




July 4, 2026
|
5 min read


احصل على وصول فوري إلى بيئة TrueFoundry مباشرة. انشر النماذج، ووجّه حركة مرور LLM، واستكشف المنصة بالكامل — بيئة الاختبار الخاصة بك جاهزة في ثوانٍ، ولا يلزم وجود بطاقة ائتمان.









Published: July 4, 2026

Blazingly fast way to build, track and deploy your models!
في عالم اليوم القائم على البيانات، يعد البحث في كميات هائلة من البيانات للعثور على عناصر متشابهة عملية أساسية تُستخدم في تطبيقات متنوعة، بدءًا من قواعد البيانات وحتى محركات البحث وأنظمة التوصية. تتضمن هذه العملية، المعروفة بالبحث عن التشابه، تحديد العناصر المتشابهة بناءً على معايير معينة.
بينما تكون عمليات البحث التقليدية في قواعد البيانات القائمة على معايير رقمية ثابتة (مثل العثور على الموظفين ضمن نطاق رواتب محدد) مباشرة، يتعامل البحث عن التشابه مع استعلامات أكثر تعقيدًا. على سبيل المثال، قد يبحث المستخدم عن "أحذية"، "أحذية سوداء"، أو نموذج معين مثل "Nike AF-1 LV8". يمكن أن تكون هذه الاستعلامات غامضة ومتنوعة، مما يتطلب من النظام فهم وتمييز المفاهيم مثل الأنواع المختلفة للأحذية.
يعد البحث عن التشابه أمرًا بالغ الأهمية في العديد من المجالات، بما في ذلك:
التحدي الرئيسي في البحث عن التشابه هو التعامل مع البيانات الضخمة مع فهم دقيق للمعاني المفاهيمية الأعمق للعناصر التي يتم البحث عنها. قواعد البيانات التقليدية، التي تعتمد على تمثيلات رمزية للكائنات، لا تفي بالغرض في مثل هذه السيناريوهات. بدلاً من ذلك، نحتاج إلى تقنيات أكثر تقدمًا يمكنها التعامل مع التمثيلات الدلالية للبيانات وإجراء عمليات البحث بكفاءة حتى على نطاق واسع. التمثيلات، ومقاييس المسافة، وخوارزميات البحث المختلفة.
من خلال الاستفادة من البحث عن التشابه، يمكننا تحويل الاستعلامات المعقدة والمجردة إلى رؤى قابلة للتنفيذ، مما يجعله أداة قوية في مجالات مختلفة. في الأقسام التالية، سنتعمق في كيفية عمل البحث عن التشابه، مع التركيز على دور تمثيلات المتجهات، ومقاييس المسافة، وخوارزميات البحث المختلفة.
.webp)
في التعلم الآلي، نمثل الكائنات والمفاهيم الواقعية كمتجهات، وهي مجموعات من الأرقام المتصلة تُعرف بالتضمينات. يتيح لنا هذا النهج التقاط المعاني الدلالية الأعمق للعناصر. عندما يتم تحويل كائنات مثل الصور أو النصوص إلى تضمينات متجهية، يمكن تقييم تشابهها عن طريق قياس المسافة بين هذه المتجهات في فضاء عالي الأبعاد.
على سبيل المثال، في الفضاء المتجهي، ستكون للصور المتشابهة متجهات قريبة من بعضها البعض، بينما ستكون الصور غير المتشابهة متباعدة. وهذا يجعل من الممكن إجراء عمليات رياضية للعثور على العناصر المتشابهة ومقارنتها بكفاءة.
.webp)
تُستخدم عدة نماذج لتوليد هذه التضمينات المتجهة:
تُدرب هذه النماذج على مجموعات بيانات ومهام كبيرة، مما يمكنها من إنتاج تضمينات تمثل المحتوى الدلالي للعناصر بفعالية.
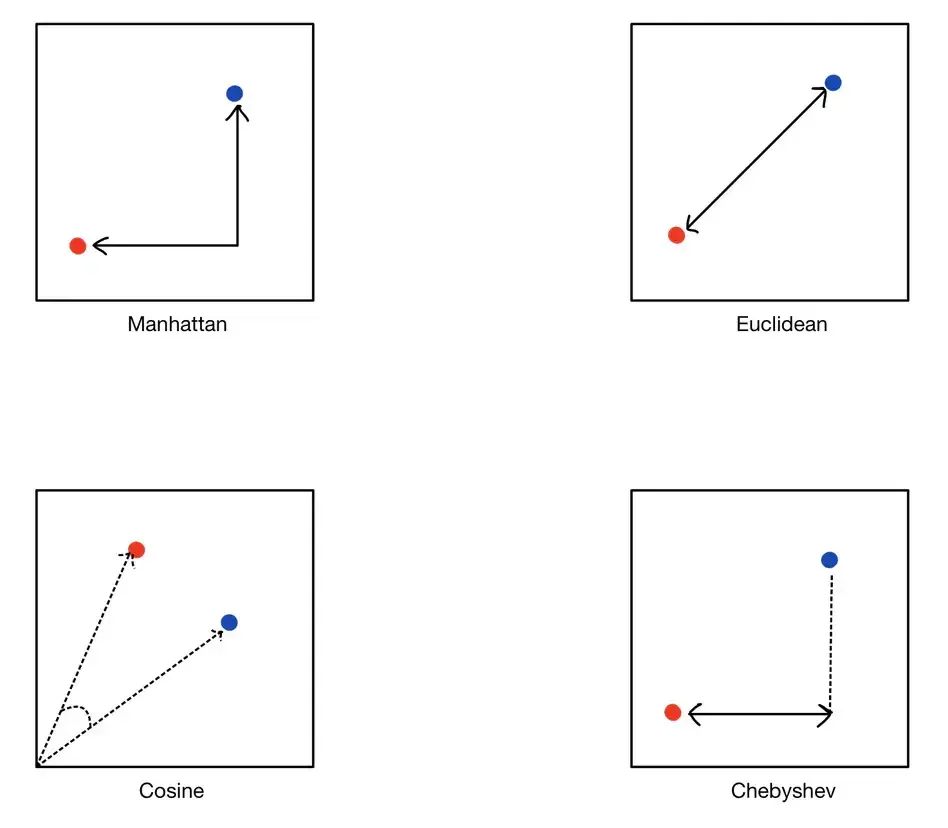
لتحديد مدى تشابه تضمينين متجهين، نستخدم مقاييس المسافة. تحسب هذه المقاييس "المسافة" بين المتجهات في الفضاء المتجه، حيث تشير المسافات الأصغر إلى تشابه أكبر.
تقيس المسافة الإقليدية المسافة الخطية المستقيمة بين نقطتين في فضاء متعدد الأبعاد. إنها الطريقة الأكثر بديهية لقياس المسافة، تشبه المسافة الهندسية التي قد تقيسها بالمسطرة. تكون مفيدة عندما تكون البيانات كثيفة، ويكون مفهوم المسافة المادية ذا صلة.
الصيغة:
.webp)
تُعرف أيضًا بمسافة L1، وتجمع مسافة مانهاتن الفروق المطلقة لإحداثياتها. هذا المقياس مناسب لهياكل البيانات الشبيهة بالشبكة، ويمكن تصورها على أنها إجمالي مسافة "كتلة المدينة" التي يقطعها المرء بين النقاط في شبكة.
الصيغة:
.webp)
يقيس تشابه جيب التمام جيب تمام الزاوية بين متجهين، مع التركيز على اتجاههما بدلاً من حجمهما. هذا مفيد بشكل خاص لبيانات النصوص، حيث قد يختلف حجم المتجه (تكرار الكلمات) ولكن الاتجاه (نمط استخدام الكلمات) أكثر أهمية.
.webp)
تقيس مسافة تشيبيشيف أقصى مسافة بين إحداثيات زوج من المتجهات. غالبًا ما تُستخدم في سيناريوهات الشبكات الشبيهة بالشطرنج حيث يمكنك التحرك في أي اتجاه، بما في ذلك قطريًا.
.webp)
يعتمد اختيار مقياس المسافة الصحيح على الخصائص والمتطلبات المحددة للتطبيق. فيما يلي بعض الإرشادات لاختيار المقياس المناسب:
أقرب الجيران K (k-NN) هي خوارزمية شائعة تستخدم للعثور على أقرب المتجهات إلى متجه استعلام معين. إليك كيفية عملها وإيجابياتها وسلبياتها:
.webp)
لمعالجة عدم كفاءة خوارزمية k-NN مع مجموعات البيانات الكبيرة، توفر طرق أقرب جار تقريبي (ANN) بديلاً أسرع، وإن كان أقل دقة. تهدف خوارزميات ANN إلى إيجاد "تخمين جيد" لأقرب الجيران، مقايضة بعض الدقة بالسرعة.
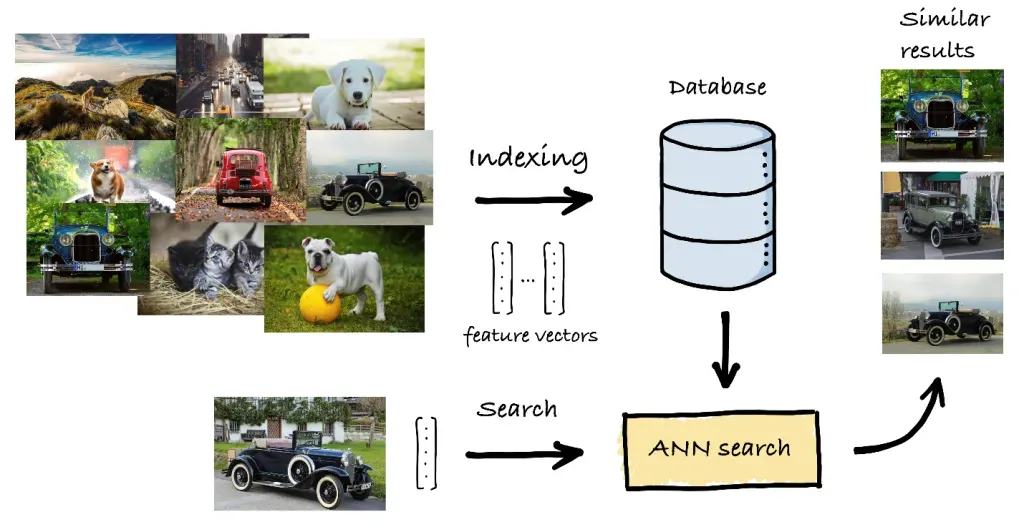
عند تطبيق البحث عن التشابه عمليًا، يمكن أن تساعد العديد من المكتبات والأطر البرمجية:
للبحث عن التشابه نطاق واسع من التطبيقات في مختلف المجالات، مستفيدًا من القدرة على إيجاد ومقارنة العناصر المتشابهة بسرعة ودقة. فيما يلي بعض التطبيقات الرئيسية:
تستخدم أنظمة التوصية البحث عن التشابه لاقتراح المنتجات أو المحتوى أو الخدمات بناءً على تفضيلات المستخدم وسلوكه.
يعد البحث عن التشابه أمرًا حيويًا لاسترجاع الصور أو مقاطع الفيديو المتشابهة بصريًا من قواعد البيانات الكبيرة.
في معالجة اللغات الطبيعية (NLP)، يساعد البحث عن التشابه في تطبيقات نصية متنوعة من خلال العثور على مستندات أو عبارات متشابهة دلاليًا.
الكشف عن الأنشطة الاحتيالية من خلال إيجاد أنماط وشذوذات تنحرف عن السلوك الطبيعي.
يساعد البحث عن التشابه في التشخيص الطبي والبحث الجيني من خلال مقارنة بيانات المرضى والتسلسلات الجينية.
أحد التحديات الرئيسية في البحث عن التشابه هو طبيعة استعلامات المستخدمين. يمكن أن تتراوح الاستعلامات من مصطلحات عامة جدًا مثل "أحذية" إلى عناصر محددة جدًا مثل "Nike AF-1 LV8". يجب أن يكون النظام قادرًا على تمييز هذه الفروق الدقيقة وفهم كيفية ارتباط العناصر المختلفة ببعضها البعض. يتطلب هذا فهمًا عميقًا للمعنى الدلالي وراء الاستعلامات، وهو ما يتجاوز مجرد مطابقة الكلمات الرئيسية البسيطة.
تحدٍ آخر مهم هو قابلية التوسع. في التطبيقات الواقعية، غالبًا ما نتعامل مع مجموعات بيانات ضخمة يمكن أن تتضمن مليارات العناصر. يتطلب البحث بكفاءة عبر هذه الكميات الكبيرة من البيانات تقنيات متقدمة وموارد حاسوبية قوية. تكافح أنظمة قواعد البيانات التقليدية، المصممة للمطابقات الدقيقة والتمثيلات الرمزية، لتقديم أداء جيد في هذه السيناريوهات.
يلعب البحث عن التشابه، المعروف أيضًا بالبحث المتجهي، دورًا محوريًا في مختلف التطبيقات الحديثة. من خلال الاستفادة من تضمينات المتجهات ومقاييس المسافة المتطورة، يتيح لنا البحث عن التشابه العثور على العناصر ومقارنتها بناءً على معناها الدلالي. فيما يلي النقاط الرئيسية:
للاستفادة حقًا من قوة البحث عن التشابه، من الضروري فهم المبادئ الأساسية واختيار الأدوات والتقنيات المناسبة لاحتياجاتك الخاصة. سواء كنت تقوم ببناء محرك توصية، أو نظام استرجاع قائم على المحتوى، أو آلية للكشف عن الاحتيال، يمكن للبحث عن التشابه أن يعزز بشكل كبير دقة وكفاءة حلولك.
البحث عن التشابه هو تقنية للعثور على العناصر المتشابهة عبر مجموعات بيانات ضخمة. يعتمد على تضمينات المتجهات التي تلتقط المعنى المفاهيمي للبيانات، وغالبًا ما يستخدم تمثيلات المتجهات ومقاييس المسافة. هذه العملية حاسمة لتطبيقات مثل توصيات المنتجات ومطابقة النصوص، مما يمكّن الأنظمة من تحديد المعلومات ذات الصلة بكفاءة ودقة.
لإجراء بحث عن التشابه، يتم أولاً تحويل الكائنات مثل النصوص أو الصور إلى تضمينات متجهة باستخدام نماذج متخصصة. ثم، تقيس مقاييس المسافة — مثل المسافة الإقليدية أو مسافة جيب التمام — "المسافة" بين هذه المتجهات في فضاء عالي الأبعاد. تشير المسافات الأصغر إلى تشابه أكبر. بدلاً من ذلك، تقيس مقاييس التشابه مثل تشابه جيب التمام (Cosine Similarity) التقارب مباشرة، حيث تعني الدرجة الأعلى (الأقرب إلى 1) تشابهًا أكبر.
مثال ممتاز على البحث عن التشابه هو منصة التجارة الإلكترونية التي توصي بمنتجات مشابهة لما شاهده المستخدم أو اشتراه. يساعد هذا المتسوقين على اكتشاف العناصر ذات الصلة بسهولة. البحث عن الصور، الذي يعثر على صور متشابهة بصريًا من قواعد بيانات ضخمة، هو تطبيق رئيسي آخر يستخدم تقنية البحث عن التشابه.
في الأنظمة المدعومة بنماذج اللغة الكبيرة (LLM) — وخاصة مسارات RAG (التوليد المعزز بالاسترجاع) — يعمل البحث عن التشابه جنبًا إلى جنب مع النموذج عن طريق تحويل النص إلى تضمينات متجهة تلتقط المعنى الدلالي. تبحث طبقة الاسترجاع في هذه المتجهات للعثور على المحتوى الأكثر تشابهًا مع استعلام، ثم تمرر النتائج إلى نموذج اللغة الكبير (LLM) عن طريق قياس المسافة بين هذه المتجهات. إنه أمر حاسم لاسترجاع المعلومات ذات الصلة وتوليد استجابات واعية بالسياق، مما يعزز بشكل كبير فهم النموذج وفائدته للمستخدمين.
البحث التشابهي بالغ الأهمية في العديد من التطبيقات. فهو يعزز توصيات المنتجات في التجارة الإلكترونية، ويسهل البحث عن الصور ومقاطع الفيديو، ويحسن معالجة اللغة الطبيعية لمطابقة النصوص. وفي الرعاية الصحية، يساعد في تحديد الحالات الطبية المتشابهة، محولاً البيانات المعقدة إلى رؤى قابلة للتنفيذ عبر مختلف الصناعات.
يعتمد البحث الدلالي على البحث التشابهي للعثور على العناصر بناءً على معناها، وليس مجرد الكلمات المفتاحية. يستخدم تضمينات المتجهات لتمثيل البيانات دلاليًا. وفي حين أن البحث التشابهي هو التقنية المستخدمة لمقارنة هذه المتجهات، فإن البحث الدلالي هو التطبيق الذي يستفيد منها لتحقيق فهم سياقي أعمق.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








أحدث الأخبار والمقالات والموارد تصلك مباشرة إلى بريدك الوارد
© 2026 جميع الحقوق محفوظة.







.png)
.webp)










.webp)
