




July 4, 2026
|
5 min read


احصل على وصول فوري إلى بيئة TrueFoundry مباشرة. انشر النماذج، ووجّه حركة مرور LLM، واستكشف المنصة بالكامل — بيئة الاختبار الخاصة بك جاهزة في ثوانٍ، ولا يلزم وجود بطاقة ائتمان.









Published: July 4, 2026

Blazingly fast way to build, track and deploy your models!
انتقل الذكاء الاصطناعي التوليدي بسرعة من مرحلة التجريب إلى التنفيذ، وأصبح الآن جزءًا لا يتجزأ من المنتجات والعمليات وتجارب العملاء. ومع ذلك، مع توسع الشركات في تبنيه، تظهر مشكلة هيكلية: ينمو استخدام الذكاء الاصطناعي بوتيرة أسرع من الآليات المطلوبة للتحكم في التكلفة. ما يبدأ كمشروع تجريبي محدود يتوسع بسرعة ليشمل فرقًا متعددة تعمل بشكل مستقل، وتطبيقات تستدعي نماذج متعددة، وسير عمل وكيلية تنفذ استدلالًا متعدد الخطوات. والنتيجة ليست مجرد إنفاق أعلى، بل تكاليف متزايدة غير متوقعة ومتراكمة عبر المؤسسة.
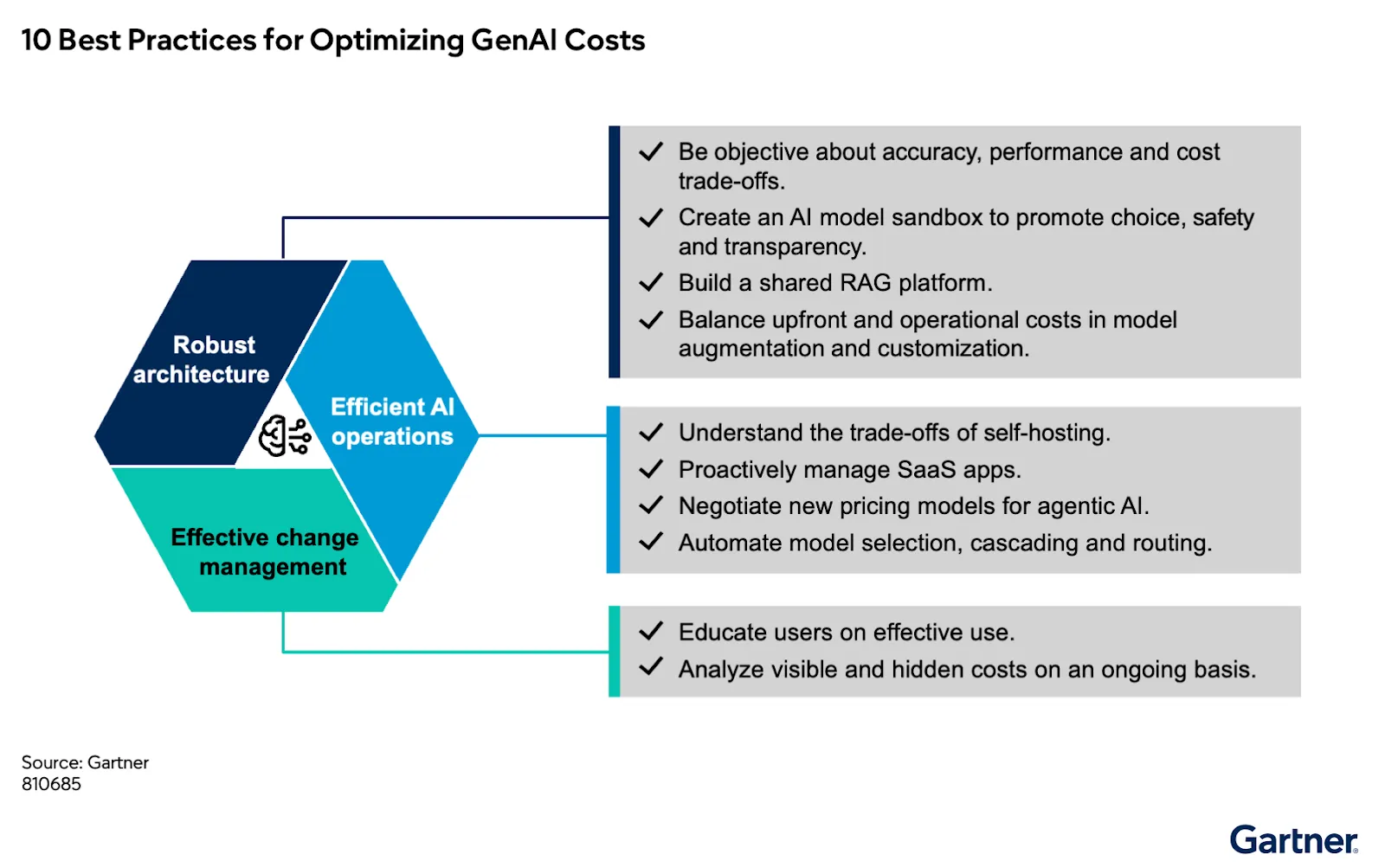
يتم تسليط الضوء على هذا التحدي في تقرير غارتنر “10 من أفضل الممارسات لتحسين تكاليف الذكاء الاصطناعي التوليدي والوكيلية” ، والذي يبحث في كيفية تأثير القرارات المعمارية ونقص الانضباط التشغيلي في تجاوز التكاليف على نطاق واسع. وكما يشير التقرير، “حتى عام 2028، سيتجاوز ما لا يقل عن 50% من مشاريع الذكاء الاصطناعي التوليدي (GenAI) تكاليفها الميزانية المخصصة بسبب خيارات معمارية سيئة ونقص الخبرة التشغيلية.” هذه ليست مشكلة أدوات—إنها في الأساس فشل في النموذج المعماري والتشغيلي.
يتم استكشاف هذا التحول في تقرير غارتنر "10 من أفضل الممارسات لتحسين تكاليف الذكاء الاصطناعي التوليدي والوكيلية" ، والذي يركز على كيفية وجوب إعادة تفكير الشركات في التكلفة والحوكمة والتحكم التشغيلي مع انتقال أنظمة الذكاء الاصطناعي إلى مرحلة الإنتاج.
تم ذكر TrueFoundry في هذا التقرير في سياق بوابات الذكاء الاصطناعي—وهي طبقة تحكم ناشئة لإدارة التكلفة والموثوقية والحوكمة عبر أعباء عمل الذكاء الاصطناعي.
تسلط غارتنر الضوء بوضوح على حجم التحدي: “تتعرض المؤسسات التي تنتقل من المشاريع التجريبية للذكاء الاصطناعي التوليدي إلى مرحلة الإنتاج لصدمة واقعية عندما يتعلق الأمر بالتكاليف. يمكن أن يكون إنشاء نظام ذكاء اصطناعي توليدي جاهز للإنتاج أغلى بأضعاف مضاعفة من تشغيل مشروع تجريبي.." تمثل هذه نقطة التحول — حيث تصبح تكلفة الذكاء الاصطناعي مشكلة وقت التشغيل، وليست مصدر قلق وقت البناء، مدفوعة بكيفية تنظيم الأنظمة وحوكمتها وتشغيلها على نطاق واسع.

لفهم المشكلة، من المهم تحليل كيفية عمل أنظمة الذكاء الاصطناعي على نطاق واسع.
1 يصبح الاستدلال طبقة التكلفة المهيمنة
على عكس الأنظمة التقليدية، يتكبد الذكاء الاصطناعي تكلفة في كل مرة يتم استخدامه فيها.
تسلط غارتنر الضوء على هذا التحول:
"حتى عام 2028، ستشكل التكاليف المجمعة لاستدلال النموذج ما لا يقل عن 70% من إجمالي تكاليف دورة حياة النموذج..."
يغير هذا جذريًا كيفية إدارة التكلفة.
2 سير العمل الوكالي يضاعف التكلفة لكل طلب
أنظمة الذكاء الاصطناعي الحديثة ليست أحادية الخطوة.
يمكن لطلب واحد أن يطلق:
يؤدي هذا إلى توسع غير خطي في التكلفة.
3 التبني المجزأ يؤدي إلى عدم الكفاءة
في معظم المؤسسات:
يؤدي هذا إلى:
4 غياب الحوكمة التشغيلية يؤدي إلى تضخم التكاليف
بدون تحكم مركزي:
هنا تصبح التكلفة غير قابلة للإدارة على نطاق واسع.
تشير التوصيات في غارتنر إلى تحول واضح.
الأمر لا يتعلق بنماذج أفضل.
بل يتعلق بـ التحكم في كيفية استخدام النماذج في بيئة الإنتاج.
تشمل الممارسات الرئيسية:
1 وصول مركزي إلى أنظمة الذكاء الاصطناعي
طبقة تحكم واحدة لإدارة جميع تفاعلات النماذج والأدوات.
2 توجيه ذكي للنماذج
اختيار النماذج ديناميكيًا بناءً على التكلفة وزمن الاستجابة والأداء.
3 الحوكمة وتطبيق السياسات
تطبيق الحصص والقيود والضوابط على جميع الاستخدامات.
4 قابلية المراقبة الشاملة
تتبع الاستخدام والأداء والتكلفة بمستوى تفصيلي.
5 آليات تحسين التكلفة
تقليل الاستدلال المتكرر من خلال التخزين المؤقت وإعادة الاستخدام.
تحدد جارتنر هذا التحول:
"فئة جديدة من الأدوات تسمى بوابات الذكاء الاصطناعي يمكن أن تساعد في التحكم في التكاليف من خلال فرض السياسات... وبتوفير ميزات مثل التخزين المؤقت وتوجيه النماذج لتقليل التكاليف."
هذا يحدد طبقة جديدة:
مستوى التحكم في الذكاء الاصطناعي
نعتقد أن الاتجاه الذي تحدده جارتنر يشير إلى متطلب واضح:
طبقة تحكم مركزية تنظم كيفية استخدام الذكاء الاصطناعي في جميع أنحاء المؤسسة.
لقد تم ذكر TrueFoundry في هذا التقرير كجزء من هذه المنظومة الناشئة لبوابات الذكاء الاصطناعي.
تعمل TrueFoundry على مستوى الطبقة التي يحدث فيها استخدام الذكاء الاصطناعي — وحيث تتولد التكلفة.
1 من التتبع التفاعلي إلى التحكم الاستباقي
بدلاً من:
تتيح TrueFoundry:
2 التحسين الديناميكي أثناء التشغيل
3 رؤية شاملة عبر أنظمة الذكاء الاصطناعي
4 الحوكمة على نطاق المؤسسة
5 عمليات نشر جاهزة للمؤسسات
هذا يحول نموذج التشغيل من:
«ما هو حجم إنفاقنا على الذكاء الاصطناعي؟»
إلى
«هل نستخدم الذكاء الاصطناعي بكفاءة — وهل يجب تنفيذ هذا الطلب من الأساس؟»
يدخل الذكاء الاصطناعي التوليدي مرحلته الثانية.
كانت المرحلة الأولى تدور حول الوصول.
المرحلة التالية تدور حول التحكم والاقتصاديات.
في الوقت نفسه، تتطور نماذج التسعير:
«بحلول عام 2030، سيتحول ما لا يقل عن 40% من إنفاق برمجيات SaaS للمؤسسات نحو التسعير القائم على الاستخدام أو الوكيل أو النتائج.» هذا يجعل التكلفة:
المؤسسات التي تفرض الرقابة على طبقة وقت التشغيل ستقوم بما يلي:
منظور نهائي
تُعرّف غارتنر تكلفة الذكاء الاصطناعي التوليدي بأنها تحدٍ على مستوى الأنظمة متجذر في سلوك وقت التشغيل—وليس اختيار النموذج. لأنه عند التوسع:
الشركات التي تنجح لن تكون تلك التي تتبنى الذكاء الاصطناعي بشكل أسرع.
بل ستكون تلك التي تُدخل:
التحكم، والحوكمة، والانضباط الاقتصادي في كيفية عمل أنظمة الذكاء الاصطناعي.
لن تأتي الميزة من الوصول إلى النماذج—
بل من التحكم في كيفية استخدام تلك النماذج.
استكشف المزيد
اقرأ تقرير غارتنر الكامل
تعرف على المزيد حول TrueFoundry: https://www.truefoundry.com
لا تصادق غارتنر على أي بائع أو منتج أو خدمة مذكورة في منشوراتها البحثية، ولا تنصح مستخدمي التكنولوجيا باختيار البائعين الحاصلين على أعلى التقييمات أو أي تصنيف آخر فقط. تتكون منشورات غارتنر البحثية من آراء منظمة غارتنر البحثية ولا ينبغي تفسيرها على أنها بيانات واقعية.
غارتنر، 10 أفضل الممارسات لتحسين تكاليف الذكاء الاصطناعي التوليدي والوكيل، بقلم أرون تشاندراسيكاران وآخرين، 20 مارس 2026
GARTNER هي علامة تجارية لشركة غارتنر و/أو الشركات التابعة لها.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.

You can optimize generative AI costs by using the right model for each task and avoiding unnecessary usage. For example, simple tasks do not require large and expensive models, so choosing smaller ones can reduce spend. In addition, keeping prompts focused helps avoid extra token usage that does not add value. Similarly, limiting response length prevents paying for unnecessary output. Over time, regularly tracking usage makes it easier to identify where costs are increasing and take corrective action.
You can reduce LLM costs by cutting down on long prompts and repeated queries. Since longer inputs increase token usage, keeping them concise helps control costs. At the same time, repeated queries without caching can lead to avoidable spending. Using smaller models for basic tasks is another effective way to reduce costs without impacting performance. Overall, maintaining control over both input and output length ensures more efficient and predictable usage.
An AI gateway helps optimize costs by controlling how different AI models are used. It routes requests to the most cost-effective model based on the task, so simple queries do not end up using expensive models. This prevents unnecessary spend and improves efficiency. With TrueFoundry, the AI gateway goes a step further by giving teams a unified layer to connect, observe, and govern AI usage across applications. It also provides clear visibility into token usage, enables smart routing, and helps enforce limits to keep spending under control.
Yes, you can use generative AI for free through limited plans offered by providers. These plans are useful for testing and small-scale usage. However, they come with restrictions on usage and features. Once usage increases, you will need to move to paid plans.
Generative AI is expensive because it requires high computing power for every request. Large models run on costly infrastructure, which increases overall expenses. Costs also come from embeddings, integrations, and repeated workflows. This makes the total cost higher than just token usage.
The best practices for AI cost optimization include using the smallest effective model and reducing unnecessary usage. Keeping prompts clear and output limited helps control token usage. Monitoring usage regularly helps identify cost-heavy areas. Reducing repeated tasks and optimizing workflows also improves efficiency.
LLM inference cost is affected by model size, token usage, and request frequency. Larger models cost more because they require more computing power. Longer prompts and outputs increase token usage and cost. Frequent or multi-step requests can quickly increase overall expenses.
Token usage impacts AI costs by determining how much you are charged per request. Every input and output is measured in tokens. Longer prompts and responses lead to higher costs. Managing token usage carefully helps keep overall spending under control.
The cost of running LLMs in production includes token usage, infrastructure, and system-related expenses. You also need to account for storage, monitoring, and integrations. Token costs are often only a part of the total spend. As usage grows, these additional costs increase significantly.
Agentic AI is a system where AI performs tasks through multiple steps and decisions. It affects costs by increasing the number of model calls required to complete a task. Each step adds to token usage and compute cost. This makes it more expensive than single-step AI interactions.






أحدث الأخبار والمقالات والموارد تصلك مباشرة إلى بريدك الوارد
© 2026 جميع الحقوق محفوظة.







.png)
.webp)










.webp)
