد. إذا كان لدى شخص ما أقل من عشر ذكريات، نضمّنها جميعًا بغض النظر عن التشابه. في بداية العلاقة، كل جزء من السياق مهم. بمجرد أن يتجاوز العدد عشرة، نتحول إلى الاسترجاع القائم على التشابه الخالص.
هذا الاسترجاع جزء من سير عمل أوسع لإعداد السياق، ويجب أن يكون سريعًا.
طبقة الذاكرة تكون مفيدة فقط إذا لم تُضف زمن انتقال ملحوظًا. المستخدمون حساسون للتأخيرات؛ حتى 200 مللي ثانية تبدو بطيئة. كان هدفنا أقل من 80 مللي ثانية لإعداد السياق.
المفتاح هو الموازاة. يتضمن إعداد السياق عدة عمليات مستقلة: توليد تضمين، جلب الرسائل الحديثة، التحقق من المحفزات الصريحة، والبحث في الذكريات طويلة المدى. بدلاً من تشغيلها بالتسلسل، نقوم بتشغيلها بالتوازي.
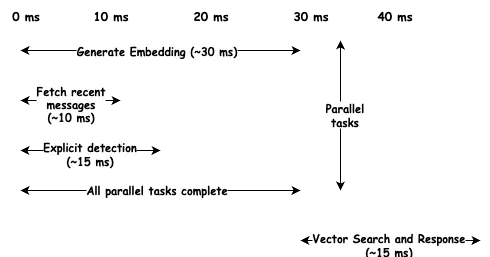
توليد التضمين هو الأبطأ بحوالي 30 مللي ثانية، لكنه يعمل بالتوازي مع استعلامات قاعدة البيانات التي تكتمل في 10 مللي ثانية. نحن نتحمل تكلفة أطول عملية، وليس المجموع. إجمالي زمن الانتقال يصل إلى حوالي 45 مللي ثانية، وهو أقل بكثير من الهدف.
العمليات الثقيلة مثل التلخيص واستخراج الذاكرة تعمل بشكل غير متزامن بعد إرسال الاستجابة. المستخدم لا ينتظر أبدًا؛ تتم المعالجة في الخلفية. هذا الفصل بين المسار المتزامن السريع والمسار غير المتزامن البطيء ضروري للاستخدام في بيئة الإنتاج.
مع عمل الذاكرة بشكل موثوق، ظهرت فائدة غير متوقعة: لقد بنينا بالصدفة شيئًا مستقلاً عن النموذج.
هذا ما لم نتوقعه. بمجرد أن توجد الذاكرة خارج النموذج، لم تعد مقيدًا بمزود واحد.
هل تنتقل من GPT-4 إلى Claude؟ ذاكرتك تستمر. هل تستخدم نماذج مختلفة لمهام مختلفة، مثل التفكير المعقد بنموذج والكتابة الإبداعية بآخر؟ جميعها تشارك نفس الفهم عنك. هل تقوم بضبط نموذج مخصص؟ يرث علاقات المستخدم الحالية من اليوم الأول.
طبقة الذاكرة تصبح ثابتك؛ وتصبح النماذج قابلة للتبديل.
يبقى التكامل في حده الأدنى: جلب السياق قبل استدعاء نموذج اللغة الكبير (LLM)، وتسجيل التفاعل بعد ذلك. مكالمتان لـ API تحولان أي نموذج عديم الحالة إلى نموذج بذاكرة مستمرة. لا يوجد ارتباط بـ SDK، ولا تكامل معقد. مجرد نقاط نهاية HTTP تتناسب مع أي بنية.
بالطبع، لا يمكن للذكريات أن تنمو إلى الأبد. نظام بدون إدارة دورة حياة سيغرق في الحقائق القديمة.
كل ذاكرة لها درجة أهمية من واحد إلى خمسة. التعليمات الصريحة تحصل على خمسة. الحقائق الشخصية الرئيسية تحصل على أربعة. السياق العام يحصل على ثلاثة. المعلومات المؤقتة تحصل على اثنين. التفاصيل الثانوية تحصل على واحد.
عندما يتجاوز العدد حدًا مرنًا (150 افتراضيًا)، تبدأ عملية التقليم. لا يمس النظام أبدًا الذكريات ذات الأهمية أربعة أو أعلى. من بين الذكريات الأقل أهمية، يزيل الأقل تقييمًا أولاً، مستخدمًا العمر كمعيار لكسر التعادل.
تعليمات المستخدم الصريحة تبقى إلى أجل غير مسمى. الاستخلاصات التلقائية منخفضة القيمة يتم إعادة تدويرها لإفساح المجال لمعلومات جديدة. تبقى الذاكرة ذات صلة دون الحاجة إلى تنظيم يدوي.
يفتح المستخدم محادثة ويكتب: "ساعدني في صياغة تحديثي الأسبوعي، بناءً على النقاط التالية..."
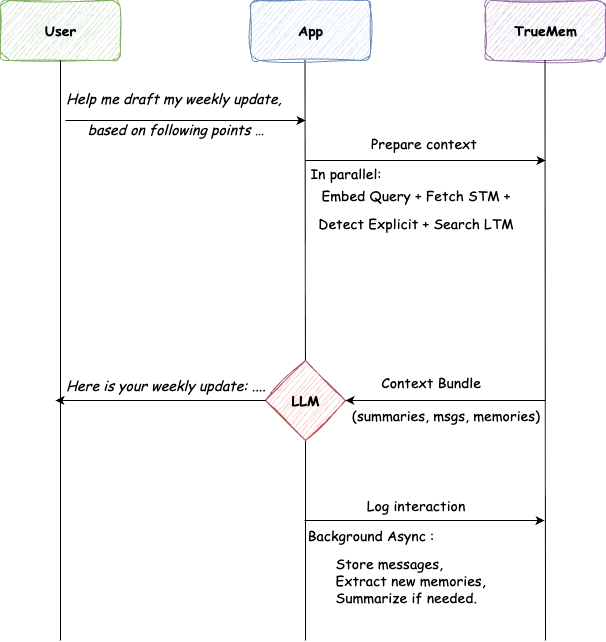
يستدعي التطبيق TrueMem للحصول على السياق. يقوم TrueMem بتجميع الذاكرة قصيرة المدى (STM) والذاكرة طويلة المدى (LTM) ذات الصلة، بما في ذلك "الاسم هو براثاميش"، "مهندس تعلم آلة أول"، "يعمل على خدمة الذاكرة". يستغرق هذا 45 مللي ثانية.
يُنشئ نموذج اللغة الكبير (LLM) استجابة مخصصة: "إليك تحديثك الأسبوعي، براثاميش..." لا طقوس. لا إعادة تقديم. الذكاء الاصطناعي يعرف من يسأل.
بعد الاستجابة، يسجل التطبيق التفاعل. تقوم العمال الخلفيون بتخزين الرسائل، واستخراج أي حقائق جديدة، وتحديث الملخصات حسب الحاجة. تتم المهام الثقيلة بشكل غير مرئي.
اخترنا PostgreSQL مع pgvector بدلاً من قواعد بيانات المتجهات المخصصة لأسباب عملية. معظم الفرق تستخدم Postgres بالفعل. تتواجد الذكريات جنبًا إلى جنب مع بيانات المستخدم بضمانات ACID كاملة. بالنسبة لمجموعات المتجهات لكل مستخدم التي تتراوح بين 100-200 متجه، يوفر pgvector بحث تشابه في أقل من 10 مللي ثانية. بالنسبة للذاكرة المحددة للمستخدم، إنه الخيار الصحيح.
تعمل العمال الخلفيون على قوائم انتظار مدعومة بـ Redis لأن استدعاءات نموذج اللغة الكبير (LLM) تستغرق ثوانٍ، وهو وقت طويل جدًا لحظر الطلبات. يمكن للعمال إعادة محاولة الفشل، وتجميع العمليات، والتوسع بشكل مستقل دون التأثير على زمن الاستجابة للمستخدم.
هل تتذكر طقس الجمعة ذاك؟ "أنا براثاميش. مهندس برمجيات أول. أعمل على خدمة الذاكرة."
مع TrueMem، يحدث ذلك مرة واحدة. يتذكر الذكاء الاصطناعي. تحديث الجمعة القادم يعمل بسلاسة. مسودة البريد الإلكتروني للشهر القادم تعرف توقيعي. السياق موجود دائمًا.
والأفضل من ذلك: قم بالتبديل إلى نموذج مختلف، وتنتقل الذاكرة. يصبح المساعد اليومي مستقلًا عن النموذج دون عمل إضافي.
هذا هو الهدف. ذكاء اصطناعي يتذكرك. ليس لأنك تستمر في تذكيره، بل لأنه يفعل ذلك بالفعل.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








أحدث الأخبار والمقالات والموارد تصلك مباشرة إلى بريدك الوارد
© 2026 جميع الحقوق محفوظة.







.png)
.webp)










.webp)
